
Deepseek v4发布,有哪些技术亮点?
我们先来看看之前几个版本V2用的是MoE加MLA,通俗来讲就是大模型不用每次激活全部参数,也能解决问题。V3的模型不只是跑分好看,调用更稳、更便宜。R1的重点转向推理,让模型可以先思考再回答。这次到了V4,这几条线合到一起了。上下文拉到百万,推理更强,Agent工具调用直接内置。成本相比V3价格略高,但是对比国外那几家,还是便宜。后面昇腾950真批量上来,价格可能还会往下走。
千呼万唤的DeepSeek V4来了,我用三个关键词来总结,分别是:百万上下文、MoE升级、Agent适配。
我们先来看看之前几个版本

V2用的是MoE加MLA,通俗来讲就是大模型不用每次激活全部参数,也能解决问题。V3的模型不只是跑分好看,调用更稳、更便宜。R1的重点转向推理,让模型可以先思考再回答。
这次到了V4,这几条线合到一起了。上下文拉到百万,推理更强,Agent工具调用直接内置。
成本相比V3价格略高,但是对比国外那几家,还是便宜。后面昇腾950真批量上来,价格可能还会往下走。
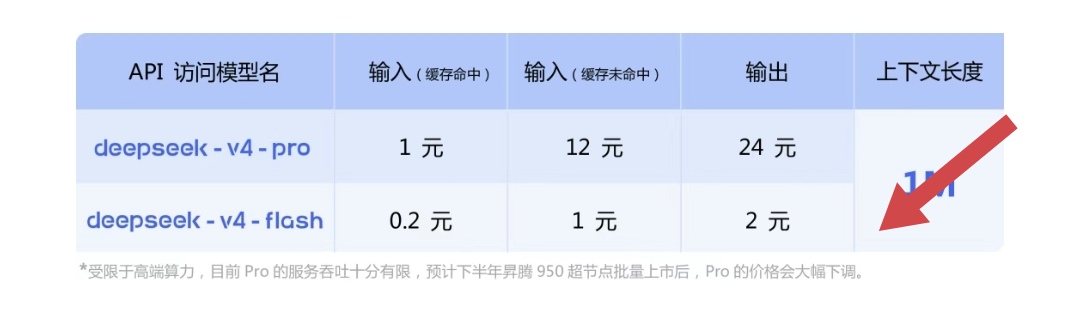
技术亮点一:一百万超长上下文
