
昇腾FlatQuant、MXFP重构大模型量化新范式
昇腾处理器凭借其独特的硬件架构优势,深度融合低精量化技术,为DeepSeek、Qwen3等系列主流大模型提供了高效、精准的量化方案,实现了模型瘦身与性能提升的双重目标。随着技术的持续演进和应用场景的不断拓展,量化技术必将在大模型产业化落地的道路上发挥更加关键的作用,推动人工智能技术惠及更广泛的领域。昇腾亲和加速的量化解决方案,以W8A8/W4A8/W4A4、A5的MXFP量化为代表,从技术原理的创
在大模型蓬勃发展的今天,模型大小的持续膨胀已成为行业共识。从早期的几十亿参数到如今的千亿、万亿级别,大模型的推理部署面临着前所未有的挑战:显存占用居高不下、推理延迟难以优化、部署成本持续攀升。
如何在保证模型精度的前提下,有效压缩模型体积、提升推理性能,成为产业落地的关键命题。低精度量化技术作为模型压缩的核心手段之一,通过缩减权重与激活值的存储比特位宽,在精度与性能之间寻找最优平衡点。昇腾处理器凭借其独特的硬件架构优势,深度融合低精量化技术,为DeepSeek、Qwen3等系列主流大模型提供了高效、精准的量化方案,实现了模型瘦身与性能提升的双重目标。
- 业界主流量化算法以及昇腾场景面临的挑战
量化是将模型中高精度浮点数(如FP16、FP32)转换为低精度整数(如INT8、INT4)的技术过程。其核心思想在于:神经网络中的权重和激活值往往分布在相对集中的数值范围内,使用更少的比特位表示这些数值,可以大幅减少存储空间和计算开销。
以一个10B参数的模型为例,采用FP16存储需要约20GB显存,而量化至INT8仅需约10GB,INT4更是可压缩至约5GB。这种指数级的存储优化,为大模型在边缘设备、资源受限环境中的部署打开了新的可能性。
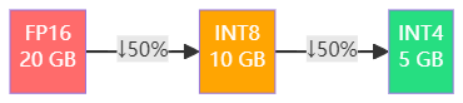
但大量实验表明,大模型难以量化,难点主要集中在以下方面:
- 激活量化难度远高于权重量化
实验验证,对大模型权重采用 INT8、INT4 低位量化时,模型精度几乎不会出现明显损失。
- 激活分布存在极端离群值,严重干扰量化映射
大模型激活离群值幅值远超常规激活值,差距可达百倍以上。若直接采用 INT8 均匀量化,绝大部分正常激活值会被截断归零,造成严重精度衰减。
- 激活离群值具有通道固定性
异常幅值会长期稳定出现在固定特征通道内,无法通过动态平滑方式消除,进一步加剧低位量化误差。
针对上述激活量化难题,SmoothQuant 提出数学等价的逐通道平滑变换方案,有效均衡各通道数值幅值,降低模型整体量化难度,在维持模型精度的同时优化推理性能。
该算法对激活张量按通道除以平滑因子s,为保证矩阵乘法运算数学等价,同步对权重张量对应行乘以相同因子s。借助线性变换守恒特性,输出结果不会发生改变,矩阵乘公式如下:
![]()
在 channel 维度(列)上每个元素除以 s ,![]() 则在每行上每个元素乘以 s ,以此来保障Y在数学上等价。
则在每行上每个元素乘以 s ,以此来保障Y在数学上等价。
结合大模型权重量化鲁棒性强、激活量化极易掉点的特点,SmoothQuant 通过平滑因子将激活上难以量化的离群幅值,等效转移至权重侧处理,从而实现8比特权重、8 比特激活 (W8A8) 量化,兼顾模型精度与推理加速效果。
为了进一步对权重进行压缩,AWQ、GPTQ等量化算法通过激活感知、二阶信息补偿等方式来保持量化精度。以激活感知权重量化(Activation-aware Weight Quantization,AWQ) 为例,通过保护更“重要”的权重不进行量化,从而在不进行训练的情况下提高准确率。基于这些算法,W4A16/W4A8等量化方式在保障激活精度的同时,将权重压缩到4bit,能极大节省显存,成为业界通用的量化方式。
而主流的量化方案W4A16之所以高效,是因为有诸如Marlin这类高度优化、与硬件架构深度耦合的计算内核。相比之下,昇腾NPU的挑战主要体现在以下几个方面:
- 专用化设计限制:达芬奇架构的Cube计算单元对于INT4到FP16的混合精度计算,缺乏直接的原生支持。
- 非对称的内存访存:W4A16的实现必须先解压缩INT4权重,再执行FP16矩阵乘法(GEMM)。这个“解压缩”过程引入了大量额外数据读写,导致访存瓶颈。
- 极致压缩的艺术 —— flatQuant与W4A4量化
W4A4量化将权重和激活值均压缩至INT4,是目前主流量化方案中的极致压缩形态。
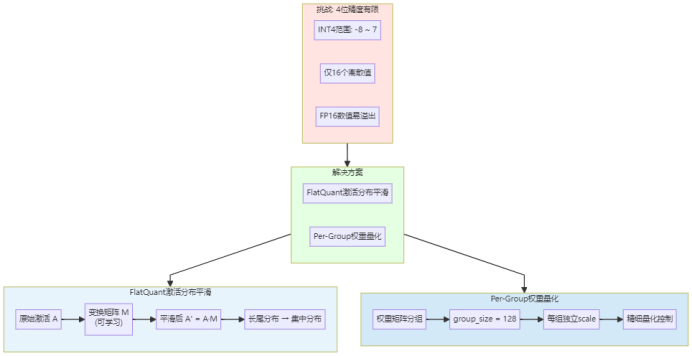
