
银河麒麟v10 Server 本地部署多模态模型 #3
银河麒麟v10 Server 本地部署大模型 #3
懒了好多天,还是决定把最近一段时间的工作日志写一下,前段时间不想写日志的原因是配置得相对比较顺利,进度一直在按部就班地推进。但干活总得留下点什么,主要还是因为记性比较差。万一以后哪天机器出问题了,还能留下点能复现的教程。
一、进度介绍
硬件总览
| 组件 | 详细信息 |
|---|---|
| CPU | 2 × 华为鲲鹏 920 (Kunpeng 920 5220) |
| 内存 | 总容量:254 GiB |
| 系统盘 | 致态 Ti600 4TB NVMe SSD |
| 数据盘 | 东芝 3.6T SATA HDD |
| 处理加速器 | 2 × Atlas 300I Duo 推理卡 |
软件总览
| 项目 | 详细信息 |
|---|---|
| 操作系统 | Kylin Linux Advanced Server V10 (Halberd) ID: kylin,VERSION_ID: V10 |
| 内核版本 | 4.19.90-89.11.v2401.ky10.aarch64 |
| 架构支持 | aarch64 (ARM 64-bit) |
| Python版本 | 3.7.9 |
| Docker版本 | 29.3.0 |
| NPU驱动版本 | 25.2.0 |
| MindIE版本 | 2.3.0 |
| OpenWebUI版本 | 0.8.10 |
| 已验证部署模型 | DeepSeek-R1-Distill-Qwen-32B,Qwen2.5-VL-3B-Instruct |
二、Qwen2.5-VL-32B-Instruct部署
已经成功部署了Qwen2.5-VL-3B-Instruct,但3B的模型确实在准确度方面比较差,对于一些复杂图形的理解能力能力也有限,想要更高级的应用,还是要部署更大的模型
故选择部署Qwen2.5-VL-32B-Instruct,因为同版本的3B模型已经成功部署了,32B的模型无非也就是调一下参数,不存在太多的兼容性问题
获取模型文件
还是一样,为了避免网络原因导致下载中断浪费时间,先去hugging face镜像站获取模型结构
对于LFS追踪的大文件,只下载一个指针文件,而不下载实际内容
[@localhost ]#GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/Qwen/Qwen2.5-VL-32B-Instruct
正克隆到 'Qwen2.5-VL-32B-Instruct'...
remote: Enumerating objects: 78, done.
remote: Counting objects: 100% (78/78), done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 78 (delta 38), reused 70 (delta 30), pack-reused 0
接收对象中: 100% (78/78), 完成.
处理 delta 中: 100% (38/38), 完成.
根据仓库里的指针文件,去专门的LFS服务器下载那些大文件的实际内容
[@localhost ]# cd Qwen2.5-VL-32B-Instruct
/data/Qwen2.5-VL-32B-Instruct
[@localhost ]# git lfs pull
下载完成
