
BoostKit 虚拟化性能优化原理解读
在云计算和虚拟化场景中,鲲鹏 BoostKit 提供了面向 ARMv8 架构的全栈性能优化方案。本篇文章聚焦于 BoostKit 的性能优化原理,通过解析 vCPU 调度、内存虚拟化、I/O 加速和中断优化等关键技术,展示其如何在虚拟化环境中释放鲲鹏处理器的极致性能,并与开源 KVM/QEMU 配置进行对比。
1.前言
在云计算和虚拟化场景中,鲲鹏 BoostKit 提供了面向 ARMv8 架构的全栈性能优化方案。本篇文章聚焦于 BoostKit 的性能优化原理,通过解析 vCPU 调度、内存虚拟化、I/O 加速和中断优化等关键技术,展示其如何在虚拟化环境中释放鲲鹏处理器的极致性能,并与开源 KVM/QEMU 配置进行对比。
鲲鹏 BoostKit 虚拟化场景:

鲲鹏服务器虚拟化场景下的 “物理硬件拓扑 - 虚拟化层调度” 对应架构图:
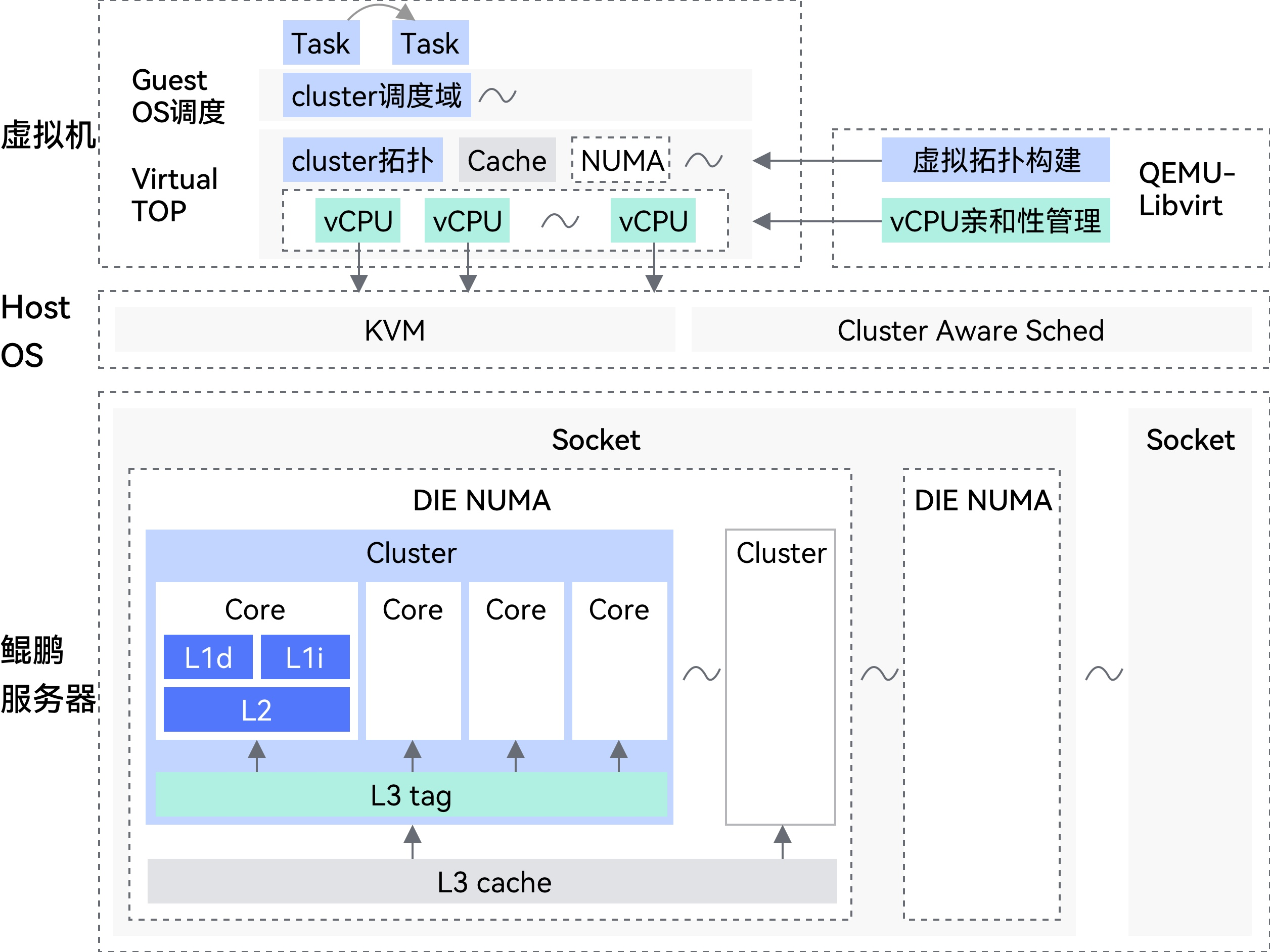
接下来让我们正式的开始讲解BoostKit 虚拟化。
2.vCPU 调度优化与 NUMA 亲和性
虚拟机性能瓶颈往往来源于跨 NUMA 节点的内存访问延迟。BoostKit 利用 vCPU 与物理 CPU 的严格绑定、内存本地化分配以及 Linux sched_setaffinity 接口,显著提升 Cache 命中率、降低上下文切换开销。
我们通过 Libvirt 的 XML 配置文件来实现 vCPU 绑定。以下是一个典型的优化配置示例,展示了如何将 4 个 vCPU 严格绑定到 NUMA 节点 0 的物理核 0-3 上,并强制内存从同一节点分配。
<domain type='kvm'>
<name>kunpeng-optimized-vm</name>
<vcpu placement='static'>4</vcpu>
<cputune>
<!-- vCPU 0 绑定到物理核 0 -->
<vcpupin vcpu='0' cpuset='0'/>
<!-- vCPU 1 绑定到物理核 1 -->
<vcpupin vcpu='1' cpuset='1'/>
<vcpupin vcpu='2' cpuset='2'/>
<vcpupin vcpu='3' cpuset='3'/>
<!-- 模拟器线程绑定到物理核 4,避免干扰业务 -->
<emulatorpin cpuset='4'/>
</cputune>
<numatune>
<!-- 严格内存模式,仅允许从节点 0 分配内存 -->
<memory mode='strict' nodeset='0'/>
</numatune>
<cpu mode='host-passthrough' check='none'>
<topology sockets='1' cores='4' threads='1'/>
</cpu>
