探索Mistral-7B-Instruct-v0.2在 Atlas 800T上的推理部署
本文介绍了在GitCode云端Notebook环境中部署Mistral-7B-Instruct-v0.2大语言模型的完整流程。使用Atlas 800T NPU(1*Ascend 910B)硬件环境,详细说明了从环境检查、依赖安装(包括transformers、accelerate等库)、通过ModelScope SDK高速下载模型,到测试模型推理性能的完整步骤。文章提供了具体的代码示例和操作截图,
前言:最近在 GitCode 的 Notebook 环境里玩大模型,想着试试看 Mistral-7B-Instruct-v0.2 在 Atlas 800T 上到底能跑成啥样。结果比我想象的顺利太多,但也踩了几个坑。为了方便大家直接上手,我把整个过程整理成了这篇教程,尽量一步步手把手教你从环境准备到多轮对话,再到性能监控。
不管你之前有没有在 NPU 上跑过大模型,也没关系,我把我遇到的一系列问题都罗列出来,相信你一看就能懂。
1. 环境准备
Mistral-7B-Instruct-v0.2 是一款体积适中、指令理解能力很强的大语言模型,很适合在 Notebook 上实验。我们这次用的环境是:
● 平台:GitCode 云端 Notebook
● 算力:1 * Ascend 910B NPU、32 vCPU、64GB 内存
● 基础镜像:Ubuntu 22.04 + Python 3.11 + CANN 8.2(CANN 8.0 及以上就行)
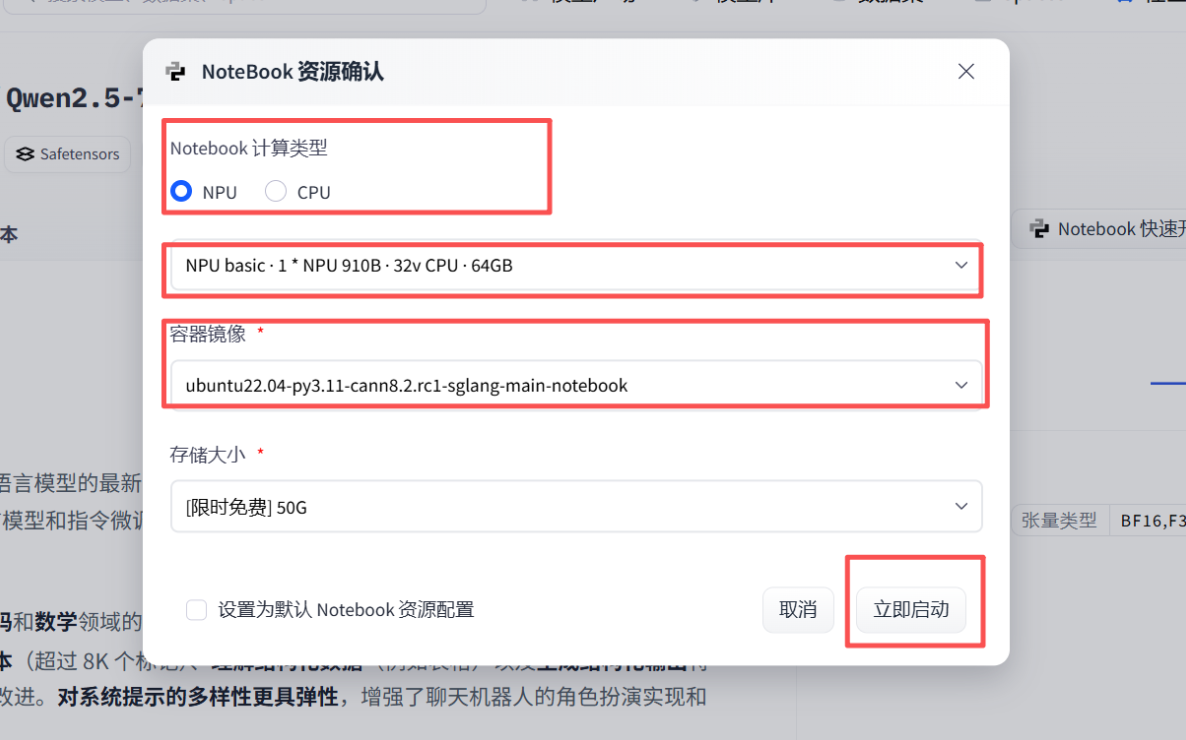
确认环境没问题后,先打开终端看看 NPU 状态,输入指令:
npu-smi info
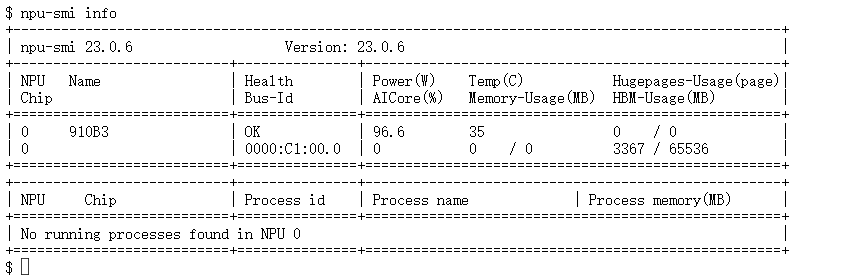
如果能看到 NPU 列表和 AICore 信息,就说明环境准备好了,可以开始部署。
