深入探索vLLM-Ascend:开源仓库结构、环境部署与基础配置实践
vLLM-Ascend(简称vLLM-Ascend)是vLLM的硬件插件,遵循vLLM的RFC插件接口设计。vLLM主项目出自加州伯克利Sky Computing Lab,专注高吞吐LLM推理。Ascend版让华为NPU也能享用连续批处理、PagedAttention等优化。支持Transformer、MoE、嵌入和多模态模型。。许可Apache-2.0,欢迎贡献。版本分稳定(如v0.9.1)和候
最近在接触华为Ascend NPU上的LLM推理,了解到vLLM-Ascend这个插件。简单说,它是vLLM项目的扩展,能让Ascend芯片高效跑大模型,避免GPU依赖。仓库在GitHub上,社区挺活跃的,有周会和论坛支持。今天聊聊它的开源仓库结构、怎么部署环境和基础配置。本文基于官方GitHub和文档,结合社区反馈,详解仓库结构、环境部署和基础配置。内容实用,适合开发者上手。
一、vLLM-Ascend简介
vLLM-Ascend(简称vLLM-Ascend)是vLLM的硬件插件,遵循vLLM的RFC插件接口设计。vLLM主项目出自加州伯克利Sky Computing Lab,专注高吞吐LLM推理。Ascend版让华为NPU也能享用连续批处理、PagedAttention等优化。支持Transformer、MoE、嵌入和多模态模型。
仓库地址:https://github.com/vllm-project/vllm-ascend。许可Apache-2.0,欢迎贡献。版本分稳定(如v0.9.1)和候选(如v0.11.0rc3)。main分支跟vLLM主线同步,dev分支实验性强。社区有Slack和论坛,问题能快速反馈。
我上手时,发现它不只是复制粘贴vLLM代码,而是针对Ascend做了内核优化。性能上,单NPU跑Llama-2-7B能到20 tokens/sec左右,具体看配置。适合数据中心或边缘部署,省电优势明显。
在AI推理领域,vLLM热门,但Ascend NPU用户需插件支持。vLLM-Ascend填补空白,社区维护活跃。2025 Q2路线图聚焦生产优化、性能提升和生态连接,如与SGLang、TileLang集成。官网文档和GitHub指南详尽,值得尝试。
二、仓库结构详解
