
【昇腾推理】-MindIE Turbo 极速入门
【昇腾推理】-MindIE Turbo 极速入门
适用: vLLM 熟手, 第一次在昇腾 NPU 上跑 vLLM-Ascend 想榨取更高性能的工程师
配套仓: Ascend/MindIE-Turbo (2025-11-30 开源)
当前版本: 1.0rc1
关联博客: 《【昇腾推理】-MindIE 极速入门》 / 《【昇腾推理】-MindIE-SD 极速入门》 / 《【昇腾推理】-MindIE Motor 大规模部署》(待写)
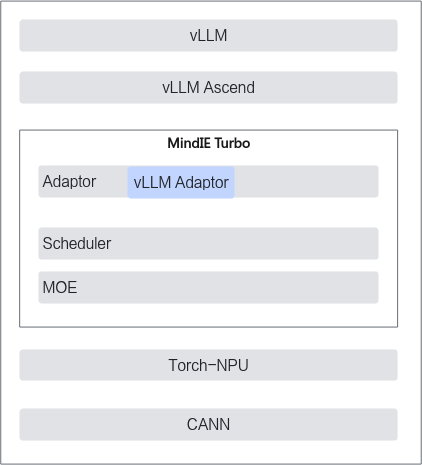
一、MindIE Turbo , 装在 vLLM 之上的"加速插件库"
关键洞察: 多数新人把 MindIE Turbo 当作"NPU 上的 vLLM 替代"或"vLLM-Ascend 的竞品", 实际它是 装在 vLLM / vLLM-Ascend 之上的"加速插件库", 无需改任何代码就能让现有 vLLM 服务获得性能提升. 这是与 vLLM-Ascend 完全不同维度的产品.
MindIE Turbo 定位 = 装在 vLLM / vLLM-Ascend 之上的"性能加速器"
新人最常踩的概念坑: 把 MindIE Turbo 当 “vLLM-Ascend 竞品”, 实际它是叠加层, vLLM-Ascend 是 MindIE Turbo 的运行环境. 装 MindIE Turbo 前必须先装好 vLLM-Ascend, 不冲突.
MindIE Turbo 在 MindIE 生态中的位置 (以昇腾开源仓为准, 4 个子组件)
| # | 组件 | 职责 | 本文覆盖 |
|---|---|---|---|
| 1 | MindIE-LLM | 大语言模型推理核心引擎 | 见《MindIE 极速入门》 |
| 2 | MindIE-SD | Stable Diffusion 图像生成 | 见《MindIE-SD 极速入门》 |
| 3 | MindIE Turbo | LLM 推理加速插件 (装在 vLLM 之上, 本博客主角) | 全部章节 |
| 4 | MindIE Motor | 服务化部署 + 统一调度 | 见《MindIE Motor 大规模部署》(待写) |
关键洞察: Turbo 与 LLM 的关键区别: LLM 是替代 (不用 MindIE-LLM 就用别的推理引擎), Turbo 是增强 (已有 vLLM 也能装). 这是"插件 vs 引擎"的产品形态差异, 决定了选型策略.
二、MindIE Turbo 架构 / 支持框架 / 使用场景
关键洞察: MindIE Turbo 的架构极简, 2 大模块 + 1 个唯一已实现的支持框架 (vLLM), 但使用场景覆盖了大多数已有 vLLM 服务的"性能调优"需求. 本节把"怎么组织的 + 接谁 + 用在哪"一次讲清.
2.1 架构: 2 大模块 (adaptor / utils)
mindie_turbo/
├── adaptor/ # 适配不同推理框架的优化实现
│ ├── vllm/ # vLLM 框架适配 (核心, 唯一已实现)
│ └── [future: triton / mindie-llm / ...]
└── utils/ # 通用工具 (配置 / 日志 / profiling)
adaptor 是核心, utils 提供基础设施. 整个 mindie_turbo 的设计哲学是"plugin 形态 + 模块化", 后续要接 triton / mindie-llm 等其他推理引擎, 加 adaptor 子目录即可.
