
同样是Attention架构,为什么昇腾NPU跑HSTU时延降低10倍、显存省97%?
同样是Attention架构,为什么昇腾NPU跑HSTU时延降低10倍、显存省97%?
自从Meta推出的GR(生成式推荐)范式,传统DLRM推荐模型就被颠覆了,而HSTU作为GR的核心核心单元,地位等同于Transformer里的Self-Attention。
但做推荐算法的小伙伴都卡在同一个致命问题:HSTU看似只有几行极简代码,落地却堪称硬件杀手。
序列一拉长,显存直接爆炸;千万级QPS的工业场景下,推理延迟根本压不住。哪怕用顶配GPU,跑长序列HSTU依旧吃力。
但最近,同样的HSTU模型、同样的参数,昇腾NPU却大幅优化了性能,提速最高95%,显存直接砍掉97%,8192长序列场景下,性能更是比主流Transformer快5-15倍。
你一定疑惑:都是Attention类架构,凭什么昇腾能跑这么快?
今天一次性讲透昇腾HSTU的四大绝杀级优化,全是底层硬件+算子的核心优化!
先搞懂:HSTU到底难在哪?
先看官方极简代码,核心逻辑就三步:矩阵相乘、SiLU激活、上下文Mask掩码,看似简单到离谱。
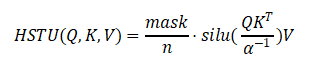
Python实现:
def HSTU(Q, K, V, mask, alpha=1, n=1):
# (b, n, s, d) x (b, n, d, s) -> (b, n, s, s)
x = torch.matmul(Q, K.permute(0, 1, 3, 2))
x *= alpha
x = F.silu(x)
x *= mask / n
# (b, n, s, s) x (b, n, s, d) -> (b, n, s, d)
x = torch.matmul(x, V)
return x但它和普通Transformer Attention最大的区别:适配推荐场景超长、动态、高稀疏的用户行为序列。
这些基于原生实现的致命硬伤,也是所有大厂落地GR的共同痛点:
- 显存开销是O(n²),序列越长,显存指数级爆炸
- 多算子拆分执行,频繁读写显存,带宽直接跑满
- 大量Padding无效计算,算力严重浪费
- 计算单元串行执行,硬件算力根本跑不满
而昇腾的优化,没有花里胡哨的算法魔改,全是吃透NPU硬件架构的极致工程优化,每一招都精准戳中核心优化之处。
绝杀优化一:全域算子融合!显存从O(n²)砍到O(n)
传统PyTorch/GPU实现,把HSTU拆成MatMul矩阵计算、SiLU激活、Mul缩放多个独立算子。每跑完一步,中间结果必须写回全局显存(GM),下一步再重新读取,反复搬运数据。
这就是GPU慢、显存高的核心元凶!
昇腾直接暴力优化:全流程算子融合+片上UB(Unified Buffer)分块计算
利用NPU高速片上统一缓存UB(Unified Buffer),将QK矩阵乘、SiLU激活、数值缩放全部在片内闭环完成,全程无需读写全局显存,仅最终结果落地。
同时采用分块计算策略,不用一次性加载完整QKV矩阵,仅小块迭代运算、累加结果。
分块计算策略示意图
实测数据碾压(QKV=16,4,4096,64):
❌ torch原生:耗时46.6ms,显存占用4.125G
✅ 昇腾融合算子:耗时5.8ms,显存2.125G
性能暴涨87.5%,直接省掉49%显存,第一步就拉开差距!