部署参数调整
不同于vLLM架构下部署大模型,MindIE架构在部署大模型时,不直接通过docker参数传递模型参数,而是通过一个config.json文件确定模型运行参数
模型运行参数的详细说明在昇腾社区的配置参数说明(服务化)一文中有详细说明,这里不再赘述,只挑选几个3B模型调整到32B模型需要修改的关键参数来介绍,这个配置参数的调整旨在让模型能跑起来,并不代表性能最优配置
需要修改的参数集中在config.json的ModelDeployConfig和ScheduleConfig两个部分,3B模型的参数如图所示
"ModelDeployConfig" :
{
"maxSeqLen" : 32768,
"maxInputTokenLen" : 16384,
"truncation" : false,
"ModelConfig" : [
{
"modelInstanceType" : "Standard",
"modelName" : "Qwen2.5-VL-3B-Instruct",
"modelWeightPath" : "/data/Qwen2.5-VL-3B/Qwen2.5-VL-3B-Instruct",
"worldSize" : 4,
"cpuMemSize" : 0,
"npuMemSize" : -1,
"backendType" : "atb",
"trustRemoteCode" : false,
"async_scheduler_wait_time": 120,
"kv_trans_timeout": 10,
"kv_link_timeout": 1080
}
]
},
"ScheduleConfig" :
{
"templateType" : "Standard",
"templateName" : "Standard_LLM",
"cacheBlockSize" : 128,
"maxPrefillBatchSize" : 50,
"maxPrefillTokens" : 16384,
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 200,
"maxIterTimes" : 16384,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000,
"maxFirstTokenWaitTime": 2500
}
1.modelName 与 modelWeightPath
modelName: Qwen2.5-VL-32B-Instruct -> Qwen2.5-VL-3B-Instruct
modelWeightPath: /data/…/32B/… -> /data/…/3B/…
指定要加载的模型名称和权重文件夹路径,MindIE 据此去找模型文件。
2.npuMemSize
npuMemSize: -1 -> 8
限制每个 NPU 设备可使用的最大设备内存(HBM)大小,-1 表示不额外限制,允许模型运行时按需占用全部可用显存。
Qwen2.5-VL-32B 权重大(FP16 约 64 GB),张量并行分配到 4 张卡后,每卡仅权重就需要约 16 GB,再加上 KV Cache 和中间激活,显存用量会非常大
若不限制,MindIE 可能会尝试占用全部可用显存,在长序列或多请求下极易触发 OOM,导致服务 crash,这里写成 8 可能偏小,但是先把模型跑起来,性能后续再说
3.maxSeqLen 与 maxInputTokenLen
