
万卡集群训练任务挂了?别慌,这本秘籍帮你解决!
摘要
大规模AI集群运行过程中频繁因为各类硬件、软件故障导致训练任务中断,如何快速发现故障、缩短故障恢复时间MTTR成为提高AI集群可用度的重点方向。本文汇总了昇腾断点续训特性提供的故障检测、故障恢复能力以及面临的问题和挑战。
1、背景介绍
大规模AI集群运行过程中频繁因为各类硬件、软件故障导致训练任务中断,如何快速发现故障、缩短故障恢复时间MTTR成为提高AI集群可用度的重点方向。本文汇总了昇腾断点续训特性提供的故障检测、故障恢复能力以及面临的问题和挑战,欢迎大家讨论。
2、解决方案
2.1)故障检测
及时、准确的故障检测能力是训练任务故障快速恢复的前提,如下图所示,目前提供的AI集群故障检测能力包括:
① NPU芯片故障监控
通过MindX Ascend Device-Plugin组件监控NPU芯片故障以及NPU直出的ROCE网口故障,其中NPU芯片故障包含了由NPU驱动提供的100+故障码(类似XID),ROCE网口故障包括网口Link状态、网络联通性检测结果。
② 计算节点&操作系统故障监控
通过MindX NodeD组件监控计算节点状态,目前针对服务器宕机、OS挂死类的故障提供了心跳检测机制,同时从服务器BMC获取整机硬件包括CPU、内存、硬盘、电源等部件的故障信息作为补充。
③ HCCS网络故障监控(A3产品)
HCCS网络分为L1/L2两层组网,其中L1-HCCS打通了从计算节点主机侧进行故障监控的能力,由Device-Plugin负责获取L1-HCCS故障信息,同时L1/L2-HCCS均提供了标准的北向管理能力,对接NCE网管,再统一被CCAE纳管。
④ 网络故障监控
NPU ROCE网络(参数面)、业务面网络、存储面网络的交换机设备故障监控由NCE负责,再统一被CCAE纳管。
⑤ 存储故障监控
存储设备故障监控通过DM直接被CCAE纳管。
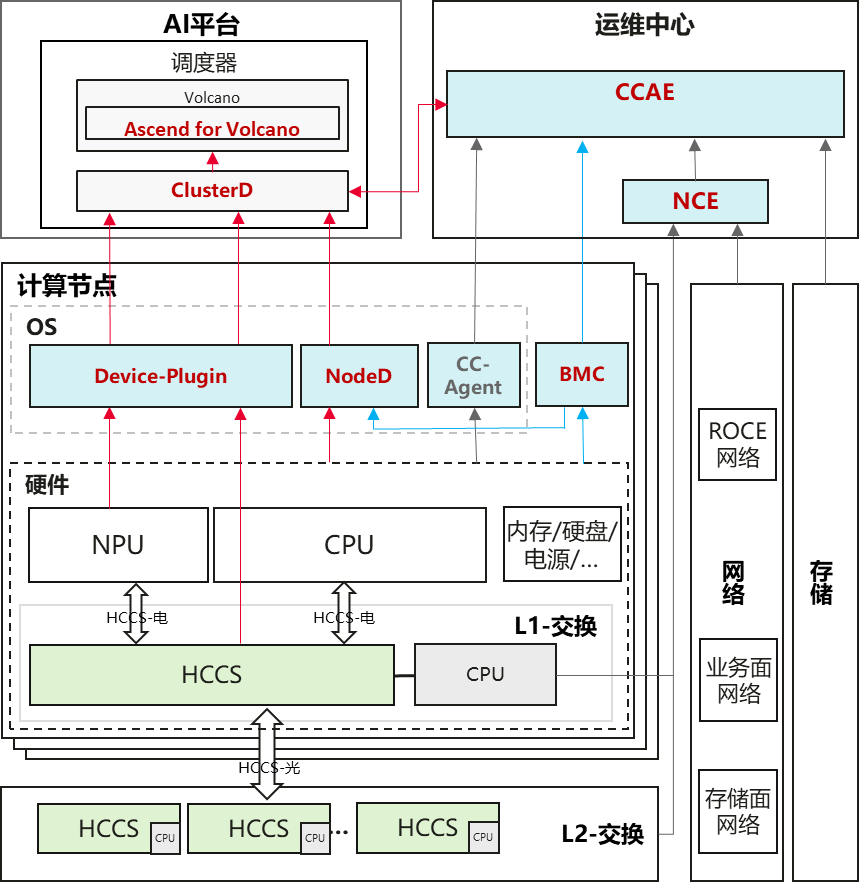
通过Device-Plugin、NodeD、BMC、CCAE、NCE监控到的故障信息统一汇聚到MindX ClusterD组件,由ClusterD根据不同故障信息综合识别故障点以及受影响的资源,生成故障恢复策略,通知AI平台调度器执行故障恢复操作。(注:当前CCAE通知故障信息给ClusterD的通道暂未提供)
2.2)故障恢复
基于故障检测的结果如何快速恢复训练任务?断点续训特性提供了如下图所示的分层分级快速恢复能力:
① 作业级快速恢复
销毁所有的Pod、训练进程,隔离故障节点并重新调度训练资源,整个训练任务作业重新拉起。
② Pod级快速恢复
仅销毁故障节点对应的Pod、调度到新的节点上重建,重启所有训练进程,相比于作业级快速恢复会减少部分资源调度、Pod创建的时间。
③ 进程级快速恢复
针对故障节点可以原地恢复的场景,保留所有Pod,重启所有训练进程,进一步减少Pod创建耗时。
④ 进程级重调度恢复
仅销毁故障节点对应的Pod、调度到新的节点上重建;正常节点清理NPU训练状态、但保留训练进程、等待新节点加入;各节点重建集合通信,利用Ranktable免协商建链;正常节点通过参数面网络将临终CKPT传递到备用节点上,完成参数状态恢复后继续训练。