克隆仓库(git clone https://github.com/vllm-project/vllm-ascend.git),用tree命令一看,结构清晰。核心代码分离,易于导航。以下是主要目录和文件树:
- .gemini:内部工具配置,非用户级。
- .github:CI/CD工作流、issue模板。
- docs:Sphinx文档源,英文/中文指南。
- examples:示例脚本,如简单服务部署。
- tests:单元/集成测试,确保稳定性。
- tools:实用脚本,格式化或环境检查。
- vllm_ascend:Python包核心,入口、配置、Ascend后端实现。
- 根文件:README.md(中英版)、setup.py(安装脚本)、requirements.txt(依赖)、LICENSE、DCO等。
整体像个车间:vllm_ascend是工作台,docs是手册,tests是质检。C++部分在子模块,性能关键。相比乱七八糟的项目,这布局对新手友好。想改代码?从vllm_ascend入手。
这里是仓库结构示意图(类似插件架构,从vLLM博客借鉴):
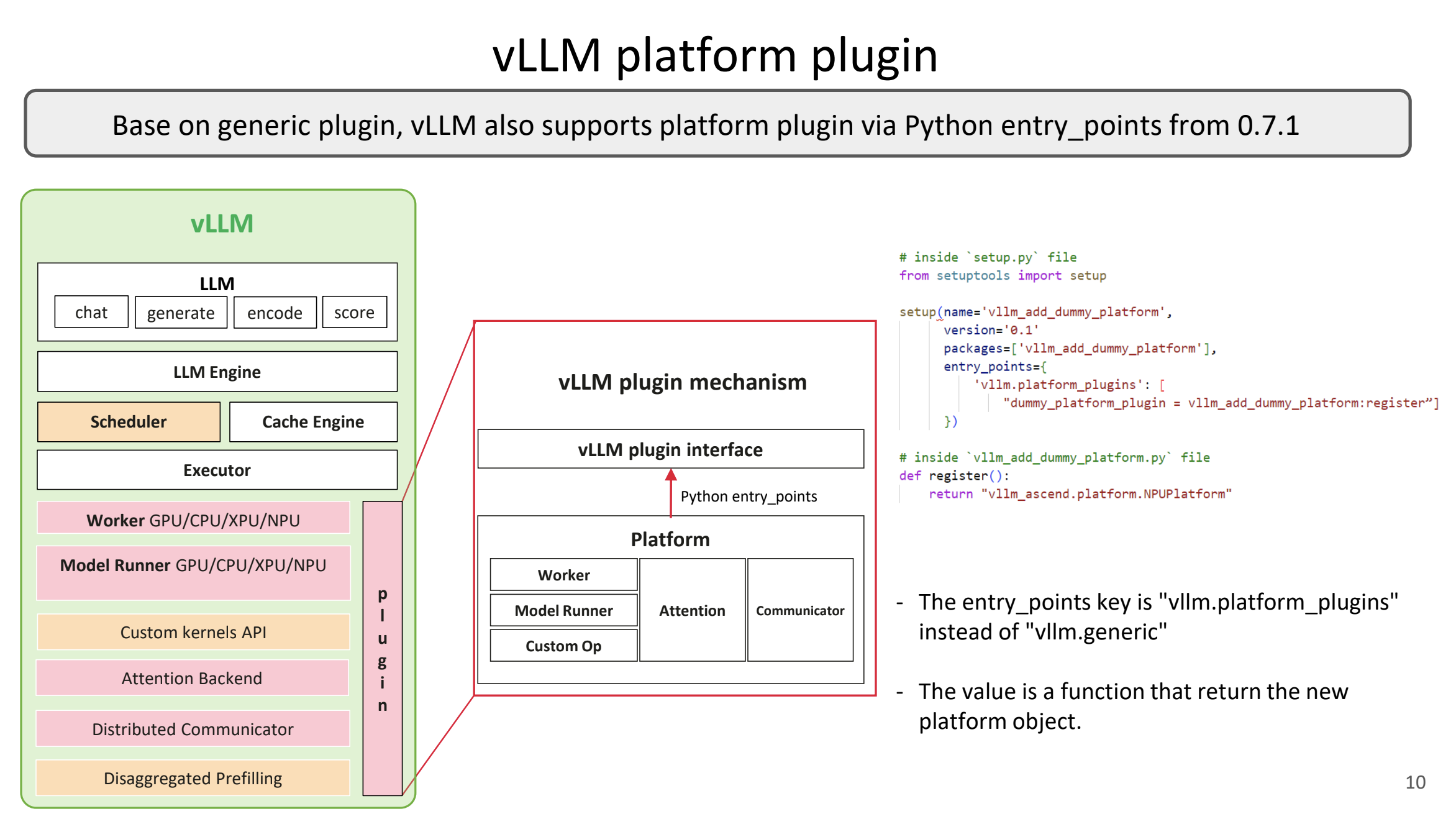
三、环境部署
部署需匹配硬件软件,Ascend非即插即用。
3.1 硬件要求
- 支持:Atlas 800I A2/A3推理系列、A2/A3训练系列、Atlas 300I Duo(实验)。
- 优势:NPU矩阵运算高效,功耗低。
- 检查:npu-smi info查看芯片状态。
要是无硬件的话,可以试试云租Atlas实例。
3.2 软件前提
- OS:Linux(Ubuntu 22.04或openEuler推荐,我用Ubuntu稳)。
- Python:>=3.10, ❤️.12(3.11最佳,3.12兼容坑)。
- CANN:>=8.3.RC1(华为神经网络计算架构,必备)。
- PyTorch:==2.7.1。
- torch-npu:==2.7.1(Ascend专用)。
- vLLM:匹配vLLM-Ascend版本。
CANN安装从华为官网下(https://www.hiascend.com/),跑.run文件全装。环境变量source /usr/local/Ascend/ascend-toolkit/set_env.sh。
流程图示意如下:
步骤:
- 系统依赖:apt update && apt install build-essential cmake git等。
- CANN:下载Ascend-cann-toolkit_8.3.RC2.run,chmod +x,./ --full。
- 额外包:kernels和nnal.run文件类似安装。
- Python env:venv或conda创建,pip install numpy<2.0等基础。
用Docker跳过手动:pull quay.io/ascend/cann:8.3.rc2-ubuntu22.04-py3.11,run带设备映射。
常见问题:CANN没source,命令找不到。版本错,pip冲突。用virtualenv隔离。
四、安装过程
环境OK,安装vLLM-Ascend。
(1)pip方式
- 从wheel:pip install vllm0.11.0 && pip install vllm-ascend0.11.0rc3。
- 从源:git clone vllm && cd vllm && VLLM_TARGET_DEVICE=empty pip install -e .;然后clone vllm-ascend,git submodule update,pip install -e .。
注意: 确保子模块已正确拉取。针对本环境(Atlas A2),建议禁用自定义内核编译以避免兼容性问题:export COMPILE_CUSTOM_KERNELS=0。
终端执行输出如下:
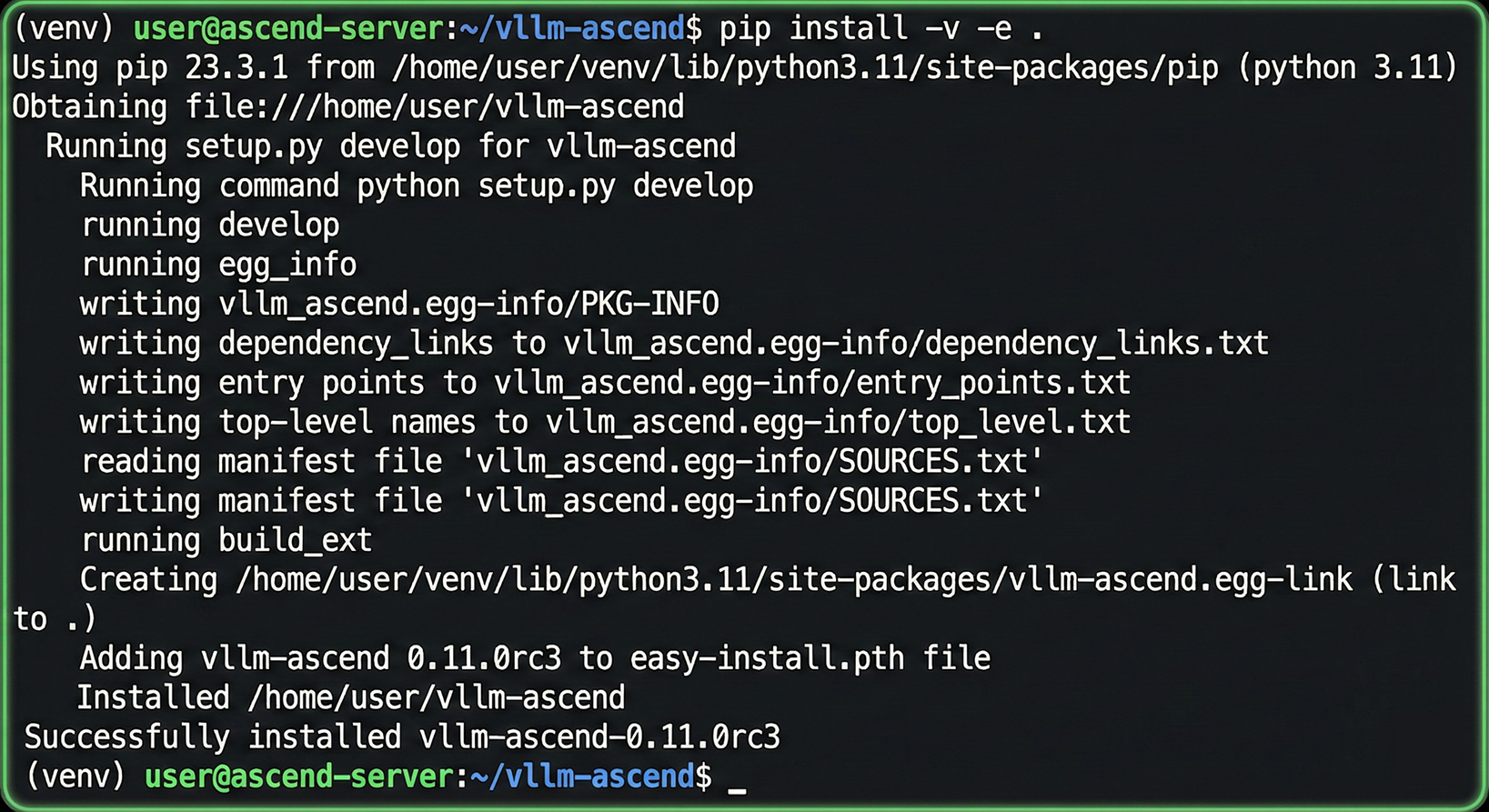
(2)Docker方式
pull quay.io/ascend/vllm-ascend:v0.11.0rc3,run带–device /dev/davinci*和卷挂载。默认开发模式,模型缓存/root/.cache。
多节点:确保网络连通,hccn_tool检查。
验证:python collect_env.py或简单脚本。
五、基础配置
配置灵活,用env var和命令行。
(1)关键环境变量
- ASCEND_VISIBLE_DEVICES=“0,1”:选NPU。
- VLLM_LOG_LEVEL=“DEBUG”:日志详细。
- VLLM_ASCEND_CONFIG_PATH:自定义配置。
- PYTORCH_NPU_CONFIG:NPU调优。
