
未来原生稀疏Attention是block-wise or token-wise?
自上半年幻方发表NSA以来,原生稀疏Attention开始进入大众视野,直到十一之前DeepSeek-V3.2发布了DSA(DeepSeek Sparse Attention),原生稀疏Attention正式掀起应用热潮,当前已成为模型结构设计的重要考虑因素,然而稀疏Attention的未来趋势是block-wise还是token-wise稀疏,仍存在未知的发展可能,有待更进一步的检验。
摘要
自上半年幻方发表NSA以来,原生稀疏Attention开始进入大众视野,直到十一之前DeepSeek-V3.2发布了DSA(DeepSeek Sparse Attention),原生稀疏Attention正式掀起应用热潮,当前已成为模型结构设计的重要考虑因素,然而稀疏Attention的未来趋势是block-wise还是token-wise稀疏,仍存在未知的发展可能,有待更进一步的检验。
一、从token-wise丢弃到block-wise稀疏检索
早期像Streaming-LLM、H2O等通过token丢弃实现KV Cache压缩、降低访存开销,但丢失历史信息容易放大曝光偏置的影响,误差累积将引起精度崩塌。后续RazorAttention、DuoAttention通过设置检索头,以增强长序列推理的信息检索能力,在32K以上长输入场景具备一定的精度优势。
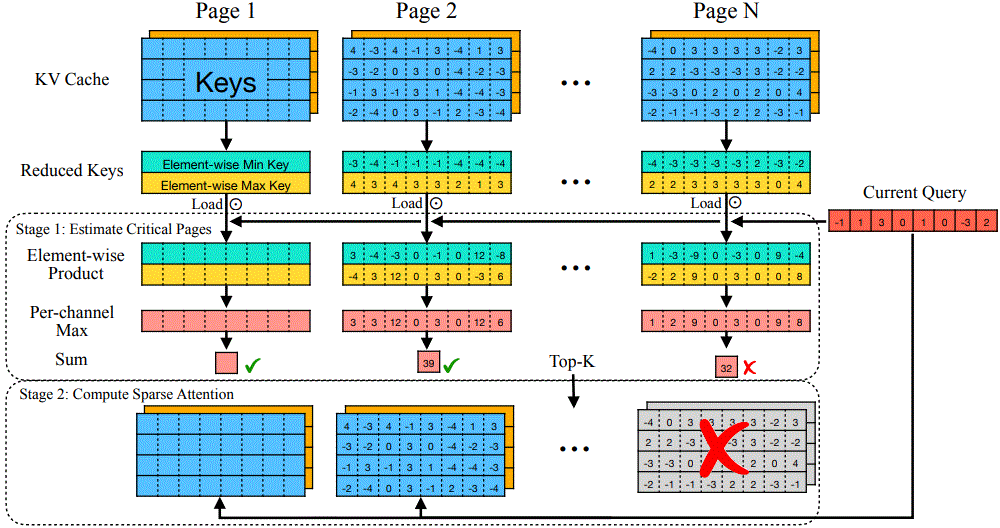
然而随着Reasoning、Agent、Coding等长输出任务的兴起,基于token丢弃的KV Cache压缩将引起非常大的精度损失,因此业界普遍开始设计基于以查代算的长序列推理系统,通过保留完整的KV Cache(如offload到CPU,构建多级缓存),并结合稀疏检索机制,每次大模型推理仅查询少量的KV Cache,以缓解长序列访存瓶颈。