
【昇腾训练】-MindSpeed 极速入门
【昇腾训练】-MindSpeed 极速入门
适用: 有 LLM 训练基础, 第一次在昇腾 NPU 上做训练开发的工程师
配套版本: MindSpeed Core 26.0.0 / CANN 9.0.0 / torch_npu 26.0.0 / Python 3.10.x
配套仓: Ascend/MindSpeed (主仓) + Ascend/MindSpeed-LLM (LLM 端到端)
一、MindSpeed 不是"加速器", 是覆盖训练端到端的工程化框架
关键洞察: 多数新人把 MindSpeed 当作"NPU 版 DeepSpeed"或"又一个加速库", 实际它是 上接 LLM/MM 套件 / 下接 CANN 算子层 的端到端平台, 覆盖从数据预处理到权重转换的完整流程.
MindSpeed 生态 = Core 加速库 + LLM 端到端套件 + MM 多模态套件 + RL 强化学习加速框架
| 仓 | 角色 | 适用 |
|---|---|---|
Ascend/MindSpeed |
核心加速库 (在 Megatron 上做适配) | 所有训练场景 |
Ascend/MindSpeed-LLM |
端到端 LLM 训练套件 (100+ 模型) | LLM 预训练/微调 |
Ascend/MindSpeed-MM |
多模态训练套件 (FSDP2 配置) | 多模态模型 |
Ascend/MindSpeed-RL |
强化学习加速框架 (RLHF/GRPO) | LLM RL 训练 |
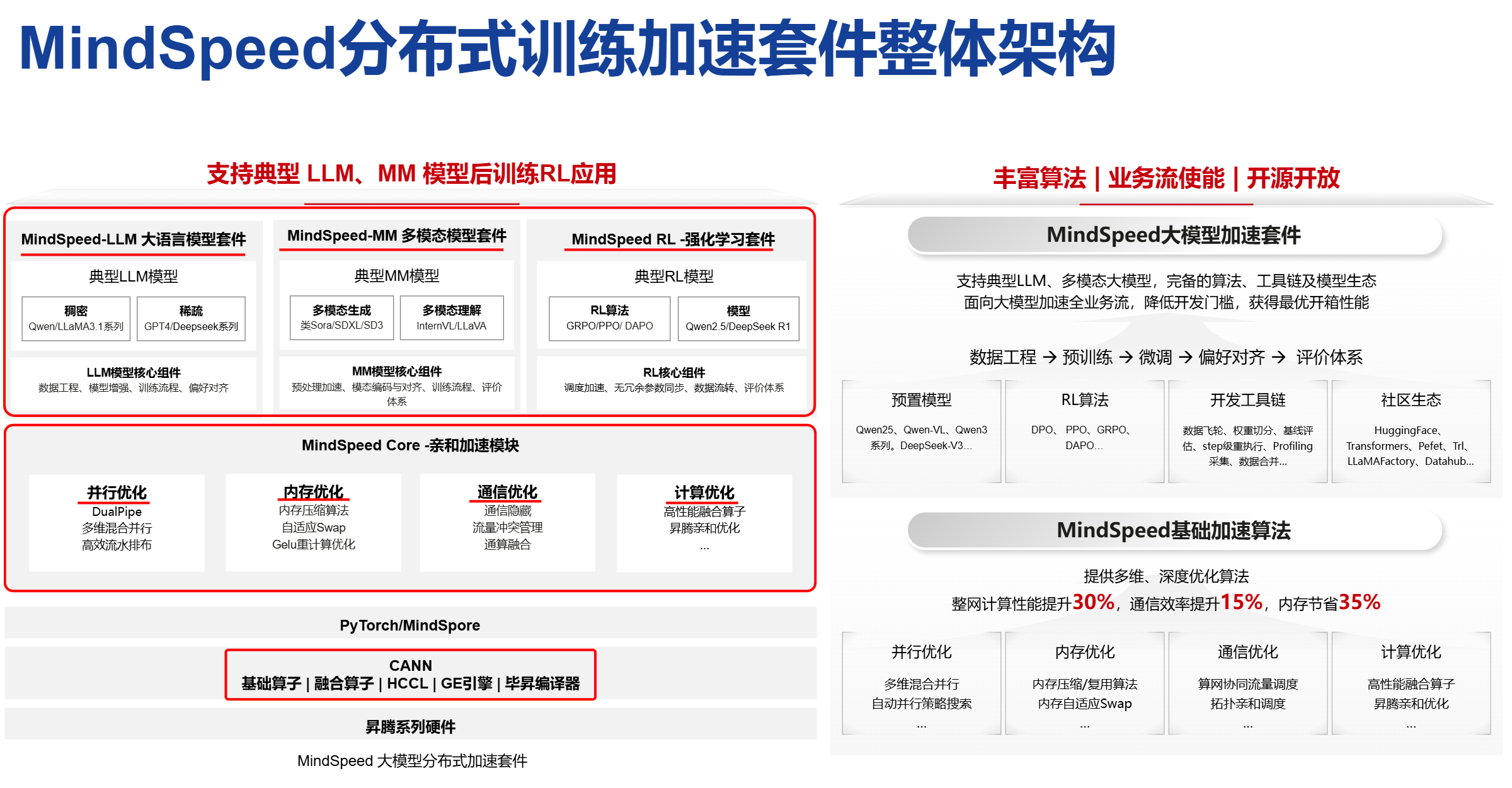
新人最常踩的概念坑: 把 MindSpeed 等同于 MindSpeed-LLM. 实际上 MindSpeed Core 才是底座, LLM / MM / RL 都是 Core 之上做的"端到端套件". 选型的标准不是"用哪个", 而是:
- 已在用 Megatron, 想上 NPU → 直接 Core
- 想跑 7B+ LLM 预训练/微调全套流程 → MindSpeed-LLM
- 跑多模态 (Qwen-VL / InternVL) → MindSpeed-MM
- 跑 LLM 强化学习 (RLHF / GRPO) → MindSpeed-RL
二、Core 的能力地图: 七大特性模块
关键洞察: MindSpeed 不是一个"特性", 是 7 类特性的统一入口. 每个特性用具体参数启用, 不是开关.
MindSpeed Core 加速特性 = 七大模块
| # | 模块 | 一句话 | 典型特性 |
|---|---|---|---|
| 1 | Megatron 特性支持 | 把 Megatron-LM 跑通到 NPU 的能力补齐 | TP/PP/DP/EP/CP |
| 2 | 并行策略特性 | 各种并行实现 | 流水并行 / 序列并行 / MoE EP |
| 3 | 内存优化特性 | 显存吃紧时用的 trick | 重计算 / 优化器切分 / 显存池 |
| 4 | 亲和计算特性 | 算子/计算图重写让 NPU 跑得更舒服 | 算子融合 / NPU 亲和改写 |
