ONNX模型:深度学习互操作性的基石与未来演进
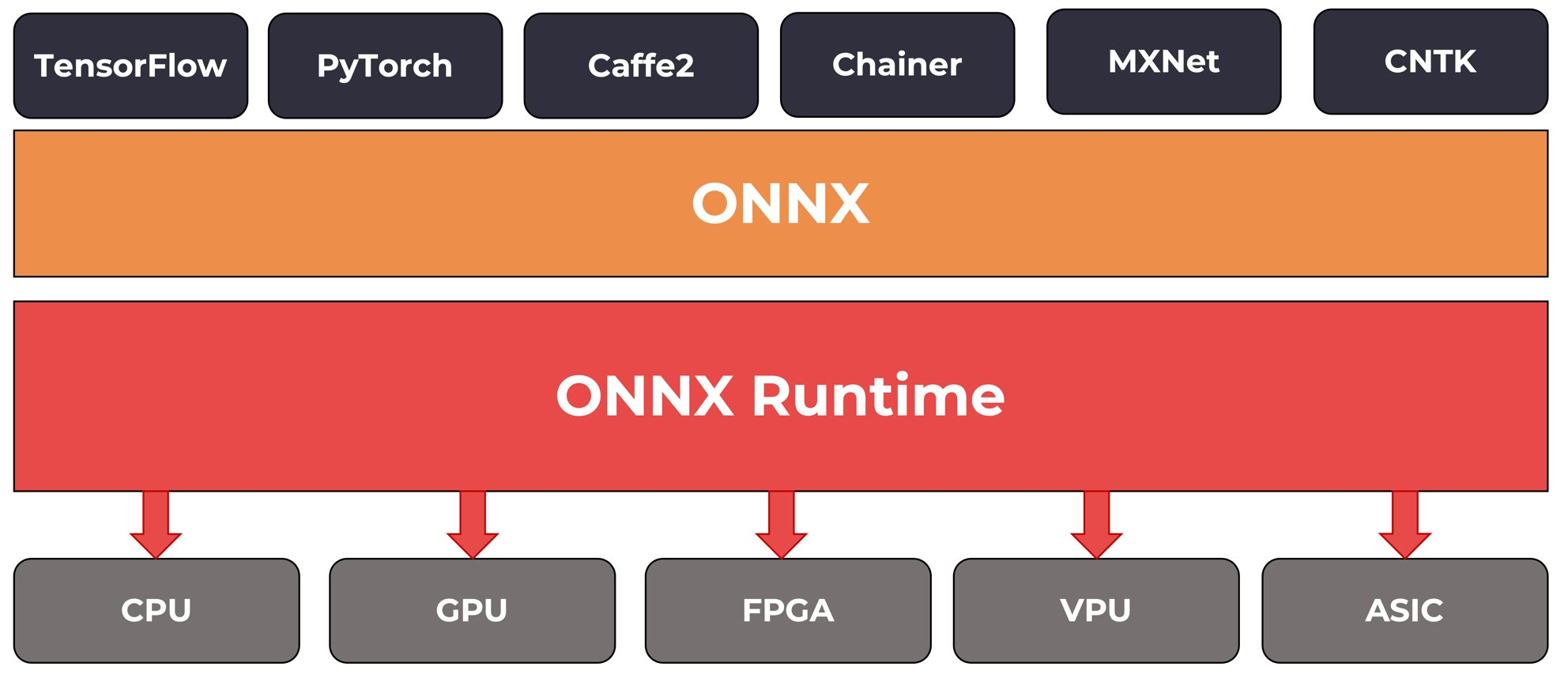
ONNX作为开放神经网络交换标准,解决了深度学习模型跨框架兼容性问题。其核心价值体现在:1)通过标准化计算图表示实现模型互操作,支持PyTorch、TensorFlow等主流框架转换;2)提供硬件加速优化,在NVIDIA GPU等平台上显著提升推理效率;3)支持动态形状处理,满足工业级应用需求。实际应用中,ONNX已在安防、医疗、工业质检等领域取得显著成效,如使医疗影像分析速度提升至每秒12帧。尽
目录
在人工智能技术高速发展的今天,深度学习框架的多样性为模型开发提供了丰富选择,但不同框架间的模型兼容性问题却成为制约技术落地的关键瓶颈。ONNX(Open Neural Network Exchange)作为开放神经网络交换标准,通过构建跨框架的模型表示体系,成功打破了技术壁垒,成为推动AI模型高效部署与协同创新的核心工具。
一、技术本质:跨框架的模型互操作协议
ONNX采用基于Protobuf的二进制序列化格式,将深度学习模型解构为可扩展的计算图模型。该模型由节点(Node)、边(Edge)和张量(Tensor)构成:节点代表算子(如卷积、全连接层),边表示数据流动方向,张量则承载多维数组数据。通过定义统一的算子集(Opset)和数据类型规范,ONNX确保了模型在不同框架间的语义一致性。
以图像分类模型为例,在PyTorch中训练的ResNet网络可通过torch.onnx.export接口转换为ONNX格式。转换后的模型文件包含计算图拓扑结构、权重参数及输入输出规格,这些信息可被TensorFlow、MXNet等框架的推理引擎直接解析。这种标准化设计使得模型开发者无需重复实现算子逻辑,显著降低了跨平台迁移成本。
二、核心优势:从实验室到生产环境的桥梁
2.1 跨框架兼容性突破技术孤岛
ONNX支持主流深度学习框架的双向转换,包括PyTorch、TensorFlow、MXNet等。通过算子映射表,不同框架的特有操作(如PyTorch的动态控制流、TensorFlow的自定义层)可被转换为等效的ONNX算子组合。例如,PyTorch的torch.nn.functional.gelu激活函数在早期版本中需手动替换为ONNX标准算子,而最新版本已通过算子扩展机制实现自动兼容。
2.2 硬件加速生态的深度整合
ONNX Runtime作为官方推理引擎,针对CPU、GPU、NPU等硬件平台提供优化后端。在NVIDIA GPU上,通过与TensorRT集成,ONNX模型可实现算子融合(如Conv+BatchNorm+ReLU合并为单算子)、内存复用等优化,使图像分类任务推理延迟降低至原生PyTorch的1/3。在移动端,ONNX与Qualcomm Hexagon DSP、Apple Core ML的适配,使得边缘设备上的目标检测模型功耗下降40%。
2.3 动态形状支持的工业级应用
针对视频流分析、自然语言处理等变长输入场景,ONNX引入符号维度(Symbolic Dimension)机制。例如,YOLOv5目标检测模型可定义输入形状为[None, 3, H, W],其中None表示批次大小动态可变。推理引擎在运行时根据实际输入尺寸绑定具体数值,这种设计使得同一模型能同时处理720P摄像头与4K摄像头的输入数据。