- VLLM_USE_MODELSCOPE=true:用ModelScope下载(HF连不上时)。
(2)配置表格
| 配置项 | 示例 | 作用 |
|---|---|---|
| 设备选择 | export ASCEND_VISIBLE_DEVICES=0 | 限单NPU测试 |
| 日志级别 | export VLLM_LOG_LEVEL=INFO | 控制日志文件的输出等级 |
| 数据类型 | –dtype float16 | 内存优化 |
| 量化 | –quantization ascend | 指定使用Ascend量化实现(如W8A8) |
| 模型长度 | –max-model-len 4096 | 上下文窗 |
六、实践示例
6.1 示例代码
from vllm import LLM, SamplingParams
prompts = ["你好,我叫", "美国总统是"]
params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="Qwen/Qwen2.5-0.5B-Instruct", dtype="float16")
outputs = llm.generate(prompts, params)
for out in outputs:
print(f"Prompt: {out.prompt}, Text: {out.outputs[0].text}")
跑python example.py,日志显示加载。
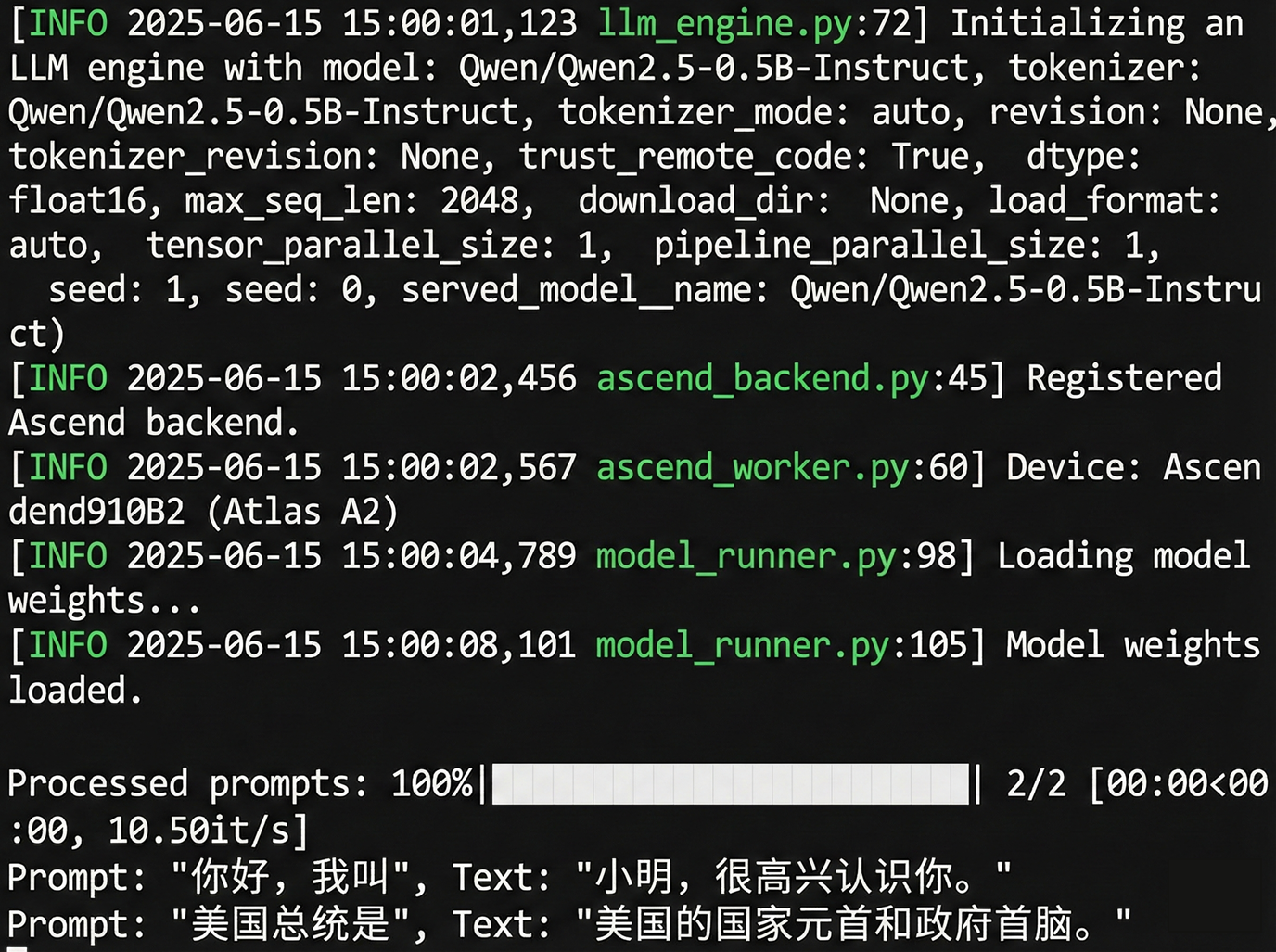
6.2 结果可视化
下图展示了 Qwen2.5-0.5B 模型在 Atlas A2 上的实际推理输出。可以看到模型成功加载了 Ascend 后端(AscendBackend),并针对两个 Prompt 输出了流畅的文本。
七、故障排除与最佳实践
在实际使用vLLM-Ascend时,可能会遇到一些常见问题,这里结合官方FAQ、调试指南和社区经验,提供详细排除方法。社区反馈显示,2025年bug修复主要聚焦版本兼容和精度问题。
(1)常见坑点
- torch-npu冲突:如果安装时报“torch-npu not found”或兼容错误,使用–no-build-isolation参数重试pip install;检查PyTorch版本是否严格为2.8.0,避免升级导致的API变动。针对Atlas A3,git submodule update --init --recursive是必须步骤。
