
Qwen3.5-35B-VeRL-FSDP 功能适配实践
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
在大模型强化学习训练场景中,Qwen3.5-35B相比同类模型展现出更快的训练速度和更高的收敛效率,能够在更少的训练步数和更短的单步时间内达到优异的测试集准确率。为充分发挥其性能优势,我们基于昇腾硬件平台实现了VeRL强化学习训练框架的适配,以支持更大规模的分布式训练和多模态任务。
环境配置
- 硬件平台:Atlas 800T A2
- 基础环境:CANN 8.5.1 + vLLM 0.18 + vLLM-Ascend 0.18.0rc1
- 框架版本:PyTorch 2.9.0 + Transformers 5.4.0
关键技术问题与解决方案
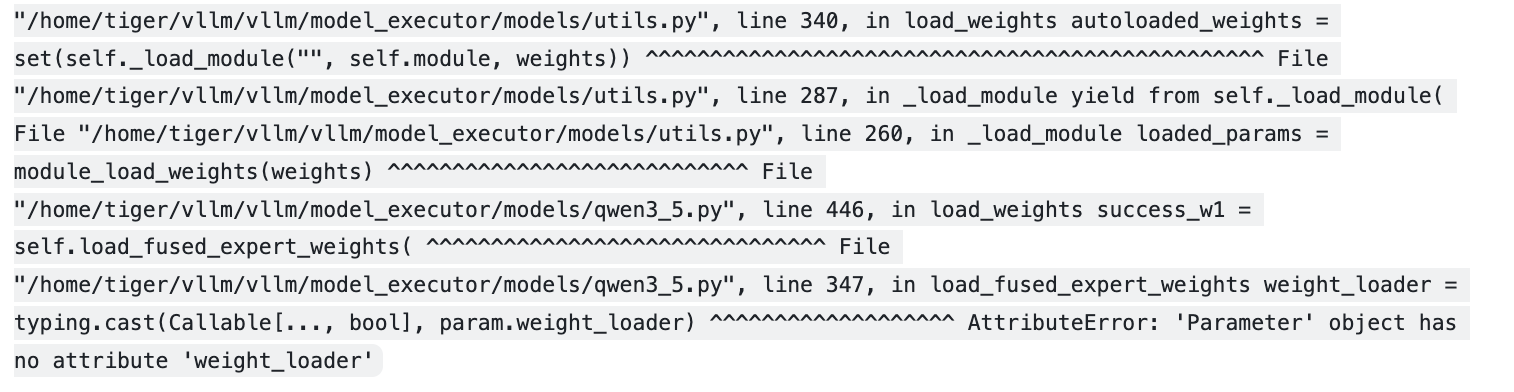
1. 模型权重加载异常
问题现象:
通过vLLM加载模型时出现Parameter Object has no attribute 'weight_loader'错误,导致权重加载失败,该问题为vLLM和VeRL间的BUG。
解决方案:
在VeRL的vLLM补丁文件中增加对Qwen3_5MoeForCausalLM模型的兼容支持,已通过PR合入开源社区主线。
2. 熵计算显存溢出
问题现象:
训练过程中出现OOM错误,熵计算时申请超过18GB显存,对于 64G显存的设备,该块的显存峰值容易触发OOM。
File "/opt/tiger/verl-0318/verl/workers/actor/dp_actor.py", line 479, in compute_log_prob
outputs = self._forward_micro_batch(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tiger/verl-0318/verl/workers/actor/dp_actor.py", line 373, in _forward_micro_batch
entropy = verl_F.entropy_from_logits(logits) # (bsz, response_length)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tiger/verl-0318/verl/utils/torch_functional.py", line 237, in entropy_from_logits
