
NVIDIA迁移昇腾踩坑记:为何数据拷贝成了“背锅侠”?(附1.5s→0.7s优化复盘)
一、背景解读:从NVIDIA到昇腾的性能挑战
开发者在进行NLP文本分类业务迁移时,使用了一个基于 BERT-Base(或 DistilBERT)结构的轻量化 LLM 编码器模型。在 NVIDIA A10 环境下,单批次推理耗时仅为 1s。但当我们将环境切换至华为昇腾 300I Duo 推理卡(搭载 CANN 8.0 系列) 后,发现总耗时激增至 1.5s,其中 .to(cpu) 操作显得异常缓慢。
昇腾NPU基于Ascend芯片设计,专为AI计算优化,但与NVIDIA的CUDA生态不同,它使用CANN(Compute Architecture for Neural Networks)框架。这导致PyTorch在昇腾上的实现(通过torch_npu模块)需要适配NPU的计算范式。小模型(如轻量级Transformer或CNN变体)在NVIDIA上可能受益于成熟的优化(如cuDNN库),但在昇腾上,如果未进行针对性调优,可能会出现计算图不匹配、内存拷贝开销或算子编译延迟等问题。
这其实是很多开发者从N卡迁移到昇腾时最容易踩的坑。性能掉得莫名其妙,通常不外乎这三个原因:
- “水土不服”:NVIDIA GPU和昇腾NPU底层的计算逻辑不一样,昇腾的AICore特别依赖矩阵运算的优化,如果模型里的算子没有针对性适配,效率就会大打折扣。
- “翻译损耗”:PyTorch原生是亲CUDA的,在昇腾上跑需要经过