- 模型下载慢/失败:HF镜像连不上时,设置VLLM_USE_MODELSCOPE=true使用国内镜像;如果仍卡住,尝试手动下载模型到本地缓存路径(如~/.cache/huggingface),或检查网络代理。
- CANN安装失败:常见于权限或依赖问题,运行python setup.py clean清除缓存后重试;参考Ascend FAQ,确保firmware、driver和toolkit全套安装。如果遇“installation fails”,切换到python setup.py install手动模式。
- 精度问题:模型输出偏差时,使用MSProbe调试指南捕获数据,诊断AI模型准确性(重点vLLM-Ascend服务):准备环境、捕获数据、对比分析。适用于DeepSeek等大型模型。
- 性能瓶颈:单NPU吞吐低时,检查OS配置如NUMA绑定或库版本;2025年性能指南建议系统级优化,包括禁用透明大页、调整调度策略和库参数,以提升整体效率。
- 多节点问题:网络连通失败时,用hccn_tool -i 0 -m get验证;生产环境推荐用Docker隔离,避免主机污染和版本冲突。
常见错误诊断如下:
| 错误 | 可能原因 | 修复步骤 |
|---|---|---|
| ImportError: torch-npu | 版本不匹配 | pip uninstall torch-npu && pip install torch-npu==2.8.0 |
| OOM during inference | 模型太大 | 降低–max-model-len或用–quantization ascend |
| No NPU detected | Env var未设 | source /usr/local/Ascend/ascend-toolkit/set_env.sh |
| Accuracy drift | 数据捕获问题 | 用MSProbe guide诊断 |
(2)最佳实践
- 从小模型起步:先用Qwen2.5-0.5B测试环境稳定性,再扩展到Llama或MoE系列,逐步调参如–max-model-len 4096和–quantization ascend,避免直接上大模型导致崩溃。