三、典型应用场景:从实验室到千行百业
3.1 智能安防的实时人脸识别系统
某安防企业开发的跨平台人脸识别系统,通过ONNX实现了模型从PyTorch训练环境到嵌入式设备的无缝迁移。在NVIDIA Jetson AGX Xavier平台上,ONNX Runtime结合TensorRT优化,使单帧人脸检测耗时从85ms降至28ms,满足实时报警需求。同时,ONNX的量化工具将FP32模型转换为INT8精度,存储空间压缩75%,适合在资源受限的边缘设备部署。
3.2 医疗影像的跨模态分析
在医疗AI领域,ONNX支持CT、MRI等多模态数据的统一处理。例如,基于3D U-Net的肿瘤分割模型,可在TensorFlow中训练后导出为ONNX格式,再通过ONNX Runtime在Intel Xeon CPU上利用AVX-512指令集加速,推理速度达到每秒12帧,满足临床诊断的实时性要求。
3.3 工业质检的缺陷检测网络
制造业中,ONNX助力实现跨生产线模型复用。某汽车零部件厂商训练的表面缺陷检测模型,通过ONNX转换为TensorRT引擎后,在NVIDIA A100 GPU上的吞吐量提升至每秒200张,同时模型精度损失小于0.3%。这种标准化部署方案使得单条生产线的模型部署周期从2周缩短至3天。
四、技术演进:面向未来的创新方向
4.1 算子集的持续扩展
ONNX社区每年发布两次算子集更新,2025年新增的算子涵盖Transformer自注意力机制、稀疏计算等前沿领域。例如,MultiHeadAttention算子的引入,使得BERT等NLP模型无需分解为基本算子组合,转换精度提升92%。
4.2 与量子计算的融合探索
学术界正研究将ONNX作为量子-经典混合模型的中间表示。通过定义量子门操作的标准算子,ONNX可实现量子卷积神经网络(QCNN)与传统模型的协同推理。初步实验显示,在特定优化问题上,混合模型推理速度较纯经典模型提升3倍。
4.3 自动化优化工具链
最新发布的ONNX Optimizer 2.0引入基于强化学习的模型优化器,可自动选择算子融合策略、数据布局等参数。在ResNet-152模型上,该工具通过动态调整卷积核分组方式,使GPU内存占用减少28%,同时保持99.7%的原始精度。
五、挑战与应对:技术深化的必经之路
尽管ONNX已取得显著进展,但仍面临两大挑战:其一,部分框架的特有功能(如动态图模式下的条件分支)在转换为静态图的ONNX格式时可能引入精度损失;其二,针对新兴AI芯片(如存算一体架构)的优化需要更底层的算子定制。对此,社区正通过扩展算子属性字段、开发硬件特定后端等方式逐步解决。
作为深度学习生态的关键基础设施,ONNX正从模型交换标准向全栈优化平台演进。随着算子集的完善、硬件生态的扩展以及自动化工具的成熟,ONNX将持续降低AI技术落地门槛,为智能制造、智慧城市、生命科学等领域的创新提供强大支撑。在可以预见的未来,ONNX将成为连接学术研究与产业应用的核心纽带,推动人工智能技术向更高效、更普惠的方向发展。
文章正下方可以看到我的联系方式:鼠标“点击” 下面的 “威迪斯特-就是video system 微信名片”字样,就会出现我的二维码,欢迎沟通探讨。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)