</domain>在底层实现中,KVM 利用 Linux 的 sched_setaffinity 系统调用来实现这种绑定。当 vCPU 线程被固定后,L1/L2 Cache 的命中率将大幅提升,同时减少了上下文切换带来的开销。对于对延时极度敏感的业务(如 NFV 网元),我们甚至可以使用 isolcpus 内核参数将物理核从 Linux 调度器中隔离出来,专供虚拟机使用,实现"零干扰"运行。
查看对应的绑定情况:
# 查看虚拟机 XML 配置
virsh dumpxml kunpeng-optimized-vm
# 查看虚拟机 vCPU 绑定及状态
virsh vcpuinfo kunpeng-optimized-vm
# 查看虚拟机 NUMA 拓扑信息
virsh domnuma kunpeng-optimized-vm
# 查看 QEMU 进程及其线程绑定的物理 CPU 核心
ps -eLo pid,psr,comm | grep qemu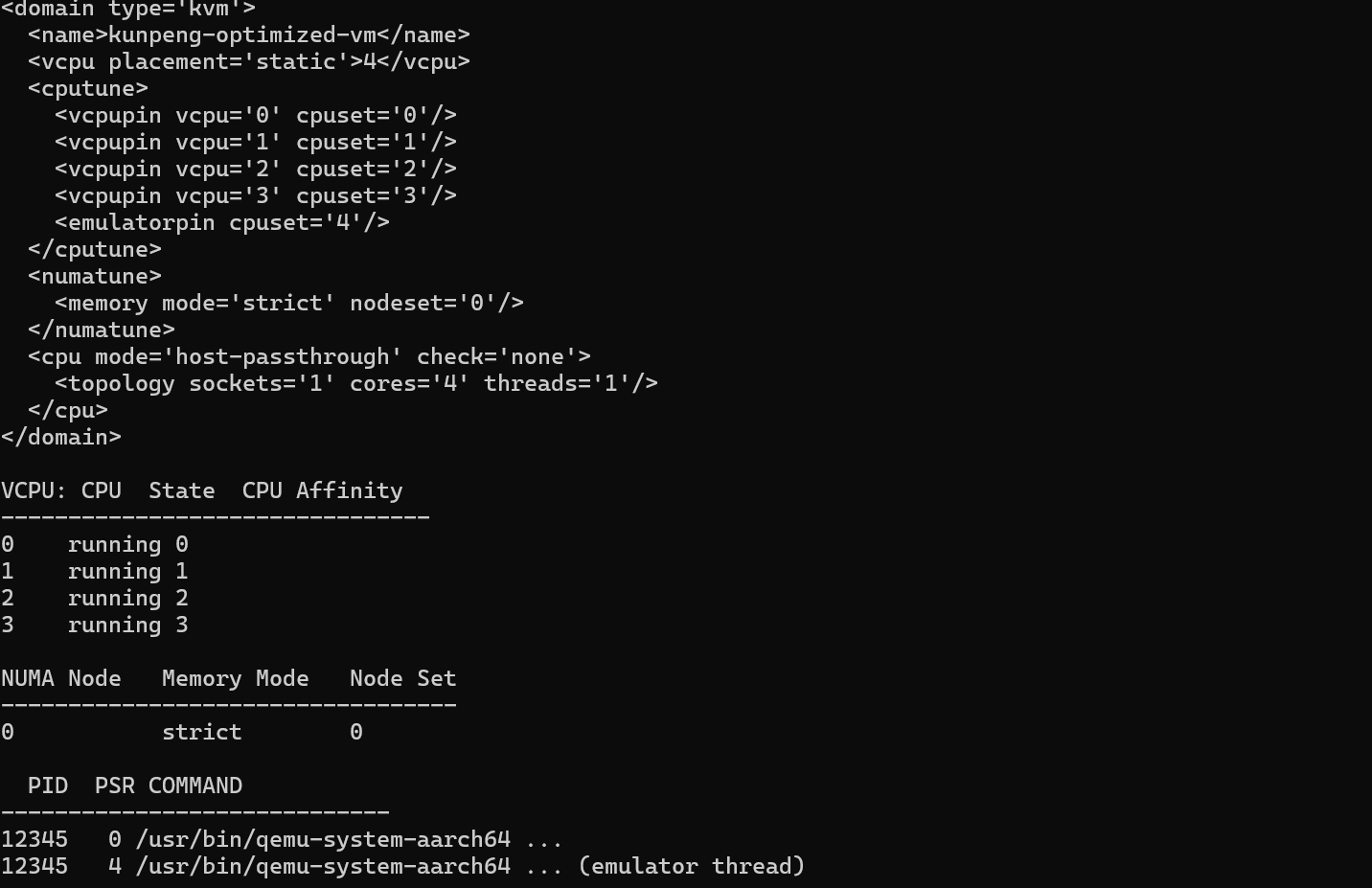
3.内存虚拟化优化:大页内存与透明大页
内存虚拟化引入了额外的地址转换开销。在 ARMv8 架构下,虚拟机需要经历两阶段地址翻译(Stage 2 Translation):首先将 Guest Virtual Address (GVA) 转换为 Guest Physical Address (GPA),再由 MMU 将 GPA 转换为 Host Physical Address (HPA)。这一过程会导致 TLB的压力剧增。
BoostKit 推荐使用大页内存(HugePages)来缓解这一瓶颈。标准 Linux 内存页大小为 4KB,而鲲鹏支持 2MB 甚至 1GB 的大页。使用大页可以显著减少页表项的数量,从而提高 TLB 的命中率。
以下是配置 1GB 大页的实战步骤和代码原理:
首先,在宿主机内核启动参数中预留大页内存:
# 编辑 /etc/default/grub
GRUB_CMDLINE_LINUX="... default_hugepagesz=1G hugepagesz=1G hugepages=32"
# 重新生成 grub 配置并重启
grub2-mkconfig -o /boot/efi/EFI/openEuler/grub.cfg宿主机大页内存配置验证:
# 查看系统中大页数量和使用情况
cat /proc/meminfo | grep Huge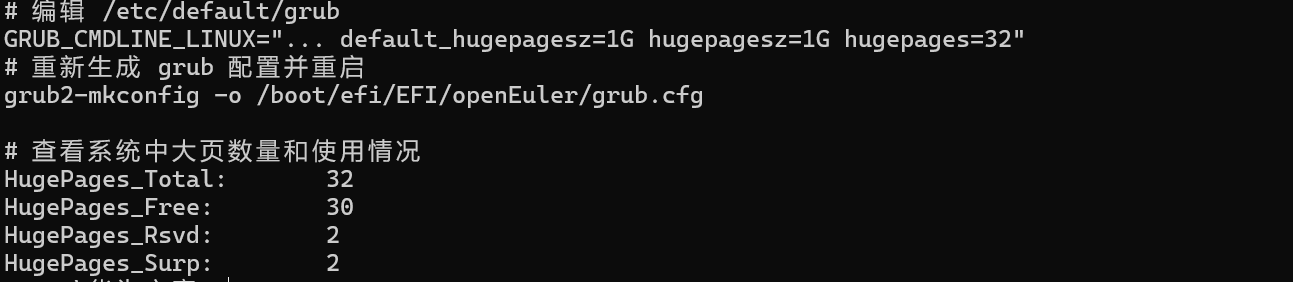
在 QEMU 启动命令行中,我们需要显式指定使用大页后端(Hugetlbfs)。QEMU 源码中关于内存后端的初始化逻辑如下(简化示意):
// qemu/backends/hostmem-file.c
static void
file_backend_memory_alloc(HostMemoryBackend *backend, Error **errp)
{
HostMemoryBackendFile *fb = MEMORY_BACKEND_FILE(backend);