| 5 | 通信优化特性 | HCCL 集合通信优化 | 拓扑感知 / 通信计算 overlap |
| 6 | 关键场景特性 | MoE / 长序列 / RL 等 | MoE 训练 / 长序列 / RLHF |
| 7 | 多模态特性 | MM 模型相关 | FSDP2 配置 / 跨模态融合 |
加速特性三级开关
通过 --optimization-level {0|1|2} 选择:
| 层级 | 名称 | 含义 | 何时用 |
|---|---|---|---|
| L0 | 基础功能兼容 | Megatron-LM 对 NPU 的基本适配 | 第一次跑通, 验证环境 |
| L1 | 亲和性增强 | L0 + 部分融合算子 + 昇腾亲和改写 | 性能要追平台 baseline |
| L2 | 加速特性使能 (默认) | L0 + L1 + 更丰富的加速特性 | 实际生产训练, 推荐的起点 |
L2 是默认, 但不是必须全开 —— 某些特性 (比如某类算子融合) 在小模型上反而拖慢, 需按场景调. 建议: 第一次跑 L0 验证 → 切 L1 测基线 → 加具体特性参数逐步打开 L2.
三、MindSpeed 与 Megatron-LM 的关系 (这是关键)
关键洞察: MindSpeed 不是替代 Megatron-LM, 而是在 Megatron 之上做"打补丁 + 优化增强". 这与 DeepSpeed (独立训练框架) 路线完全不同.
MindSpeed = Megatron-on-NPU 适配层
Megatron-LM (上游 NVIDIA 维护)
↓ patch + 适配
mindspeed/megatron_adapter.py
↓ import
你的训练脚本 (pretrain_gpt.py 加一行 import)
这个机制有 2 个含义:
- 使用成本极低: 你已有的 Megatron 训练脚本不需要改, 加一行 import 就能让 Megatron 跑在 NPU 上. 这就是 README 里说的"一行代码运行 Megatron-LM"的核心.
- 升级有保证: 昇腾有专门的 skill (
megatron-impact-mapper/megatron-migration-generator) 跟踪 Megatron 上游变更, 把新特性迁移进 MindSpeed. 你不用自己跟踪 NVIDIA 仓库.
立场: 如果你已经在用 Megatron-LM, 迁到 NPU 的最短路径就是 MindSpeed. 如果你还没选训练框架, 且目标是 LLM 训练, Megatron + MindSpeed 比从零写 torch.distributed 划算得多.
MindSpeed 与 DeepSpeed 的对比: DeepSpeed 是独立框架 (替代 Megatron 的角色), MindSpeed 是适配层 (在 Megatron 之上). 选哪个看你的起点: 已用 Megatron → MindSpeed; 已用 DeepSpeed → 找 DeepSpeed-Ascend 路线.