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: NPU out of memory. Tried to allocate 18.95 GiB (NPU 0; 60.96 GiB total capacity; 54.37 GiB already allocated; 54.37 GiB current active; 2.32 GiB free; 54.43 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
解决方案:
- 尝试启用分块计算功能(
entropy_from_logits_with_chunking)降低显存峰值 - 临时方案:直接返回零值张量(
entropy = torch.zeros_like(log_probs)),因熵值不参与实际梯度计算

3. Logits modified inplace问题
问题现象:logits.div_(temperature)进行原地除法时触发运行时错误,该问题为通用问题,会在开启 activation offload 下触发。
解决方案:
将原地操作改为赋值操作:logits = logits / temperature,社区上已经有修复PR:[fsdp] fix: use non-inplace div for activation-offloaded logits views by cavities12 · Pull Request #5513 · verl-project/verl
4. position_id 非 contiguous 问题
问题现象:position_id张量非连续内存布局导致计算异常。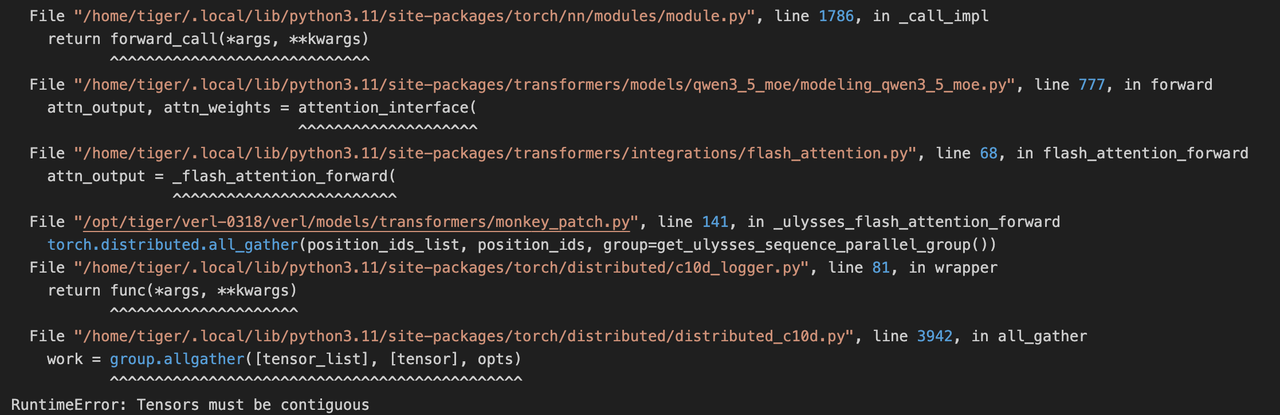
解决方案:
在monkey patch中显式调用连续化操作:position_ids = position_ids.contiguous()
5. 多模态组件段错误
问题现象:
