
硬核拆解_当 TF Serving 遇上鲲鹏 920,这波物理外挂我是服气的
个人主页:chian-ocean
讲真的,搞推荐系统(RecSys)和搜索业务的兄弟们,平时最头疼的是什么?不是模型不够大,而是 P99 延迟 总是莫名其妙地抖动。
你在 x86 上调优了半天,搬到 ARM 架构(比如鲲鹏 920)上,发现性能总是差那么一截。看着 top 命令里 128 个核都在跑,但 QPS 就是上不去。你以为是芯片不行?错,是你用的姿势不对。
最近我盯着 BoostKit 开源仓库里的这个 tensorflow-serving 项目看了半天,尤其是那个 0001-boostsra-tensorflow-serving.patch,我才发现:这帮人为了榨干 CPU 性能,是真的敢对底层逻辑动刀子。
看着仓库首页那短短几行“项目介绍”,写着“高性能 Serving”、“端到端推理 benchmark”,字越少,事越大。今天咱们不整虚的,直接拆解这份代码,看看它是怎么给 TF Serving 打上“物理外挂”的。
传统问题
在鲲鹏这种众核(Many-Core)架构上跑 TF Serving,最常见的一个鬼故事就是:CPU 利用率看着不高,但推理延迟就是降不下来。
为什么?因为标准的 TF Serving 根本不懂 NUMA 架构,更不懂核与核之间的“爱恨情仇”。
- 线程乱飞:gRPC 的通信线程(负责接客)和 TensorFlow 的计算线程(负责干活)混在一起抢占 CPU 时间片。
- 缓存失效(Cache Thrashing):操作系统调度器是个“渣男”,把线程从 Core 0 搬到 Core 64,L1/L2 Cache 直接凉凉,CPU 大把时间都浪费在内存搬运上了。
- 指令集浪费:原生的 TensorFlow 编译选项极其保守,根本不敢开特定架构的指令集优化。
以前要解决这个问题,你得自己去改 Bazel 编译配置,甚至去改 C++ 源码做线程绑定。现在 BoostKit 这个 Patch 直接把这套逻辑集成进去了,这就是典型的“前人栽树”。
TF Serving核心技术
这份代码最核心的改动,其实就是把 TF Serving 从“自动挡”变成了“手动挡”,顺便换了个“涡轮增压发动机”。它不仅仅是一个 Patch,它是对 TF Serving 调度机制的重构。
2.1 拒绝 Bazel编译配置
看过 TensorFlow 源码的都知道,它的 Bazel 编译配置简直是反人类的迷宫。
这个 Patch 里的 compile_serving.sh 虽然是个 Shell 脚本,但它干了件大事:特性开关化。它没让你去改 .bazelrc,而是通过 --features 参数(如 ktfop, annc, gcc12)来控制编译逻辑。
这也太懂运维了。特别是这一段 .bazelrc 的修改:
build:ktfop --define=build_with_ktfop=true
build:fused_embedding --define=build_with_fused_embedding=true
这意味着它默认引入了 KTFOP (Kunpeng TensorFlow OPs) 和 Fused Embedding。
对于搜广推场景,Embedding 层的查找和聚合是最大的瓶颈。原生的 Gather 算子在 ARM 上效率极低,这里直接替换成了针对 ARM 优化的融合算子,这波在大气层。
