
Atlas 800T A2部署qwen3.5-35b
本文介绍了在Atlas 800T A2服务器上部署Qwen3.5-35B大模型的完整流程。首先检查了硬件配置(8张910B3显卡)和操作系统(openEuler-24.03),然后下载并安装了Ascend驱动和固件。由于官方mindie框架尚未适配,选择使用vLLM 0.18.0rc1-openeuler版本作为推理框架。详细说明了权重文件下载、容器启动脚本配置以及vLLM服务启动命令的参数优化过
目录
一. 检查服务器、OS等配置
博主这里设备清单:
- 服务器型号:Atlas 800T A2
- 显卡类型:910B3,8张,单张显存64G
- 操作系统:openEuler-24.03(LTS-SP1)
- cpu指令架构:AArch64
二. 驱动和固件下载与安装
下载驱动链接:https://www.hiascend.com/hardware/firmware-drivers/community?product=4&model=26&cann=8.5.1&driver=Ascend+HDK+25.5.2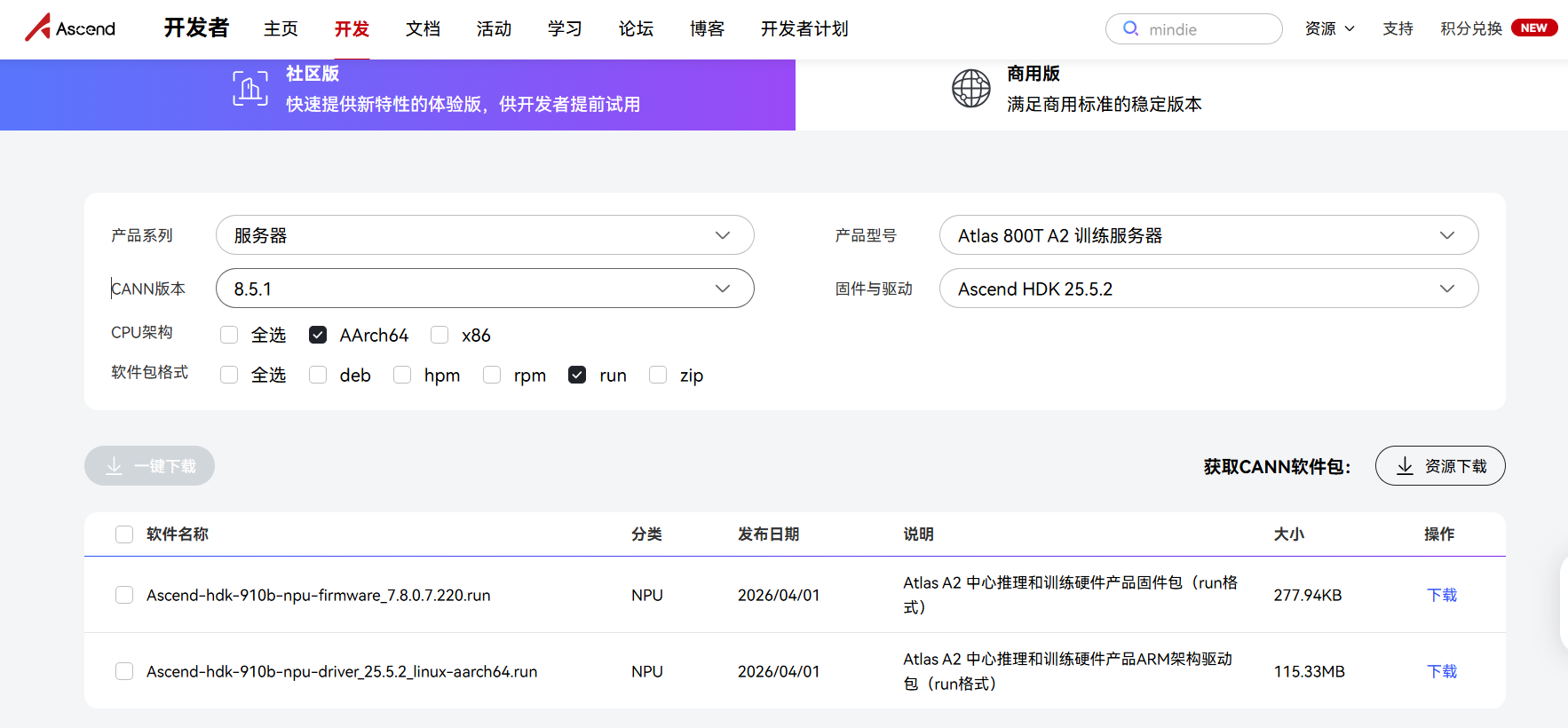
具体驱动安装参考:https://blog.csdn.net/mizhiakk/article/details/147305068
三. 下载vllm推理框架
由于官方mindie还不适配qwen3.5,所以使用vllm来拉取模型。
vllm下载链接:https://quay.io/repository/ascend/vllm-ascend?tab=tags
选择:v0.18.0rc1-openeuler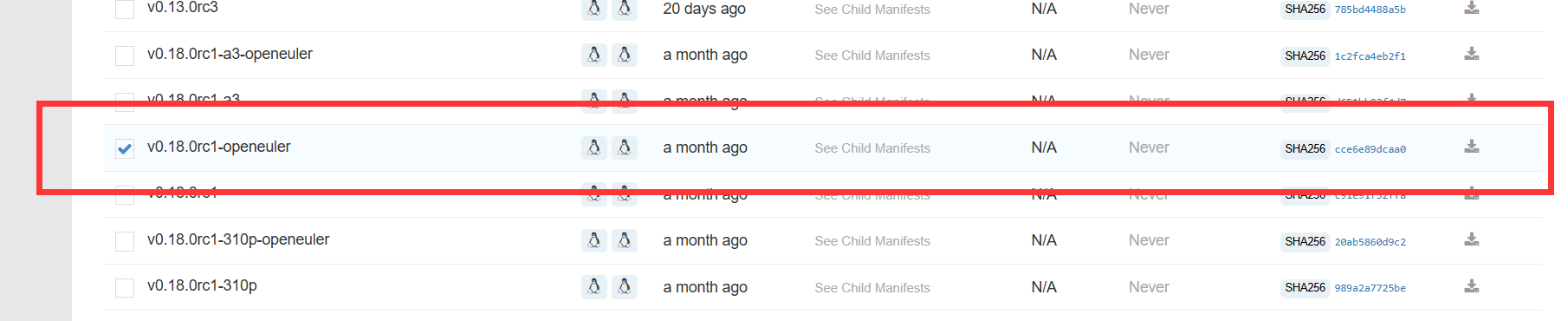
四. 下载权重文件
- qwen3.5-35B-A3B:https://www.modelscope.cn/models/Qwen/Qwen3.5-35B-A3B/files
具体操作参考:https://blog.csdn.net/qq_39671159/article/details/157475648?spm=1001.2014.3001.5501
五. 启动模型
1. model_start.sh文件
#!/usr/bin/sh
docker run -it -d --name qwen3_5_vllm_35b_2 --privileged=true --net=host --shm-size=120g --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /usr/local/dcmi:/usr/local/dcmi -v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info -v /etc/ascend_install.info:/etc/ascend_install.info -v /run/qwen3.5-35B-A3B/35B-A3B:/model 1aacf7df8a78 /bin/bash
2. vllm启动命令
- 这里类似mindie,mindie需要在conf.json修改参数,再使用官方的./mindieservic_daemon脚本启动模型;而vllm需要在命令中显式的指定相关参数。
本来博主使用下面命令来启动,启动成功。
vllm serve /model \
--served-model-name "qwen3.5-35b" \
--host 0.0.0.0 \
--port 8010 \
--data-parallel-size 1 \
--tensor-parallel-size 4 \
--max-model-len 5000 \
--max-num-batched-tokens 8192\
