
一天一个昇腾 Agent-Skills 小技巧:30 分钟完成 BEVFormer 自驾模型迁移与训练实战
提示词需要加载 https://gitcode.com/Ascend/agent-skills/skills 目录下的 drivingsdk-ascend-model-migration 这个 Skill,总结你当前具有的 Skills 能力。基于 DrivingSDK 套件的自动驾驶模型迁移 Skills 通过模块化技能设计、自动化环境搭建、标准化迁移流程与完整训练支持,实现了自动驾驶模型在昇腾
背景介绍
在自动驾驶技术快速发展的背景下,基于多视角特征融合的 3D 目标检测模型(如 BEVFormer)已成为行业主流。然而,这些模型普遍基于 GPU 环境开发,深度依赖自定义算子与特定依赖栈,难以直接迁移至昇腾 AI 基础软硬件平台。开发者在实际落地过程中常面临以下挑战:
- 环境配置复杂:OpenMMLab 生态(mmcv、mmdetection3d 等)依赖关系严格,版本冲突频发;
- 适配需要修改大量代码:需手动修改大量算子调用逻辑,涉及算子替换、数据格式转换与内存布局优化;
- 问题排查困难:缺乏统一调试工具与标准化流程,故障定位效率低。
为解决这些痛点,昇腾构建了一套基于 DrivingSDK 套件的自动驾驶模型迁移技能体系。通过标准化的工作流程、自动化 patch 应用和完整的训练脚本,帮助开发者快速完成模型迁移和训练。通过模块化设计、标准化流程与智能辅助能力,实现从环境搭建到模型训练的端到端高效支持,助力开发者将原本需数天完成的迁移工作压缩至 30 分钟内。