绝杀优化二:内置Mask生成!立省一半算力,显存再砍一刀
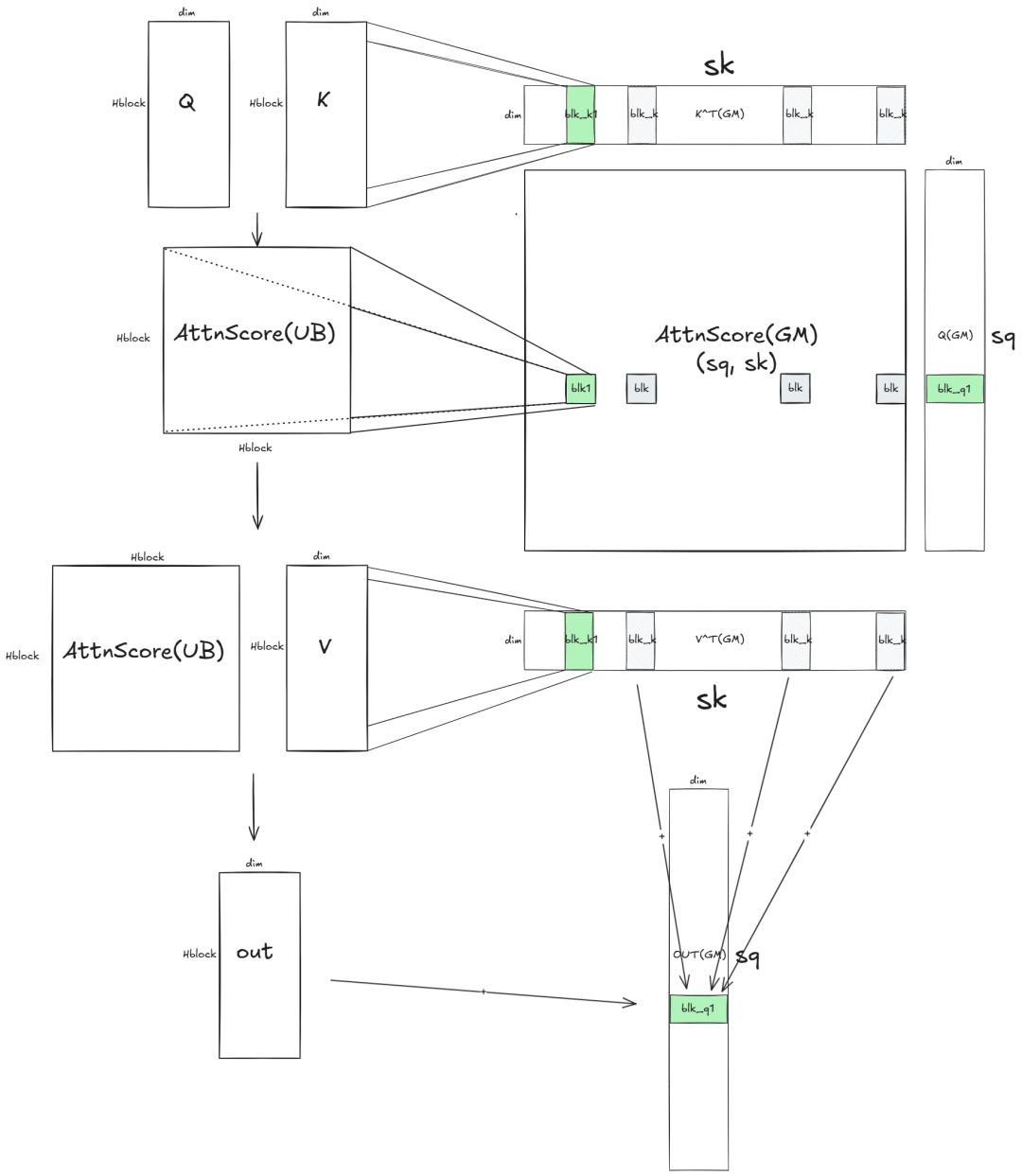
HSTU作为Decoder-only结构,必须依赖Attention Mask做序列遮挡。
常规实现是外部传入完整Mask矩阵,而Mask本身是O(n²)的超大显存张量,4096序列长度下,单Mask就占用2G+显存,极其浪费资源。
昇腾直接釜底抽薪:放弃外部传参,算子内部实时生成Mask!
