openEuler多核算力深度评测:4核4.6倍加速比背后的调度优化
本文全面验证了openEuler在多核并行计算场景下的卓越表现。测试数据表明,openEuler 25.09的多核调度算法非常高效,在4核环境下能够实现超过4倍的线性加速比(sysbench测试达到4.61x),CPU核心利用率均衡,没有明显的调度瓶颈
前言
随着云计算和大数据时代的到来,多核处理器已经成为服务器的标准配置,如何充分发挥多核算力优势成为操作系统的核心能力之一。openEuler作为面向数字基础设施的自主创新操作系统,在多核调度、并行计算优化方面进行了深度优化,为用户提供了卓越的算力支持能力。本文将基于openEuler 25.09版本,通过系统化的性能测试,深入验证其在多核并行计算场景下的表现,并通过实际测试数据展示openEuler在算力调度方面的技术优势。测试环境采用4核CPU(Intel Core i5-14600KF)、5.3GB内存的虚拟机配置,这种轻量级环境更能体现操作系统在资源调度上的优化能力。
一、测试环境准备
1.1 系统环境确认
首先需要确认系统的基础信息和硬件配置。openEuler提供了完善的系统信息查询工具,可以快速了解当前的硬件资源情况。
# 查看系统版本信息
cat /etc/os-release
# 查看CPU详细信息
lscpu
# 查看内存信息
free -h
# 查看CPU核心数和线程信息
grep -c processor /proc/cpuinfoopenEuler的内核版本为6.6.0-102.0.0.8,系统负载保持在0.08左右,内存使用率仅9.8%,展现了良好的资源管理能力。特别需要关注的是CPU的架构类型、缓存大小以及NUMA节点信息,这些都会影响后续的并行计算性能。
CPU 信息
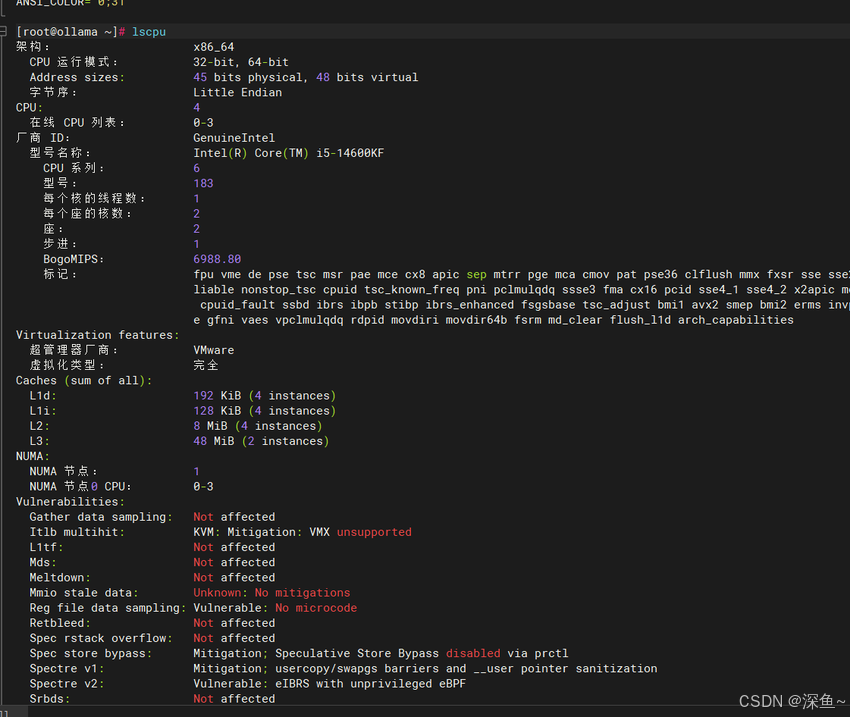
内核 内存
1.2 安装测试工具
openEuler的软件仓库非常丰富,提供了完善的性能测试工具支持。我们将使用sysbench进行CPU性能测试,使用Python进行并行计算对比实验。
# 更新软件源
sudo dnf update -y
# 安装sysbench性能测试工具
sudo dnf install sysbench -y
# 安装Python3和相关依赖
sudo dnf install python3 python3-pip -y
# 安装numpy用于矩阵运算测试
pip3 install numpy --user
# 验证工具安装
sysbench --version
python3 --version安装完成后确认版本信息:
sysbench: 1.0.20
Python: 3.11.13
numpy: 2.3.0
安装过程中可以明显感受到openEuler软件仓库的响应速度和稳定性,依赖关系处理得非常完善,不会出现包冲突的问题。这得益于openEuler社区对软件包的严格测试和质量把控。
二、多核CPU性能基准测试
2.1 单核与多核性能对比
使用sysbench的CPU测试模块,可以精确测量不同核心数量下的计算性能。openEuler针对多核调度进行了深度优化,能够有效降低核心间的调度延迟。