torch_npu这个适配层,版本稍微没对上(比如PyTorch 1.8配了新的CANN),就可能出现算子跑在CPU上的尴尬情况。 - “隐形搬运”:也就是我这次遇到的核心问题——数据在Device和Host之间的搬运管理。如果不刻意优化,CPU和NPU之间的同步等待会让性能显得非常难看。
二、调优流程详解:从问题定位到解决方案
2.1 初步定位问题
迁移后,推理结果默认存储在NPU上,需要额外.to(cpu)下发到CPU。开发者分别统计了推理耗时和 .to(cpu) 耗时,发现窗口显示.to(cpu)时间很长,因此初步认为下发算子耗时是主要原因。经过尝试异步传输等手段,发现效果不佳。
为了搞清楚到底是哪一步拖了后腿,我采用了最原始但有效的“分段计时法”。我在代码里打点了几个
time.time(),试图把推理时间和数据拷贝时间隔离开。理论上,.to(cpu)只是一个单纯的内存拷贝动作(Device to Host),除非Output的张量大得离谱(比如超大的Embedding),否则不应该成为瓶颈。但当时的日志数据着实骗了我一把。
在昇腾环境中,数据传输可以通过异步流(Stream)优化。例如,使用torch_npu.npu.Stream()创建流,并在流上执行拷贝:
import torch_npu
stream = torch_npu.npu.Stream()
with torch_npu.npu.stream(stream):
output = model(input) # 假设在NPU上推理
cpu_output = output.to('cpu', non_blocking=True) # 异步拷贝
stream.synchronize() # 同步等待