flatQuant激活分布平滑:
W4A4 量化面临的核心挑战在于:INT4 的表示范围极为有限(仅16个离散值),激活值的微小波动都可能导致显著的量化误差。为解决这一问题,昇腾引入了flatQuant技术,在量化前对激活分布进行平滑处理。
flatQuant的核心思想是通过可学习的线性变换矩阵,将激活值转换至更适合量化的分布空间。设原始激活为A,flatQuant学习变换矩阵M,使得变换后的激活A' = A·M具有更平坦、更集中的分布特性。这种预处理显著降低了量化误差,为INT4量化奠定了基础。
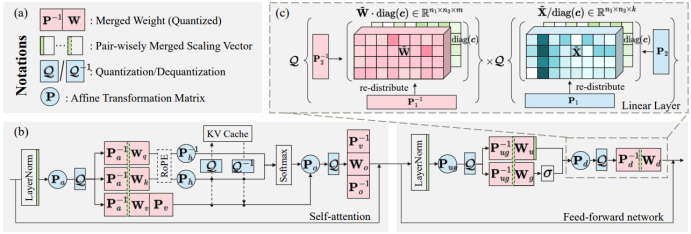
flatQuant利用仿射变换来消除Outlier,也就是把INT4量化的Y=Q(X)×Q(WT) 变为 Y'=Q(XP)×Q(P-1WT)。优化矩阵P以最小化Output MSE,得到如下式子:
![]()
其中Q(P-1WT)离线计算,我们主要关注在线计算的Q(XP)部分。
P本身是个n*n (n=hidden dim)的矩阵,直接在线计算XP显然不现实。于是flatQuant利用Kronecker Decomposition进行分解,将P矩阵分解为P1⊗P2,(⊗为Kronecker Product);通过P矩阵完成Activation矩阵的平坦化后,同时也利用了现有较成熟的per-channel scaling平滑算法,并使用learnable clipping削减量化过程中的精度损失。
完成矩阵P的分解后,计算量已大大减小,但还是会引入一定开销。如图中蓝色的部分是量化框架引入的额外计算。然而相比额外计算开销,4bit量化带来的性能收益非常可观。
- 混合精度的创新实践——A5与MXFP量化
A5作为新一代昇腾处理器,引入了对MXFP(Microscaling Floating Point)量化格式的原生支持。MXFP是OCP(开放计算项目)推出的新兴标准,采用块级缩放因子与浮点数值表示相结合的创新架构。
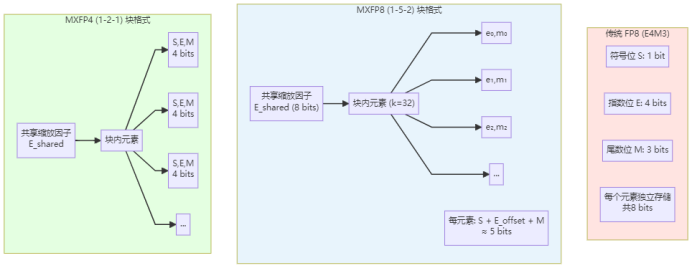
MXFP8量化原理
MXFP8采用1-5-2格式,即1位符号位、5位指数位、2位尾数位。与标准FP8的显著区别在于:MXFP引入块级缩放因子(Block Scaling Factor),将相邻的数值元素组成一个块,块内共享指数基准,每个元素仅需存储尾数和偏移指数。
具体而言,MXFP8将每k个元素(典型值为32)组成一个块,块内共享一个共享指数E_shared,每个元素存储各自的尾数m_i和指数偏移e_i。这种设计在保持8位总存储的同时,有效扩展了动态范围,特别适合表示神经网络中常见的长尾分布数值。
MXFP4量化原理
MXFP4进一步压缩至4位,采用1-2-1格式(1位符号位、2位指数位、1位尾数位)。同样采用块级缩放因子机制,MXFP4在极致压缩存储的同时,尽可能保留了数值表示的有效范围。每个块内的元素共享缩放基准,通过尾数和局部指数偏移实现差异化表示。
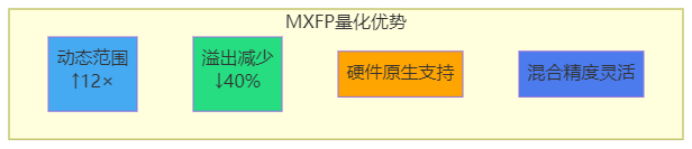
MXFP量化的技术优势
动态范围扩展:传统INT4的表示范围仅为-8到7,MXFP4通过浮点表示和块级缩放,有效扩展了动态范围。实验表明,MXFP4在表示神经网络权重时,相比INT4可减少约40%的溢出情况,精度损失显著降低。
硬件级加速支持:A5处理器针对MXFP格式进行了硬件级优化,包括专用的块缩放因子计算单元、MXFP格式的矩阵乘法加速器等。这种软硬件协同设计使得MXFP量化不仅能够减少存储占用,更能实现真正的计算加速。
混合精度部署灵活:MXFP8和MXFP4支持灵活的混合精度部署策略。对于模型中精度敏感的关键层(如Attention层),可采用MXFP8;对于精度冗余较大的层(如部分MLP层),可采用MXFP4。这种差异化策略在保证整体精度的同时,最大化压缩收益。
- 昇腾量化实践
详细的量化步骤、使用指南可以参考官方文档:https://github.com/vllm-project/vllm-ascend/blob/main/docs/source/user_guide/feature_guide/quantization.md
4.1 量化工具
4.1.1. ModelSlim
ModelSlim是昇腾亲和的模型量化工具,工具安装:
|
git clone https://gitcode.com/Ascend/msmodelslim.git |