Skills 可通过以下地址获取:https://gitcode.com/Ascend/agent-skills/tree/master/skills/drivingsdk-ascend-model-migration
Skills 支持的模型与特性
模型支持概览
当前基于 DrivingSDK 套件的自动驾驶模型迁移 Skills 已支持主流模型 BEVFormer 的迁移:
| 模型类别 | 代表模型 | 状态 | 说明 |
|---|---|---|---|
| 3D 目标检测 | BEVFormer | ✅ 已支持 | 多视角 3D 目标检测 |
| 3D 感知 | BEVFusion | 🔄 开发中 | 场景理解与融合感知 |
| 端到端 | SparseDrive | 🔄 开发中 | 基于稀疏化表征的端到端模型 |
功能特性
- ✅ 远程开发支持:完整的 SSH 连接和容器管理能力
- ✅ 环境搭建自动化:一键安装 mmcv、mmdet、mmdet3d 等依赖
- ✅ NPU 适配零门槛:自动应用昇腾 DrivingSDK 提供的 patch 文件
- ✅ 训练脚本标准化:支持性能训练和精度训练两种模式
Skills 架构设计
整体架构
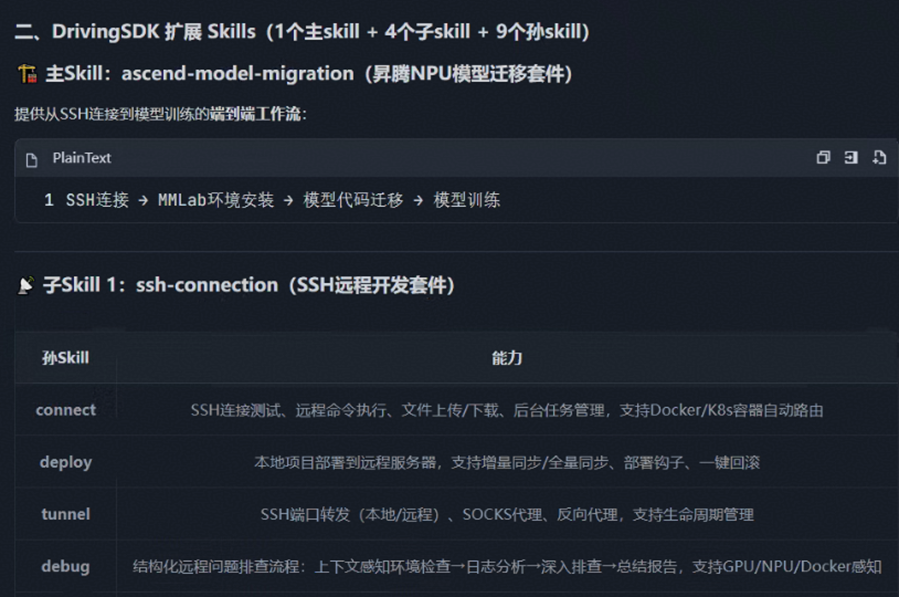
基于 DrivingSDK 套件的自动驾驶模型迁移 Skills 采用模块化设计,将模型迁移流程分解为 4 个核心技能模块,将复杂迁移任务拆解为可复用、可验证的原子能力单元:

各阶段 Skills 功能详解
阶段 1:ssh-connection(SSH 连接管理)