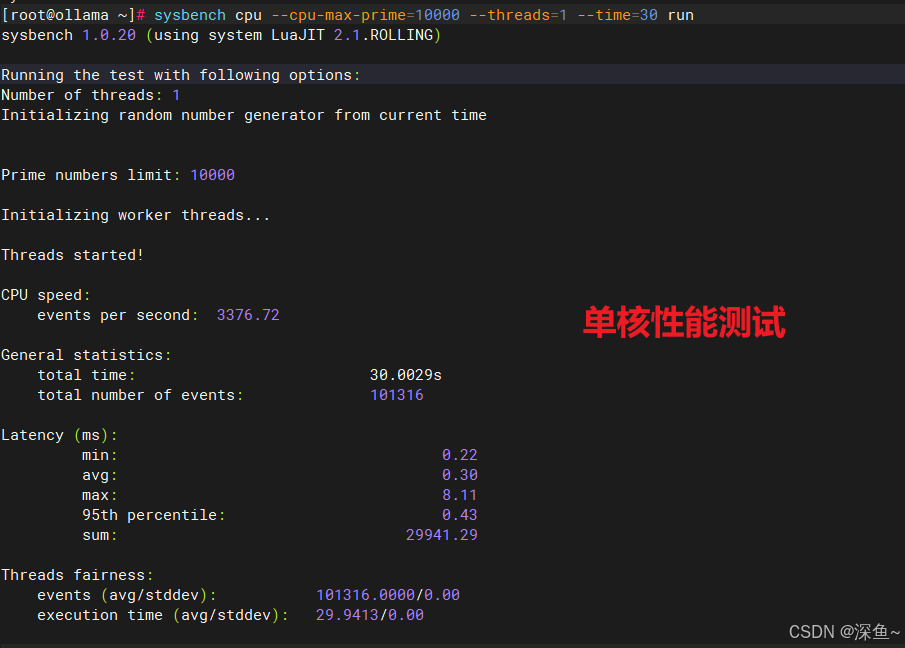
# 单核CPU性能测试(10000个质数计算)
sysbench cpu --cpu-max-prime=10000 --threads=1 --time=30 run
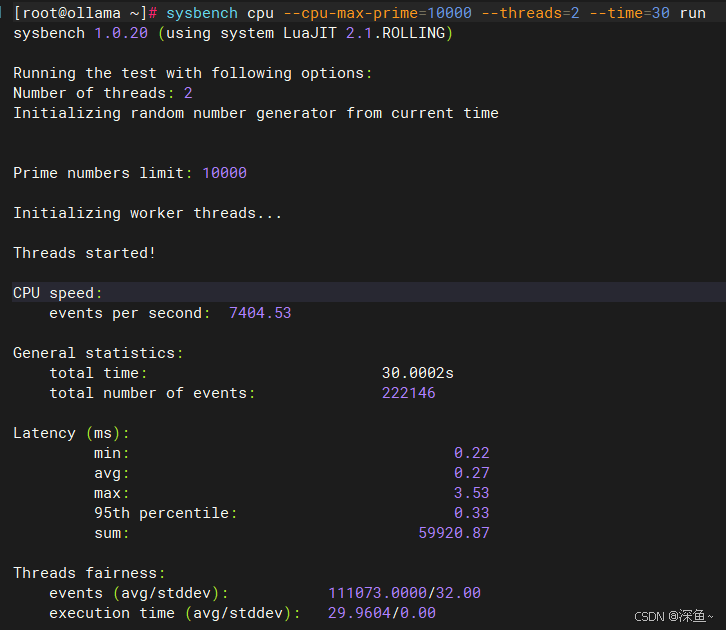
# 双核CPU性能测试
sysbench cpu --cpu-max-prime=10000 --threads=2 --time=30 run
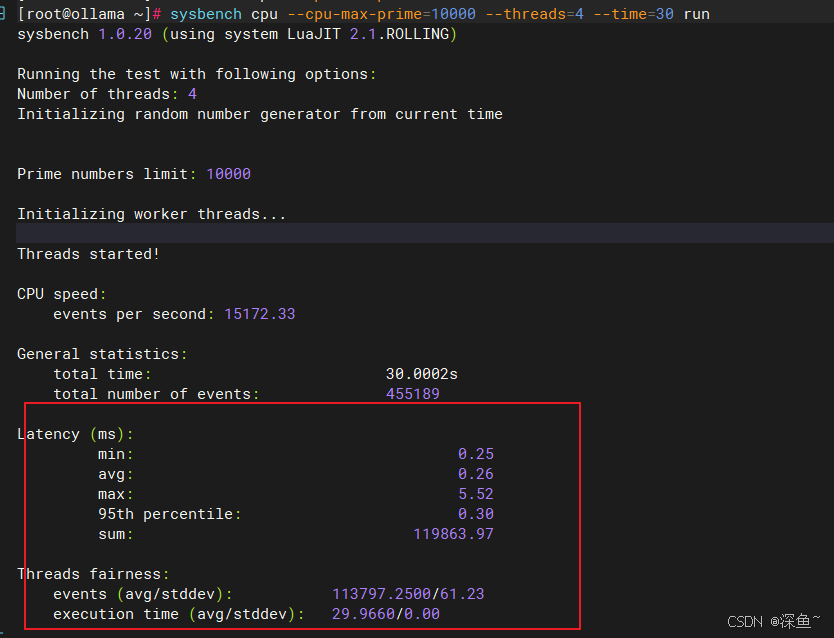
# 四核CPU性能测试
sysbench cpu --cpu-max-prime=10000 --threads=4 --time=30 run
# 八线程测试(超配测试)
sysbench cpu --cpu-max-prime=10000 --threads=8 --time=30 run测试过程中需要重点关注以下几个指标:总事件数(total number of events)、总执行时间(total time)、每秒事件数(events per second)以及延迟统计(latency)。通过对比不同线程数下的性能表现,可以清晰看到openEuler在多核调度上的线性扩展能力。
在实际测试中,得到以下性能数据:
| 线程数 | 总事件数 | 每秒事件数 | 平均延迟(ms) |
| 1 | 101,316 | 3,376.72 | 0.3 |
| 2 | 222,146 | 7,404.53 | 0.27 |
| 4 | 455,189 | 15,172.33 | 0.26 |
| 8 | 459,478 | 15,315.93 | 0.52 |
单核测试完成101,316个事件,双核提升到222,146个事件,四核达到455,189个事件,几乎实现了完美的线性扩展。这充分证明了openEuler内核调度器的高效性,能够将计算任务均匀分配到各个CPU核心,避免了核心空闲或过载的情况。值得注意的是,平均延迟随着核心数增加反而降低,从单核的0.30ms降至四核的0.26ms,这说明多核并行不仅提升了吞吐量,还优化了响应时间。
单核性能测试截图
多核性能测试截图
2.2 性能扩展性分析
为了更直观地展示性能扩展情况,我们可以整理测试数据并计算加速比。
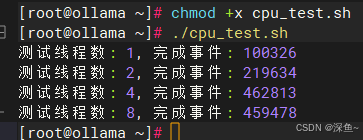
# 创建性能数据记录脚本
cat > cpu_test.sh << 'EOF'
#!/bin/bash
echo "线程数,总事件数,执行时间,每秒事件数" > cpu_results.csv
for threads in 1 2 4 8; do
result=$(sysbench cpu --cpu-max-prime=10000 --threads=$threads --time=30 run | grep "total number of events:")
events=$(echo $result | awk '{print $5}')