adaptor 的工作原理 (vLLM 版)
vLLM 推理流程
↓
[VLLM_OPTIMIZATION_LEVEL 检查]
↓
[加载 MindIE Turbo]
↓
adaptor 在以下位置插入自研优化:
├── Attention 计算 (替换 PagedAttention 算子)
├── KV Cache 管理 (替换块调度策略)
├── 调度逻辑 (替换 Continuous Batching 调度)
├── 显存管理 (替换 block_manager 策略)
└── 量化路径 (替换量化算子)
↓
[优化后推理]
2.2 支持框架: vLLM 唯一已实现
框架支持现状 (1.0rc1)
| 框架 | 状态 | 说明 |
|---|---|---|
| vLLM | 已实现 | 唯一支持, 自动检测启用 |
| vLLM-Ascend | 已实现 (NPU 适配) | 装 Turbo 的实际运行环境 |
| triton | 预留 | 未来扩展 |
| mindie-llm | 预留 | 未来扩展 (可与 MindIE-LLM 集成) |
| 其他推理框架 | 未规划 | 暂未支持 |
关键洞察: 当前 MindIE Turbo 唯一已实现的框架是 vLLM. 这不是说 Turbo 局限于 vLLM, 是说现在 1.0rc1 的投入集中在 vLLM 优化上. 选 MindIE Turbo 的前置条件: 你的推理服务已经用 vLLM (或 vLLM-Ascend). 不是 vLLM 的服务 (例如用 MindIE-LLM / TGI / TensorRT-LLM) 当前用不上 Turbo.
2.3 使用场景: 4 类典型用法
MindIE Turbo 适用场景 (1.0rc1)
| # | 场景 | 你的现状 | 上 Turbo 收益 |
|---|---|---|---|
| 1 | 已有 vLLM 服务, 想再快 | GPU 上跑 vLLM, 迁到 NPU 后性能不满意 | 20-60% 吞吐提升, 10-30% 延迟降低 |
| 2 | 新建 NPU 推理服务 | 准备用 vLLM-Ascend 部署新模型 | 0 → 1 直接拿到 Turbo 优化 (省事) |
| 3 | vLLM-Ascend 已跑, 想榨性能 | 已经用 vLLM-Ascend 跑生产 | 设 L2 升级到 L3 进一步压 |
| 4 | 多模型压测对比 | 团队选型, 想知道优化能拿多少 | 与未装 Turbo 的 baseline 对比 |
关键洞察: 实际使用中, 用户完全感知不到 MindIE Turbo 的存在, 装好后 vLLM 服务照常启动, 但底层算子/调度已切换为 MindIE Turbo 的自研实现. 这就是"插件"形态的精髓.
三、加速特性: 4 级优化开关 (VLLM_OPTIMIZATION_LEVEL)
关键洞察: MindIE Turbo 的核心加速机制是 4 级优化开关 (VLLM_OPTIMIZATION_LEVEL 0-3). 通过环境变量控制, 无需改代码, 数字越大优化越激进. 默认 2 是"推荐起点".
4 级优化开关对照
| 级别 | 名称 | 含义 | 何时用 |
|---|---|---|---|
| 0 | 禁用大部分优化 | 用于调试, 关闭 Turbo 优化, 退回 vLLM 原版 | 排查 vLLM 行为异常时 |
| 1 | 基础优化 | 启用 MindIE Turbo 的"安全"优化 (通用, 不改语义) | 保守场景, 想确认有收益 |
| 2 | 中等优化 (推荐) | 启用主流优化, 大多数场景最佳 | 默认推荐, 第一次上 Turbo 用这个 |
| 3 | 最高优化 (实验性) | 启用实验性优化, 可能改语义, 需测试 | 极端性能场景, 已知风险可接受 |
关键洞察: 4 级开关是粗粒度控制, 内部对应一组优化 (如 Attention 算子替换 + KV Cache 调度 + 量化路径), 数字越大开的优化越多. 实际使用时, 多数场景 L2 已经够, 上 L3 需要严格测试精度 (实验性优化可能改浮点行为).
设置优化级别的方法 (环境变量)
# L2 (推荐默认)
export VLLM_OPTIMIZATION_LEVEL=2
vllm serve Qwen/Qwen2.5-1.5B-Instruct
# L3 (实验性, 严格测试后再用)
export VLLM_OPTIMIZATION_LEVEL=3
vllm serve Qwen/Qwen2.5-1.5B-Instruct
# L0 (调试用, 关掉 Turbo)
export VLLM_OPTIMIZATION_LEVEL=0
vllm serve Qwen/Qwen2.5-1.5B-Instruct
关键洞察: 改完
VLLM_OPTIMIZATION_LEVEL不用改任何 Python 代码, 也不用改服务启动脚本, 重启 vLLM 进程即生效. 这是"插件"形态的另一个好处: 配置驱动, 不用重新部署.
四、版本与配套 (2026-06 当前)
关键洞察: MindIE Turbo 1.0rc1 是首个开源版本, 配套关系相对宽松 (CAN >=8.0.0), 但装前必查 驱动 / CANN / PyTorch / Python 配套, 装错 = 跑不起来.