核心功能:建立与昇腾服务器和容器的安全连接。
关键能力:
- connect:底层通过 SSH 一键接入服务器或 Docker 容器
- debug:支持远程日志查看与环境诊断
- deploy:远程部署工具,传输文件和代码
- long-task:长时间任务管理,训练任务后台运行
- tunnel:SSH 隧道和端口转发,可视化监测
产出物:稳定可操作的远程开发环境
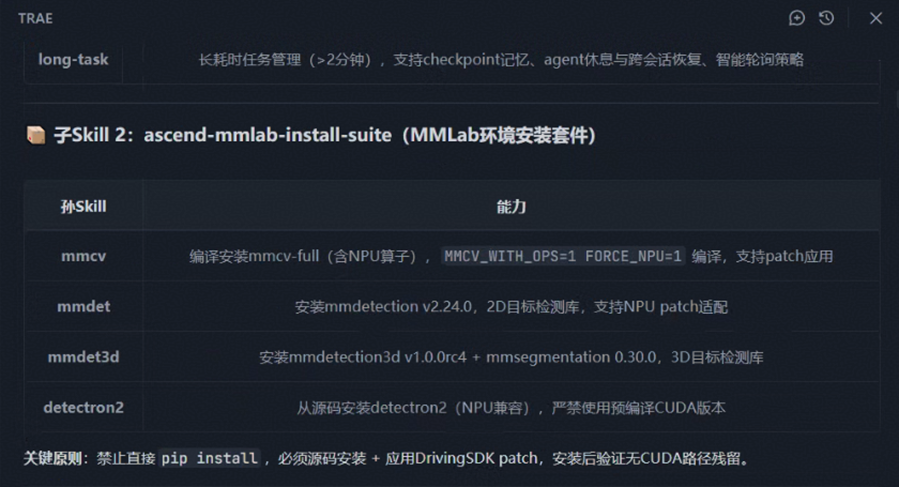
阶段 2:ascend-mmlab-install-suite(环境搭建)
核心功能:在昇腾 NPU 容器中构建完整的 OpenMMLab 开发环境。
安装组件:
| 组件 | 版本 | 说明 |
|---|---|---|
| mmcv-full | 1.7.2 | 含 NPU 算子的计算机视觉基础库 |
| mmdetection | 2.24.0 | 目标检测库 |
| mmsegmentation | 0.30.0 | 语义分割库 |
| mmdetection3d | 1.0.0rc4 | 3D 目标检测库 |
| detectron2 | 0.6 | Facebook 检测分割库 |
关键原则:
- ⚠️ 严禁直接 pip 安装:必须通过源码编译 + 应用 patch 方式安装
- ✅ 自动集成昇腾 DrivingSDK 提供的 NPU 适配补丁
- ✅ 验证 NPU 兼容性,确保无 GPU 依赖,完全适配 NPU 运行时
- ✅ 支持代理配置,应对网络受限场景
产出物:完整的 NPU 兼容开发环境