相比于进程级快速恢复,该层能力仅重调度故障进程,减少了大量进程间不同步的等待耗时,同时利用了新的HCCL建链方案大大降低了建链耗时,且通过NPU卡间的参数面高速网络P2P传递CKPT信息,避免了CKPT保存和加载的耗时。
⑤ 进程级在线恢复
针对NPU HBM UCE故障,通过业务面CANN软件、框架软件、MindX软件配合实现HBM故障地址在线修复,故障节点对应的训练进程不退出,重新执行当前训练Step(临终CKPT),无需回滚到周期CKPT恢复,训练任务秒级恢复。
⑥ 算子级在线恢复
针对A3产品NPU HCCS网络、A2/A3产品NPU ROCE参数面网络提供HCCL算子重试能力,容忍更长时间的网络异常,训练任务不中断。
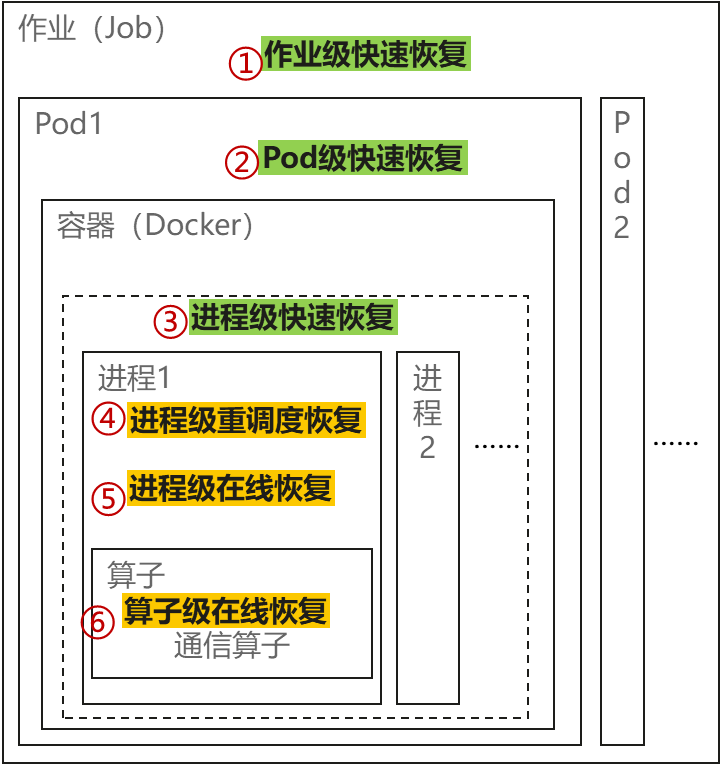
上述不同恢复能力通过状态机控制,可以逐层兜底,尽可能确保训练任务快速恢复。
3、问题和讨论
断点续训的故障检测和恢复能力并不是一蹴而就的,是基于技术成熟度和现网应用效果不断持续演进的结果,不同层级容错能力涉及的关键技术点也可以相互组合使用,整体来看可以通过“恢复时间、适用故障场景、易用性(企业集成使用的难易程度)、资源依赖”4个维度衡量竞争力和客户价值,如下表所示。
|
特性名称 |
说明 |
恢复时间 |
适用故障场景 |
资源依赖程度 |
易用性 |
适用CKPT |
|
人工恢复 |
人工拉起,训练任务重调度 |
小时级别 |
全,全局性故障 | NPU其他故障 | 节点/框/局部网络故障 |
高,冗余节点恢复 |
低 |
周期性CKPT |
|
①作业级快速恢复 |
训练任务重调度 |
十到几十分钟级别 |
中,原地恢复 | 冗余节点恢复 |
低 |
周期性CKPT | 临终CKPT |
|
|
②Pod级快速恢复 |
故障容器重调度 |
小于十分钟 |
中,NPU其他故障 | 节点/框/局部网络故障 |
|||
|
③进程级快速恢复 |
所有进程重试 |
小于十分钟 |
||||
|
④进程级重调度恢复 |
故障进程重试 |
小于五分钟 |
中 |
|||
|
⑤进程级在线恢复 |
故障进程不退出 |
分钟级 |
不全,NPU HBM UCE故障 |
低,原地恢复 |
临终CKPT |
|
|
⑥算子级在线恢复 |
故障进程不退出 |
分钟级 |
不全,通信算子故障 |
低,原地恢复 |
高 |
不依赖CKPT |
面向未来十万卡以及更大规模集群的训练任务,断点续训需要持续改进,目前识别和规划的改进方向如下:
- 硬件CPU/NPU静默故障检测&容错,提高断点续训故障模式覆盖率,尽可能避免人工介入恢复;
- 慢节点慢网络等亚健康故障检测&容错,通过CCAE、BMC等组件提供亚健康诊断能力,触发断点续训;
- 软件故障快速诊断&容错,通过报错日志或者配合故障诊断功能快速识别可以恢复的故障模式,触发断点续训;
- 故障恢复时间的进一步压缩,包括容器镜像快照恢复、热备/温备快速无感切换等。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 25
25 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)