maxSeqLen: 32768->8192
maxInputTokenLen: 16384->2048
maxSeqLen是模型能处理的最大序列总长度(提示词 + 生成 token 数),maxInputTokenLen是单次请求输入 token 的最大长度
KV Cache 的显存占用与序列长度成正比。32B 模型的层数更多、隐藏维度更大,KV Cache maxInputTokenLen: 16384->2048的“膨胀系数”远高于 3B 模型。若维持 32k 的上下文窗口,KV Cache 所需的显存可能会超过单卡 8 GB 的限制,直接导致显存不足,必须大幅缩短上下文长度。
4.truncation
truncation: false -> true
truncation参数决定当输入令牌数超过 maxInputTokenLen 时,是否自动截断而不是拒绝请求。
因为压缩了maxInputTokenLen实际使用中
5.maxPrefillBatchSize和maxPrefillTokens
maxPrefillBatchSize:50->1
maxPrefillTokens:16384->2048
maxPrefillBatchSize是预填充阶段一次并行处理的请求数量上限,maxPrefillTokens是预填充阶段一次性处理的最大 token 总数,这两个值谁先达到各自的取值就完成本次组batch
在这里maxPrefillTokens的值与maxInputTokenLen的值保持一致,而maxPrefillBatchSize比较激进地设置为1,在部署测试阶段的低并发场景下,最大限度保障服务可用
6.maxBatchSize
解码阶段允许的最大批处理大小,计算公式如下
首先计算block_num:
Total Block Num = Floor(NPU显存/(模型网络层数*cacheBlockSize*模型注意力头数*注意力头大小*Cache类型字节数*Cache数)),其中,Cache数=2;在tensor并行的情况下,block_num*world_size为实际的分配block数。
如果是多卡,公式中的模型注意力头数*注意力大小的值需要均摊在每张卡上,即“模型注意力头数*注意力大小/卡数”。
公式中的Floor表示计算结果向下取整。
为每个请求申请的block数量Block Num = Ceil(输入Token数/cacheBlockSize)+Ceil(最大输出Token数/cacheBlockSize)。
输入Token数:输入(字符串)做完tokenizer后的tokenID个数;最大输出Token数:模型推理最大迭代次数和最大输出长度之间取较小值。
公式中的Ceil表示计算结果向上取整。
maxBatchSize = Total Block Num/Block Num。
解码阶段虽然每步计算量比预填充小,但 KV Cache 占用和激活值都会叠加,同时处理过多请求会导致显存超限,缩小到 8 兼顾吞吐与显存安全。
这套参数组合使得 32B 模型能够在有限的硬件上先“跑起来”,但代价是牺牲了长文本处理能力、多用户并发体验以及整体吞吐量。
模型运行效果
如图,运行效果要明显优于3B的模型,特别是在图像细节理解上,能够注意到k线图的上下影线,这是3B模型所不具备的能力。

三、Qwen3-VL部署
虽说Qwen2.5VL已经基本满足使用需要了,但是Qwen3VL在同参数量下的性能更强,也多了很多高级的特性,所以还是想测试一下部署的可能性