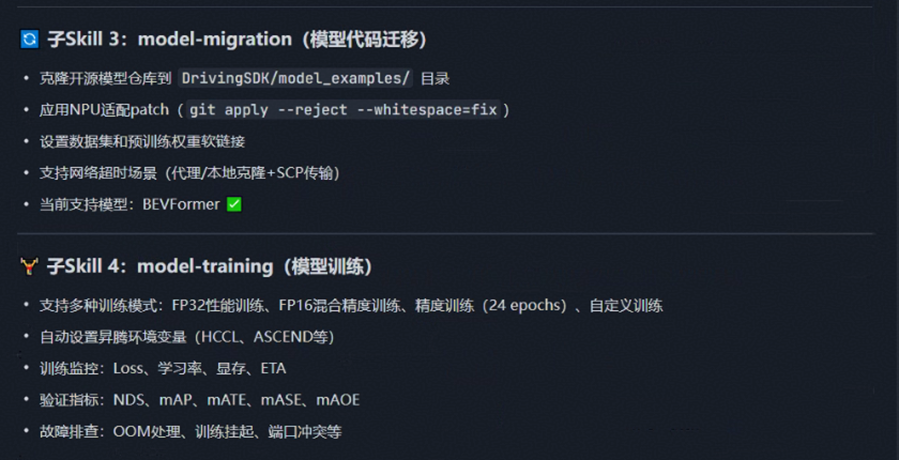
阶段 3:model-migration(模型迁移)
核心功能:将开源模型迁移到昇腾 AI 基础软硬件平台。
工作流程:
- 克隆仓库:克隆模型源码至
DrivingSDK/model_examples/BEVFormer - 切换版本:切换到指定的 commit 版本
- 应用 patch:自动应用 NPU 适配 patch 文件
- 配置数据:设置数据集和预训练权重软链接
关键特性:
- ✅ 在 DrivingSDK 目录结构下操作,patch 文件已就绪
- ✅ 自动处理 NPU 适配的代码修改
- ✅ 支持数据集和权重的软链接配置
- ✅ 支持多种网络策略:直连、代理、本地克隆 + SCP 传输
产出物:已适配 NPU 的可运行模型代码
阶段 4:model-training(模型训练)
核心功能:在昇腾上启动和监测训练。
训练模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| FP32 性能测试 | FP32 精度,快速性能测试 | 性能验证 |
| FP16 性能测试 | FP16 混合精度,快速测试 | 性能验证 |
| 完整训练 | 24 epochs,完整训练 | 模型训练 |
关键指标监测:
- 训练指标:Loss 值、学习率、迭代时间、内存使用
- 验证指标:NDS、mAP、mATE、mASE、mAOE
- 硬件指标:NPU 利用率、内存带宽、计算单元利用率
产出物:训练完成的模型权重文件和性能分析报告