根据QKV分块位置智能判断:
- 前置分块:全1 Mask,正常计算
- 对齐分块:下三角Mask,精准遮挡未来信息
- 后置分块:全0 Mask,直接跳过、不做无效计算
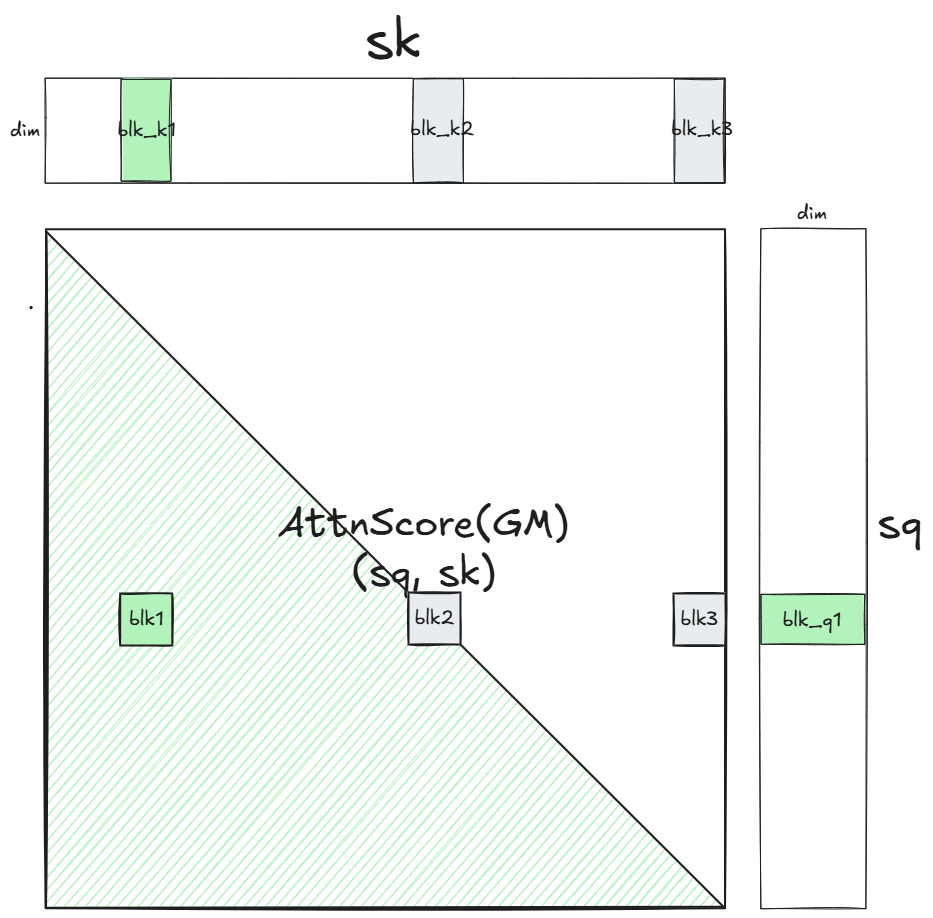
内置mask
这波优化直接封神:彻底删掉巨型Mask显存张量,还立省一半计算量!
最终实测:同样4096序列长度下,显存从4.125G暴跌至0.125G,显存节省97%,耗时进一步压缩至3.3ms!
绝杀优化三:Jagged变长张量!彻底消灭Padding无效计算
推荐场景的真实数据,永远是长短不一的用户行为序列。
pytorch实现的训练通用操作,就是统一Padding补零到最大序列长度。看似简单的操作,却藏着巨大算力浪费:大量零值Token参与计算、搬运、存储,全程无效做功。
昇腾祭出Jagged Tensor(锯齿张量)黑科技,彻底告别Padding!
不再用「批次、最大序列长度、维度」的冗余格式,直接压缩所有有效序列,记录每段真实长度。只计算、搬运、存储有效数据,零值Padding彻底消失。
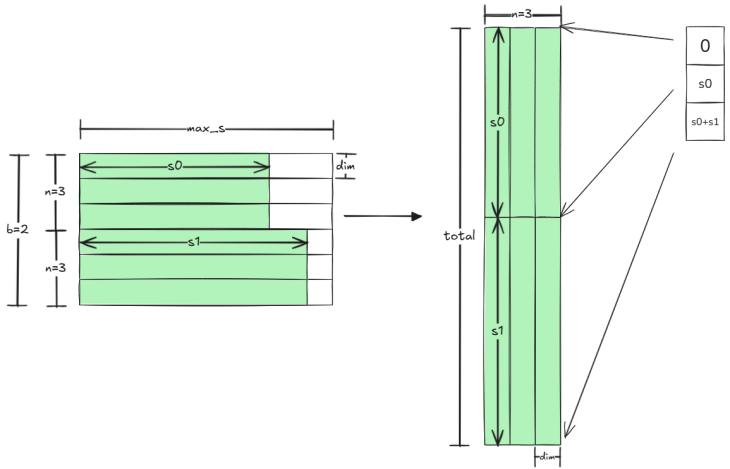
dense转jagged tensor
带来三重收益:
- 显存:从「批次×最大序列长」变为「真实序列总长」,杜绝冗余占用
- 算力:不做任何无效零值计算,算力利用率拉满
- 搬运:不搬运无效数据
- 访存:有效数据连续排布,Cache命中率大幅提升
绝杀优化四:三级流水并行!榨干NPU100%硬件算力
最后一步,也是昇腾方案的核心底牌:硬件级异构流水并行。
GPU是统一SIMT架构,矩阵计算、向量计算抢同一批核心。
而昇腾NPU的Cube矩阵核、Vector向量核物理分离、独立并行,天生支持多任务同时执行,可以发挥多算力协同的优势!