但是token-wise稀疏涉及密集的重要性计算、以及在线稀疏访存,容易引入不小的overhead,因此QuestAttention、infLLM等block-wise稀疏Attention逐步流行,通过设置代表性token(将block信息压缩至单token表示)以确定不同block的重要性,可降低重要性计算的在线开销,同时block-wise稀疏检索能够使访存变得连续,从而较好的平衡了精度与性能。以QuestAttention(如下图所示)算法为例,在长输入与长输出任务上均表现优越,包括Longbench、AIME、GPQA等评测指标。
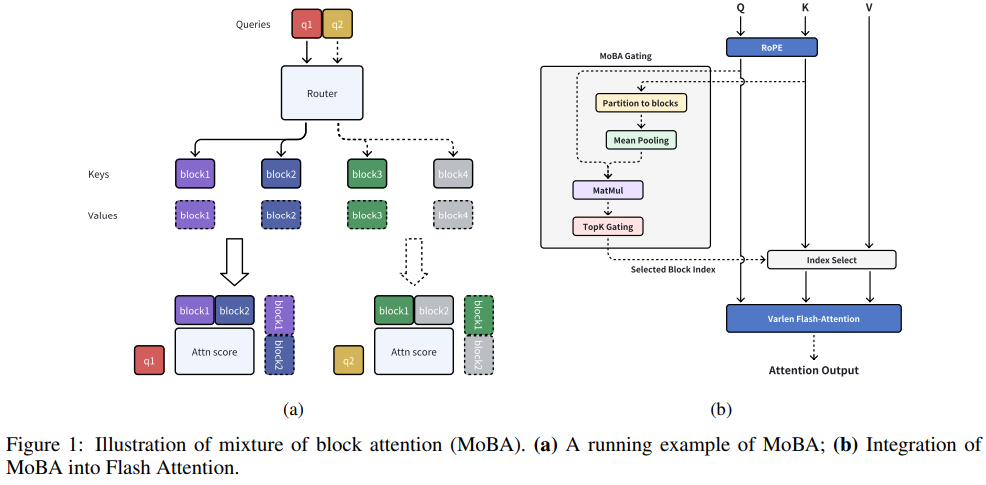
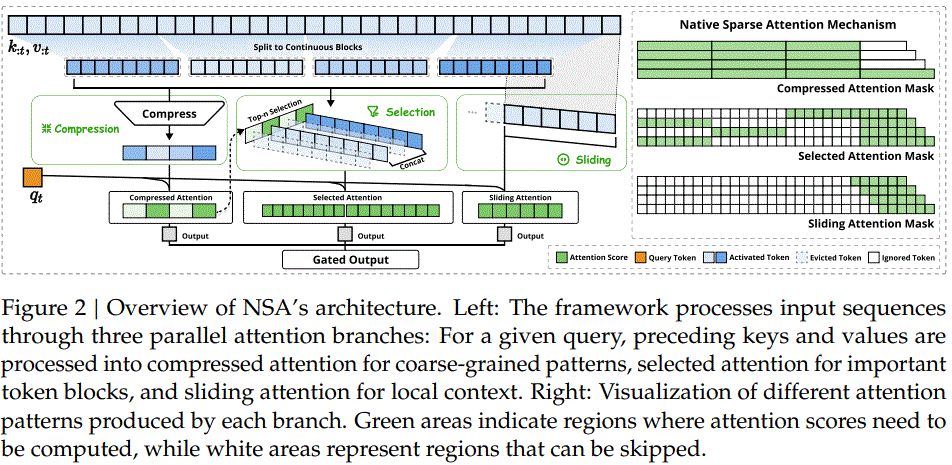
二、Block-wise原生稀疏Attention
典型代表包括NSA、MoBA与infLLM-v2,通过模型结构的原生设计、以及预训练的海量数据拟合,以确保模型精度。由于是Block-wise信息压缩(线性降维投影、pooling降采样等方式),因此该类型稀疏Attention通常与MHA/GQA结合,可实现prefill阶段稀疏计算、以及decode阶段稀疏访存,从而缓解长序列推理瓶颈。
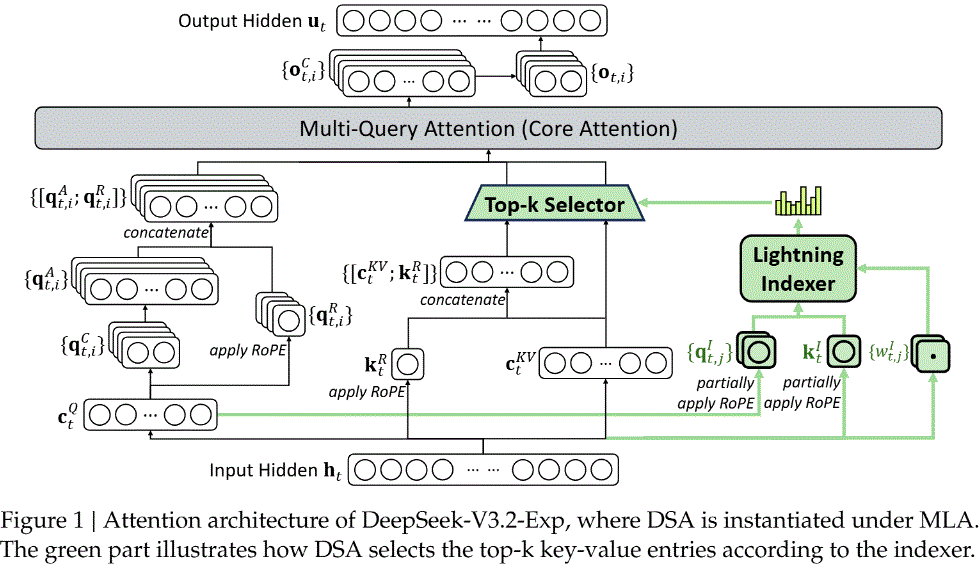
三、Token-wise原生稀疏Attention
目前以DSA为代表,由于直接是token粒度重要性表示,因此可实现较高的稀疏率(每次检索2K tokens);并可与MLA结合,同时实现序列维度与head-dim维度的压缩,显著降低32K以上长序列甚至1M以上超长序列的推理开销。典型效果:大EP场景,相同BS,3.5K+1K序列,MLA在decode阶段访存开销占比超过10%;64K+1K序列,DSA在decode阶段访存开销占比约6%。
DSA的优势在于固定召回2K序列,随着序列长度增加,能够维持较高的稀疏率;然而固定2K范围的token-wise信息检索(会越来越狭窄),也容易丢失关键信息,影响Attention recall,尤其是Agent等多轮推理、需要持续记忆增强的大模型应用场景。
四、What's the future?