四、一行代码启用 MindSpeed (Quickstart)
4.1 装环境
版本配套 (2026-06 当前主流)
| 组件 | 版本 |
|---|---|
| MindSpeed Core | 26.0.0 |
| Megatron-LM | core_v0.12.1 |
| CANN | 9.0.0 |
| PyTorch | 2.7.1 |
| torch_npu | 26.0.0 |
| Python | 3.10.x |
版本敏感: 训练框架迭代快, 上表对应 26.0.0_core_r0.12.1 分支, 预计维护到 2026-09-30. 不同分支的版本配套不一样, 装之前先查 MindSpeed Core 版本说明.
# 1. 拉 Megatron-LM
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_v0.12.1
cd ..
# 2. 拉 MindSpeed Core
git clone https://gitcode.com/Ascend/MindSpeed.git
cd MindSpeed && pip install -e .
4.2 一行代码启用
在 Megatron-LM 目录的 pretrain_gpt.py 里, 在 import torch 之后加一行:
import torch
import mindspeed.megatron_adaptor # 这一行让 Megatron 跑在 NPU
from functools import partial
from contextlib import nullcontext
import inspect
# ... 其他 import 保持原样
4.3 启动训练 (按需选加速层级)
python pretrain_gpt.py \
--optimization-level 2 \ # 默认 L2
--tensor-model-parallel-size 8 \
--pipeline-model-parallel-size 1 \
--num-layers 32 \
--hidden-size 4096 \
--num-attention-heads 32 \
# ... 其他分布式参数
第一次跑建议从
--optimization-level 0起步, 验证环境 OK 后再切到 L2. 全开 L2 + 不调具体参数 = 性能可能不达预期 (因为 L2 的"具体特性"需要单独参数使能).
五、场景覆盖 (MindSpeed-LLM 视角)
MindSpeed-LLM 是 Core 之上的 LLM 端到端套件, 截至 2026-06 已内置支持 100+ 业界常用 LLM. 近期新增的 (从 MindSpeed-LLM README 整理):
| 模型 | 类型 | 训练后端 | 备注 |
|---|---|---|---|
| DeepSeek-V3-671B | 预训练全家桶 | mcore | 2025-03 上线 |
| DeepSeek-V4-Flash | 定长数据预训练 | mcore | 2026-04 |
| DeepSeek-R1 / R1-ZERO | 强化学习 | mcore + veRL | 2025-03 起逐步上线 |
| Qwen3-0.6B / 8B / 30B | 全尺寸 | mcore / FSDP2 | FSDP2 后端 2026-02 上线 |
| Qwen3-Next / Qwen3-Coder-Next | Next-gen | FSDP2 | Triton 融合 GDN |
| GLM-4.5-Air / GLM5 | GLM 系列 | mcore | 2025-07 起 |
| Mamba3 / Step-3.5-Flash | 新架构 | FSDP2 | 2026-03 / 2026-02 |
| GPT-OSS | 开源 | mcore | 2025-12 |
训练后端 2 选 1:
- mcore (Megatron-Core): 成熟, 大规模训练首选, LLaMA-70B+ 通常走这条
- FSDP2: 2026-02 上线, 适合中小规模 / 多模态 / Qwen3-Next 等新架构
框架 2 选 1:
- PyTorch (主流): 复用 Megatron 生态, 90% 场景
- MindSpore: 2025-10 起 DeepSeek-V3 预训练已支持, 适合公司强推 MindSpore 场景
六、4 个常见踩坑 (FAQ 精选)
从 MindSpeed Core README 官方 FAQ + 实践经验整理, 排名按出现频次.
| # | 现象 | 根因 | 解决 |
|---|---|---|---|
| 1 | Data helpers 数据预处理出错 | 数据格式与 MindSpeed 期望不匹配 | 查 docs/zh/faq/data_helpers.md, 多数是字段命名/分隔符差异 |
| 2 | Torch extensions 编译卡住 | NPU 编译器与 torch_npu 版本不匹配 | 严格按 torch==2.7.1 + torch_npu==26.0.0 配套, 清理 ~/.cache/torch_extensions 后重试 |
| 3 | megatron 0.7.0 grad norm 为 nan | 老版本 + 某种并行组合下的数值问题 | 升 core 版本到 r0.9.0+ 或调小 learning rate + 加 grad clip |
| 4 | Gloo 建链失败 | MindSpeed 期望 HCCL, 但代码里默认 Gloo | 显式 export BACKEND=hccl 或在代码里 init_process_group(backend="hccl") |
重要: MindSpeed 与 Megatron 版本是强耦合的, 老版本 (如 core_r0.7.0) 上的 workaround 在新版本可能已经修复, 升版本前先看 release notes, 别硬背 fix 步骤.