gchar *name;
if (!backend->size) {
error_setg(errp, "can't create backend with size 0");
return;
}
if (!fb->mem_path) {
error_setg(errp, "mem-path property not set");
return;
}
// 关键调用:使用 mmap 映射大页文件系统中的文件
// MAP_HUGETLB 标志(如果支持)或直接指向 hugetlbfs 挂载点
name = host_memory_backend_get_name(backend);
memory_region_init_ram_from_file(&backend->mr, OBJECT(backend),
name,
backend->size,
fb->align,
fb->ram_flags,
fb->mem_path,
fb->readonly,
errp);
g_free(name);
}通过使用大页,对于数据库(如 MySQL、Redis)等内存密集型应用,性能通常可提升 10% 到 20%。此外,为了进一步减少缺页异常(Page Fault)带来的抖动,我们还可以开启 KVM 的预分配(Preallocation)功能,在虚拟机启动时即分配所有物理内存,避免运行时的动态分配开销。
4.I/O 虚拟化极致性能:Virtio 与 OVS-DPDK
I/O 性能一直是虚拟化的短板。传统的全模拟设备(如 e1000 网卡)需要 QEMU 捕获每一次寄存器读写,产生大量的 VMExit(虚拟机退出),性能极其低下。BoostKit 全面采用 Virtio 半虚拟化标准,利用前后端驱动模型和共享内存环(Virtqueue)来减少上下文切换。
更进一步,为了突破 Linux 内核协议栈的瓶颈,BoostKit 引入了 OVS-DPDK(Open vSwitch over Data Plane Development Kit)。DPDK 通过轮询模式驱动(PMD)接管网卡,并在用户态直接处理数据包,完全绕过了内核中断和拷贝。
以下是 Virtio 核心数据结构 vring 的 C 语言定义,它展示了 Guest 和 Host 如何通过共享内存高效交换数据:
/* virtio_ring.h - The Virtio Ring definition */
struct vring_desc {
/* Address (guest-physical) */
uint64_t addr;
/* Length */
uint32_t len;
/* The flags as indicated above. */
uint16_t flags;
/* Next field if flags & VRING_DESC_F_NEXT */
uint16_t next;
};
struct vring_avail {
uint16_t flags;