但提到异步等手段效果不佳,这可能是因为问题根源不在拷贝本身,而是上游计算的延迟导致同步等待。通用建议:使用nvprof(NVIDIA)或类似昇腾工具初步 profiling,避免盲目优化。
为什么初步定位容易出错?因为时间统计往往是壁钟时间(wall time),未考虑并发和依赖。如果推理未完成,.to(cpu)会阻塞,导致误判。
2.2 采集profile
为了进一步定位,文档建议采集profile数据。参考链接:Ascend PyTorch Profiler接口采集-CANN商用版8.1.RC1-昇腾社区。
具体操作:在训练或推理代码(如run.py或train.py)中添加torch_npu.profiler.profile接口。
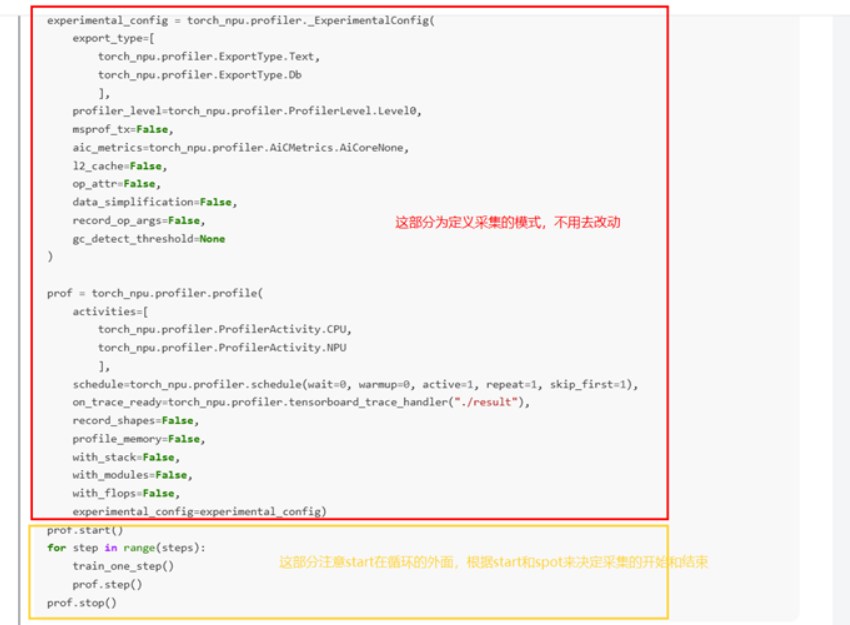
from torch_npu.profiler import profile, ProfileConfig
prof = profile(
activities=[ProfileConfig.CPU, ProfileConfig.NPU],
schedule=profile.schedule(wait=1, warmup=1, active=3, repeat=2),
on_trace_ready=profile.tensorboard_trace_handler('./profile_dir'),
record_shapes=True,
profile_memory=True,
with_stack=True
)
# 你的推理代码
prof.start()
input = ... # 输入数据
output = model(input)
prof.step() # 如果有循环
# ...
prof.stop()