实战案例:BEVFormer 迁移全流程
完整工作流演示
Step 1:加载识别 Skills —— 输出能力概述
提示词:
需要加载 https://gitcode.com/Ascend/agent-skills/skills 目录下的 drivingsdk-ascend-model-migration 这个 Skill,总结你当前具有的 Skills 能力。
Agent 自动总结输出 DrivingSDK 自驾模型迁移适配 Skills 能力概述:

Step 2:根据 Skills 梳理自动迁移环境配置 plan
提示词:
你需要进入 driving-train 这个容器,conda 环境使用 torch2.1.0_py38,请你参考 ascend-mmlab-install-suite 的 Skills 安装包,首先你要列出相应的 plan,待我确认后可以执行登陆容器环境,并执行安装过程。
Agent 梳理环境配置详细步骤:
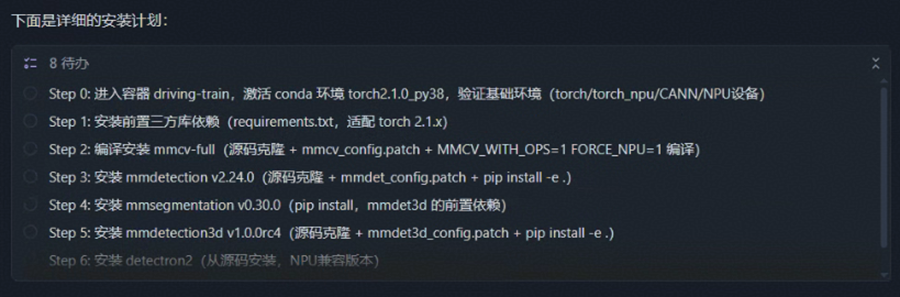
Agent 会自动确认操作计划是否符合预期:
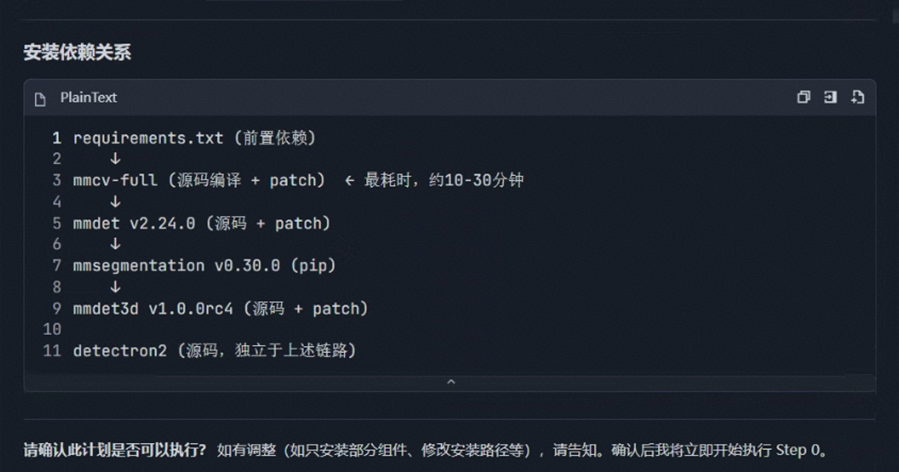
Step 3:准备 DrivingSDK
git clone https://gitcode.com/Ascend/DrivingSDK
cd DrivingSDK/model_examples/BEVFormer
Step 4:安装基础依赖项以及 MMLab 依赖
提示词:
执行上述规划的操作,完成 MMLab 库环境安装。
Agent:再次罗列安装计划明细