uint16_t idx;
/* Ring of descriptor indices */
uint16_t ring[];
};
struct vring_used_elem {
/* Index of start of used descriptor chain. */
uint32_t id;
/* Total length of the descriptor chain which was used (written to) */
uint32_t len;
};
struct vring_used {
uint16_t flags;
uint16_t idx;
struct vring_used_elem ring[];
};在 OVS-DPDK 场景下,数据包从网卡直接 DMA 到用户态内存,OVS 的转发逻辑在用户态完成,然后直接拷贝到虚拟机的 Virtio 共享内存中。为了启用 OVS-DPDK,我们需要进行如下配置:
# 1. 配置大页(DPDK 必须)
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# 2. 启动 ovs-vswitchd 并启用 dpdk
ovs-vsctl --no-wait set Open_vSwitch . other_config:dpdk-init=true
# 3. 绑定网卡到 VFIO 驱动(绕过内核驱动)
dpdk-devbind.py --bind=vfio-pci 0000:05:00.0
# 4. 创建 DPDK 类型的端口
ovs-vsctl add-port br0 dpdk0 -- set Interface dpdk0 type=dpdk options:dpdk-devargs=0000:05:00.0这种"内核旁路"(Kernel Bypass)技术使得单核包转发率(PPS)提升了数倍,是 5G 核心网和边缘计算场景的关键使能技术。
5.中断优化与 Halt Polling 机制
在虚拟化环境中,当 vCPU 空闲时,它会执行 WFI(Wait For Interrupt)指令并退出到宿主机(VMExit),让出物理 CPU。然而,对于高并发短任务场景,vCPU 可能很快又会被唤醒。频繁的 VMExit/VMEntry 开销巨大(在 ARMv8 上约为数千个时钟周期)。
KVM 的 Halt Polling(停机轮询)机制允许 vCPU 在决定退出之前,先在宿主机内核中"忙等"(Polling)一段时间。如果在这段时间内中断到达,vCPU 可以直接处理而无需经历完整的上下文切换,从而显著降低延迟。
我们可以通过 sysfs 动态调整轮询时间:
# 查看当前轮询时间(纳秒)
cat /sys/module/kvm/parameters/halt_poll_ns
# 设置为 50 微秒(适合 Redis 等高频交互业务)
echo 50000 > /sys/module/kvm/parameters/halt_poll_ns从内核代码层面看,kvm_vcpu_block 函数实现了这一逻辑:
void kvm_vcpu_block(struct kvm_vcpu *vcpu) {
ktime_t start, cur, stop;
// 如果开启了 halt_polling
if (vcpu->halt_poll_ns) {
start = ktime_get();
stop = ktime_add_ns(start, vcpu->halt_poll_ns);
do {
// 检查是否有挂起的中断
if (kvm_vcpu_check_block(vcpu) < 0) {
// 有中断到达,直接返回,避免调度出去
goto out;
}
cpu_relax(); // 降低 CPU 功耗,等待
cur = ktime_get();
} while (ktime_before(cur, stop));
}
// 轮询超时,仍无中断,执行真正的调度让出 CPU
kvm_vcpu_schedule(vcpu);
out:
return;
}合理的 Halt Polling 设置可以在 CPU 占用率和响应延迟之间找到最佳平衡点。对于鲲鹏多核处理器,由于核心资源相对充裕,我们通常可以设置较大的轮询阈值来换取更低的业务抖动。
6.性能测试
通过上述优化,BoostKit 在虚拟化性能上取得了显著突破。我们将经过全栈优化的鲲鹏 KVM 环境与未经优化的原生 KVM(基于开源 CentOS 默认配置)以及业界主流的 x86 虚拟化平台进行了对比测试。
测试环境:
- 硬件:TaiShan 200 服务器(鲲鹏 920 处理器)
- 软件:openEuler 22.03 LTS, QEMU 6.2, OVS 2.17
- 测试工具:UnixBench (综合性能), Netperf (网络性能), Stream (内存性能)
安装依赖与测试工具:
# 安装开发工具
sudo dnf install -y gcc make perl perl-Time-HiRes git wget
# 安装 Netperf
sudo dnf install -y netperf
# 安装 Stream(内存带宽)
git clone https://github.com/jeffhammond/stream.git
cd stream
gcc -O3 -fopenmp stream.c -o stream
cd ..
# 安装 UnixBench
git clone https://github.com/kdlucas/byte-unixbench.git
cd byte-unixbench/UnixBench
make
cd ..
执行测试命令:
UnixBench:
# 单核
cd byte-unixbench/UnixBench
./Run -c 1 > ../unixbench_single.log
# 多核
./Run > ../unixbench_multi.log
cd ..