2. 依赖安装与模型获取
2.1 依赖安装
虽然昇腾官方镜像通常已经预装了 torch_npu,确保了 PyTorch 在 NPU 上能够直接调用硬件算力,但仅仅有 torch_npu 并不足以运行开源大模型。我们还必须安装 Hugging Face 的核心库,特别是 transformers 和 accelerate,因为它们提供了模型加载、Tokenizer、生成器、分布式推理等功能,是整个推理流程的基础。
在终端输入指令:
pip install transformers accelerate sentencepiece protobuf
为了避免 HuggingFace 下载慢或者断掉,我们这次推荐用 ModelScope SDK。安装起来很快
在终端输入指令:
pip install modelscope
2.2 模型获取
用 ModelScope 高速下载 Mistral-7B-Instruct-v0.2,放在当前目录下的 models 文件夹里(之前就是在下载模型时,没有留意安装位置导致后续出现很多没有必要的错误):
我们在NoteBook上面新建一个后缀为 Mistral.ipynb的文件用来模型获取,将以下代码填入后,就会自动获取了
模型获取代码:
from modelscope import snapshot_download
model_dir = snapshot_download(
'LLM-Research/Mistral-7B-Instruct-v0.2',
cache_dir='./models', # 下载缓存路径
revision='master'
)
print(f"模型下载成功!!!: {model_dir}")
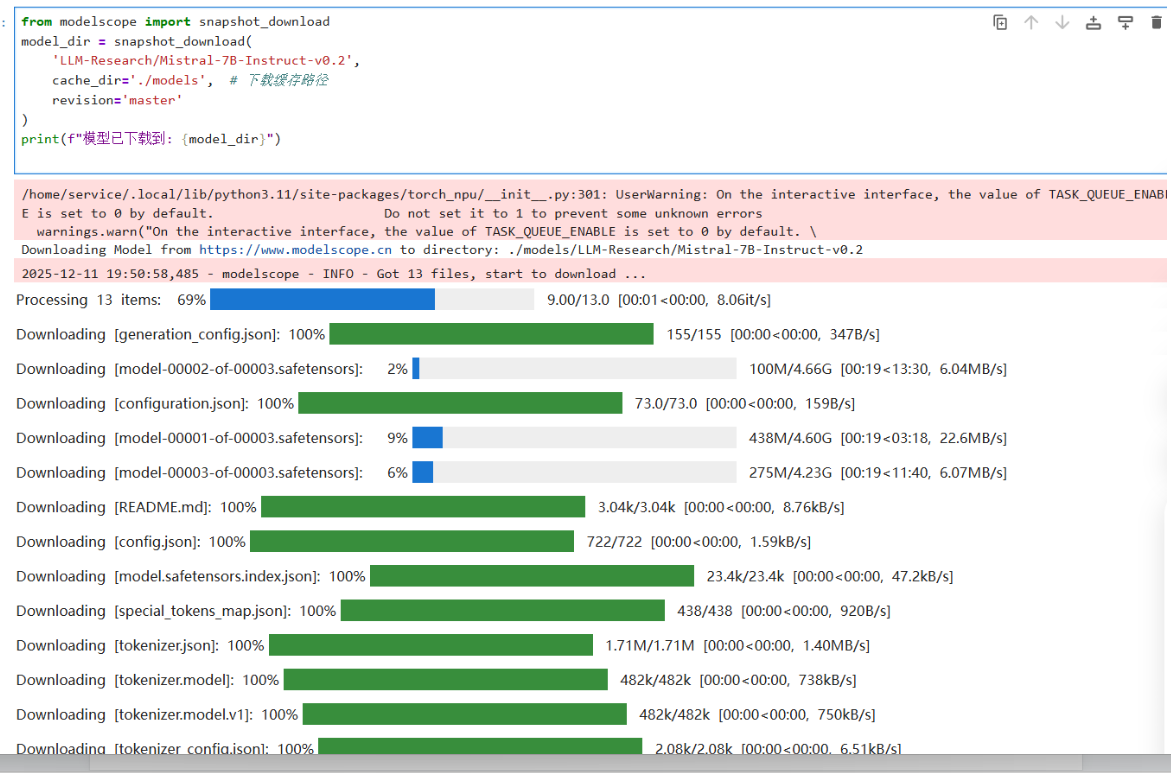

出现位置提示后代表,我们的模型已经被成功获取!