过去我们用大模型处理长资料,经常要分段、提取、再拼接。这个过程很麻烦,而且会丢信息。
比如你让模型读一整份招标文件,一百多页,模型读到第30页的时候,第3页说了什么已经忘了。你让它总结,它给你总结的是最后10页。长上下文解决的是能不能读完,且读完之后记住的问题。
DeepSeek V4把一百万上下文变成官方服务的默认能力,并且通过DSA稀疏注意力降低计算和内存成本。另外还有一个数字:V4的最大输出是384K tokens,大概二十多万字。不只是读得长,写得也长。以前让模型写个长报告,写到一半就断了,你得反复让它继续。
技术亮点二:MoE4.0架构升级
MoE可以这么理解:传统模型处理问题,是让公司全员开会;MoE是根据问题类型,只叫相关的人进会议室,其他人该干嘛干嘛。这样一来,模型总参数可以很大,但每次推理只激活其中一部分参数。能力上去了,成本不至于同步飙升。
V4升级到混合专家MoE4.0架构后,推理速度和准确率都有三成以上提升;同时V4-Pro作为专家模式处理复杂任务更强,V4-Flash则更轻量、更适合高频场景。
MoE 4.0解决的就一个问题:同样的活,花更少的钱。
技术亮点三:Agent调用能力增强
