登录社区云,与社区用户共同成长
邀请您加入社区
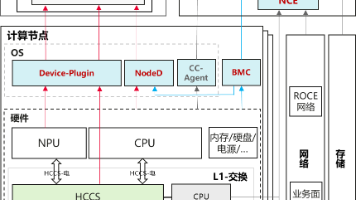
大规模AI集群运行过程中频繁因为各类硬件、软件故障导致训练任务中断,如何快速发现故障、缩短故障恢复时间MTTR成为提高AI集群可用度的重点方向。本文汇总了昇腾断点续训特性提供的故障检测、故障恢复能力以及面临的问题和挑战。
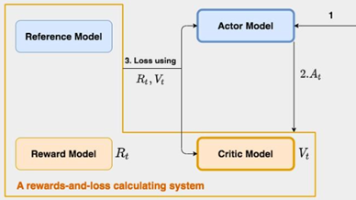
RLHF-PPO 昇腾训推共卡方案案例总结(下)
RLHF-PPO 昇腾训推共卡方案案例总结(上)
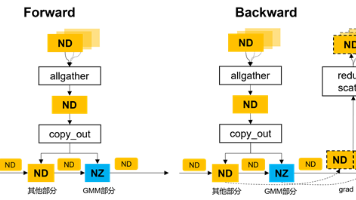
超节点FSDP2训练MOE大模型:GroupedMatmul NZ使能和性能收益分析
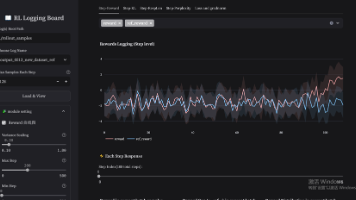
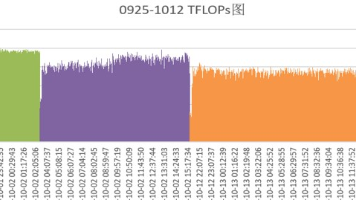
大规模训练集群性能问题(下降或抖动)分享及性能问题解决方案
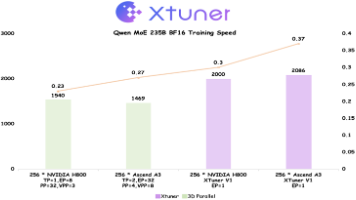
为了进一步挖掘 XTuner V1 训练方案的上限,实验室研究团队与华为昇腾技术团队在 Ascend A3 超节点上进行联合优化,充分利用超节点硬件特性,FSDP2首次在Qwen 235B MoE上实现了相比传统3D并行更高的 MFU(Model FLOPS Utilization,模型浮点运算利用率)。在理论算力落后 NVIDIA H800 近 20% 的情况下,最终实现训练吞吐超过 H800
2025年9月8日,上海人工智能实验室开源书生大模型新一代训练引擎XTuner V1。XTuner V1 是伴随上海AI实验室“通专融合”技术路线的持续演进,以及书生大模型研发实践而成长起来的新一代训练引擎。相较于传统的 3D 并行训练引擎,XTuner V1 不仅能应对更加复杂的训练场景,还具备更快的训练速度,尤其在超大规模稀疏混合专家(MoE)模型训练中优势显著。
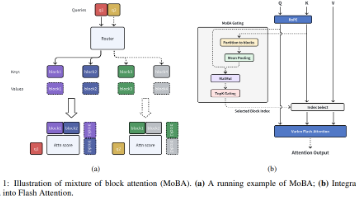
自上半年幻方发表NSA以来,原生稀疏Attention开始进入大众视野,直到十一之前DeepSeek-V3.2发布了DSA(DeepSeek Sparse Attention),原生稀疏Attention正式掀起应用热潮,当前已成为模型结构设计的重要考虑因素,然而稀疏Attention的未来趋势是block-wise还是token-wise稀疏,仍存在未知的发展可能,有待更进一步的检验。
摘要:随着大模型规模扩展和多模态应用发展,模型压缩技术面临新挑战。传统深度学习时代采用量化、剪枝等技术压缩10M-100M级模型,而大模型时代需针对LLM推理特性(Prefill计算密集、Decode访存密集)发展新型压缩方法。当前关键技术包括:1)权重量化(AWQ、GPTQ)降低访存开销;2)KVCache压缩(RazorAttention、KVQuant)优化序列处理;3)稀疏化技术(Spar
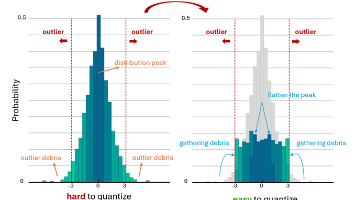
由于INT4表达能力有限,以及大模型激活异常值分布显著,大模型W4A4 INT4量化面临严峻的精度损失风险。本文分析了旋转量化的数学原理,并提出了基于分布转换的旋转量化算法(DartQuant),通过激活数据分布的平坦化,可有效降低W4A4量化误差。