兼容性查询
通过查阅开发文档可知,MindIE架构目前还不支持部署Qwen3-VL系列,所以需要转而使用vLLM架构
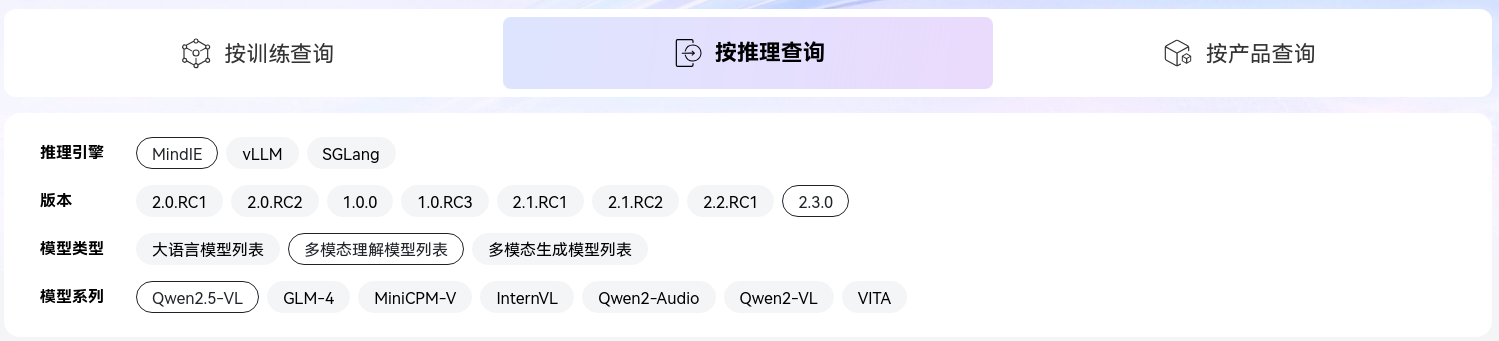
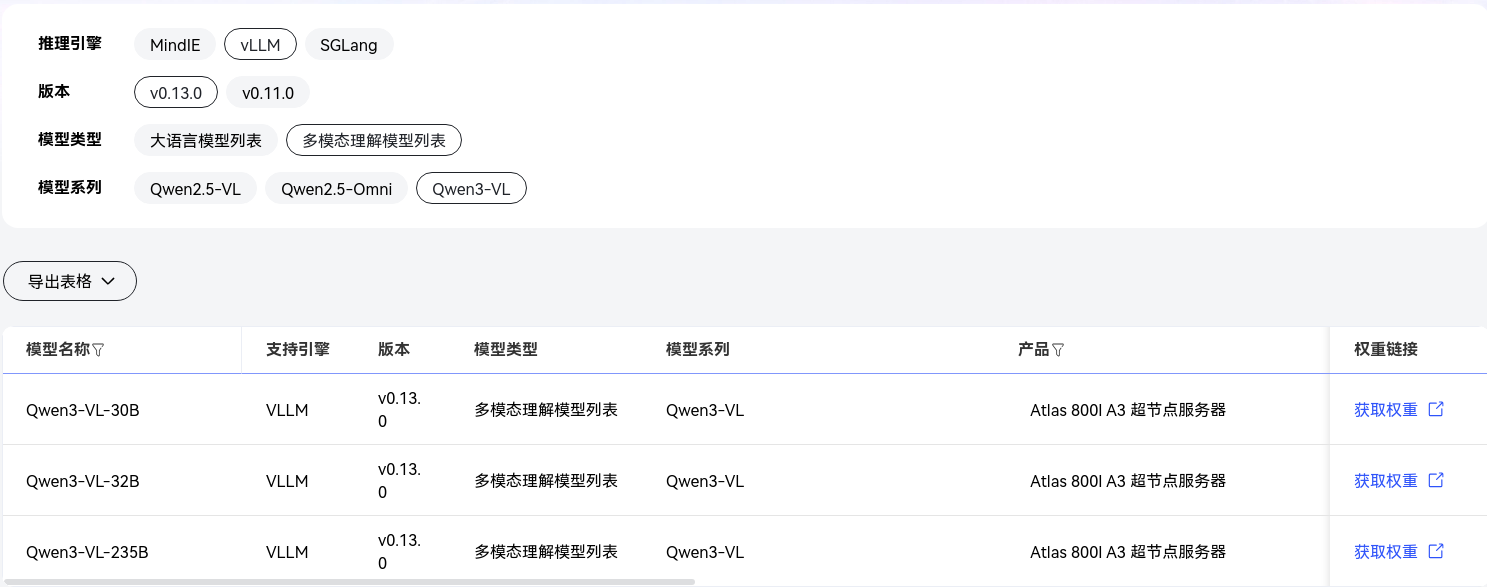
vLLM 社区与昇腾合作,通过 vLLM-Ascend 插件已实现对 Qwen3-VL 的良好支持
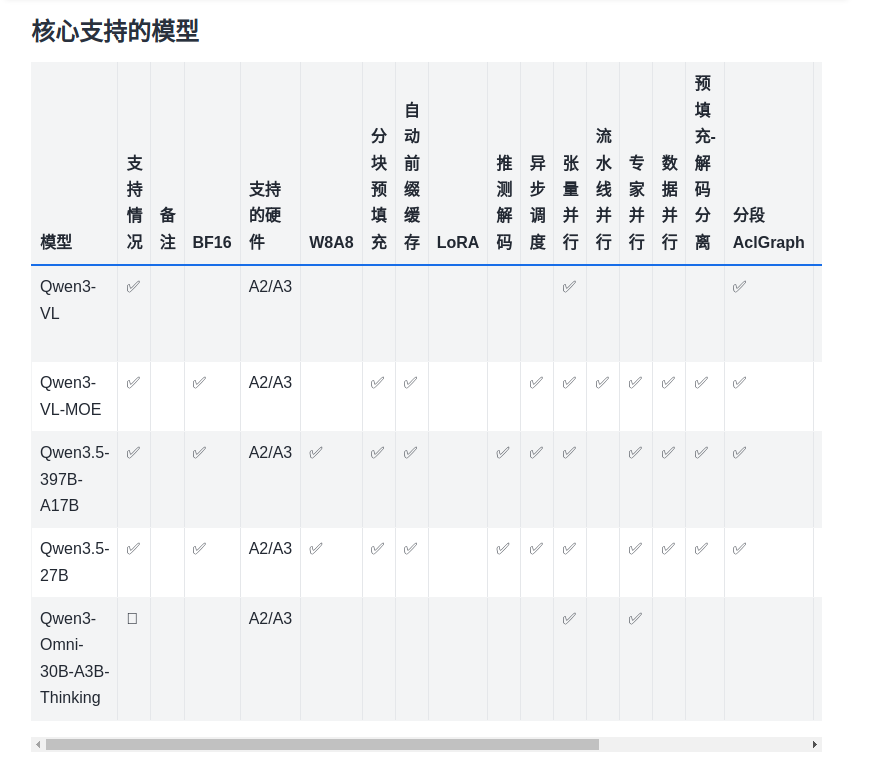
但是存在一个问题,对本机的NPU(Atlas 300I Duo)还处于实验性支持阶段

无论如何,还是需要部署一下尝尝咸淡,幸运的是,在我之前已经有一位大佬在这个NPU上部署过Qwen3模型,所以我们也是摸着石头过河,记录一下自己的部署经历
理论部署路径
1.检查驱动版本以满足vllm-ascend容器运行条件
[@localhost ]# cat /usr/local/Ascend/firmware/version.info
Version=7.8.0.7.220
firmware_version=1.0
package_version=25.5.2
compatible_version_drv=[23.0.rc2,23.0.rc2.],[23.0.rc3,23.0.rc3.],[23.0.0,23.0.0.],[24.0,24.0.],[24.1,24.1.],[25.0,25.5.]
或者
[@localhost ]# npu-smi info -t board -i 5
NPU ID : 5
Product Name : IT21PD2G10
Model : NA
Manufacturer : Huawei
Serial Number : 2106030737ZERC005995
Software Version : 25.2.0
Firmware Version : 7.8.0.7.220
Compatibility : OK
Board ID : 0xb1
PCB ID : E
BOM ID : 3
PCIe Bus Info : 0000:03:00.0
Slot ID : 5
Class ID : NA
PCI Vendor ID : 0x19E5
PCI Device ID : 0xD500
Subsystem Vendor ID : 0x0200
Subsystem Device ID : 0x0110
Chip Count : 2
Chip Fault : 0
2.获取模型文件
公式化获取模型文件这一块
对于LFS追踪的大文件,只下载一个指针文件,而不下载实际内容
[@localhost ]#GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/Qwen/Qwen3-VL-4B-Thinking-FP8
正克隆到 'Qwen3-VL-4B-Thinking-FP8'...
remote: Enumerating objects: 78, done.
remote: Counting objects: 100% (78/78), done.
remote: Compressing objects: 100% (47/47), done.
remote: Total 78 (delta 38), reused 70 (delta 30), pack-reused 0
接收对象中: 100% (78/78), 完成.