多模态训练时出现段错误,定位到 vision patch 的卷积算子,该问题会在较旧的 CANN 版本触发,建议升级新版本。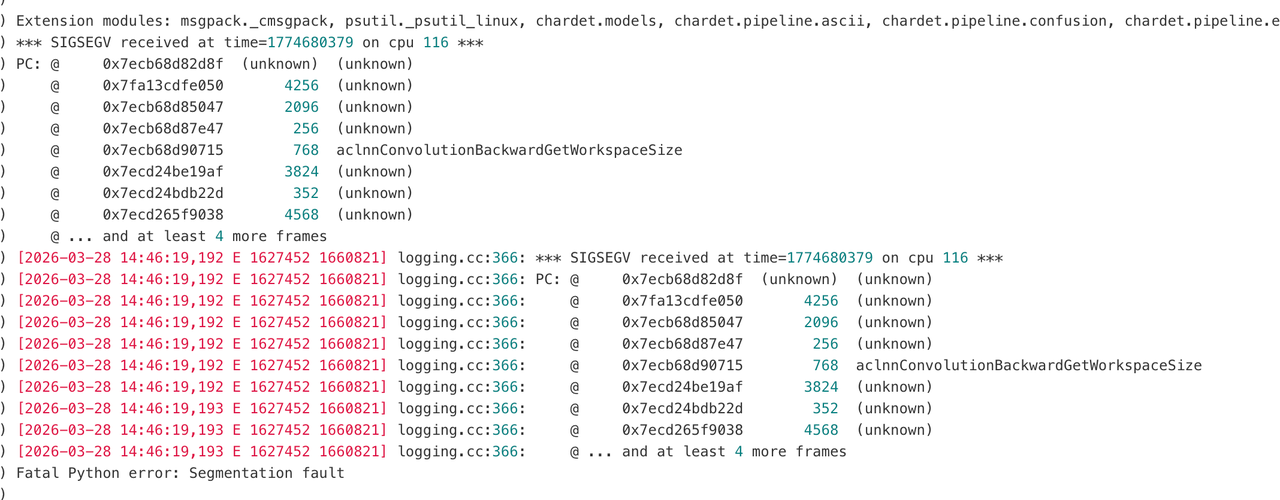
解决方案:
- 临时方案:通过
torch.randn构造模拟隐藏状态返回 - 根治方案:升级CANN至8.5.1及以上版本
6. 类型断言错误
问题现象:
FSDP层包装时预期接收列表类型但实际收到集合类型。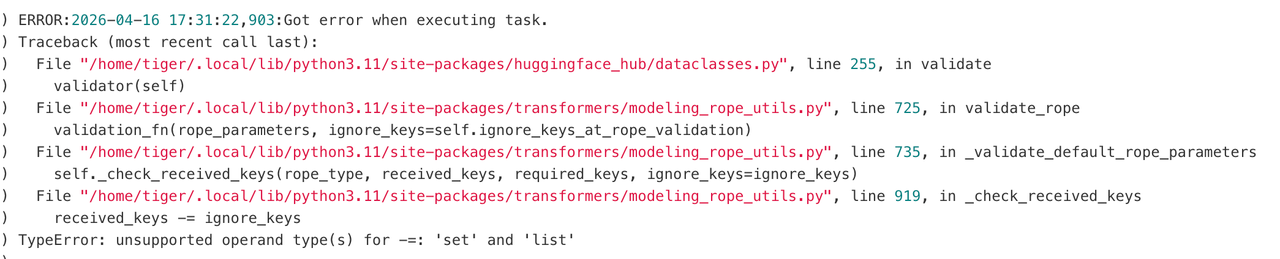
解决方案:
将输入类型强制转换为列表,该问题为通用问题,已在主线版本修复。
7. NPU补丁生效检测
问题现象:
Transformers 版本差异导致 NPU 补丁 import 错误而中断。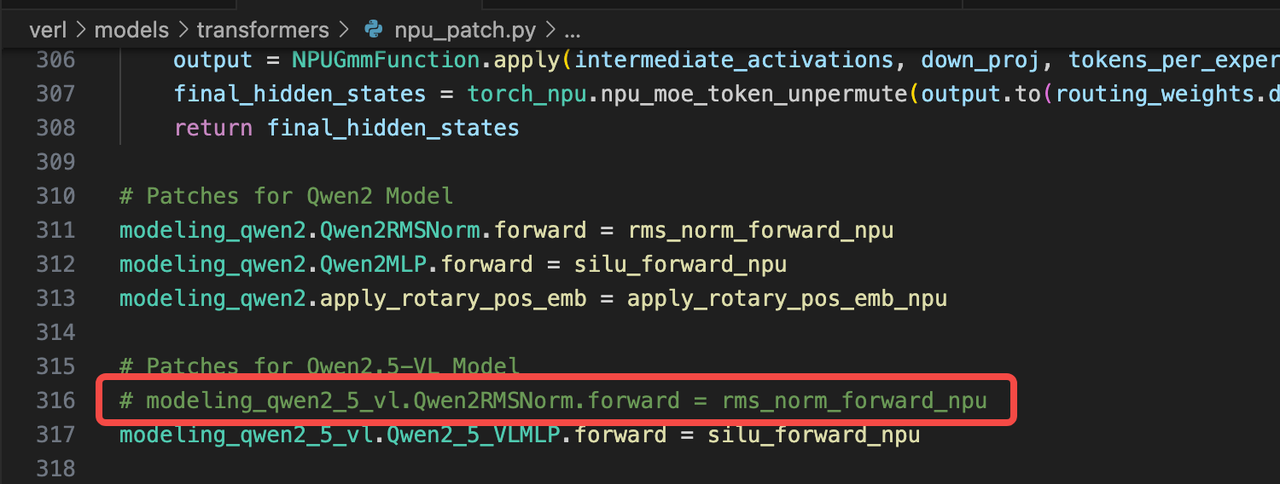
解决方案:
通过日志搜索确认补丁生效状态,已提交修复PR。
8. 集合运算兼容性
问题现象:
Transformers 5.4.0版本中集合减法操作不支持混合类型。
解决方案:
在rope_utils.py中将集合操作改为列表操作。

9. FSDP版本配置
问题现象:
FSDP2配置错误触发版本断言失败。
解决方案:
在脚本中同时配置FSDP1和FSDP2版本参数。

10. 设备匹配错误
问题现象:
Offload策略下出现CPU与NPU设备存储不匹配。
解决方案:
在state_dict调用前确保参数设备一致性,通过代码适配解决。

长序列训练优化
通过移除填充(remove padding)与序列并行(SP)技术支持更长序列训练:
- 显式传入cu_seqlens参数支持变长序列
- 在GDN层前向传播中补充序列长度信息
- 通过input_ids.offsets()自动生成cu_seqlens
当前FSDP方案通过参数卸载可在20K序列长度下稳定训练。
实现成果
- Veomni后端:2K→20K序列训练精度与GPU对齐
- FSDP后端:支持2K→128K长序列训练,Engine worker模式已打通
- 多模态支持:成功运行纯文本(AIME)和多模态(geo3k)数据集
通过系统性的问题排查和解决方案实施,成功在昇腾平台上建立了稳定高效的Qwen3.5强化学习训练流程,为大规模模型训练提供了可靠的技术基础。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)