--max-num-seqs 128 \
--trust-remote-code \
--async-scheduling \
--allowed-local-media-path / \
--enforce-eager \
--additional-config '{"enable_cpu_binding":true, "multistream_overlap_shared_expert": true}'
- –tensor-parallel-size 4:4张卡同时处理同一个请求,减少单卡显存占用,加速单请求推理。
- –data-parallel-size 1 :所有请求都在同一组TP=4的4张卡上处理(一个模型副本)。相当于现在就是一个队列,如果不同客户端同时发请求,就需要排队,一个一个响应。如果设为2,那么就有了两个队列来处理求,增加了模型的吞吐率,但是DP=2 意味着需要两倍于 TP=4 的 GPU 资源,才能启动两个模型副本。
- max-model-len 5000:模型支持的最大序列长度(输入 + 输出 token 总数)。超出此长度会拒绝请求。这里显然太小了。推荐设置:65536(64K)即可覆盖大多数场景,设置成2的次方数不会提高性能。
- max-num-batched-tokens 8192:每个批次中最多处理的 token 数量(跨所有请求)。
- max-num-seqs 128:一个模型副本里,同时处理的请求的最大数量。
- trust-remote-code:允许执行模型仓库中的自定义代码(如 modeling.py)。对于非标准架构的模型(如 Qwen)通常需要开启。
- allowed-local-media-path / :允许访问的本地媒体文件根路径(用于多模态模型)。/ 表示允许访问整个根文件系统。
- enforce-eager:强制使用 eager 模式执行(而非 PyTorch 的 compile 或图模式)。便于调试,但可能降低性能。
- additional-config :传递给底层调度器的额外配置(JSON 格式)
enable_cpu_binding:将 GPU 线程绑定到特定 CPU 核心,减少上下文切换,提升性能。
multistream_overlap_shared_expert:针对 MoE(混合专家)模型,使共享专家的计算与路由计算重叠,降低延迟。
后来博主发现,提出问题后,回答的速度太慢了,有点像是一个字一个字蹦。后面博主又使用了以下命令:
vllm serve /model \
--served-model-name "qwen3.5-35b" \
--host 0.0.0.0 \
--port 8010 \
--tensor-parallel-size 4 \
--performance-mode interactivity\
--allowed-local-media-path /
这里博主使用了4张卡并发处理请求,并启用了多模态特性以支持大模型运行。
- performance-mode:vLLM 在 0.17.0 版本之后新增的一个性能调优参数,拥有下面三种选择:
① interactivity:低延迟,使用更细粒度的CUDA图,优先处理你的单次请求。
② throughput:高吞吐,采用更激进的批处理上限,最大化GPU利用率。
③ balanced(默认):折中,vLLM的默认调度策略。
六. 验证模型
验证使用openai来验证,具体操作参考:https://blog.csdn.net/qq_39671159/article/details/157475648?spm=1001.2014.3001.5501
七. 可能遇到的问题