DeepSeek官方提到,V4已经和主流AI Agent工具做了集成,并且支持OpenAI和Anthropic的API调用,只需要改model参数就可以接入。
比如做PPT。普通聊天模型可以帮你写大纲、提炼文案、润色标题。但Agent接入之后,模型可以理解资料、拆分页面、调用工具、生成内容、调整结构,甚至与自动化工具结合,输出更接近交付物的结果。
再比如写代码,普通模型只能回答某一段代码怎么改;Agent工作流则可以读项目、找bug、改文件、跑测试、反复修正。
V4适配这些Agent工具瞄准的是开发者每天在用的工作流。顺便说一个细节,以前deepseek-chat和deepseek-reasoner是两个模型,你得分开调。这次V4把思考模式和普通模式合到一个模型里了,切换靠参数就行。开发者就可以少维护一套东西,省不少事。
和GPT、Claude、Gemini横向对比
和GPT比一下。GPT的生态是真的好,工具链成熟,产品体验也稳,这些东西短期追不上。但V4便宜,接入简单,中文处理也更好。调用量大、预算有限的话,V4更实际。
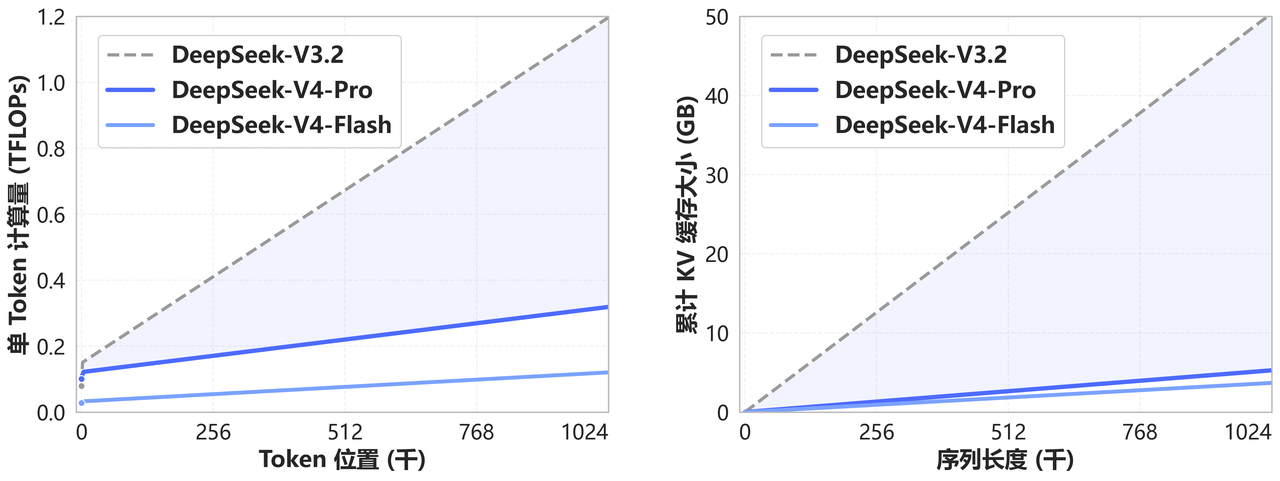
和Claude比。Claude写代码、写长文口碑一直很好,是很多开发者的首选。然而V4不是要变成另一个Claude,它面向的是那些用不起Claude的人。