注:如果采集不到数据,在step或stop前添加torch_npu.npu.synchronize()确保同步。如果仍无效,移除prof.step()(适用于单次循环场景)。
Profile采集是性能分析的核心工具。昇腾的Profiler基于Chrome Tracing格式,支持可视化CPU/NPU活动、内存使用和调用栈。图片示例强调了接口的使用,实际操作中,确保目录权限和CANN版本兼容。
2.3 分析数据
参考链接:简介-MindStudio8.0.RC1-昇腾社区。
操作:使用MindStudio工具导入采集数据(整体目录或chrome_tracing.json),查找异常或耗时长的算子。分析发现:.to(cpu)耗时很短;推理完成后虽打印时间,但实际推理仍在后台进行;.to(cpu)需等待推理完成,导致误判。
MindStudio是华为的IDE,支持可视化trace分析,如时间线视图、算子统计和内存热图。这一步揭示了初步定位的错误:时间统计未捕获异步计算的尾巴。
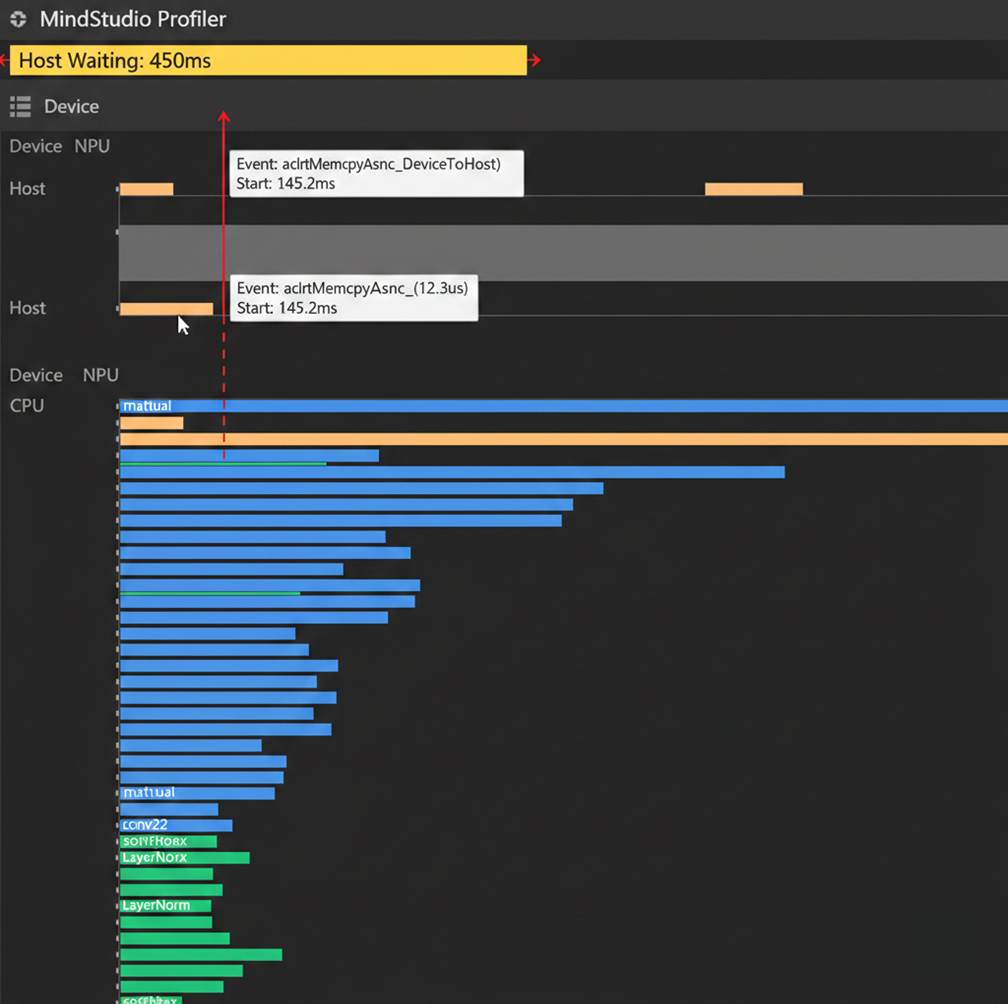
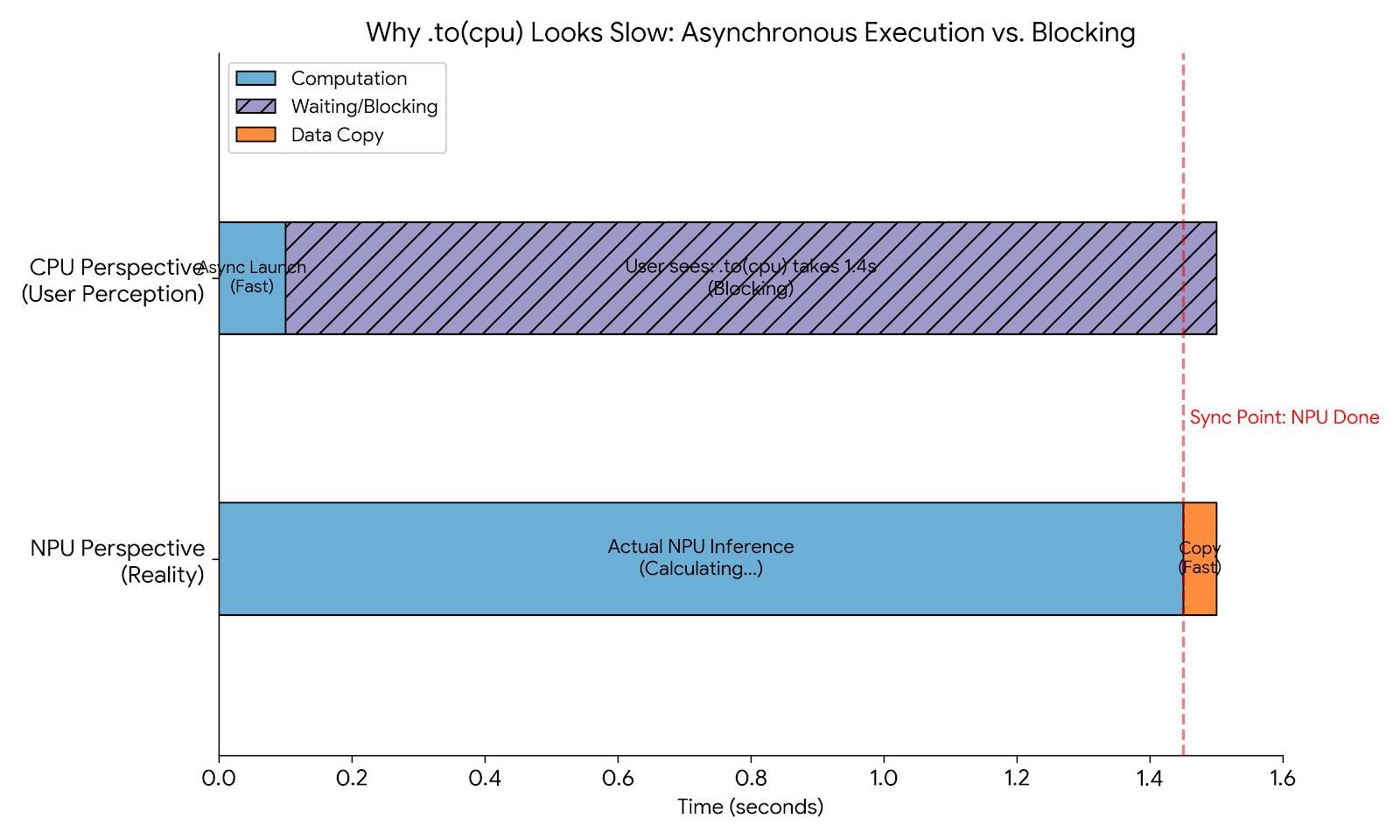
在上图中,我们可以清晰地观察到 CPU(Host)与 NPU(Device)之间的协作时序。橙色区域代表 .to(cpu) 发起的内存拷贝指令,而下方的 NPU 算子执行流(Task Stream)显示,在拷贝指令下达时,NPU 仍在执行前序的计算算子。
视图显示 .to(cpu) 的实际物理耗时(图中窄条部分)极短,但其前面的“空白等待区”很长。这量化地证明了 CPU 产生的 1.5s 阻塞,本质上是在等待 NPU 完成最后一组计算任务。所谓的“拷贝慢”,其实是由于异步机制导致的计算延迟长尾效应。