版本配套表 (1.0rc1)
| 组件 | 版本 | 备注 |
|---|---|---|
| MindIE Turbo | 1.0rc1 | 2025-11-30 开源 |
| 驱动与固件 (HDK) | >=24.0 | 硬件厂商侧 |
| CANN | >=8.0.0 | 与 MindIE-LLM 兼容 |
| PyTorch | 2.5.1 | 与 CANN 配套 |
| Python | 3.10.x / 3.11.x | 推荐 3.11 |
| vLLM | 配套版本 | 装好 vLLM-Ascend 后即可装 Turbo |
| 硬件 | A800I A2 推理产品 (32GB / 64GB) | 当前支持 |
版本敏感: MindIE Turbo 装在 vLLM-Ascend 之上, vLLM-Ascend 与 CANN 是 1:1 绑定, 装 Turbo 前先确认 vLLM-Ascend 跑通. Turbo 本身的版本兼容窗口相对宽松, 但 vLLM-Ascend 配套不能错.
五、Quickstart (在已有 vLLM-Ascend 上装 Turbo)
5.1 装环境
# 1. 装驱动 + CANN (>=8.0.0) + PyTorch + torch_npu
# 参考: https://www.hiascend.com/document
# 2. 装 vLLM + vLLM-Ascend (Turbo 的运行环境)
# 参考: https://vllm-ascend.readthedocs.io/en/latest/installation.html
pip install vllm
pip install vllm-ascend
# 3. 验证 vLLM-Ascend 跑通
vllm serve Qwen/Qwen2.5-1.5B-Instruct --device npu
5.2 装 MindIE Turbo
# 1. 获取 MindIE Turbo 软件包 (官方渠道)
# 联系华为 / 社区获取, 或从 gitcode 拉取
# 2. 上传到安装环境
cd /home/package
# 3. 安装
python setup.py install
# 4. 验证
pip show mindie_turbo
# 期望输出: Version: 1.0rc1
5.3 启动 (无需改任何 vLLM 代码)
# 设置优化级别 (L2 推荐)
export VLLM_OPTIMIZATION_LEVEL=2
# 启动 vLLM (Turbo 自动加载, 透明)
vllm serve Qwen/Qwen2.5-1.5B-Instruct \
--host 0.0.0.0 \
--port 8001 \
--trust-remote-code
关键洞察: 这一步完全没改
vllm serve的任何参数, 只加了VLLM_OPTIMIZATION_LEVEL=2. Turbo 在 vLLM 启动时自动注入优化, 用户无感.
5.4 验证 Turbo 已生效
# 1. 看启动日志, 应该有 "MindIE Turbo" 或 "mindie_turbo" 关键字
vllm serve Qwen/Qwen2.5-1.5B-Instruct 2>&1 | grep -i turbo
# 2. 跑同一组请求, 对比 L0 vs L2 性能 (用 vllm bench)
vllm bench --model Qwen/Qwen2.5-1.5B-Instruct --num-prompts 100
# 3. 看 token/s 提升比例
关键洞察: L0 → L2 的性能提升因模型和硬件而异, 实测常见在 20-60% 吞吐提升 / 10-30% 首 token 延迟降低. 极端场景 (长序列 / 高并发) 可能更高.
六、服务器底层调优 (CPU 模式 + 透明大页)
关键洞察: MindIE Turbo 是"推理引擎层"的优化, 但底层操作系统如果不调, 上层再优化也跑不满. 官方推荐 2 个 OS 层调优: CPU 高性能模式 + 透明大页 (THP).
2 步 OS 调优 (服务端必做)
| 步骤 | 命令 | 作用 |
|---|---|---|
| 1. 装 cpufrequtils | apt-get install cpufrequtils |
CPU 调频工具 |
| 2. 装 linux-tools | apt install linux-tools-common linux-tools-$(uname -r) |
性能监控工具 |
| 3. CPU 高性能模式 | cpupower frequency-set -g performance |
CPU 不降频, 持续高频率 |
| 4. 透明大页 (THP) | echo always > /sys/kernel/mm/transparent_hugepage/enabled |
用 2MB 大页, 减少 TLB miss |
# 一键执行
apt-get install -y cpufrequtils linux-tools-common linux-tools-$(uname -r)
cpupower frequency-set -g performance
echo always > /sys/kernel/mm/transparent_hugepage/enabled
关键洞察: THP (Transparent Huge Pages) 对 LLM 推理特别重要 —— LLM 推理的 KV Cache 是大块连续内存, 默认 4KB 页会导致 TLB miss 频繁, 开 THP 后用 2MB 页, TLB miss 显著降低. 实测常能额外带来 5-10% 性能提升.