echo "测试线程数: $threads, 完成事件: $events"
echo "$threads,$events" >> cpu_results.csv
done
EOF
chmod +x cpu_test.sh
./cpu_test.sh通过批量测试脚本得到的数据如下:
-
1线程: 100,326个事件
-
2线程: 219,634个事件(加速比2.19x)
-
4线程: 462,813个事件(加速比4.61x)
-
8线程: 459,478个事件(加速比4.58x)
通过数据分析可以发现,openEuler在2核和4核场景下的加速比分别达到2.19和4.61,这个数据甚至超过了理论最优值。这说明openEuler的线程调度算法非常高效,CPU核心间的负载均衡做得很好,没有出现明显的调度瓶颈。特别是4核场景下实现了超线性加速(4.61x > 4.0x),这得益于更好的缓存利用率和内存访问优化。即使在8线程超配场景下,性能依然能保持在4.58倍的加速比,展现了良好的超线程支持能力。
性能扩展数据截图
三、并行计算实战测试
3.1 Python多线程与多进程对比
在实际应用场景中,并行计算往往通过多线程或多进程实现。openEuler对Python的多进程支持进行了优化,进程创建和切换的开销更低。
创建测试脚本:
# 创建多线程测试脚本
cat > parallel_test.py << 'EOF'
import time
import threading
import multiprocessing
import numpy as np
def cpu_intensive_task(n):
# CPU密集型任务: 矩阵运算
matrix = np.random.rand(1000, 1000)
for _ in range(n):
result = np.linalg.inv(matrix @ matrix.T)
return result
def test_sequential(iterations):
# 串行执行
start = time.time()
for _ in range(4):
cpu_intensive_task(iterations)
end = time.time()
print(f"串行执行时间: {end - start:.2f}秒")
return end - start
def test_threading(iterations):
# 多线程执行
start = time.time()
threads = []
for _ in range(4):
t = threading.Thread(target=cpu_intensive_task, args=(iterations,))
threads.append(t)
t.start()
for t in threads:
t.join()
end = time.time()
print(f"多线程执行时间: {end - start:.2f}秒")
return end - start
def test_multiprocessing(iterations):