成本更低,接口更开放,中文更强。这批用户的量比你想的大。官方测试V4-Pro在 Agentic、数学、代码这几项上,已经是开放模型里最强的一档,接近顶级闭源模型。
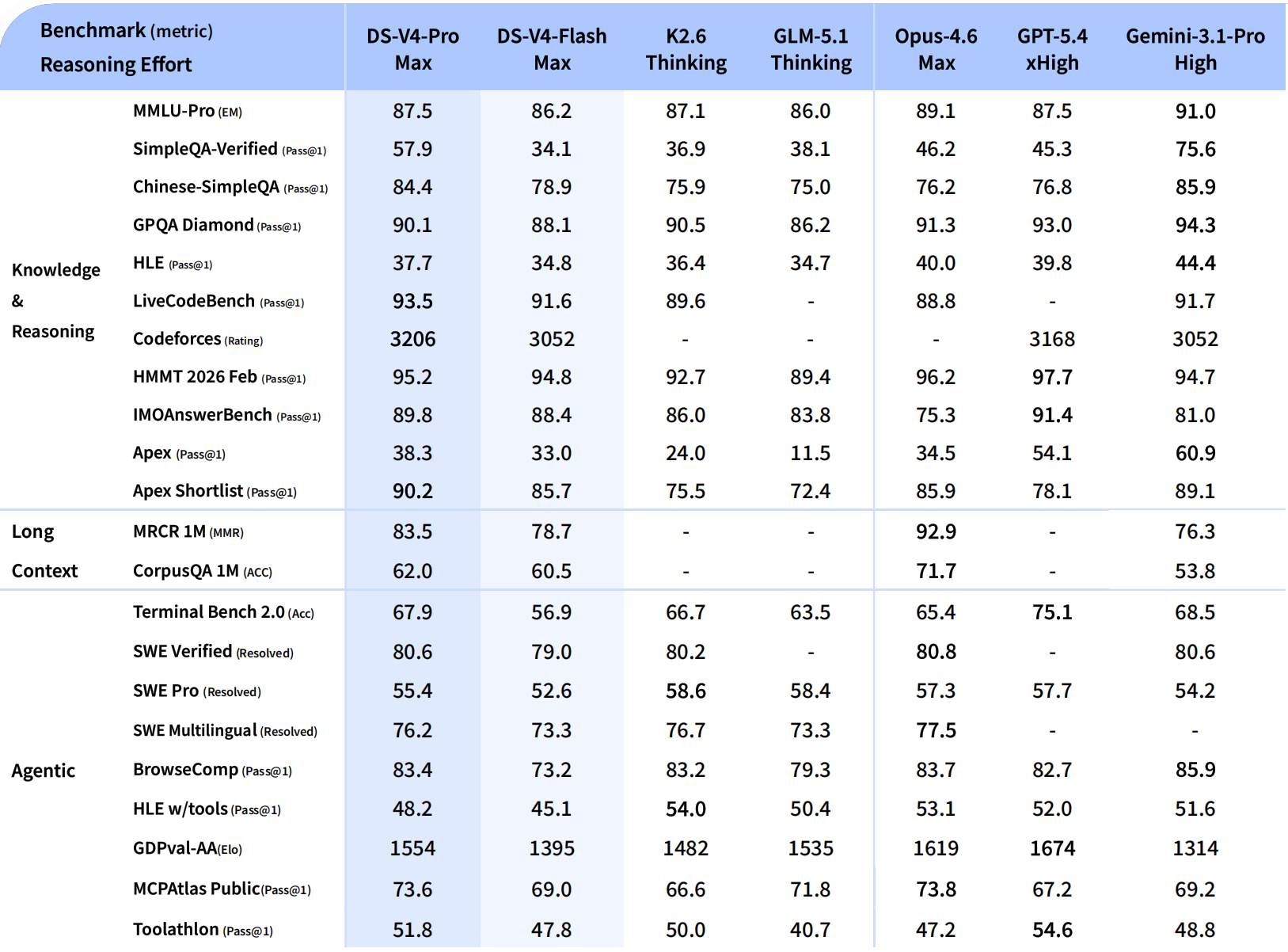
和Gemini比。Gemini背靠Google,世界知识丰富,多模态和检索能力强,是个全能型选手。V4不跟它比全能,就三样:便宜,开放,上下文长。开发者接起来省事,够用就行。
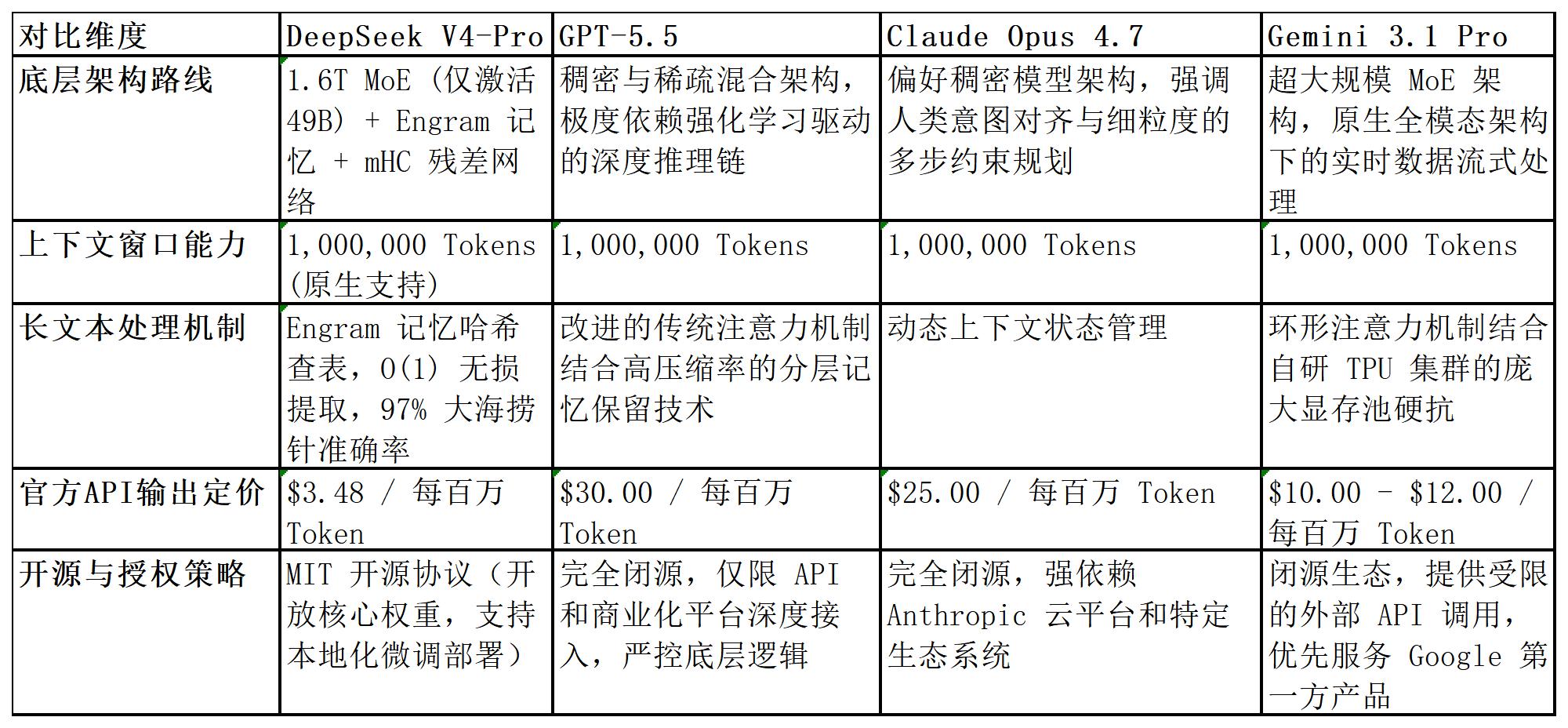
还有一个最根本的区别,上面三家全是闭源,只能通过API用。V4是MIT协议开源的,权重直接放出来了。你可以本地部署,可以微调。
看完GPT、Claude、Gemini和DeepSeekV4的对比,会发现一个非常清晰的趋势:所有头部模型都在往同一个方向走。更长上下文,更强工具调用,更复杂任务执行。
回到V4本身。它证明了一件事:模型会继续变强,调用成本也会继续降。后面真正值得看的,不是谁又发布了新模型,而是谁先把模型用到自己的工作里。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)