HSTU的QK矩阵乘、SiLU向量激活、SV矩阵乘,看似串行的三步流程,昇腾通过三级流水线调度重构执行逻辑:
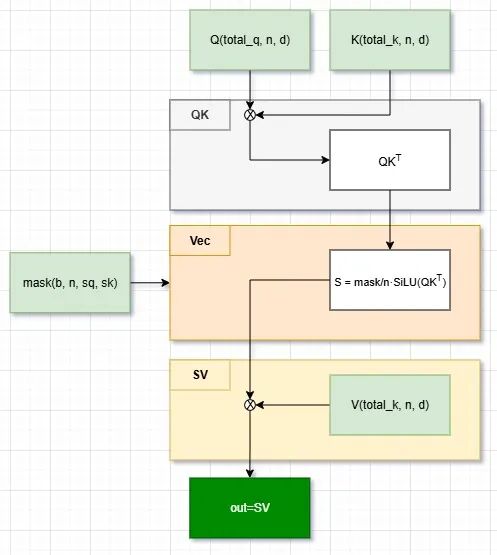
HSTU计算流图
当前迭代算QK矩阵乘、上一轮迭代算SiLU向量激活、上两轮迭代算SV矩阵乘,三步并行、无缝衔接。
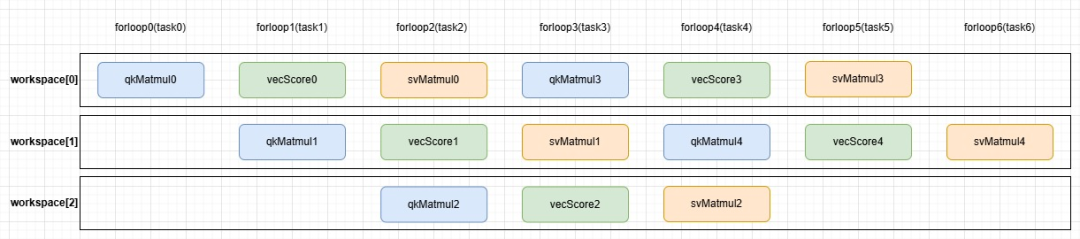
HSTU三级流水
完美匹配NPU Cube:Vector=1:2的算力配比,彻底杜绝核心空闲、等待卡顿。
最终极致成绩:模型耗时压缩至2.35ms,性能再提升40%,硬件算力彻底拉满!
总结:昇腾快的本质,不是参数碾压,是工程降维
看完这四大优化就能明白:HSTU提速和模型算法无关,完全是硬件架构+底层算子的降维打击。
同样的Attention类架构,GPU还在被显存带宽、无效计算、串行调度束缚时,昇腾已经通过:
- 算子融合降显存(O(n²)→O(n))
- 内置Mask省算力
- 锯齿张量消冗余
- 三级流水榨干硬件
实现了推荐生成式模型的极致落地优化,完美解决工业级千万QPS、超长序列场景的核心痛点。
目前这套优化方案已全部开源在昇腾RecSDK,支持直接编译部署、开箱即用,想跑通高性能HSTU的小伙伴可以直接上手实测!
👉 代码仓库:
https://gitcode.com/Ascend/RecSDK
昇腾CANN, 2026. 昇腾社区:
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850/opdevg/Ascendcopdevg/atlas_ascendc_10_0049.html

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 2
2 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)