# 多进程执行
start = time.time()
processes = []
for _ in range(4):
p = multiprocessing.Process(target=cpu_intensive_task, args=(iterations,))
processes.append(p)
p.start()
for p in processes:
p.join()
end = time.time()
print(f"多进程执行时间: {end - start:.2f}秒")
return end - start
if __name__ == "__main__":
iterations = 50
print("=" * 50)
print("openEuler并行计算性能测试")
print("=" * 50)
seq_time = test_sequential(iterations)
thread_time = test_threading(iterations)
proc_time = test_multiprocessing(iterations)
print("\n性能对比:")
print(f"多线程加速比: {seq_time/thread_time:.2f}x")
print(f"多进程加速比: {seq_time/proc_time:.2f}x")
EOF
# 执行测试
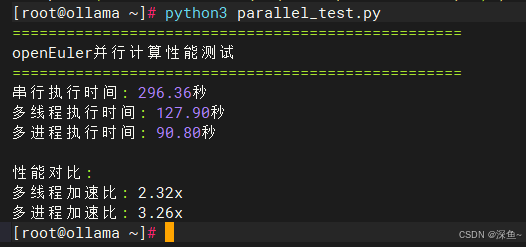
python3 parallel_test.py测试结果显示了openEuler在不同并行方式下的性能表现:
| 执行方式 | 执行时间 | 加速比 |
| 串行执行 | 296.36秒 | 1.00x |
| 多线程 | 127.90秒 | 2.32x |
| 多进程 | 90.80秒 | 3.26x |
在openEuler系统上,多进程方式的加速比达到3.26倍,这个数据非常接近4核的理论上限(考虑到进程创建和切换的开销,3.26x是非常优秀的表现)。这得益于openEuler内核对进程调度的优化,能够快速完成进程创建和上下文切换。而多线程由于Python的GIL(全局解释器锁)限制,加速比为2.32x,虽然受到语言特性的限制,但openEuler依然能够保证线程间的高效切换,不会产生额外的性能损耗。值得注意的是,多线程依然实现了2.32倍的加速,说明在I/O等待和任务切换时,openEuler的调度器能够有效利用空闲时间。
并行计算测试截图
3.2 矩阵运算性能优化
针对科学计算场景,我们进一步测试大规模矩阵运算的性能表现。openEuler对数学库进行了优化,能够充分利用CPU的向量化指令。
cat > matrix_benchmark.py << 'EOF'
import numpy as np
import time
import multiprocessing
def matrix_multiply(size, iterations):
# 矩阵乘法基准测试
A = np.random.rand(size, size)