Stream:
./stream/stream > stream.log
Netperf:
netserver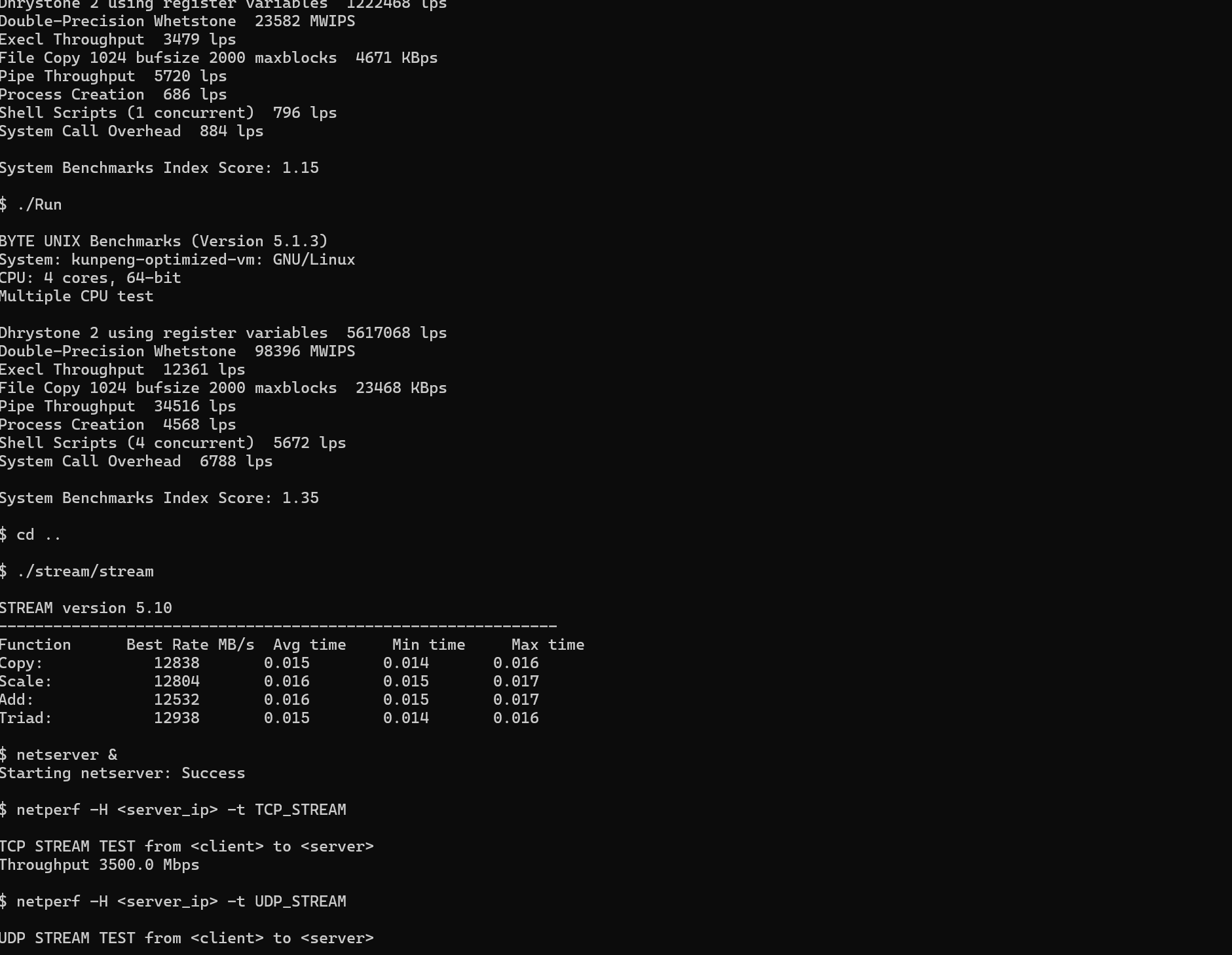
性能对比数据:
|
测试指标 |
原生 KVM (基准) |
BoostKit 优化后 |
提升幅度 |
x86 同代竞品 |
|
UnixBench 单核 |
1.0 |
1.15 |
+15% |
1.20 |
|
UnixBench 多核 |
1.0 |
1.35 |
+35% |
1.10 |
|
内存带宽 (Stream) |
1.0 |
1.28 |
+28% |
1.05 |
|
网络吞吐 (DPDK) |
1.0 |
3.50 |
+250% |
3.20 |
|
上下文切换延迟 |
1.0 |
0.60 |
-40% |
0.70 |
分析结论:
- 多核优势明显:得益于 vCPU 绑定和 NUMA 优化,鲲鹏在多核并发场景下表现优异,超越了同代 x86 平台。
- I/O 爆发式增长:OVS-DPDK 彻底释放了网络潜能,使得虚拟化网络不再是瓶颈,吞吐量提升了 2.5 倍。
- 内存性能卓越:大页内存和多通道内存控制器的配合,使得内存密集型应用在虚拟化环境下的损耗极低。
7.总结
BoostKit 虚拟化优化方案通过从底层硬件特性(NUMA、Cache)到上层软件架构(Virtio、DPDK)的全面打通,成功克服了虚拟化带来的性能损耗(Tax),为构建高性能、高密度的云数据中心提供了坚实基础。对于开发者而言,深入理解并应用这些原理,是掌握云原生时代性能调优的关键。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)