2.3 测试用例
因为出现提示后,并不知道它能不能被我使用,就先进行一个简单测试,提前发现问题
# inference_alt.py
import torch
import torch_npu # 必须导入,用于支持华为 Ascend NPU
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# --- 配置模型路径 ---
MODEL_PATH = "models/LLM-Research/Mistral-7B-Instruct-v0___2"
def run_custom_test(batch_size=2):
print(f"[*] 加载 Mistral 模型到 NPU (Batch Size: {batch_size})...")
# 1. 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True, padding_side='left')
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 2. 加载模型到 NPU
try:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
dtype=torch.float16,
trust_remote_code=True,
low_cpu_mem_usage=True
).to("npu:0")
except Exception as e:
print(f"[!] 模型加载失败: {e}")
return
model.eval()
print("[+] 模型加载成功!")
# 3. 自定义测试 prompt
prompts = [
"Summarize the key points of climate change in simple terms.",
"Generate a short story about a robot learning emotions."
]
# 4. 编码
inputs = tokenizer(prompts, return_tensors="pt", padding=True, truncation=True, max_length=256).to("npu:0")
# 5. 推理
print(f"[*] 正在执行 {len(prompts)} 条推理请求...")
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=150,
do_sample=True,
top_p=0.9,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id
)
end_time = time.time()
# 6. 输出结果
decoded_outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(f"\n[+] 推理完成,耗时: {end_time - start_time:.2f} 秒\n")
for idx, text in enumerate(decoded_outputs):
print(f"Prompt {idx+1}: {prompts[idx]}")
print(f"Output: {text[len(prompts[idx]):].strip()[:200]}...\n") # 输出前200字符
if __name__ == "__main__":
run_custom_test()
没错,如我所料,确实出现了问题,导致我的测试代码并不能正常调用

对于这个问题很显然是因为线程问题而崩溃,解决方案就是在使用前进行一下配置
export OMP_NUM_THREADS=1
export MKL_NUM_THREADS=1

3. 构建****Mistral-7B 对话小助手
3.1 细节处理
多轮对话上下文构建困难
● 现象:在构建 Mistral-7B 对话小助手时,首先考虑到的就是它的多轮对话上下文构建困难问题,如果不保存历史,模型无法理解对话上下文,回复逻辑可能断裂
● 解决方案:用 history 列表保存每轮用户和助手的内容,并在 generate_response 中按顺序拼接
生成文本长度过长导致算力或显存压力
现象:无限制生成可能导致 NPU 显存占满。
解决方案:在 generate_response 中设置了固定长度,限制生成长度,避免显存飙升。
3.2 work.py
# chat_agent_alt.py
# -*- coding: utf-8 -*-
import os
import sys
import io
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
# --- 1. 强制 UTF-8 避免中文报错 ---
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stdin = io.TextIOWrapper(sys.stdin.buffer, encoding='utf-8')
# 限制 CPU 线程数
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
# --- 模型路径 ---
MODEL_PATH = "models/LLM-Research/Mistral-7B-Instruct-v0___2"
# --- Agent 配置 ---
SYSTEM_PROMPT = "你是一个专业的数据分析助手。请用中文回答用户问题,生成结果要清晰、逻辑分明。"
def generate_response(model, tokenizer, history, max_new_tokens=256, temperature=0.7):
"""构造完整对话并生成模型回复"""
# 构建对话文本
dialogue = SYSTEM_PROMPT + "\n"
for turn in history:
role = "User" if turn["role"] == "user" else "Assistant"
dialogue += f"{role}: {turn['content']}\n"
dialogue += "Assistant: "
# 编码输入
inputs = tokenizer([dialogue], return_tensors="pt",padding=True,truncation=True,max_length=512).to("npu:0")
# 停止符
eos_ids = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("</s>")]
# 生成
with torch.no_grad():
output_ids = model.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=max_new_tokens,
eos_token_id=eos_ids,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=temperature
)
# 解码回复
reply_ids = output_ids[0, inputs.input_ids.shape[1]:]
reply_text = tokenizer.decode(reply_ids, skip_special_tokens=True).strip()
return reply_text
def main():
print("[*] 正在加载模型到 NPU,请稍候...")