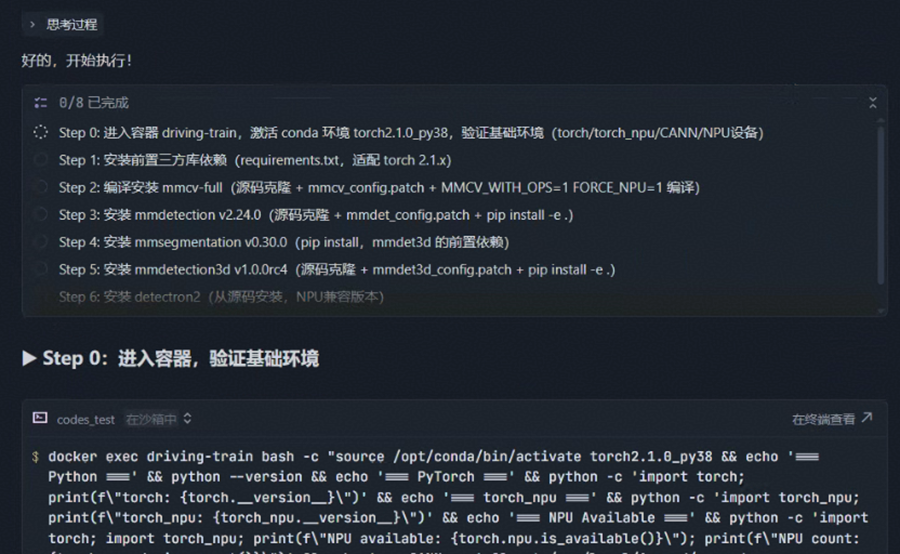
首先会安装基础依赖项:
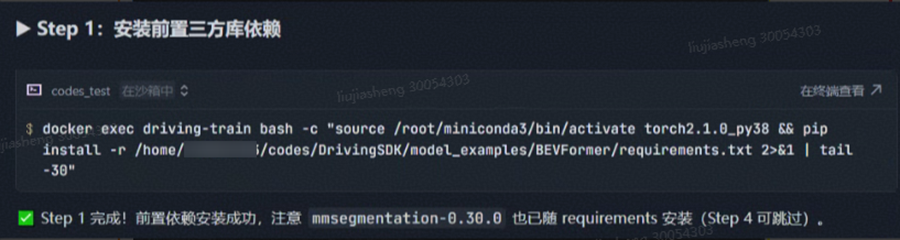
然后依次完成后续安装计划:
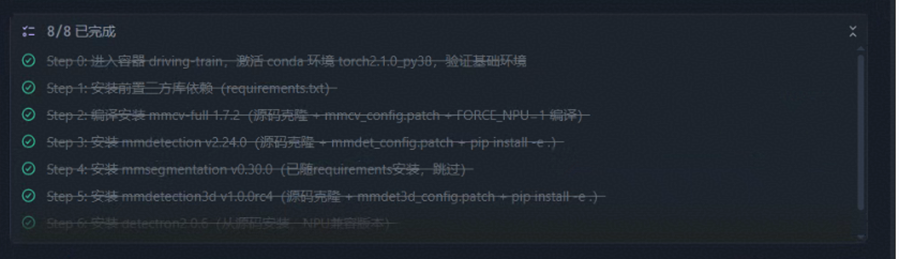
生成安装验证报告及安装总结:确保 MMLab 三方库可用。
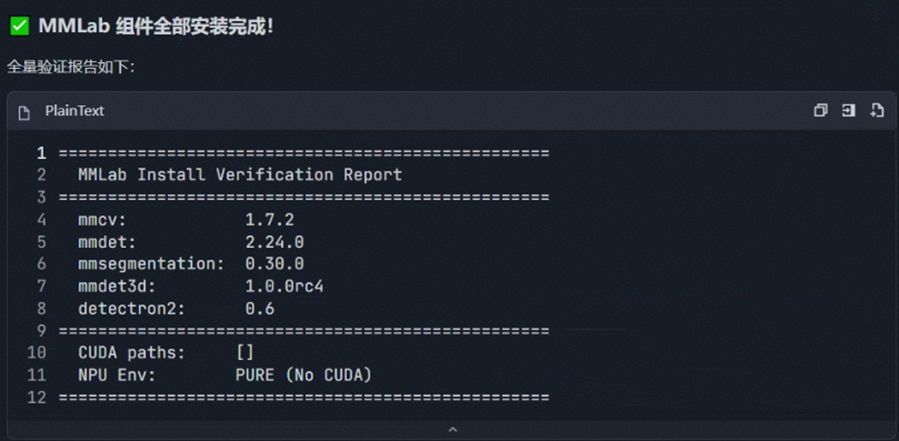
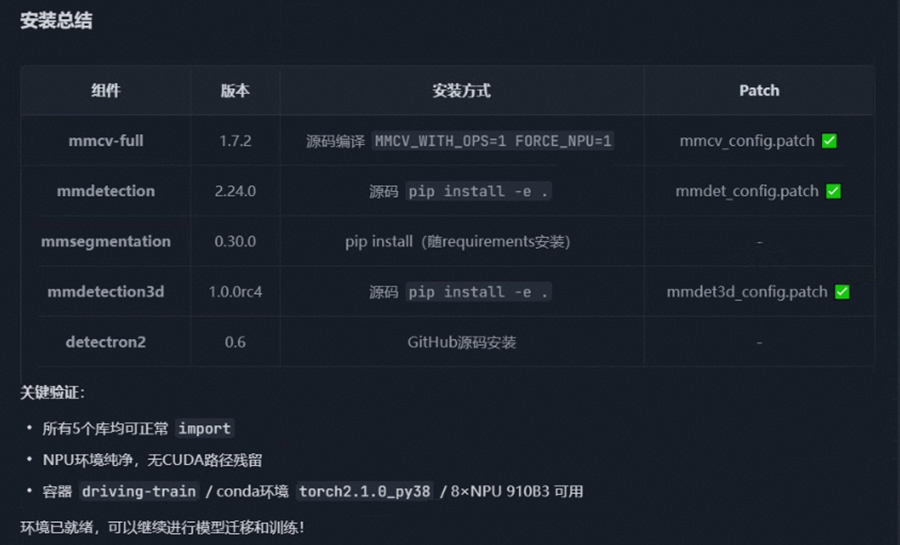
备注:需要注意的是,mmcv 安装可能会遇到超时情况,Skills 会指导 Agent 多次尝试获取日志,增大检测的时间间隔。
Step 5:迁移 BEVFormer 模型
关键目标操作:
# 克隆 BEVFormer 仓库
git clone https://github.com/fundamentalvision/BEVFormer.git
cd BEVFormer
# 应用 NPU 适配补丁
git checkout 66b65f3a1f58caf0507cb2a971b9c0e7f842376c
git apply --reject --whitespace=fix bev_former_config.patch
# 配置数据集和权重
mkdir -p data ckpts
ln -sf /path/to/nuscenes data/nuscenes
ln -sf /path/to/r101_dcn_fcos3d_pretrain.pth ckpts/