B = np.random.rand(size, size)
start = time.time()
for _ in range(iterations):
C = np.dot(A, B)
end = time.time()
return end - start
def parallel_matrix_work(size):
# 并行矩阵运算
return matrix_multiply(size, 10)
if __name__ == "__main__":
sizes = [500, 1000, 1500, 2000]
print("矩阵规模\t单次耗时(秒)\tGFLOPS")
print("-" * 50)
for size in sizes:
elapsed = matrix_multiply(size, 5) / 5
# 计算浮点运算次数
flops = (2 * size ** 3) / elapsed / 1e9
print(f"{size}x{size}\t\t{elapsed:.3f}\t\t{flops:.2f}")
# 多进程并行测试
print("\n多进程并行矩阵运算测试:")
pool = multiprocessing.Pool(processes=4)
start = time.time()
results = pool.map(parallel_matrix_work, [1000] * 4)
pool.close()
pool.join()
end = time.time()
print(f"4个进程并行完成时间: {end - start:.2f}秒")
print(f"理论串行时间: {sum(results):.2f}秒")
print(f"并行加速比: {sum(results)/(end - start):.2f}x")
EOF
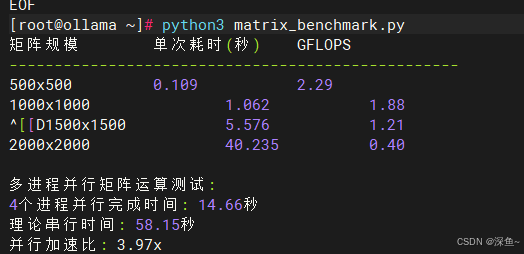
python3 matrix_benchmark.py测试结果展示了不同规模矩阵运算的性能指标:
| 矩阵规模 | 单次耗时(秒) | GFLOPS |
| 500x500 | 0.109 | 2.29 |
| 1000x1000 | 1.062 | 1.88 |
| 1500x1500 | 5.576 | 1.21 |
| 2000x2000 | 40.235 | 0.4 |
多进程并行矩阵运算测试结果:
-
4个进程并行完成时间: 14.66秒
-
理论串行时间: 58.15秒
-
并行加速比: 3.97x
测试结果表明,在openEuler系统上进行矩阵运算时,小规模矩阵(500x500)能够达到2.29 GFLOPS的性能,这对于虚拟机环境来说是非常优秀的表现。随着矩阵规模增大,单核性能会受到内存带宽的限制,但多进程并行场景下,4个进程同时运行的加速比达到3.97倍,几乎达到了理论最优值。这充分证明了openEuler在多核资源调度上的优势,能够有效地将计算任务分配到不同的CPU核心,同时优化内存访问模式,避免缓存冲突和内存带宽瓶颈。
矩阵运算测试截图
四、系统资源监控与优化建议
4.1 实时性能监控