处理 delta 中: 100% (38/38), 完成.
根据仓库里的指针文件,去专门的LFS服务器下载那些大文件的实际内容
[@localhost ]# cd Qwen3-VL-4B-Thinking-FP8
/data/Qwen3-VL-4B-Thinking-FP8
[@localhost ]# git lfs pull
下载完成
3.拉取容器镜像
用容器部署,能够做到环境隔离,软件版本互不干扰,发明docker的人真是个天才
docker pull quay.io/ascend/vllm-ascend:v0.18.0rc1-310p-openeuler
4.设计启动参数
参照之前MindIE的config.json和启动脚本配置
关键在设备挂载、驱动和库文件挂载、模型目录挂载以及指定运行参数
vllm serve /workspace/models/Qwen3-VL-30B-A3B-Instruct-FP8 \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 4096 \
--gpu-memory-utilization 0.9 \
--dtype float16 \
--trust-remote-code \
--max-num-seqs 16 \
--block-size 64 \
--swap-space 32
5.功能验证与测试
在接入OpenWebUI之前,先测试容器服务提供情况
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/Qwen3-VL-4B-Thinking-FP8",
"messages": [{"role": "user", "content": "你好,请介绍下你自己"}],
"max_tokens": 100
}'
实际部署情况
1.检查驱动版本
[@localhost ]# cat /usr/local/Ascend/firmware/version.info
Version=7.7.0.6.236
firmware_version=1.0
package_version=25.2.0
compatible_version_drv=[23.0.rc2,23.0.rc2.],[23.0.rc3,23.0.rc3.],[23.0.0,23.0.0.],[24.0,24.0.],[24.1,24.1.],[25.0,25.2.]
大佬的博客里面固件版本是7.8.0.7.220,目前看版本是略有差别,但是暂且先跑一下看有没有问题,有问题再从昇腾社区下载就好了
从未来穿越回来,事实上这个固件版本不兼容,查看docker log报如下错误,即使使用了 --enforce-eager参数也无法解决
(EngineCore pid=110) [ERROR] 2026-04-15-07:07:48 (PID:110, Device:0, RankID:-1) ERR00100 PTA call acl api failed.
(EngineCore pid=110) [PID: 110] 2026-04-15-07:07:48.918.234 AclNN_Parameter_Error(EZ1001): DynamicQuant launch kernel failed.
(EngineCore pid=110) TraceBack (most recent call last):
(EngineCore pid=110) Tiling failed
(EngineCore pid=110) Tiling Failed.
(EngineCore pid=110) Kernel GetWorkspace failed. opType: 35
(EngineCore pid=110) DynamicQuant launch kernel failed.