提示词:
你需要在 DrivingSDK/model_examples/BEVFormer 下面完成模型的迁移,参考 ascend-model-migration 这个 Skills。同样的,先给我一版 plan,我确认后可以执行。
Agent:给出详细的迁移计划。

Agent 自动确认数据集路径和权重路径:
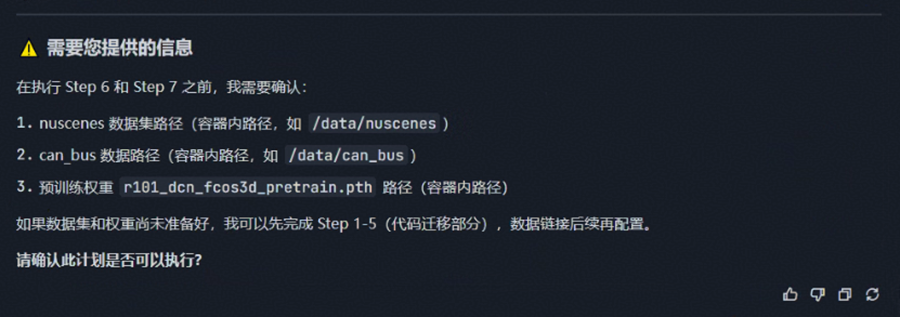
提示词:
先执行模型迁移部分
Agent:依次执行模型迁移流程
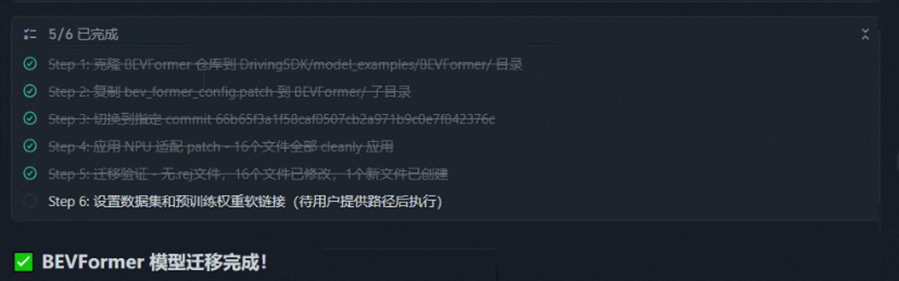
完成迁移报告,以及说明 “Patch 修改覆盖范围”
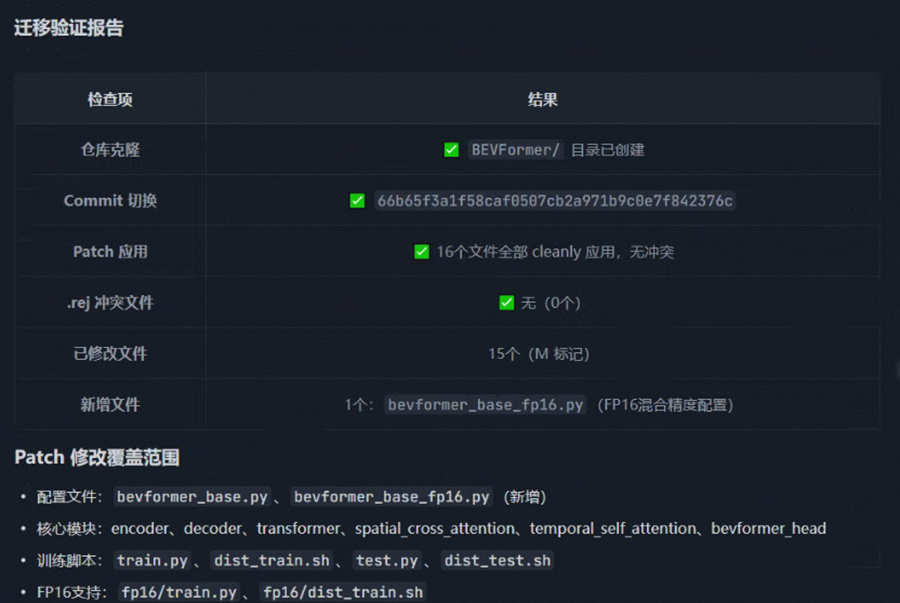
Step 6:设置数据集、权重文件路径
提示词:
数据集的 nuscenes 路径是 /home/xxx/datasets/v1.0-mini;can_bus 路径是 /home/xxx/datasets/can_bus;权重路径是 /home/xxx/weights/r101_dcn_fcos3d_pretrain.pt
Agent:完成设置数据集、权重文件,完成全量模型迁移
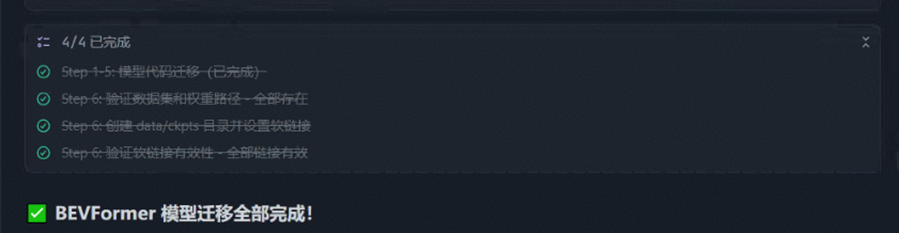
Agent 提示可进入训练阶段:
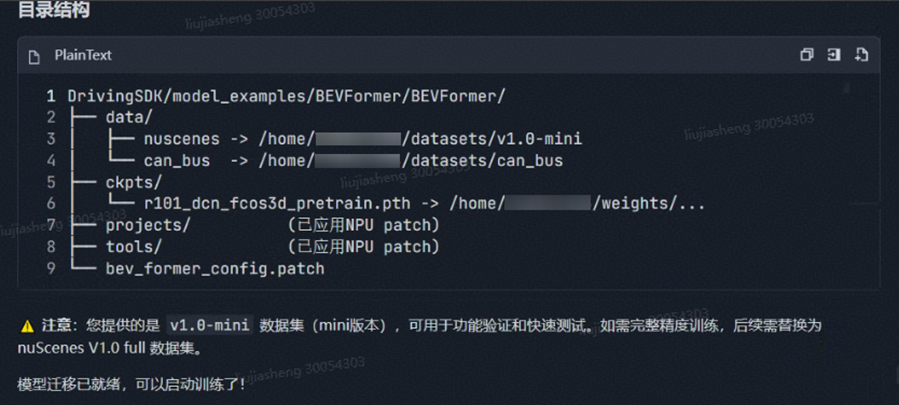
Step 7:启动模型训练后台任务
关键目标操作:
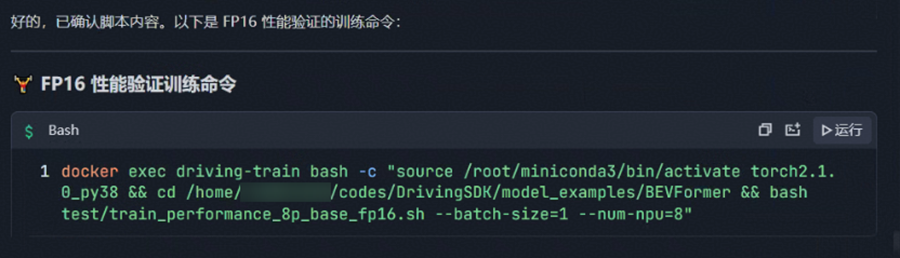
cd ..