|
cd msmodelslim |
|
bash install.sh |
模型量化:
Modelslim量化推荐实践集可参考:https://gitcode.com/Ascend/msmodelslim/tree/master/example
以Qwen3.5-27B W8A8量化为例:
msmodelslim quant --model_path ${MODEL_PATH} --save_path ${SAVE_PATH} --device npu --model_type Qwen3.5-27B --quant_type w8a8 --trust_remote_code True
执行上述量化命令,即得到量化后的权重。
4.1.2 LLM-Compressor
LLM-Compressor是一款业界开源的模型量化工具,安装如下:
pip install llmcompressor
模型量化(以w8a8为例):
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend/examples/quantization/llm-compressor
python3 w8a8_int8_dynamic.py
4.2 加载量化模型进行推理
4.2.1 离线推理
import torch
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The future of AI is",
]
# Set sampling parameters
sampling_params = SamplingParams(temperature=0.6, top_p=0.95, top_k=40)
llm = LLM(model="/path/to/your/quantized_model",
max_model_len=4096,
trust_remote_code=True,
# Set appropriate TP and DP values
tensor_parallel_size=2,
data_parallel_size=1,
# Set an unused port
port=8000,
# Set serving model name
served_model_name="quantized_model"
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
4.2.2 在线推理
python -m vllm.entrypoints.api_server \
--model /path/to/your/quantized_model \
--max-model-len 4096 \
--port 8000 \
--tensor-parallel-size 2 \
--data-parallel-size 1 \
--served-model-name quantized_model \
--trust-remote-code
- 未来展望
低精度量化技术的发展仍处于快速演进阶段,展望未来,以下几个方向值得重点关注:
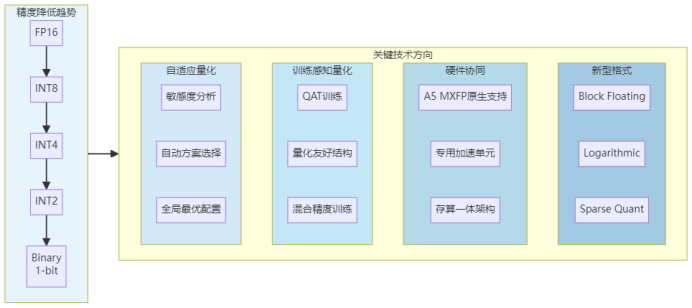
更低精度探索:2位量化(W2A2)甚至1位二值网络的研究正在推进,如何在极致压缩下保持模型能力是核心挑战。
自适应量化:根据各层对精度的敏感度自动选择最优量化方案,实现精度与压缩的全局最优。
训练感知量化:在模型训练阶段引入量化感知,使得训练后的模型天生适合低精度部署。
硬件协同演进:随着A5等新代际处理器的推出,MXFP等新型量化格式将获得更完善的硬件支持,开启低度量化的新篇章。
昇腾亲和加速的量化解决方案,以W8A8/W4A8/W4A4、A5的MXFP量化为代表,从技术原理的创新,到硬件架构的协同优化,再到部署工具链的完善构建,提供了一套完整、高效、易用的量化实践路径。
低度量化不仅实现了模型的"瘦身",更在精度保持、推理加速、部署成本等多个维度创造了显著价值。随着技术的持续演进和应用场景的不断拓展,量化技术必将在大模型产业化落地的道路上发挥更加关键的作用,推动人工智能技术惠及更广泛的领域。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 2
2 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)