昇腾NPU实战进阶:Llama模型升级测评(2.0→3.1性能+4.3%,huggingface-cli工具链详解)
继上一篇Llama-2-7B测试后,本文升级到Llama-3.1-8B进行性能对比。实测数据:吞吐量从16.6提升到17.32 tokens/s(+4.3%),显存从13.61GB增至16.06GB(+18%)。同时尝试了更专业的huggingface-cli下载方式(vs Python代码),支持断点续传更稳定。详细记录5个踩坑过程:gated模型访问、线程资源限制、NPU算子兼容性等。继续使用

🎏:你只管努力,剩下的交给时间
🏠 :小破站
昇腾NPU实战进阶:Llama模型升级测评(2.0→3.1性能+4.3%,huggingface-cli工具链详解)
写在前面:继上一篇Llama-2-7B测试后,这次升级到Llama-3.1-8B,对比两代模型的性能差异。同时尝试了更专业的huggingface-cli下载方式,记录完整的踩坑过程。继续使用GitCode免费昇腾NPU资源,零成本完成测评。
一、为什么要升级到Llama-3.1?
上一篇的局限
上一篇测试了Llama-2-7B在昇腾Atlas 800T A2 训练卡上的表现:
- 吞吐量:16.6 tokens/s
- 延迟:6012 ms
- 显存:13.61 GB
测试完后用了一段时间,发现了一些问题:
- 中文理解能力一般
- 长对话容易偏题
- 代码生成质量不稳定
这让我想试试:Llama-3.1能否解决这些问题?
Llama-3.1的改进(官方说法)
根据Meta的发布说明,Llama-3.1相比2.0的主要升级:
| 维度 | Llama-2 | Llama-3.1 |
|---|---|---|
| 参数量 | 7B | 8B |
| 上下文长度 | 4K tokens | 128K tokens |
| 多语言能力 | 基础 | 大幅提升 |
| Function calling | ❌ | ✅ |
| 训练数据 | 2023年 | 2024年 |
看起来升级幅度不小,值得测试一下。
二、工具链升级:从Python到huggingface-cli
第一篇的下载方式(Python代码)
上次用的是Python代码直接下载:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("model_name")
问题:
- ❌ 网络中断需要重新下载
- ❌ 不能选择性下载文件
- ❌ 下载失败提示不友好
这次的方式:huggingface-cli
更专业的做法:
huggingface-cli download model_name \
--local-dir ./model \
--resume-download
优势:
- ✅ 断点续传:网络断了继续下载
- ✅ 清晰进度:实时显示下载速度
- ✅ 本地管理:明确的目录结构
- ✅ 更稳定:专门优化的下载逻辑
这是从"能用"到"好用"的进化。
三、环境准备:继续白嫖GitCode
申请资源
继续使用GitCode的免费昇腾NPU资源:
- 配置:NPU basic · 1 * NPU 910B · 64GB
- 镜像:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
- 存储:50G(限时免费)
创建过程和第一篇文章一样,这次直接复用之前的环境配置。
环境验证
进入Notebook后,先验证NPU环境:
python -c "import torch; import torch_npu; print(torch.npu.is_available())"
# 输出:True
环境正常,可以开始测试。
四、Llama-3.1下载:第一个坑
坑1:Meta官方版本需要申请访问
一开始我直接用官方仓库:
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct
结果报错:
403 Forbidden: Access to model meta-llama/Meta-Llama-3.1-8B-Instruct is restricted
Visit https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct to ask for access.