2.4 完整定位原因
通过分析,整体耗时增加的真正原因是推理耗时的延长,而非.to(cpu)。
这是一个经典的“表象 vs 根因”案例。初步统计误导开发者,但profile数据提供了证据链。扩展:性能调优的“Pareto原则”——80%瓶颈来自20%代码。针对昇腾,小模型推理慢可能因:
- 算子融合不足(NPU优化不如GPU)。
- 动态形状导致重编译。
- 版本问题(旧CANN缺少小模型支持)。
通用方法:使用A/B测试对比NVIDIA和昇腾的trace,量化差异。
2.5 针对原因定制解决方案
既然问题是推理耗时增加,文档提供两种方案:
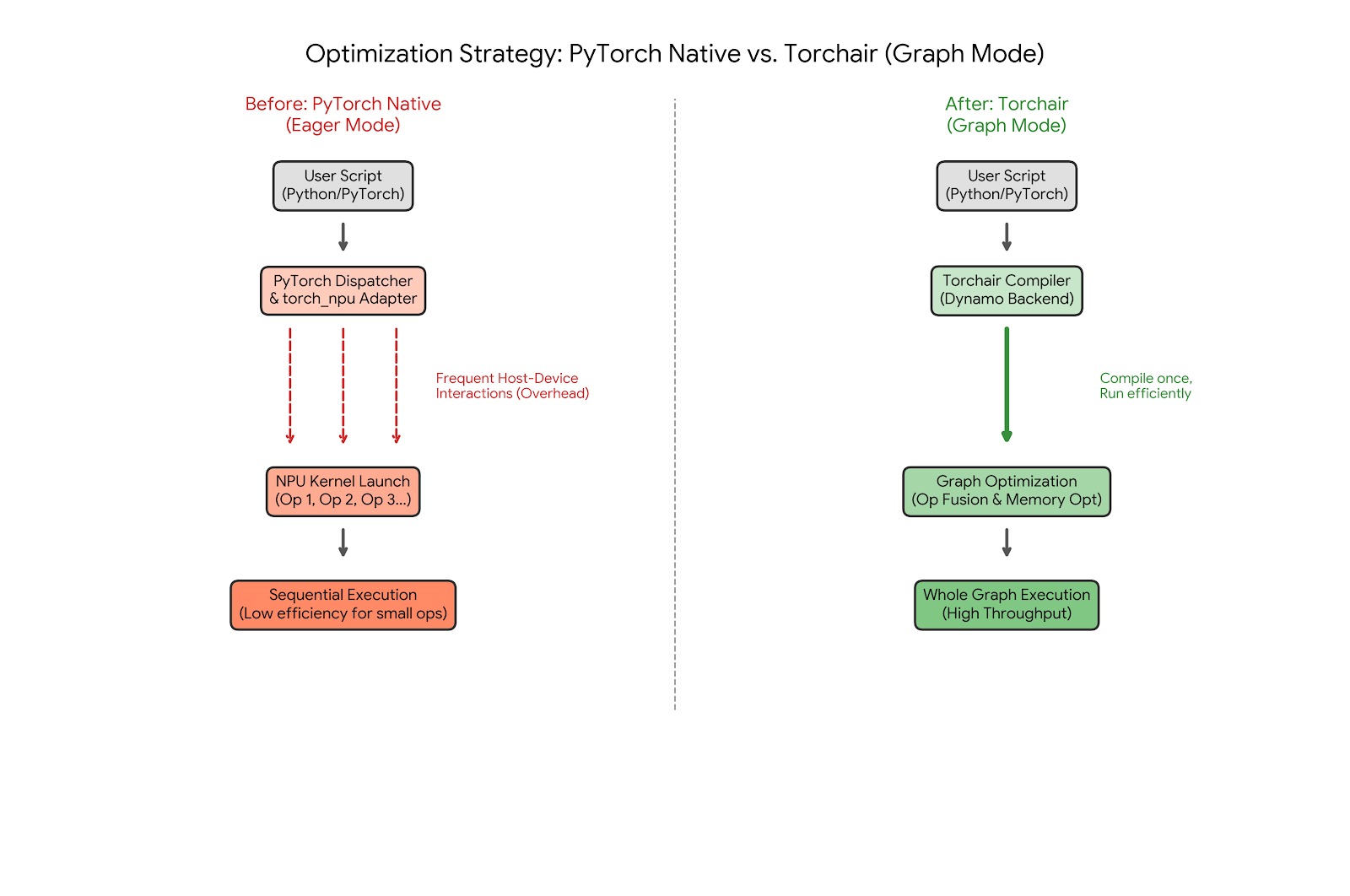
- 更换框架:使用torchair或mindie_torch,专为小模型优化。参考:https://gitee.com/ascend/torchair、https://www.hiascend.com/document/detail/zh/mindie/20RC2/mindietorch/Torchdev/mindie_torch0002.html。
- Torchair:基于AIR(Ascend Intermediate Representation)的轻量框架,减少PyTorch开销。
- MindIE Torch:集成MindSpore的Torch接口,针对小模型的图优化。
- PyTorch调优策略:
- 流水优化(host-bound场景):
export TASK_QUEUE_ENABLE=2