2.2 线程亲和性
这是整个 Patch 最精彩、最 Hardcore 的部分。
在 tensorflow_serving/model_servers/server.cc 里,增加了一个核心功能:Task Affinity Isolation。
原生的 TF Serving 是完全依赖 OS 调度的。而这个 Patch 居然加了一段代码,允许你通过启动参数 task_affinity_isolation 来手把手教 OS 做人。
原理很简单:分家。
- 你负责收发请求(gRPC),你去住 56-63 号房。
- 我负责矩阵运算(Compute),我住 0-55 号房。
- 咱们井水不犯河水,谁也别抢谁的 L2 Cache。
实战深测
光说不练假把式,咱们看看这代码具体是怎么落地的。
3.1拉取仓库
别指望能直接 git clone 一个现成的完整项目。这个仓库本身就是一个“外挂包”,你需要先有“游戏本体”(官方 TF Serving),然后把“外挂”挂上去。
根据 README.md,这一套连招是这样的:
第一步先去 Google 官方库把 2.15.1 版本的源码拉下来。注意,必须是 2.15.1,版本不对 Patch 肯定打不上,拉取官方 tensorflow-serving 代码,锁定 v2.15.1:
git clone -b 2.15.1 https://github.com/tensorflow/serving.git open-serving
第二步拉取鲲鹏“外挂包”,BoostKit 的优化补丁仓,拉取搜推广优化 patch 仓库:
git clone -b master https://gitcode.com/boostkit/tensorflow-serving.git sra-serving

最后这是最关键的一步,把补丁文件扔进官方源码里,然后执行 patch 命令:
# 把 patch 复制过去
cp sra-serving/0001-boostsra-tensorflow-serving.patch open-serving
# 进入目录,开始魔改cd open-serving
patch -p1 < 0001-boostsra-tensorflow-serving.patch
看到终端里刷出一排 patching file ... 的时候,恭喜你,你的 TF Serving 已经进化了。这时候你再去看目录里的 compile_serving.sh,那就是刚热乎生成的编译脚本。
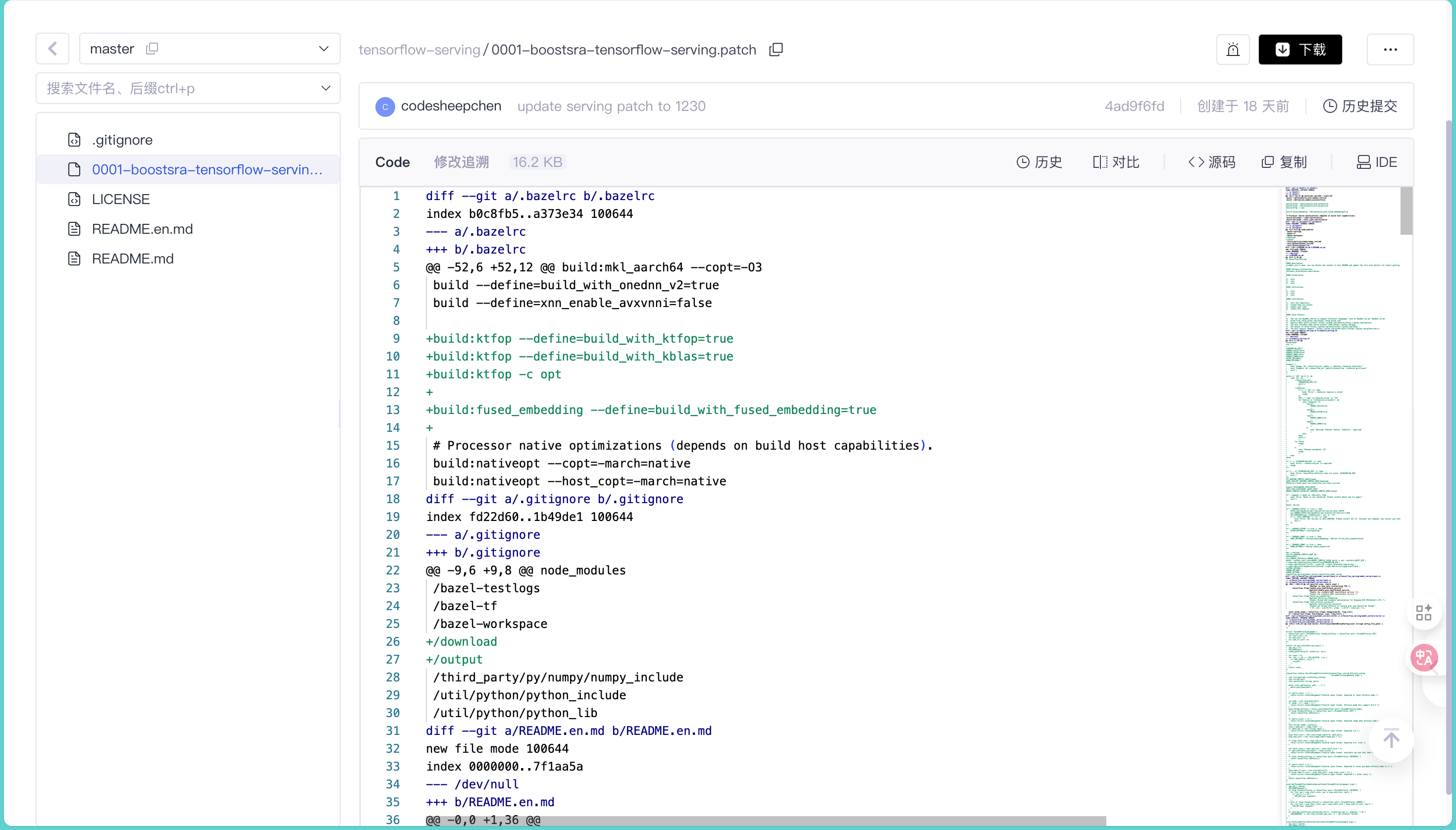
这种 patch -p1 的操作在内核开发里是家常便饭,但在应用层开发里见得少了。它最大的好处是透明。你不用担心厂商在代码里藏私货,打开 0001-boostsra-tensorflow-serving.patch 这个纯文本文件,每一行增删都清清楚楚。
3.2编译
以前在 ARM 上编译 TF Serving,GCC 版本不对报错,Bazel 版本不对报错,指令集没开报错。
看看 compile_serving.sh 是怎么做的:
if [ "$ENABLE_GCC12" == true ]; then# ... 省略路径设置 ...