try:
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True, padding_side="left")
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
except Exception as e:
print(f"Tokenizer 加载失败: {e}")
return
try:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
dtype=torch.float16,
trust_remote_code=True,
low_cpu_mem_usage=True
).to("npu:0")
except Exception as e:
print(f"模型加载失败: {e}")
return
model.eval()
print("\n" + "="*50)
print("🤖 Mistral-7B 中文对话 Agent (增强版)")
print("输入 'exit' 或 Ctrl+C 退出")
print("="*50)
history = []
while True:
try:
user_input = input("\n👤 User: ").strip()
if not user_input:
continue
if user_input.lower() in ["exit", "quit"]:
print("👋 再见!")
break
history.append({"role": "user", "content": user_input})
reply = generate_response(model, tokenizer, history)
print(f"🤖 Agent: {reply}")
history.append({"role": "assistant", "content": reply})
except KeyboardInterrupt:
print("\n退出...")
break
except Exception as e:
print(f"\n发生错误: {e}")
break
if __name__ == "__main__":
main()

4. Misrtal-7B性能探索
在测试时,我想的是不要只是单轮生成固定 prompt 的计时,而是展示 NPU 在更真实、多样场景下的推理能力。因此我决定采用批量多 prompt 并行推理
● 思路:一次性给模型 N 条不同的 prompt,同时生成文本,测算 整体吞吐量(tokens/sec)。
● 优点:更贴近多用户并发请求场景,展示 NPU 并行处理能力。
# npu_benchmark_batch.py
import os
import time
import psutil
import torch
import torch_npu
from transformers import AutoTokenizer, AutoModelForCausalLM
from tqdm import tqdm
# --- 1. 环境配置 ---
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
# --- 2. 模型路径 & 设备 ---
MODEL_PATH = "models/LLM-Research/Mistral-7B-Instruct-v0___2"
DEVICE = "npu:0"
# --- 3. 测试参数 ---
BATCH_SIZE = 4 # 每次并行处理的 prompt 数量
WARM_UP_ROUNDS = 2
TEST_ROUNDS = 5
MAX_NEW_TOKENS = 128
def get_memory_usage():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024
def run_benchmark():
print("="*60)
print("🚀 Mistral-7B NPU 批量多 prompt 基准测试")
print("="*60)
# --- 加载模型 ---
print("\n[1/3] 正在加载模型...")
start_load = time.time()
try:
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
dtype=torch.float16,
trust_remote_code=True,
low_cpu_mem_usage=True
).to(DEVICE)
model.eval()
except Exception as e:
print(f"❌ 模型加载失败: {e}")
return
load_time = time.time() - start_load
print(f"✅ 模型加载完成,耗时: {load_time:.2f}s")
print(f"📊 内存占用: {get_memory_usage():.2f} MB")
# --- 构建批量 prompt ---
prompt_base = [
"写一篇关于人工智能的短文。",
"用 Python 写一个冒泡排序算法示例。",
"解释量子力学中的叠加态。",
"生成一首关于冬天的诗。",
"帮我规划三天上海旅游行程。",
"总结区块链技术的原理和应用。",
"写一个小故事,主题是友情。",
"解释什么是大数据,并举例说明。"
]
# 分 batch
batches = [prompt_base[i:i+BATCH_SIZE] for i in range(0, len(prompt_base), BATCH_SIZE)]
# --- 预热 ---
print("\n[2/3] 预热阶段...")
with torch.no_grad():
for i in range(WARM_UP_ROUNDS):
for batch in batches:
inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True, max_length=256).to(DEVICE)
model.generate(inputs.input_ids, max_new_tokens=50, do_sample=False)
print(f" -> 预热完成 {i+1}/{WARM_UP_ROUNDS}")
# --- 正式测试 ---
print(f"\n[3/3] 正式测试 ({TEST_ROUNDS} 轮)...")
