
零基础入门深度学习:用汉明距离预测理解神经网络工作流程
摘要: 该代码实现了一个基于PyTorch的深度学习价格预测框架,通过商品价格预测场景展示回归问题的标准流程。框架包含数据生成、模型构建(全连接网络)、训练(Adam优化器+MSELoss)和评估(MAE指标)四个核心模块。特别适合初学者理解"数据处理→模型设计→训练优化→预测评估"的完整链路,并提供了二进制字符串汉明距离预测的具体实现示例,包括自定义数据生成、网络架构设计和预
这段代码是一个面向深度学习入门者的价格预测框架示例,非常适合初学者理解 “数据→模型→训练→预测” 的完整深度学习流程。它用 PyTorch 实现了一个端到端的回归任务(预测商品价格),结构清晰、逻辑简单,能帮助学习者快速掌握深度学习的核心环节。
一、代码的核心目的
通过 “汉明距离预测” 这个具体场景,展示深度学习解决回归问题(预测连续数值)的标准流程,让学习者理解:
- 如何用代码生成 / 处理数据;
- 如何设计神经网络模型;
- 如何训练模型并评估效果;
- 如何用训练好的模型做预测。
二、代码的整体结构(深度学习通用框架)
(一)、数据准备
(二)、模型构建
任务定位层:明确模型要解决的问题
网络架构层:核心骨架,确定网络结构(CNN/RNN)
层内配置层:细化每层参数,隐藏神经数量,卷积核大小,激活函数类型,dropout比例
向前传播:任何深度学习模型的构建都必须包含前向传播,它是模型能够 “工作” 的前提。在 PyTorch 中,forward方法就是前向传播的标准化实现,是nn.Module类的强制要求(否则模型无法运行)。
(三)、模型编辑与训练
编译配置层:数据准备 ——→ 模型初始化 ——→ 编译配置(指定优化器,损失函数,评价指标)
循环训练:梯度清零(优化器的辅助操作) ——→ 向前传播 (求出预测值)——→计算损失(损失函数)——→反向传播(计算梯度) ——→ 参数更新(优化器的核心操作)
梯度下降法在代码中的具体体现
-
获取梯度:反向传播(loss.backward())会自动计算损失函数对所有可训练参数的梯度
-
执行参数更新:优化器(这里是 Adam)的 step() 方法是梯度下降法的实际执行环节。
(四)、模型评估
更换评估指标(针对回归任务,如当前的汉明距离预测)
当前用的是平均绝对误差(MAE)

还可以用:
- 均方误差(MSE):
nn.MSELoss(),对大误差更敏感(惩罚更重),适合关注 “避免严重错误” 的场景;

-
均方根误差(RMSE):torch.sqrt(nn.MSELoss()(...)),将 MSE 开平方,单位与原始标签一致,更易解释;
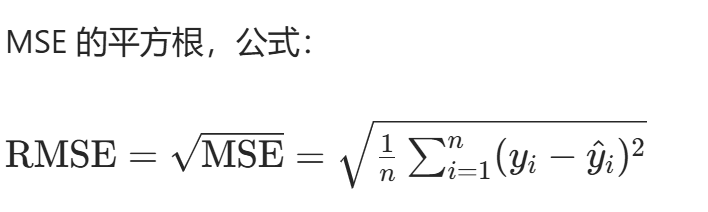
-
决定系数(R²):衡量模型对数据的解释程度(范围 0~1,越接近 1 越好),公式为1 - (预测误差平方和 / 真实值方差)。