基于SOTA稀疏Attention算法(如表格所示),推测未来原生稀疏Attention可能具备以下特点:
- Block-wise稀疏:主要结合GQA使用,随着序列长度的增加,Top-K召回检索的访存较为连续,block size可选为64、128或256;
- Layer-wise/head-wise稀疏率:不同layer或head分配不同稀疏率,自适应Attention recall,精度更加可控,且整网维持固定稀疏率(如50%);
- 混合架构:多种稀疏模式(如StreamingLLM)、以及Full Attention构建混合架构;等等
|
典型算法 |
稀疏方式 |
简要描述 |
精度效果 |
性能优化诉求 |
|
DSA (DeepSeek) (2025/9/29) |
•LLM •Tokenwise稀疏 |
•在模型中引入一个轻量级可训练的 Lightning Indexer,负责为每个 Query Token 动态地选取 Top-K 个最相关的 Key |
由于没有抛弃KV,只是选择重要KV进行计算,在不同等级KV budget下精度都大幅优于H2O等其他稀疏算法 |
•KV序列采样(minmax) •计算importance score •Topk •根据topk索引gather数据块 |
|
NSA (DeepSeek) (2025/2/16) |
•LLM •Blockwise稀疏 |
•采用了一种动态分层稀疏策略,将粗粒度 token 压缩与细粒度 token 选择相结合,compress、select、sliding window三阶段压缩算子计算量和访存量,同时保持全局上下文感知和局部精确性 |
在通用基准测试、长上下文任务和基于指令的推理任务中,NSA预训练的模型表现与全注意力模型相当或更优;在 64k长度序列上相较于全注意力实现了显著加速 |
•计算importance score •Topk •根据topk索引gather数据块 |
|
FlexPrefill (北京大学) (2025/2/28) |
•LLM •Blockwise稀疏 |
•通过查询感知稀疏模式确定(基于 Jensen-Shannon 散度切换模式)和基于累积注意力的索引选择(动态选索引满足注意力分数阈值),动态调整稀疏模式 |
512k 上下文长度下较 FlashAttention 最高提速 8.0 倍,同时在 RULER 基准以及InfiniteBench 检索任务中精度接近全注意力 |
•Token序列下采样 •计算importance score •Topk •根据topk索引gather数据块 |
|
MOBA (kimi) (2025/2/18) |
•LLM •Blockwise稀疏 |
•通过将上下文划分为block,并采用可学习的top-k 门控机制为每个查询 query 动态选择历史最相关的key和value block |
各种长上下文基准测试中表现出色,包括大海捞针和RULER,取得和全注意力相同效果; 与全注意力相比,100万上下文长度实现了6.5倍的速度提升 |
•Token序列下采样 •计算importance score •Topk •根据topk索引gather数据块 |
|
Spargeattn (清华大学) (2025/2/25) |
•LLM •动态 Blockwise稀疏 |
•先基于avgpool计算块注意力分数以及块内的自相似性来预测块稀疏掩码以跳过部分QK运算,再利用在线 softmax 的全局与局部最大值差异进一步省略PV计算 |
可适配语言(Llama3.1)、图像(Stable-Diffusion3.5、Flux)、视频(CogvideoX、Mochi)生成模型,相比传统全注意力,加速倍数普遍在 1.83 倍至 5 倍之间 |
•Token序列下采样 •Token序列维度重排 •计算importance score |
|
MInference (Microsoft) (2024/7/2) |
•LLM •半动态Blockwise稀疏 |
•通过识别长上下文注意力矩阵中 A 形、垂直斜线、块状稀疏三种独特模式,离线为每个注意力头确定最优模式,推理时动态构建稀疏索引 |
•稀疏mask的在线访存 •需要完整LSE的缓存,在线计算需要 •计算importance score •Topk |
|
|
XAttention (清华大学) (2025/5/20) |
•LLM •动态Blockwise稀疏 |
•利用“反对角线值的和” 作为块的重要性指标,通过对每个块的反对角线求和结果做 Softmax 归一化,得到概率分布,并筛选出概率和≥给定阈值 的最小块集合 |
在长上下文 Transformer 模型(处理长文本、长视频等)中,保持与全注意力接近甚至更优的精度,同时实现最高 13.5 倍的注意力加速 |
•Token序列维度重排 •Token序列下采样(avg) •计算importance score •Topk •稀疏mask的在线访存 |

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)