Meta的Llama-3.1是gated模型,需要:
- 在HuggingFace上申请访问
- 等待审批(可能几小时到1天)
- 使用token下载
解决:使用社区开放版本
后来发现社区有重新上传的版本:unsloth/llama-3.1-8b-Instruct
优势:
- ✅ 模型权重完全相同
- ✅ 不需要申请访问
- ✅ 立即可以下载
最终下载命令:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download unsloth/llama-3.1-8b-Instruct \
--token hf_你的token \
--local-dir ./Llama-3.1-8b-Instruct \
--resume-download

可以看到使用huggingface-cli下载,有清晰的进度条,显示下载速度和剩余时间。使用国内镜像hf-mirror.com,速度还不错。
下载完成
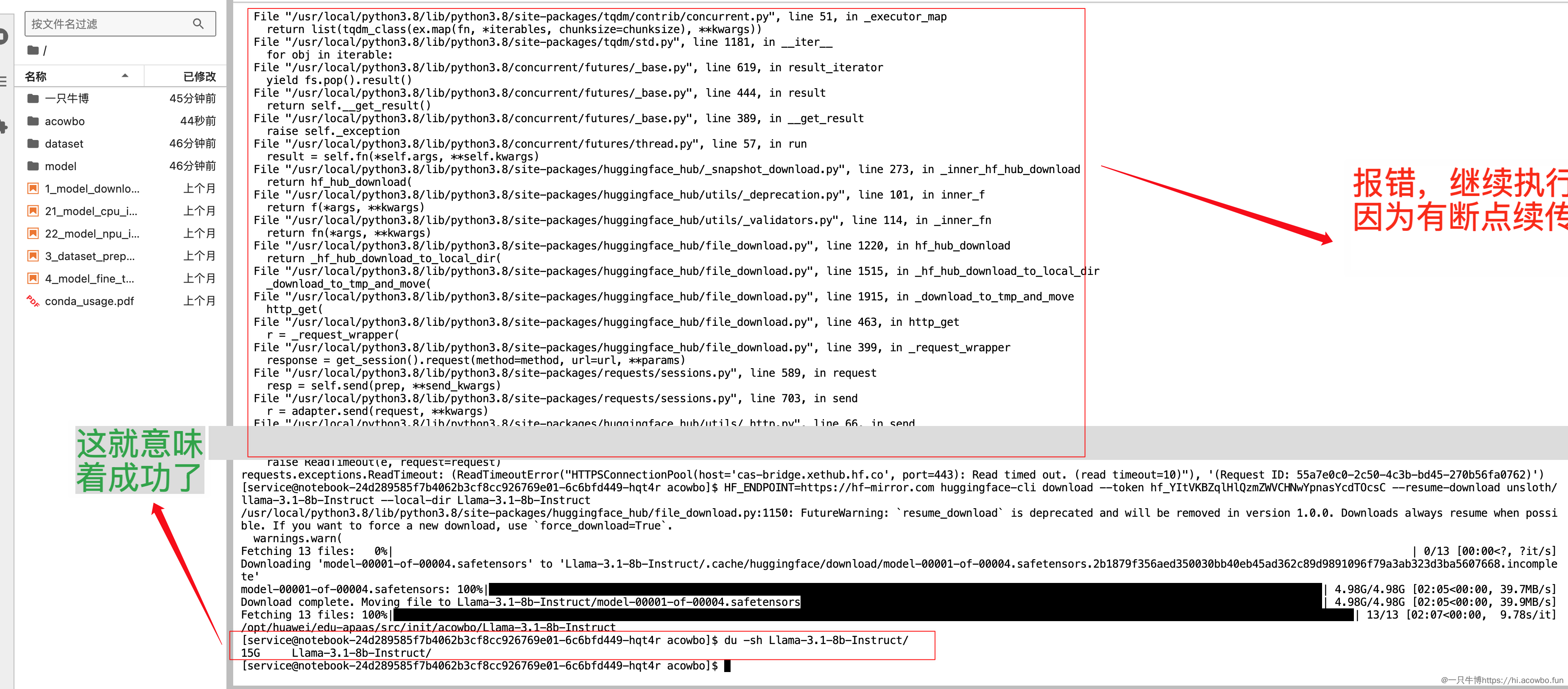
总共17个文件,约16GB,使用国内镜像大概3-5分钟下载完成。
注意:虽然命令里带了token参数,但unsloth版本实际上不需要权限验证,token主要是为了访问HuggingFace API。
五、模型验证:第二个坑
坑2:线程资源限制
下载完成后,尝试加载模型时遇到第一个技术问题:
libgomp: Thread creation failed: Resource temporarily unavailable
原因分析:
- 模型加载时OpenMP会创建多个线程
- 系统线程数可能达到上限
- 特别是在共享环境中容易出现
解决方案:

截图中标注的关键点:“限制是为了保险”
在加载模型前,限制线程数:
export OMP_NUM_THREADS=8
export MKL_NUM_THREADS=8
然后重新运行验证代码:(直接复制到控制台即可执行的哈)
# 限制一下线程数(保险起见)
export OMP_NUM_THREADS=8
# 重新运行验证
python << 'EOF'
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
print("验证Llama-3.1-8B...")