import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.utils.data import Dataset, DataLoader
# 1. 数据生成模块(模拟二进制字符串数据)
class HammingDistanceDataset(Dataset):
def __init__(self, num_samples=10000):
self.num_samples = num_samples
# 生成随机5位二进制字符串(用0-1张量表示)
self.data = torch.randint(0, 2, (num_samples, 2, 5), dtype=torch.float32)
# 计算真实汉明距离(标签)
self.labels = torch.sum(torch.abs(self.data[:, 0] - self.data[:, 1]), dim=1, dtype=torch.float32)
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
# 输入:两个二进制字符串拼接(维度:10)
input_vec = torch.cat([self.data[idx, 0], self.data[idx, 1]], dim=0)
return input_vec, self.labels[idx]
# 2. 模型构建模块(对应4个层级)
class HammingDistanceModel(nn.Module):
def __init__(self):
super().__init__()
# 2.1 任务定位:回归任务(预测连续值0-5)
# 2.2 网络架构层:全连接网络(输入层→隐藏层→输出层)
self.network = nn.Sequential(
# 2.3 层内配置层:隐藏层神经元数量、激活函数
nn.Linear(10, 64), # 输入层(10维:5+5)→ 隐藏层1(64神经元)
nn.ReLU(), # 激活函数(引入非线性)
nn.Dropout(0.1), # 正则化(防止过拟合)
nn.Linear(64, 32), # 隐藏层2(32神经元)
nn.ReLU(),
nn.Linear(32, 1) # 输出层(1维:预测汉明距离)
)
def forward(self, x):
return self.network(x).squeeze() # 输出维度压缩(适配标签形状)
# 3. 编译与训练模块
def train_model():
# 3.1 数据准备
train_dataset = HammingDistanceDataset(num_samples=10000)
test_dataset = HammingDistanceDataset(num_samples=2000)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 3.2 模型初始化
model = HammingDistanceModel()
# 3.3 编译配置(优化器、损失函数、评估指标)
criterion = nn.MSELoss() # 回归任务损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3) # Adam优化器
metric = nn.L1Loss() # 评估指标(平均绝对误差)
# 3.4 训练循环(前向传播→损失计算→反向传播→参数更新)
epochs = 20
model.train()
for epoch in range(epochs):
total_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad() # ① 梯度清零(优化器的辅助操作)
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播(会自动计算损失函数对所有可训练参数的梯度)
optimizer.step() # ③ 参数更新(优化器的核心操作)
total_loss += loss.item() * inputs.size(0)
avg_train_loss = total_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}/{epochs}, 训练损失: {avg_train_loss:.4f}")
# 4. 模型评估模块
model.eval() #将模型切换到「评估模式」,关闭训练时专用的层
total_metric = 0.0
with torch.no_grad(): # 评估时禁用梯度计算
for inputs, labels in test_loader:
outputs = model(inputs)
#用平均绝对误差 (MAE)计算预测值(outputs)与真实标签(labels)的差距
total_metric += metric(outputs, labels).item() * inputs.size(0)
#最终计算测试集上的平均指标(avg_metric),衡量模型的泛化能力
avg_metric = total_metric / len(test_loader.dataset)
print(f"\n模型评估:平均绝对误差 = {avg_metric:.4f}")
# 测试示例(对应之前的10110 vs 11010)
test_input = torch.tensor([1,0,1,1,0, 1,1,0,1,0], dtype=torch.float32)
predicted_distance = model(test_input)
print(f"\n示例测试:10110 与 11010 的汉明距离预测值 = {predicted_distance.item():.2f}(真实值=2)")
return model
# 运行训练与评估
if __name__ == "__main__":
trained_model = train_model()如果想让模型预测自己的二进制字符串对的汉明距离,只需在代码末尾添加预测逻辑,例如:
# 在代码最后添加以下内容(训练完成后调用)
if __name__ == "__main__":
trained_model = train_model() # 先训练模型
# 预测新的二进制字符串对(例如:11100 和 00111)
def predict_hamming(str1, str2):
# 将二进制字符串转换为模型需要的输入格式(10维张量)
vec1 = torch.tensor([int(c) for c in str1], dtype=torch.float32)
vec2 = torch.tensor([int(c) for c in str2], dtype=torch.float32)
input_vec = torch.cat([vec1, vec2], dim=0)
# 预测(关闭梯度计算,提高效率)
trained_model.eval()
with torch.no_grad():
predicted = trained_model(input_vec)
return round(predicted.item(), 2) # 保留两位小数
# 测试新数据
test_str1 = "11100" # 自己的二进制字符串1
test_str2 = "00111" # 自己的二进制字符串2
result = predict_hamming(test_str1, test_str2)
print(f"\n新数据预测:{test_str1} 与 {test_str2} 的汉明距离 = {result}")

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)