七、与其他方案的对比 (有立场)
| 你的情况 | 推荐方案 | 理由 |
|---|---|---|
| 已在用 Megatron, 想上 NPU | MindSpeed Core | 1 行 import 启用, 升级由昇腾跟踪 |
| 想跑 7B-70B LLM 预训练全套 | MindSpeed-LLM | 数据/权重/推理/评估端到端 |
| 已用 DeepSpeed, 想上 NPU | DeepSpeed-Ascend 路线 | MindSpeed 不是 DeepSpeed 替代, 不要混用 |
已在用 PyTorch 裸 torch.distributed |
评估迁到 Megatron + MindSpeed | 重写分布式代码是 1-2 周, 长期收益更大 |
| 单卡小模型 (ResNet / BERT-base) | 不用 MindSpeed, 直接 torch.cuda → torch.npu |
MindSpeed 复杂度对小模型不划算 |
| 多模态 (Qwen-VL / InternVL) | MindSpeed-MM | FSDP2 配置驱动, 与 LLM 分开 |
一句话立场: MindSpeed 是 NPU 上做 LLM 训练的"标准答案", 但只在 7B+ 模型上才显出价值. 小模型上它的复杂度反而是负担.
八、资源与下一步
8.1 官方资源
| 资源 | 链接 |
|---|---|
| MindSpeed Core 主仓 | https://gitcode.com/Ascend/MindSpeed |
| MindSpeed-LLM | https://gitcode.com/Ascend/MindSpeed-LLM |
| MindSpeed-MM | https://gitcode.com/Ascend/MindSpeed-MM |
| 快速上手 (官方) | MindSpeed/docs/zh/user-guide/quickstart.md |
| 特性支持清单 | MindSpeed/docs/zh/features/feature_list.md |
| 算子支持清单 | MindSpeed/docs/zh/ops/ops_list.md |
| 常见问题 | MindSpeed/docs/zh/faq/ |
8.2 推荐的下一步 (按学习曲线)
- 环境跑通: 按 §4 装好 Core, 跑 LLaMA-7B 预训练 baseline (1-2 天)
- 加速特性上手: 切
--optimization-level 0/1/2对比, 看 L1/L2 加的具体参数 (1 周) - 迁移到 MindSpeed-LLM: 用 LLM 套件跑 Qwen3-7B 完整流程 (1-2 周)
- 分布式进阶: 8 卡 / 16 卡 集群训练, 配 HCCL 拓扑 (2-3 周)
- 性能调优: 用 msprof profile, 找 TOP 3 瓶颈 (持续)
8.3 何时需要 Agent 辅助
关键洞察: MindSpeed + Megatron 生态的版本/参数组合空间很大, 靠人脑记不住. 借力昇腾知识图谱 (Ascend KG) + Agent, 1 句话任务能在 5 分钟内完成"找版本 → 装环境 → 跑通 → 调参"的端到端流程.
接入方式: Agent 系统提示里粘贴 KG API 规则 (http://47.110.229.78, X-API-Key: <key>), 涉及 MindSpeed/Megatron/CANN 等主题时自动先查 KG, 再决策.
总结
MindSpeed = Megatron-on-NPU 适配层, 不是独立框架. 它用 1 行 import 让 Megatron 跑在 NPU, 用 7 大特性模块 + L0/L1/L2 加速开关提供训练优化, 用 MegatronAdaptor + features_manager 把上游变更同步到 NPU 生态.
三个关键事实:
- 入门成本 = 1 行 import: 在
pretrain_gpt.py加import mindspeed.megatron_adaptor就能让 Megatron 跑在 NPU, 不需要改任何训练逻辑. - 能力边界 = Core + LLM + MM 三层: 选型时先确认你的场景是 Core (通用) / LLM (端到端 LLM) / MM (多模态), 别混用.
- 价值区间 = 7B+ LLM: 小模型上 MindSpeed 的复杂度是负担, 7B+ 才是它的主战场.
一句话给新人: 别再把 MindSpeed 当"NPU 版 DeepSpeed"了, 它是 NPU 上做 LLM 训练的标准答案, 但只在 7B+ 模型上才划算.
参考
- MindSpeed Core README - 2026-06-23 更新
- MindSpeed-LLM README - 2026-06-24 更新
- Megatron-LM core_v0.12.1 - NVIDIA 官方
- MindSpeed 加速百万级超长序列大模型训练 - 官方技术文章
- MindSpeed 加速万亿 MoE 大模型训练 - 官方技术文章
- 大模型训练内存优化难? MindSpeed 帮你来支招 - 官方技术文章

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)