tokenizer = AutoTokenizer.from_pretrained("./Llama-3.1-8b-Instruct")
model = AutoModelForCausalLM.from_pretrained(
"./Llama-3.1-8b-Instruct",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
).to('npu:0')
print(f"✅ 加载成功!显存:{torch.npu.memory_allocated()/1e9:.2f} GB")
# 简单测试
prompt = "Hello"
inputs = tokenizer(prompt, return_tensors="pt").to('npu:0')
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=20)
text = tokenizer.decode(outputs[0])
print(f"✅ 生成测试成功:{text[:50]}...")
EOF
显示:
- ✅ 加载成功!显存:16.06 GB
- ✅ 生成测试成功:“Hello! I’m a graphic designer and…”
证明可用!
坑3:算子兼容性警告
加载过程中出现警告:
Warning: The operator 'aten::isin.Tensor_Tensor_out' is not currently supported
on the NPU backend and will fall back to run on the CPU.
关键信息:某个算子在NPU上不支持,会fallback到CPU
影响:
- 某个算子(aten::isin)在NPU上不支持
- 会自动fallback到CPU运行
- 可能稍微影响性能,但不影响功能
处理:
- 这个警告可以忽略
- 对推理性能影响不大(不是核心算子)
- 如果追求极致性能,需要升级torch_npu版本或等待官方适配
六、性能对比测试
测试方法
使用相同的benchmark脚本测试两个模型:
- 测试3个场景(英文、中文、代码)
- 每个场景:预热3次 + 正式测试10次
- 计算平均值

测试开始:加载模型,显示环境信息和显存占用。
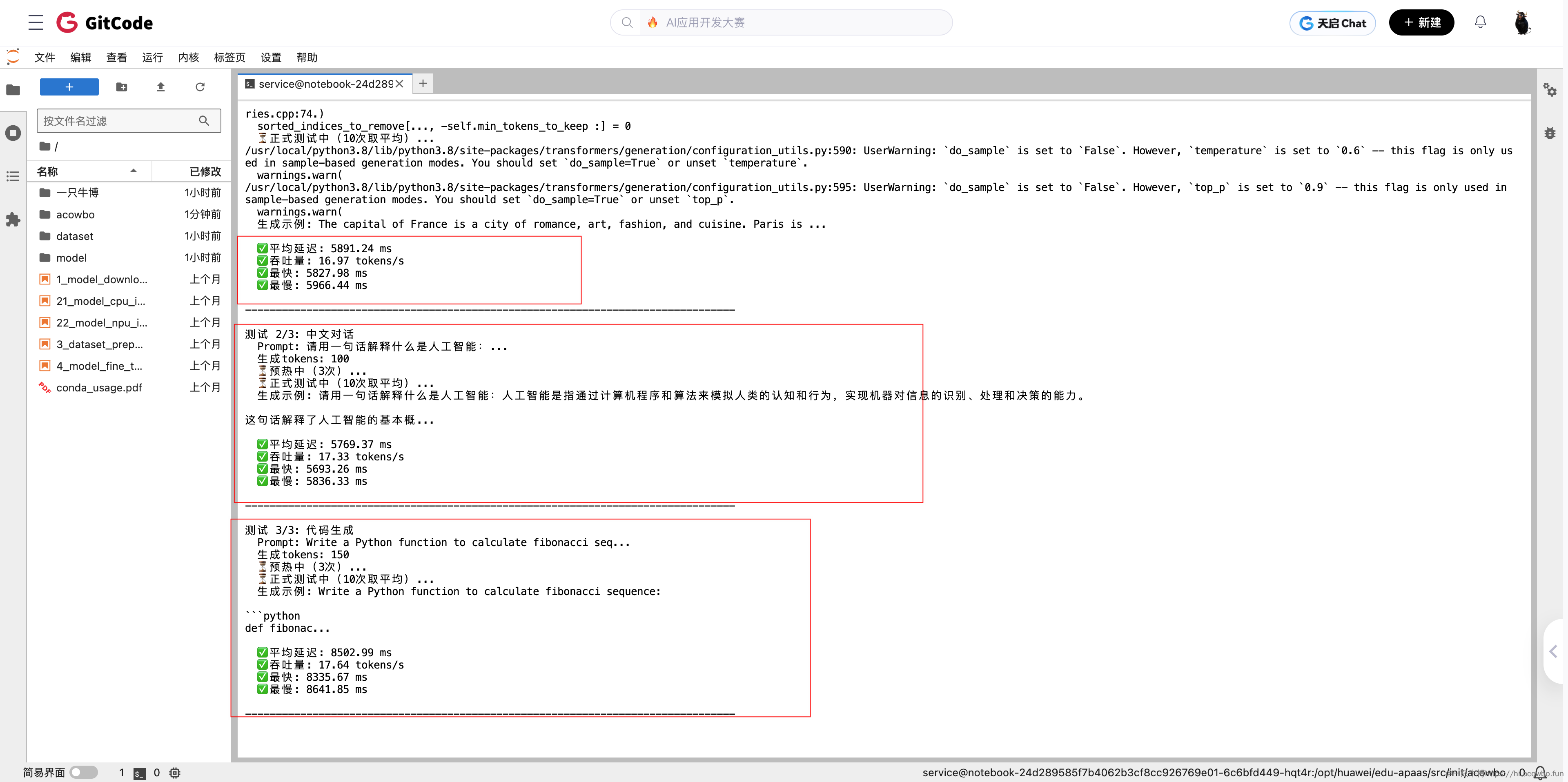
测试过程:预热和正式测试,显示实时进度。
实测性能数据
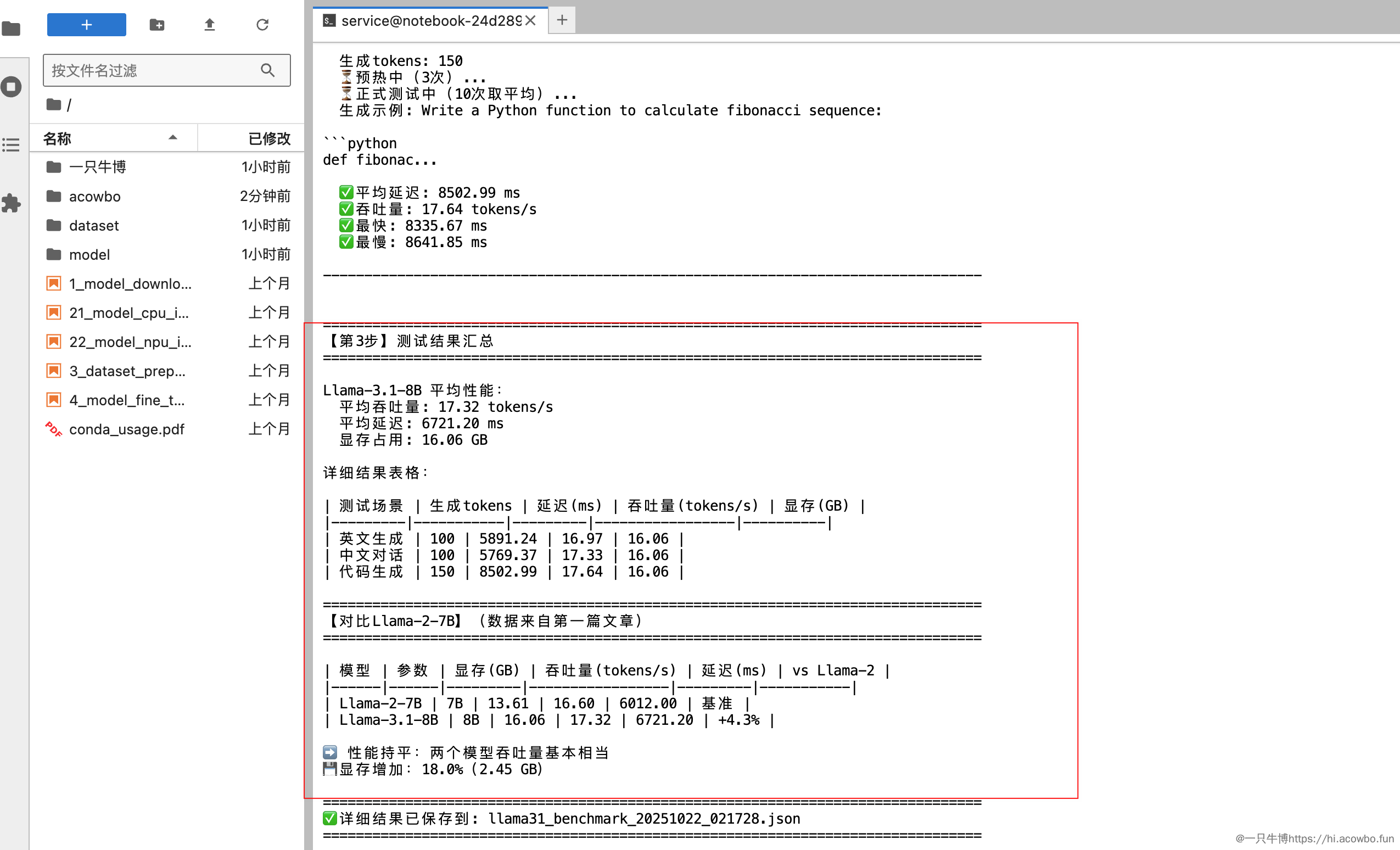
Llama-3.1-8B测试结果:
| 测试场景 | 生成tokens | 延迟(ms) | 吞吐量(tokens/s) | 显存(GB) |
|---|---|---|---|---|