(EngineCore pid=110)
(EngineCore pid=110)
(EngineCore pid=110) Set TORCHDYNAMO_VERBOSE=1 for the internal stack trace (please do this especially if you're reporting a bug to PyTorch). For even more developer context, set TORCH_LOGS="+dynamo"
(EngineCore pid=110)
遂下载对应版本固件,昇腾社区中文站下载需要登录,但是不知道为什么,登录时候一直报错*因隐私合规要求,昇腾社区中文站禁止海外用户登录*,最后还是从大佬的博客下载了一个,遂自己也上传一个,把链接放在这里7.8.0.7.220
2.获取模型文件
经测试,Qwen3-VL-4B-Thinking-FP8在当前硬件环境下跑不起来,会报如下错误
(APIServer pid=1) pydantic_core._pydantic_core.ValidationError: 1 validation error for ModelConfig
(APIServer pid=1) Value error, fp8 quantization is currently not supported in npu. [type=value_error, input_value=ArgsKwargs((), {'model': ...rocessor_plugin': None}), input_type=ArgsKwargs]
当前使用的 vLLM-Ascend 版本(v0.18.0rc1)在 310P 推理卡上尚不支持 FP8 量化模型。
遂转向Qwen3-VL-2B 😦
公式化获取模型文件,此处不再赘述
3.拉取容器镜像
很顺利,不再赘述
4.设计启动参数
关键在设备挂载、驱动和库文件挂载、模型目录挂载以及指定运行参数
这里借助了一个小工具runlike,平时有可能忘记docker当时跑起来的时候都设置了什么参数,没关系,对着容器名跑一下就行了
[@localhost ]#runlike Qwen2.5-VL-32B
docker run
--name=Qwen2.5-VL-32B
--hostname=localhost.localdomain
--volume /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf
--volume /var/log/npu/profiling:/var/log/npu/profiling
--volume /var/log/npu/slog:/var/log/npu/slog
--volume /data/Qwen2.5-VL-32B:/data/Qwen2.5-VL-32B
--volume /usr/local/Ascend/driver:/usr/local/Ascend/driver
--volume /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi
--volume /var/log/npu/dump:/var/log/npu/dump
--volume /usr/local/Ascend/add-ons:/usr/local/Ascend/add-ons
--volume /data/Qwen2.5-VL-32B/config.json:/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
--volume /usr/local/Ascend/toolbox:/usr/local/Ascend/toolbox:ro
--volume /usr/local/sbin:/usr/local/sbin
--volume /var/log/npu:/usr/slog
--dns=8.8.8.8
--network=host
--privileged
--workdir=/
-p 1025:1025
-p 1026:1026
--restart=always
--device /dev/davinci1:/dev/davinci1
--device /dev/hisi_hdc:/dev/hisi_hdc
--device /dev/davinci0:/dev/davinci0
--device /dev/davinci3:/dev/davinci3
--device /dev/davinci_manager:/dev/davinci_manager
--device /dev/davinci2:/dev/davinci2
--device /dev/devmm_svm:/dev/devmm_svm
--runtime=runc
--detach=true
-t swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.3.0-300I-Duo-py311-openeuler24.03-lts
bash -c 'source /usr/local/Ascend/atb-models/set_env.sh && source /usr/local/Ascend/mindie/latest/mindie-service/set_env.sh && source /usr/local/Ascend/cann/set_env.sh && /usr/local/Ascend/mindie/latest/mindie-service/bin/mindieservice_daemon 2>&1'
然后再针对性地写个启动脚本,方便运行
#!/bin/bash
container_name="Qwen3-VL-2B"
image_name="quay.io/ascend/vllm-ascend:v0.18.0rc1-310p-openeuler"
model_path="/data/Qwen3-VL-2B"
model_local_dir="${model_path}/Qwen3-VL-2B-Instruct"
HOST_PORT=8002
echo "正在启动脚本>>>>>>>>"
echo "删除旧容器..."
docker stop $container_name 2>/dev/null
docker rm $container_name 2>/dev/null
echo ">>> 启动vLLM容器,使用端口 ${HOST_PORT}..."
docker run -itd \
--name $container_name \
--restart always \
--ipc=host \
--net=host \
--privileged=true \
--shm-size=1g \
-p ${HOST_PORT}:${HOST_PORT} \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /usr/local/Ascend/toolbox:/usr/local/Ascend/toolbox:ro \
-v /var/log/npu/:/usr/slog \
-v $model_path:$model_path \
$image_name \cend/toolbox:/usr/local/Ascend/toolbox:ro \
-v /var/log/npu/:/usr/slog \
-v $model_path:$model_path \
$image_name \
bash -c "export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256 && \
vllm serve $model_local_dir \
--host 0.0.0.0 \
--port ${HOST_PORT} \
--served-model-name Qwen3-VL-2B \
--dtype float16 \
--tensor-parallel-size 1 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 256 \
--block-size 128 \
--trust-remote-code \
--enforce-eager"
echo "vLLM 服务启动完成。"
echo "访问地址:http://127.0.0.1:${HOST_PORT}/v1"
需要注意的是,这里需要加上参数–enforce-eager,强制关闭vLLM的图模式优化,强制使用Eager模式可以避免不兼容导致的报错,确保服务能先跑起来
5.功能验证和测试
虽然只是2B的模型,但感觉比同参数量的Qwen2.5强得不止一点半点

四、总结
Qwen3虽好,但是硬件对模型的支持还是有限,为了提供更稳定的服务,还是先回退到Qwen2.5VL 32B,后续进行一下边缘应用的配置好了

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)