Loading safetensors checkpoint shards: 0% Completed | 0/14 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 7% Completed | 1/14 [00:04<01:02, 4.77s/it]
Loading safetensors checkpoint shards: 14% Completed | 2/14 [00:09<00:58, 4.84s/it]
Loading safetensors checkpoint shards: 21% Completed | 3/14 [00:14<00:53, 4.85s/it]
Loading safetensors checkpoint shards: 29% Completed | 4/14 [00:19<00:48, 4.86s/it]
Loading safetensors checkpoint shard : 36% Completed | 5/14 [00:24<00:43, 4.88s/it]
Loading safetensors checkpoint shard : 43% Completed | 6/14 [00:29<00:39, 4.90s/it]
- 拉取大模型,加载模型检查点,卡住了,不动了。
- Answer:
① 将权重文件,改变存放路径
② 修改model_start.sh文件中权重文件的路径
③ 重新用model_start.sh启动容器
④ 重新使用VLLM命令拉取大模型 - Analyse:最后测试了好多种情况,只要容器没有docker stop,那么不管怎么执行VLLM命令都不会卡住;只要容器docker stop了,那么就要执行Answer中的操作。直接在model_start.sh文件修改模型权重文件的其他路径(之前docker启动用过),还是会卡住,必须要手动挪权重文件的位置。
- Conclusion:Docker 容器停止后,其文件系统内部可能残留了错误的“指针”或损坏的缓存状态。当第一次用 model_start.sh 启动容器、加载模型时,vLLM会在容器内的某些位置写入一些中间状态文件。docker stop后,原路径下还残留着之前的碎片文件、不完整的分片、或者损坏的索引,vLLM 在扫描所有权重分片时就会卡住。
ValueError: Free memory on device (12.03/60.96 GiB) on startup is less
than desired GPU memory utilization (0.9, 54.86 GiB)
- Answer:最终也没彻底解决这个问题。而是用VLLM在前4张卡跑的模型,来规避了这个问题。
- Analyse:一共有8张卡,博主之前使用 MindIE 框架,在前4张GPU卡(例如 device 0-3)上运行 Qwen3-32 模型;使用VLLM推理框架,在后4张GPU卡(device 4-7)上运行Qwen3.5-35B 模型。但是不管怎么加配置语句,VLLM还是会扫描前面几张卡,然后报内存不够的问题。
- Conclusion:VLLM-Ascend 版本在设备发现和内存检查逻辑上可能仍依赖于底层驱动报告的所有设备,未能完全通过环境变量或参数隔离。
参考:
https://modelers.cn/models/vLLM_Ascend/Qwen3.5-35B-A3B
https://blog.csdn.net/weixin_45724433/article/details/160470026
https://developer.huawei.com/home/forum/ascend/thread-02162212217069313067-1-1.html

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)