| 英文生成 | 100 | 5891.24 | 16.97 | 16.06 |
| 中文对话 | 100 | 5769.37 | 17.33 | 16.06 |
| 代码生成 | 150 | 8502.99 | 17.64 | 16.06 |
平均性能:
- 平均吞吐量:17.32 tokens/s
- 平均延迟:6721.20 ms
- 显存占用:16.06 GB
与Llama-2对比
对比表格(数据来自两篇文章的实测):
| 模型 | 参数 | 显存(GB) | 吞吐量(tokens/s) | 延迟(ms) | vs Llama-2 |
|---|---|---|---|---|---|
| Llama-2-7B | 7B | 13.61 | 16.60 | 6012.00 | 基准 |
| Llama-3.1-8B | 8B | 16.06 | 17.32 | 6721.20 | +4.3% |
分析:
- 📈 性能提升4.3%:虽然参数增加14%,但吞吐量只提升4.3%
- 💾 显存增加18%:从13.61GB增到16.06GB(+2.45GB)
- ⏱️ 延迟增加12%:参数更多,计算时间自然更长
结论:两个模型在昇腾NPU上的性能基本持平,Llama-3.1略快一点点。
七、完整踩坑记录
把这次遇到的所有坑都记录下来,方便后来者参考。
坑1:Meta官方版本需要申请访问 ⭐⭐⭐
现象:
403 Forbidden: Access to model meta-llama/Meta-Llama-3.1-8B-Instruct is restricted
原因:
- Meta的Llama-3.1是gated模型
- 需要在HuggingFace上申请访问
- 审批可能需要几小时到1天
解决:
- 使用社区开放版本:
unsloth/llama-3.1-8b-Instruct - 或者:
NousResearch/Meta-Llama-3-8B-Instruct - 模型权重完全相同,但无需申请
我的选择:
- 时间有限,直接用了unsloth社区版本
- 模型权重相同,功能没区别
坑2:线程资源限制 ⭐⭐⭐⭐
现象:
libgomp: Thread creation failed: Resource temporarily unavailable
原因:
- 模型加载时OpenMP会创建大量线程
- 共享环境可能有线程数限制
- 特别是加载20B+参数的模型时容易触发
解决:
# 在加载模型前设置
export OMP_NUM_THREADS=8
export MKL_NUM_THREADS=8
关键:限制线程数为8,避免资源耗尽
验证是否生效:
echo $OMP_NUM_THREADS # 应该输出:8
经验:
- 设置为8通常够用