bash test/train_performance_8p_base_fp16.sh --batch-size=1 --num-npu=8
提示词:
想要跑 FP16 场景的性能验证脚本,帮我提供训练命令,我确认一下后启动训练
Agent:给出执行命令,确认后可正常拉起训练:
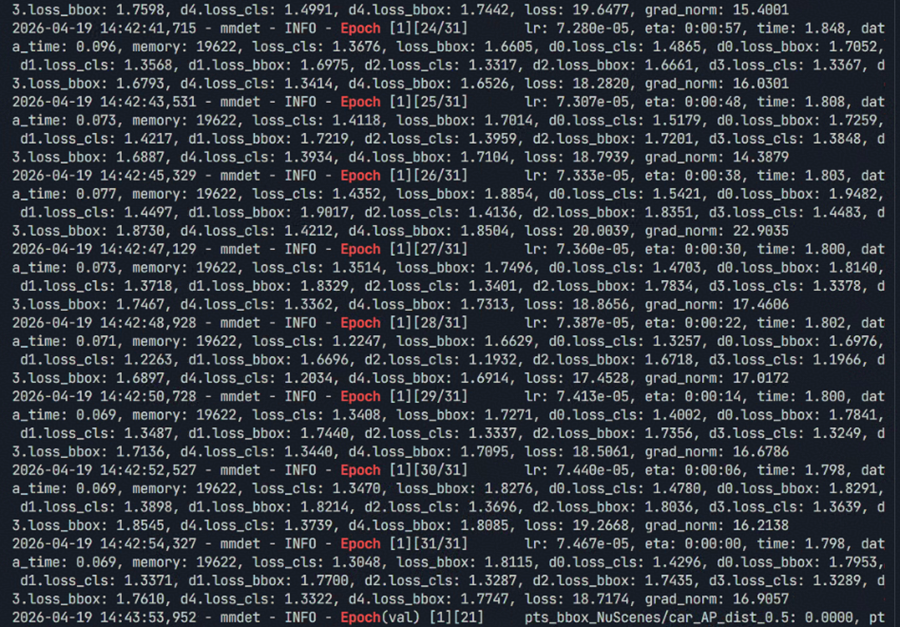
模型迁移训练时间统计
| 阶段 | 耗时 | 说明 |
|---|---|---|
| 环境搭建 | 25 分钟 | 自动化安装,受限于 MMLab 等三方库编译耗时久 |
| 模型迁移 | 5 分钟 | patch 自动应用 |
| 训练启动 | 5 分钟 | 脚本标准化 |
| 总计 | 35 分钟 | 完成从零到训练启动 |
核心价值与优势
相比传统迁移方式
| 对比维度 | 传统方式 | Skills |
|---|---|---|
| 环境搭建 | 手动安装,1 天 | 自动化脚本,25 分钟 |
| 模型适配 | 手动修改代码,1-2 天 | 自动应用 patch,即时完成 |
| 训练配置 | 手动编写脚本,半天 | 标准化脚本,即拿即用 |
| 问题排查 | 缺乏指导,耗时 | 完整文档和 troubleshooting |
| 总耗时 | 1-2 天 | 35 分钟 |
核心价值
- 效率提升:将模型迁移时间从数天缩短至 30 分钟
- 降低门槛:无需深入了解适配细节
- 质量保证:标准化的 patch 和训练脚本确保正确性
- 可复现性:完整的工作流文档,便于团队协作
总结与展望
基于 DrivingSDK 套件的自动驾驶模型迁移 Skills 通过模块化技能设计、自动化环境搭建、标准化迁移流程与完整训练支持,实现了自动驾驶模型在昇腾 AI 基础软硬件平台上的高效落地。
- 当前成果:BEVFormer 已实现端到端迁移与训练,性能达标。
- 获取地址:https://gitcode.com/Ascend/agent-skills/tree/master/skills/drivingsdk-ascend-model-migration
- 未来规划:
- 支持更多主流模型:BEVFusion、SparseDrive 等
- 增强自动化诊断能力:自动识别兼容性问题
- 推出可视化操作面板,提升易用性
- 社区共建:欢迎开发者贡献新模型支持与优化建议,共同完善昇腾生态。开源地址:https://gitcode.com/Ascend/agent-skills
30 分钟,从零开始完成 BEVFormer 在昇腾 NPU 上的迁移与训练——这不是理想,而是现实。基于 DrivingSDK 套件的自动驾驶模型迁移技能正在重新定义 AI 模型迁移的效率边界,让开发者聚焦于创新,而非重复造轮子。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)