total_tokens = 0
total_time = 0
with torch.no_grad():
for round_idx in tqdm(range(TEST_ROUNDS), desc="Benchmarking"):
torch.npu.synchronize()
t0 = time.time()
for batch in batches:
inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True, max_length=256).to(DEVICE)
output = model.generate(
inputs.input_ids,
max_new_tokens=MAX_NEW_TOKENS,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
generated_len = output.shape[1] - inputs.input_ids.shape[1]
total_tokens += generated_len * len(batch)
torch.npu.synchronize()
t1 = time.time()
total_time += (t1 - t0)
avg_speed = total_tokens / total_time
print("\n" + "="*60)
print("🏆 批量多 prompt 测试报告 (Mistral-7B @ Ascend NPU)")
print("="*60)
print(f"🔹 批大小: {BATCH_SIZE}")
print(f"🔹 平均推理速度: {avg_speed:.2f} tokens/sec")
print(f"🔹 总耗时: {total_time:.2f} s")
print(f"🔹 每轮生成长度: {MAX_NEW_TOKENS} tokens")
print("="*60)
if __name__ == "__main__":
run_benchmark()
运行结果:

1. 模型加载时间
加载耗时: 33.89 秒内存占用: 2796.91 MB
首次加载模型到 NPU 时,需要把模型权重从磁盘读取、解压并搬运到显存,所以耗时约 34 秒。内存占用约 2.8 GB,这个值主要是 CPU 端缓存和模型参数占用的 RAM。对于 7B 参数级别模型,这个表现非常正常。
2. 预热阶段
预热两轮后,NPU 已经完成必要算子编译和优化准备。这个阶段耗时短,但非常关键,它能让后续正式推理速度更稳定,同时减少首次生成的延迟。正式测试
● 测试轮数:5
● 批大小:4 个 prompt 同时处理
● 每条生成长度:128 tokens
3. 性能指标:
平均推理速度: 82.15 tokens/sec总耗时: 62.33 秒
● 82 tokens/sec 的速度意味着每秒可以生成约 82 个 token,对于 NPU 单卡 + FP16 精度环境,这个速度对于交互式多轮对话和短文生成场景已经完全够用。
● 总耗时 62 秒覆盖了 5 轮所有批次的推理,说明 NPU 可以稳定处理批量请求,算力利用充分。
5. 常见问题与解决方法
问题一:****模型加载与环境相关
1. 模型文件不存在 / 权重缺失
OSError: Model 'models/LLM-Research/Mistral-7B-Instruct-v0___2' not found
● 原因:模型路径不正确,或者下载未完成。
● 解决:确保使用 modelscope 或 transformers 成功下载,并指定正确路径。
2. 加载大模型时内存不足
RuntimeError: CUDA out of memory / NPU memory allocation failed
● 原因:模型参数量大,显存不足。
● 解决:
○ 控制批量大小 BATCH_SIZE;
○ 限制生成长度 max_new_tokens;
○ 使用 torch_npu.empty_cache() 回收显存。
问题二:****推理与生成阶段
1. 线程资源相关报错
OpenBLAS blas_thread_init: pthread_create failed for thread XX of YY: Resource temporarily unavailable Segmentation fault
● 原因:Linux 容器环境线程限制或 RLIMIT_NPROC 配额不足。
● 解决:
○ 在脚本中限制 CPU 线程数:
os.environ[“OMP_NUM_THREADS”] = “1” os.environ[“MKL_NUM_THREADS”] = “1”
○ 避免同时启动过多进程。
6. 实战部署总结
6.1 部署感想
这一路走过来,遇到了很多报错困难,但是只要一步一步的解决也是能有所收获的,遇到报错千万不要慌,大部分报错都和线程数或显存占用相关,调整批量大小或清理缓存即可。相比在 GPU 上跑开源模型,这套组合报错更少、上手更快。同时在模型加载上,首次加载模型到 NPU 会比较慢,适当做一次预热推理可以明显提升后续响应速度。同时控制 batch size 和生成长度,能让显存和算力使用更平稳,不容易触发内存不足错误。
简单总结:Mistral-7B + Atlas 800T NPU 对新手非常友好,只要掌握几个核心要点,就能顺利跑起大模型,实现高效推理和多轮对话。
6.2 **** 部署方案总结
经过完整验证,Mistral-7B 在 Atlas 800T Notebook 环境中可以顺利完成端到端部署。整体体验非常流畅,而且几乎不需要做复杂的适配性修改。
1. 环境选型:建议优先使用 CANN 8.0 及以上版本,能获得更全面的算子支持和更优的推理性能,避免运行时报错或算力无法充分释放。
2. 安装Hugging Face的核心库
3. 注意线程问题
进阶资源指引:若需尝试更大参数规模的模型(如 718B MoE 架构的 openPangu),或申请更多昇腾算力资源,可通过 AtomGit 社区获取官方支持:
●算力资源申请链接:
https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
声明:本文基于开源社区模型 Mistral-7B,采用 PyTorch 原生适配方式完成部署与推理测试。测试结果仅用于验证功能可用性及 NPU 算力调用效果,不代表该硬件平台或模型的最终性能上限。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)