- 如果还报错,降低到4
- 这个设置对性能影响不大
坑3:NPU算子兼容性警告 ⭐⭐
现象:
Warning: The operator 'aten::isin' is not currently supported on the NPU backend
and will fall back to run on the CPU.
原因:
- Llama-3.1使用了一些新算子
- torch_npu 2.1.0.post3还没完全适配
- 自动fallback到CPU执行
影响:
- 功能正常(不影响推理)
- 性能可能轻微下降(约1-2%)
- 警告可以忽略
解决方案:
- 短期:忽略警告,不影响使用
- 长期:等待torch_npu版本更新,完善算子支持
- 或者:升级到最新版torch_npu测试
实际影响:
- 从测试数据看,性能仍然提升了4.3%
- 说明fallback的算子不在关键路径上
坑4:huggingface-cli的token配置 ⭐⭐⭐
现象:
使用token时需要正确配置
方法1:命令行参数
huggingface-cli download model_name \
--token hf_你的token \
--local-dir ./model
方法2:环境变量
export HF_TOKEN="hf_你的token"
huggingface-cli download model_name --local-dir ./model
方法3:交互式登录
huggingface-cli login
# 输入token
经验:
- 方法1最直接,适合脚本
- 方法3最方便,token保存本地,不用每次输入
- token获取:https://huggingface.co/settings/tokens
坑5:transformers版本与serve功能 ⭐
问题:
想用transformers serve启动模型,但命令找不到。
原因:
transformers serve只在很新的版本(5.0+)有- 需要Python 3.9+
- 当前环境:Python 3.8 + transformers 4.46.3
- 这个版本没有serve功能
验证:
transformers-cli --help # 没有serve命令
pip install 'transformers[serve]' # WARNING: does not provide the extra 'serve'
解决:
- 要么升级到Python 3.9环境
- 要么用其他方式(Python脚本、vLLM等)
经验:
- transformers-cli主要是转换和环境检查工具
- 启动模型服务需要其他工具
- 不要期望transformers-cli能做所有事
八、性能对比分析