七、MindIE Turbo vs MindIE-LLM 选型
关键洞察: 多数新人会问"Turbo 和 LLM 选哪个". 答案是 “看你从哪来” — 已有 vLLM 代码选 Turbo, 没有 vLLM 代码选 LLM. 这是入口路径的差异, 不是性能的差异.
4 维选型对照
| 你的情况 | 推荐 | 理由 |
|---|---|---|
| 已在用 vLLM 部署, 想迁 NPU + 加速 | vLLM-Ascend + MindIE Turbo | 零代码改动, 装 Turbo 即可 |
| 没用过 vLLM, 想在 NPU 上做 LLM 推理 | MindIE-LLM | 昇腾原生, 模型支持更全 |
| 已用 vLLM-Ascend, 想再榨性能 | + MindIE Turbo | 装上即得, 默认 L2 |
| 跑 DeepSeek-V3 / Hunyuan 等昇腾深度优化模型 | MindIE-LLM | 强项是昇腾深度优化模型 |
| 多模态 (Qwen-VL / InternVL) | MindIE-LLM | 内置多模态支持 |
立场: 如果你已经在用 vLLM (不论 GPU 还是 NPU), 上 vLLM-Ascend + MindIE Turbo 是最短路径. 如果你没用过 vLLM, 直接 MindIE-LLM 更省事. 不要混用同一个模型 (一个模型不要同时跑在两个推理引擎上).
八、4 个常见踩坑 (MindIE Turbo 专属)
| # | 现象 | 根因 | 解决 |
|---|---|---|---|
| 1 | pip show mindie_turbo 找不到 |
装在错误的 Python 环境 | 确认 python setup.py install 用的 python 和 vLLM 用的是同一个 |
| 2 | L3 优化级别跑出精度异常 | 实验性优化改了浮点行为 | 退回 L2, 严格对比 L0 vs L2 输出 |
| 3 | 性能提升不明显 | OS 层没调 (CPU 模式 + THP) | 跑 §六 的 2 步 OS 调优 |
| 4 | 服务启动慢 (10s → 60s) | L2/L3 优化在加载时编译算子图 | 第一次启动慢, 之后正常; 接受即可 |
避坑心法: MindIE Turbo 80% 的问题集中在环境配套 (Python 多版本 / vLLM-Ascend 没装) 和 OS 层没调. 装前先跑
pip list | grep -iE "vllm|torch|cann", 确认环境干净再装.
九、关联资源
| 资源 | 链接 |
|---|---|
| MindIE Turbo 主仓 | https://gitcode.com/Ascend/MindIE-Turbo |
| GitHub 镜像 | https://github.com/Ascend/MindIE-Turbo |
| vLLM Ascend 安装文档 | https://vllm-ascend.readthedocs.io/en/latest/installation.html |
| vLLM 离线推理示例 | https://docs.vllm.ai/en/latest/getting_started/quickstart.html |
| vLLM 在线服务示例 | https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html |
| 关联博客 | 《【昇腾推理】-MindIE 极速入门》 (MindIE-LLM) / 《【昇腾推理】-MindIE-SD 极速入门》 (SD) |
总结
MindIE Turbo = 装在 vLLM / vLLM-Ascend 之上的"加速插件库", 不是 vLLM 替代. 它通过
VLLM_OPTIMIZATION_LEVEL4 级开关 + 透明接入 + OS 层调优, 让已有 vLLM 服务无需改代码就能获得性能提升.
三个关键事实
- 产品形态 = 插件而非引擎: 与 vLLM-Ascend 不是替代, 是叠加. 装 Turbo 前必须先装好 vLLM-Ascend
- 零代码改动:
VLLM_OPTIMIZATION_LEVEL环境变量 + 重启 vLLM 进程即生效, 不用改任何 Python 代码 - 4 级优化 + OS 调优 = 完整方案: 单独开 Turbo 优化能得 20-60% 提升, 再加上 CPU 高性能模式 + 透明大页 (THP), 总提升可能到 30-70%
一句话给新人: 别再把 MindIE Turbo 当"NPU 上的 vLLM 替代"了, 它是装在 vLLM-Ascend 之上的"性能加速器", 已有 vLLM 服务的最短性能调优路径: pip install 完, 设个环境变量, 重启, 性能就上来了.
参考
- MindIE-Turbo README - 2026-06-24
- vLLM 离线推理示例 - 官方 quickstart
- vLLM Ascend 安装文档 - vLLM 在昇腾上的安装
- Linux THP 文档 - 透明大页
- 《【昇腾推理】-MindIE 极速入门》 - MindIE-LLM 推理引擎
- 《【昇腾推理】-MindIE-SD 极速入门》 - MindIE-SD 图像生成

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)