
如何定义大模型压缩技术?
摘要:随着大模型规模扩展和多模态应用发展,模型压缩技术面临新挑战。传统深度学习时代采用量化、剪枝等技术压缩10M-100M级模型,而大模型时代需针对LLM推理特性(Prefill计算密集、Decode访存密集)发展新型压缩方法。当前关键技术包括:1)权重量化(AWQ、GPTQ)降低访存开销;2)KVCache压缩(RazorAttention、KVQuant)优化序列处理;3)稀疏化技术(Spar
摘要
随着大模型日益发展,包括参数规模与序列长度不断扩展,以及多模态、Agent等新场景应用的驱动,单双机与大EP等部署形态推陈出新,大模型推理也面临新的性能瓶颈,因此对大模型压缩技术提出了新的需求与挑战。
一、深度学习时代模型压缩
深度学习时代,模型参数规模在10M~100M量级,典型模型如ResNet50、BERT-base等,推理部署形态通常为单卡部署一个或多个模型,模型压缩的主要作用在于减小模型体积与计算量:
| 压缩技术 | 简要说明 |
| 量化 | 由于模型参数规模小,通常为W8A8/W4A4量化 |
| 结构剪枝 | 通常为channel-wise/layer-wise裁剪,如Taylor-prunning、DynaBERT |
| 低秩分解 | 如对权重进行SVD分解 |
| 半结构稀疏 | 如2:4稀疏、block-wise稀疏,通常对权重进行稀疏化 |
| 知识蒸馏 | 教师模型输出作为ground truth,诱导小模型训练 |
二、大模型时代关键压缩技术
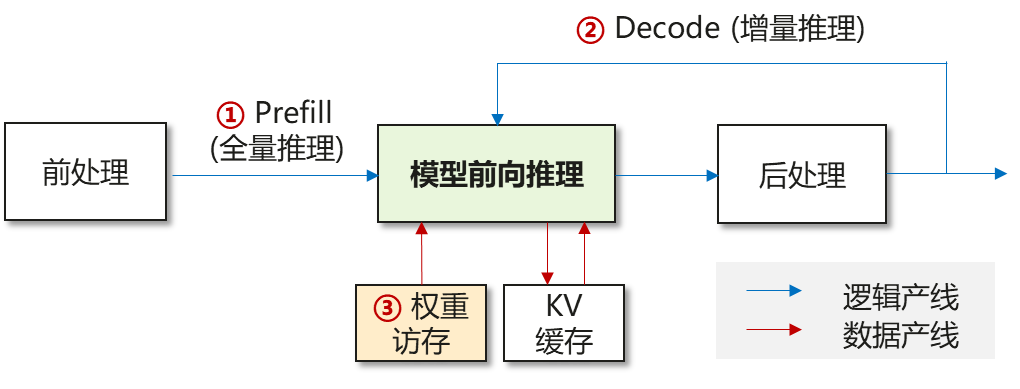
以LLM语言大模型为例,推理瓶颈主要体现在Prefill(扩散生成也表现为并行计算)、Decode与权重访存:
|
推理阶段 |
简要说明 |
|
① Prefill |
1. 计算密集型,包括Linear Matmul与Attention计算 2. 随序列增加,计算量急剧上升 |
|
② Decode |
1. Token by token解码 2. 访存密集型,包括权重与KV Cache访存 3. 短序列场景,权重占主导;长序列场景,KV Cache占主导 |
|
③ 权重访存 |
1. 大模型权重访存引起的推理开销,在Prefill与Decode阶段,都有影响 |
由于大模型推理范式/部署形态与深度学习模型有着本质区别,如LLM自回归范式、DiT扩散范式、以及分布式并行等集群系统架构,因此大模型压缩需要拥抱新的应用需求、并直面新的技术挑战。可定义如下大模型压缩关键技术与分类标准,作用于大模型推理的不同阶段(以LLM为例),针对性缓解推理性能瓶颈:
|
压缩技术 |
分类标准 |
推理阶段 |
简要说明 |
|
量化压缩 |
权重量化 |
权重访存 |
降低线性层的权重搬运开销,如AWQ、GPTQ、Qserve,以及极低比特量化(如BiLLM、BitNet)等 |
|
权重激活量化 |
Prefill/权重访存 |