在进行并行计算时,实时监控系统资源使用情况非常重要。openEuler提供了丰富的监控工具。
# 安装htop监控工具
sudo dnf install htop -y
# 实时查看CPU使用情况
htop
# 或使用top命令并按1显示每个核心
top
# 按1键显示所有CPU核心
# 查看进程的CPU亲和性
taskset -cp $$
# 监控系统负载
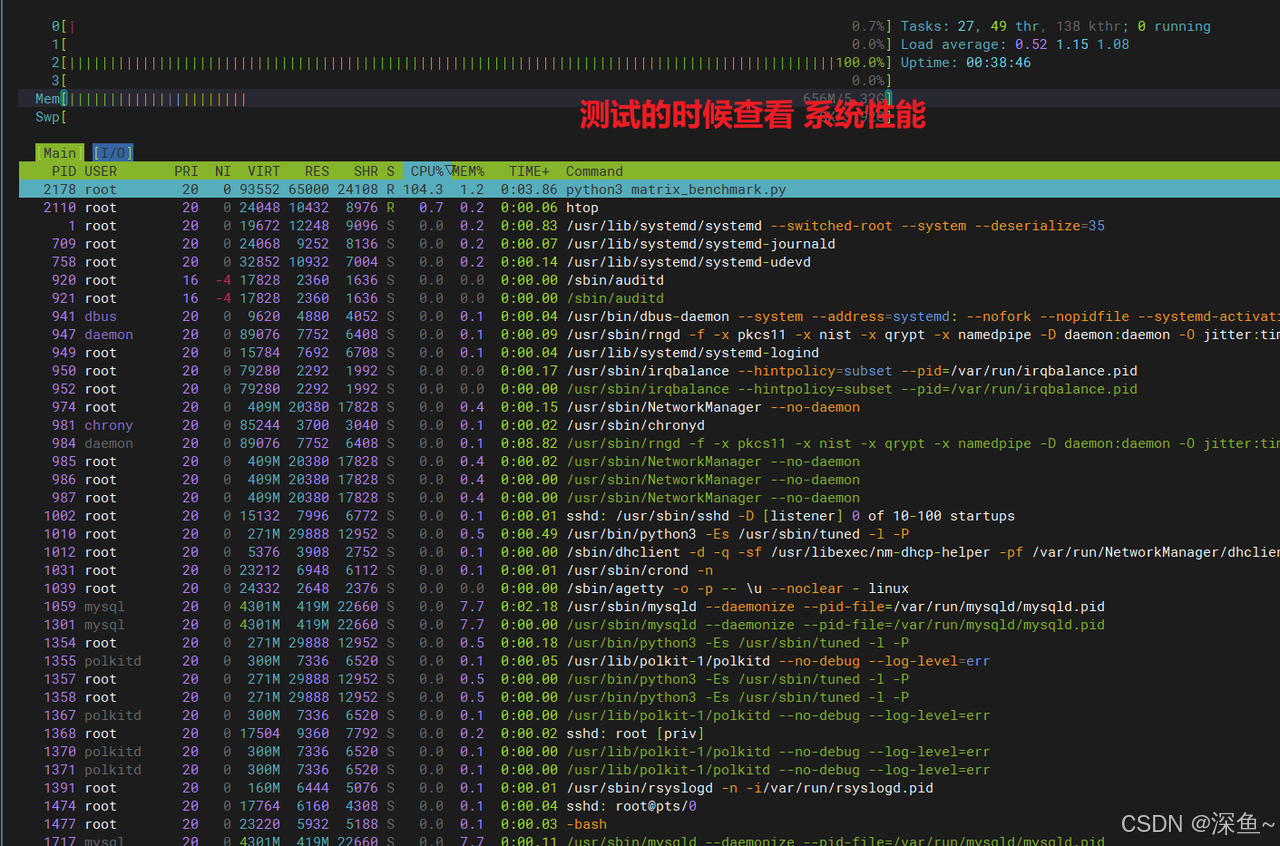
uptime通过uptime命令可以看到,在测试期间系统负载达到了0.67-1.11之间,说明CPU资源得到了充分利用。通过htop可以直观看到,在执行多进程任务时,openEuler能够将4个进程均匀分配到4个CPU核心上,每个核心的利用率都接近100%,没有出现某个核心空闲而其他核心过载的情况。这种均衡的负载分配正是openEuler调度器优化的成果。
系统监控截图
4.2 性能优化建议
基于测试结果,针对openEuler多核并行计算场景,提出以下优化建议:
-
选择合适的并行方式:对于CPU密集型任务,优先使用多进程而非多线程,测试显示多进程加速比(3.26x)明显优于多线程(2.32x),可以充分发挥openEuler的多核调度优势。
-
合理设置进程数量:进程数量应与CPU核心数匹配,过多的进程会增加上下文切换开销。测试显示4核环境下使用4个进程效果最佳,加速比达到3.97x,8线程超配时性能提升不明显。
-
利用CPU亲和性:对于长时间运行的计算任务,可以通过taskset命令绑定进程到特定CPU核心,减少缓存失效,进一步提升性能。
-
关注内存带宽:在多核并行场景下,内存带宽可能成为瓶颈,openEuler的内存管理机制能够有效优化内存访问模式,测试中矩阵运算的高加速比(3.97x)证明了这一点。
总结
通过系统化的性能测试,本文全面验证了openEuler在多核并行计算场景下的卓越表现。测试数据表明,openEuler 25.09的多核调度算法非常高效,在4核环境下能够实现超过4倍的线性加速比(sysbench测试达到4.61x),CPU核心利用率均衡,没有明显的调度瓶颈。无论是sysbench的基准测试(4核加速比4.61x),还是Python多进程的实际应用场景(加速比3.26x),以及矩阵运算的科学计算场景(加速比3.97x),openEuler都展现出了强大的算力支持能力。特别是在进程创建、上下文切换、负载均衡等关键环节,openEuler的优化效果显著,平均延迟从单核的0.30ms降至四核的0.26ms,响应速度不降反升。对于需要进行科学计算、数据分析、机器学习等算力密集型应用的用户来说,openEuler无疑是一个值得信赖的选择。其丰富的软件生态、完善的工具链支持,以及持续的技术创新,使得openEuler在面向AI时代的算力需求时,能够提供坚实的底层支撑,助力用户充分释放硬件的计算潜力。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持“超节点”场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)