这启用任务队列,提升CPU-NPU并发。
- **禁用算子在线编译**:
torch_npu.npu.set_compile_mode(jit_compile=False)
torch_npu.npu.config.allow_internal_format = False
避免JIT开销,但可能牺牲精度。
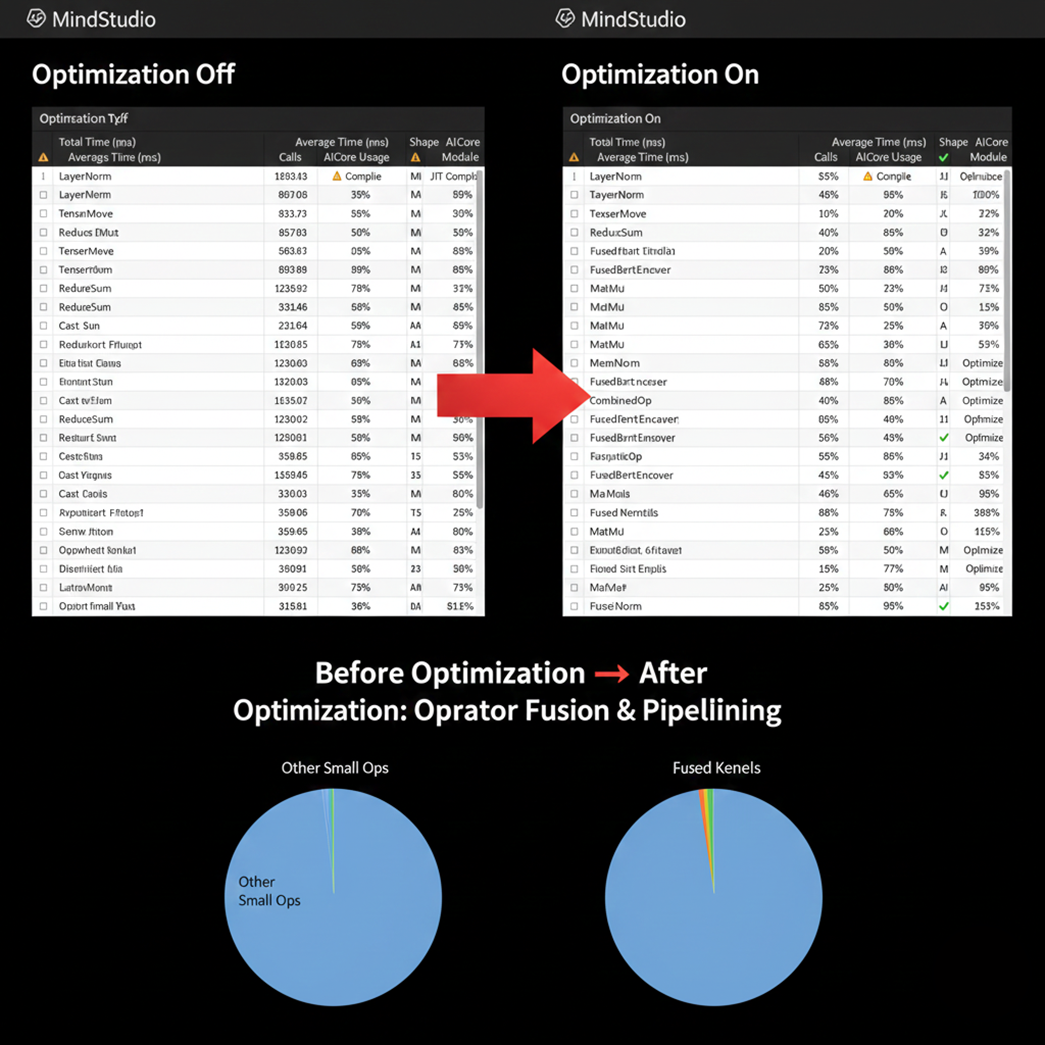
通过 Profiler 导出的算子详细清单(如上图),我们对比了优化前后的算子执行效率。在未调优前,模型中存在大量碎片化的 Small Ops(如频繁的 Tensor 转换和未融合的激活函数),导致 NPU 的 AI Core 利用率处于“锯齿状”。
| 核心指标 | 优化前 | 优化后(开启流水/关闭JIT) |
|---|---|---|
| Task Launch 耗时 | 显著(受 CPU 调度影响) | 极低(任务队列缓冲) |
| 算子编译状态 | 存在 JIT 在线编译开销 | 全量静态/算子融合 |
注意:这些策略在旧版本无效,需升级驱动、固件和CANN包。
- 方案1适合快速迁移,torchair减少了PyTorch的抽象层,类似TensorRT对NVIDIA的优化。
- 方案2是精细调优,流水优化通过队列缓冲减少同步;禁用JIT适用于静态图模型。
三、调优结果:从1.5秒到0.7秒的飞跃
经过上述一系列“组合拳”优化后,我们对模型在不同环境下的端到端(End-to-End)性能进行了最终测算。
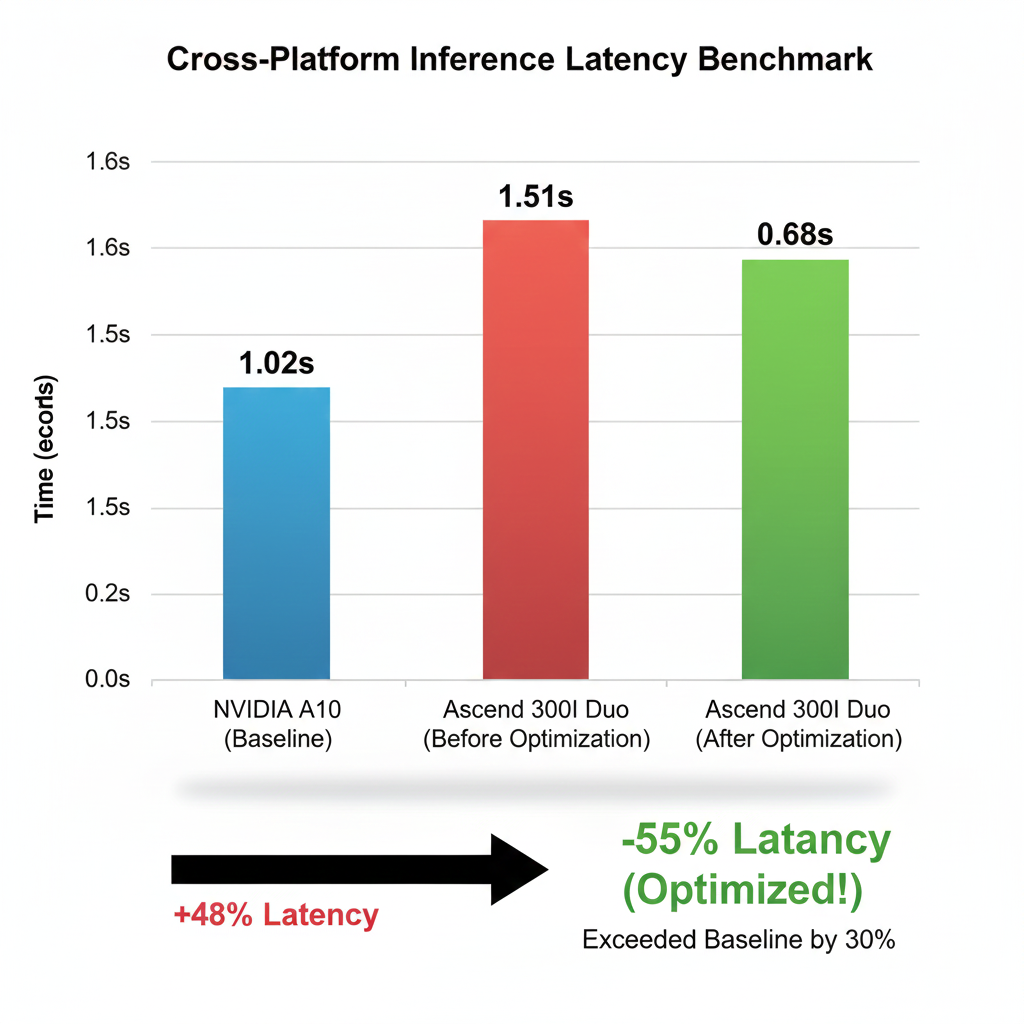