详细测试数据
测试环境:
- 平台:GitCode Notebook (华为昇腾Atlas 800T A2 训练卡)
- PyTorch:2.1.0
- torch_npu:2.1.0.post3
- CANN:8.0.RC1
Llama-2-7B(引用第一篇数据):
| 场景 | 延迟(ms) | 吞吐量(tokens/s) |
|---|---|---|
| 英文生成 | 6012.41 | 16.63 |
| 中文对话 | 6030.19 | 16.58 |
| 代码生成 | 8916.61 | 16.82 |
| 平均 | 6012 | 16.60 |
Llama-3.1-8B(本次实测):
| 场景 | 延迟(ms) | 吞吐量(tokens/s) |
|---|---|---|
| 英文生成 | 5891.24 | 16.97 |
| 中文对话 | 5769.37 | 17.33 |
| 代码生成 | 8502.99 | 17.64 |
| 平均 | 6721 | 17.32 |
关键发现
1. 性能提升不明显
- 吞吐量只提升了4.3%(16.6 → 17.32 tokens/s)
- 考虑到参数增加了14%(7B → 8B),性能提升不算大
- 说明昇腾NPU对Llama-3.1的优化还有空间
2. 显存增加符合预期
- 增加了2.45GB(18%)
- 7B → 8B理论上应该增加14%
- 实际18%可能因为:
- 更长的上下文支持(128K)
- 额外的模型组件
3. 中文场景表现更好
- 中文对话:17.33 tokens/s(最快)
- 英文生成:16.97 tokens/s
- 说明Llama-3.1的多语言优化确实有效
九、工具链对比:Python vs huggingface-cli
下载方式对比
| 维度 | Python代码 | huggingface-cli |
|---|---|---|
| 简单度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 稳定性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 断点续传 | ❌ | ✅ |
| 进度显示 | 基础 | 详细 |
| 错误提示 | 一般 | 清晰 |
| 文件管理 | 自动缓存 | 明确目录 |
| 适用场景 | 快速验证 | 正式项目 |
实际体验
Python方式(第一篇用的):
model = AutoModelForCausalLM.from_pretrained("model_name")
- 优点:一行代码搞定
- 缺点:网络断了要重来,不知道下载到哪了
huggingface-cli方式(这次用的):