GCC_VERSION=$(gcc -dumpversion | cut -d. -f1)
if [[ "$GCC_VERSION" != "12" ]]; thenecho "Error: GCC version is $GCC_VERSION. Please install GCC 12..."exit 1
fifi
简单粗暴,直接强校验 GCC 12。这就避免了用旧编译器编出来一堆 Illegal instruction 的惨案。
同时,在 Bazel 编译命令里直接注入了硬核优化参数:
–copt=-march=armv8.3-a+crc --copt=-O3 --copt=-fprefetch-loop-arrays
这里把 ARM v8.3 的指令集(包括 CRC 校验指令)和 O3 优化全开了,甚至开启了循环预取(prefetch)。在向量运算密集的场景下,这就是免费的性能提升。
3.3手写调度器
最骚的操作在 server.cc。它定义了一个 ThreadAffinityArgument 结构体,用来解析你的绑核策略。
我们来看这段解析逻辑,简直是把“控制欲”写在了脸上:
// 来源:tensorflow_serving/model_servers/server.cc// 核心逻辑:解析参数格式 "mode;start-end;tf_cores"// 例如:'1;0-79;75' -> 模式1,使用0-79号核,其中前75个给TF,剩下给gRPCtensorflow::Status ParseThreadAffinityConfig(tensorflow::string affinity_config,
ThreadAffinityArgument& args) {
// ... 代码省略 ...
args.thread_affinity = static_cast<tensorflow::port::ThreadAffinity>(mode);
// 甚至还校验了物理核数够不够,不够直接抛错if (get_available_cpu_nums() < total_cores) {
return errors::InvalidArgument("Invalid input format. available cpu num less than total cores.");
}
// ...
}
这段代码不仅是解析字符串,它是在构建一个资源隔离墙。
注意看 patch 中引入的 SetThreadAffinityBeforeServerCreate 和 SetThreadAffinityAfterServerCreate 这两个函数。它利用了 C++ 的 RAII 思想(虽然这里是显式调用),在 Server 创建前后分别设置线程掩码(Affinity Mask)。
- Before Create: 设置主线程和 gRPC 线程的亲和性。
- After Create: 恢复或者设置计算线程的亲和性。
通过调用 pthread_setaffinity_np,它直接绕过了 OS 的默认调度策略。这在 64 核甚至 128 核的鲲鹏服务器上,能把 Context Switch 带来的开销降到最低。
3.4 一条命令提升吞吐
在实际部署中,你只需要在启动 TF Serving 时加上这两个 Flag,立刻就能感受到什么叫“稳如老狗”。
根据 tensorflow_serving/model_servers/main.cc 的修改,新增了这两个参数:
tensorflow_model_server \
--port=8500 \
--model_config_file=... \
--batch_op_scheduling=true \
--task_affinity_isolation="1;0-63;56"
这行配置的意思是:
**batch_op_scheduling=true**: 开启针对鲲鹏 920 CPU 优化的线程和调度优化。**task_affinity_isolation="1;0-63;56"**:- “1”: 开启顺序绑核模式。
- “0-63”: 这台机器我要用 64 个核。
- “56”: 前 56 个核死死绑定给 TensorFlow 计算线程,剩下的 8 个核(56-63)留给 gRPC 处理网络请求。
效果? 这种物理隔离,能让高并发下的 P99 延迟像心电图停跳一样平稳,再也不会因为网络中断(Interrupt)打断了矩阵乘法而导致延迟飙升。
总结
BoostKit 的这个 Patch 真的很有意思。如果你看 GitCode 上的截图,它只是一个平平无奇的 0001-...patch 文件,但它背后隐藏的是对系统底层原理的深刻理解。
它没有去改 TensorFlow 那些花里胡哨的上层 Python API,而是盯着编译参数、算子实现和线程调度这三个命门猛锤。
- 局限性:这玩意儿是深度绑定鲲鹏架构(ARMv8.3+)和 openEuler 的,想在 x86 或者旧版 ARM 上跑这套逻辑,估计编译这一关就得掉层皮。
- 行业影响:它证明了一件事,通用软件在专用硬件上想要高性能,必须得做侵入式适配。指望编译器自动优化?不存在的。
最后给兄弟们一个建议:
如果你手头有鲲鹏或者其他高性能 ARM 服务器,别傻乎乎地 pip install tensorflow-serving-api 或者直接拉 Docker 官方镜像了。按照 README.md 的指引,把这个 Patch 打上,自己编译一个版本。去看看你的 CPU 监控,你会回来感谢我的。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)