使能线性层的低比特矩阵乘,如Outlier Suppression+、DartQuant、LLM.int8等 |
|
|
激活量化 |
Prefill/Decode |
QKV激活、通信激活量化,如KVTuner、FA3、SageAttention、通信FP8量化等 |
|
|
VQ量化 |
权重访存/Decode |
基于codebook,等效实现低比特量化,如PQCache、AQLM、VQ-LLM、CQ等 |
|
|
KV Cache 压缩 |
序列维度 |
Decode |
基于Attention稀疏性,丢弃KV或稀疏检索,降低KV Cache访存开销,如RazorAttention、FreeKV |
|
特征维度 |
Decode |
通过特征降维,实现KV Cache压缩,如Palu、MLA、MFA |
|
|
层维度 |
Decode |
层间KV Cache共享,减少KV Cache容量,如miniCache |
|
|
Head维度 |
Decode |
通过Head共享,压缩KV Heads,如GQA、MQA |
|
|
数值维度 |
Decode |
KV Cache低比特量化,如KVQuant、KIVI |
|
|
稀疏压缩 |
权重稀疏 |
Prefill/权重访存 |
静态稀疏化压缩,包括结构剪枝、半结构稀疏、非结构稀疏,如SparseGPT、Wanda、LLM-pruner |
|
激活稀疏 |
Prefill |
对激活实施动态稀疏化,包括半结构稀疏、块稀疏等 |
|
|
权重激活稀疏 |
Prefill/权重访存 |
对权重激活同时实施稀疏化 |
|
|
Attention稀疏 |
Prefill |
基于Attention稀疏性,降低Attention计算开销,如RainFusion、AdaSpa |
|
|
数据压缩 |
无损压缩 |
权重访存/Decode |
包括熵编码、游程编码、算术编码等 |
|
有损压缩 |
权重访存/Decode |
包括浮点数尾数裁剪、低比特近似(Spark、Olive)等 |
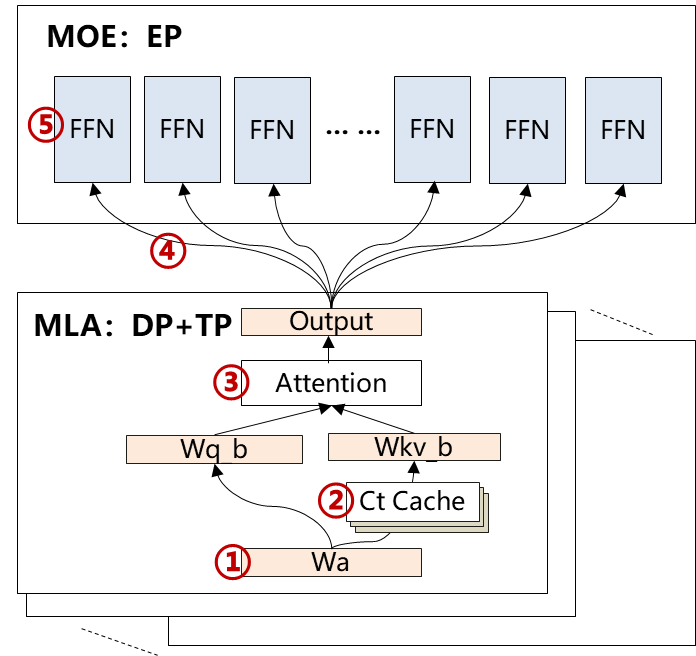
以DeepSeek-V3/R1大模型以及大EP部署为例,推理系统涉及计算、访存与通信瓶颈,大模型压缩技术可有效缓解性能瓶颈、发挥关键作用:
|
推理瓶颈 |
简要说明 |
关键压缩技术 |
|
① ⑤ 计算/访存瓶颈 |
1.权重搬运开销 2.大Batch计算bound |
量化压缩、稀疏压缩、数据压缩 |
|
② 访存瓶颈 |
长序列或大Batch,KV Cache开销 |
KV Cache压缩、稀疏压缩、数据压缩 |
|
③ 计算瓶颈 |
长序列或大Batch,Attention计算开销 |
KV Cache压缩、量化压缩、稀疏压缩 |
|
④ 通信瓶颈 |
通信带宽受限、或通信imbalance,拖尾性能 |
量化压缩、数据压缩 |

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)