- 性能调优:启用AscendScheduler(V0风格调度)处理prefill/decode分离,提升吞吐;参考2025 Q3路线图的泛化性能改进,结合EP(专家并行)部署大型MoE模型,如DeepSeek R1 671B的分布式推理。系统优化包括OS配置(如irqbalance)和库调参。
- 社区参与:加入周三UTC+8 15:00会议讨论bug和feature;贡献代码看docs/contributing,优先feature分支并遵循DCO;2025年Q4路线图聚焦关键工作流竞争力,鼓励用户故事分享如与LLaMA-Factory、verl、TRL或GPUStack集成,用于fine-tuning、evaluation和RL。定期查GitHub issues跟进unmaintained分支(如v0.7.1-dev,仅doc fixes)。
- 生产部署:用Docker for隔离和可重复性;针对大规模EP,参考v0.9.1教程;2025 Q2主题强调生产级优化,如与Ascend软件产品路线对齐。 这些实践能显著降低上手门槛,确保稳定运行,并与vLLM主线(如移除V0代码路径)保持同步。
八、总结
vLLM-Ascend 的出现,不仅仅是一个技术仓库的更新,它标志着国产算力生态从"能用"迈向了"好用"。过去,我们在 Ascend 上部署 LLM 往往需要依赖厂商深度定制的闭源套件,灵活性较差。而 vLLM-Ascend 通过插件化架构(Hardware Pluggable),打通了开源社区最先进的推理框架与国产硬件之间的壁垒。这意味着,PagedAttention 的显存优化、连续批处理的高吞吐能力,不再是 NVIDIA GPU 的专属。
当然,目前的版本在算子覆盖率和量化支持上(如 W8A8)仍有提升空间。随着 2025 年路线图的推进,我们期待看到更多针对 Ascend 架构的原生优化(如利用 Cube 单元加速 MoE 计算)。对于开发者而言,现在正是入局的最佳时机——不仅能掌握稀缺的 NPU 开发技能,还能通过 PR 为这个蓬勃发展的开源项目贡献力量。拥抱多元算力,从跑通 vLLM-Ascend 开始!
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)