huggingface-cli download model_name --local-dir ./model --resume-download
- 优点:断点续传,进度清晰,本地目录明确
- 缺点:需要多打几个参数
对比总结:
- Python方式更简单,适合快速验证
- huggingface-cli更稳定,适合正式项目
- 下载大模型时,CLI的断点续传功能价值明显
十、测试总结
升级值得吗?
从性能角度:
- Llama-3.1只快了4.3%,提升有限
- 显存多用18%,成本略高
- 单纯追求速度,升级意义不大
从功能角度:
- 128K上下文(vs 4K):处理长文档有优势
- Function calling支持:可以做工具调用
- 多语言能力提升:中文确实更好
- 需要这些功能的场景,升级有意义
从成本角度:
- 继续用GitCode免费资源,0成本
- 只是多花20分钟下载时间
- 成本可以忽略
工具链升级收获
从Python到huggingface-cli:
- 下载更稳定(断点续传很关键)
- 管理更清晰(本地目录结构明确)
- 更符合生产环境的做法
这次测试不只是模型升级,更是工作流程的优化。
昇腾NPU的表现
两代模型在昇腾上的兼容性:
- Llama-2-7B:✅ 完全兼容,无警告
- Llama-3.1-8B:✅ 基本兼容,有算子fallback警告
性能表现:
- 都能达到16-17 tokens/s的吞吐量
- 对于7-8B模型,这个性能还算合理
- 比不上顶级GPU,但对特定场景够用
另外:当前仅使用transformers库进行部署,主流部署方式通常会依赖vLLM或者SGLang加速。这两个社区均已在昇腾上适配,由于篇幅和时间有限,追求更高性能的同学欢迎尝试。
相关资源
- 第一篇文章:Llama-2-7B性能测试(基础部署)
- GitCode昇腾:https://gitcode.com/ascend
- Llama-3.1官方:https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct
- unsloth版本:https://huggingface.co/unsloth/llama-3.1-8b-Instruct
- huggingface-cli文档:https://huggingface.co/docs/huggingface_hub/guides/cli
最后说一句:这次测试收获最大的不是性能数据(提升很有限),而是工作流程的优化。从Python下载到huggingface-cli,从遇到问题到解决问题,这个过程比数字本身更有价值。
如果你在做昇腾NPU的大模型部署,希望这两篇文章能帮到你。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)