如图所示,最初迁移至昇腾时(红色柱状),耗时为 1.51s;在定位并解决计算延迟问题,并应用了 MindIE/Torchair 推理后端优化后,耗时骤降至 0.68s(绿色柱状)。相比于最初的 NVIDIA A10 环境(1.02s),我们不仅填平了迁移带来的“性能坑”,还额外获得了约 30% 的性能提升。这充分证明了在适配异构芯片时,充分利用硬件专属工具链(CANN)进行深度优化的必要性。
经过优化,昇腾上的推理耗时降至0.7秒,优于NVIDIA的1秒。这展示了调优的价值,不止恢复性能,还超越原平台。这次从1.5s优化到0.7s的经历让我意识到:在异构计算平台上,直觉往往是不可靠的。很多时候我们以为的“传输慢”,其实是计算没做完导致CPU在干等。对于小模型来说,昇腾NPU的潜力其实很大,但前提是你得善用它的工具链(比如Profiler和MindStudio)。
在类似项目中,建议从baseline benchmark开始,逐步profile-optimize-verify。最终,性能调优不仅是技术,更是工程艺术。
四、结语
本次小模型迁移性能调优实战,从最初的性能衰退到最终的超越原平台性能,整个过程充满了技术挑战和发现。最关键的是,我们打破了直觉的误导,通过科学的Profiling分析找到了真正的性能瓶颈。
目前CANN的迭代速度很快,建议大家在迁移时如果遇到性能瓶颈,不要死磕代码逻辑,先跑一遍Profiler,大概率能帮你省下几天排查时间。如果常规手段搞不定,试试Torchair或者MindIE这种针对性的推理后端,可能会有意外惊喜。
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)