
AReaL x 昇腾,加速大模型全异步RL训练创新
ReaL 是一个面向算法设计者的强化学习框架,核心目标是:将 RL 框架从完整应用演进为高性能、可复用的后端依赖。AReaL 通过 极简 API + 可扩展插件机制,把算法开发者从复杂的系统工程中解放出来,使其专注于 RL 算法、Reward 设计与Agent 行为建模,而不是分布式、通信、容错等底层细节。项目地址:https://github.com/inclusionAI/AReaL。
ReaL 是一个面向算法设计者的强化学习框架,核心目标是:将 RL 框架从完整应用演进为高性能、可复用的后端依赖。
AReaL 通过 极简 API + 可扩展插件机制,把算法开发者从复杂的系统工程中解放出来,使其专注于 RL 算法、Reward 设计与Agent 行为建模,而不是分布式、通信、容错等底层细节。
项目地址:https://github.com/inclusionAI/AReaL
AReaL的核心优势
AReaL相较于传统RL训练系统存在三大核心优势:
全异步 RL 训练系统:传统RL训练系统将生成(rollout)和训练(train)强绑定,生成序列长度的分布会显著影响算力的利用率。AReaL采用全异步RL训练系统,生成和训练完全解耦,即便序列长度差异较大算力也可以得到充分利用,提升RL训练效率。
Single Controller架构:传统RL训练系统采用SPMD(Single Program,Multiple Data)架构,多个进程运行相同代码,做不到资源的灵活控制和异常状况的快速恢复。AReaL采用Single Controller架构,将调度和计算分为两个完全独立的平面,互不干扰,可以轻松地添加修改RL训练资源,也可以将异常进程任务分配给其他进程,大大提高系统可靠性。
解耦式 Agentic RL:AI智能体的构建常常会因为RL训练和Agent编排框架的高度耦合导致代码复用性差,难以迭代更新。AReaL采用解耦式的Agentic RL,围绕Agent完全独立运行和RL训练作为外部观察者两大原则设计,实现了Agent逻辑和RL训练的完全分离,极大提升了智能体的开发效率和系统可维护性。
同时,AReaL在昇腾平台通过提供Docker镜像,软件版本矩阵以及可复现的运行教程,已经具备了稳定、便捷的开箱能力,并会持续地维护、优化AReaL框架在昇腾平台的使用体验。在超大规模RL训练中,AReaL也在昇腾平台完成了万亿参数MoE模型的真实RL后训练业务验证,保证商业用户的大规模部署需求。
AReaL在昇腾上的关键适配工作
为了顺利让AReal框架在昇腾上运行起来,昇腾团队分析并做了一系列的适配工作,包括:vLLM推理引擎支持、训练阶段适配、权重Resharding功能验证。
vLLM推理引擎支持
AReaL中的推理后端使用的是服务化的推理引擎。适配前,AReaL 只支持 SGLang推理引擎。而vLLM推理引擎以其稳定性和广泛的生态系统成为众多用户的选择,需要在AReaL框架中适配vLLM推理引擎作为推理后端。强化学习训练过程需要做权重更新,SGLang中的 update_weights 接口支持该功能,而 vLLM不支持,需要适配update_weights接口。因此,AreaL支持vLLM推理引擎分为2个部分:AReaL适配 vLLM 、vLLM新增支持update_weights权重更新功能。
对于AReaL 适配 vLLM部分,需要新增vLLM相关的类,继承AReaL中抽象出来的推理引擎接口,实现vLLM的相关模块和功能。
对于vLLM新增支持update_weights权重更新功能,起初在vLLM中直接修改添加的update_weights接口,这样依赖vLLM版本更新和其他变动,同时侵入式修改vLLM代码在设计上也不推荐。因此通过patch方式给vLLM新增接口,代码在AReaL仓库承载,使用方便也对vLLM版本无影响。
训练阶段适配
AReaL使用FSDP2作为训练后端,FSDP2在torch_npu上已经支持,首先需要torch升级到2.7.1以上版本。其次,得益于FSDP训练后端本身模型结构与并行策略解耦的轻量化设计,同时AReaL 框架的设计时就考虑了多种设备的支持,将设备部分抽象成了Platform类,用于抽象不同的设备类型。因此,训练部分适配NPU,只需要实现NPU对应的Platform类,在训练开始前根据当前使用的设备初始化对应的platform。适配过程中,系统显存占用较高,通过采集短序列场景下显存快照数据,分析显存异常点,发现显存峰值在logits前反向位置,分析代码并进行优化,将sp_group上的allgather操作从logits位置调整至logprobs位置,实现整体显存占用下降50%。
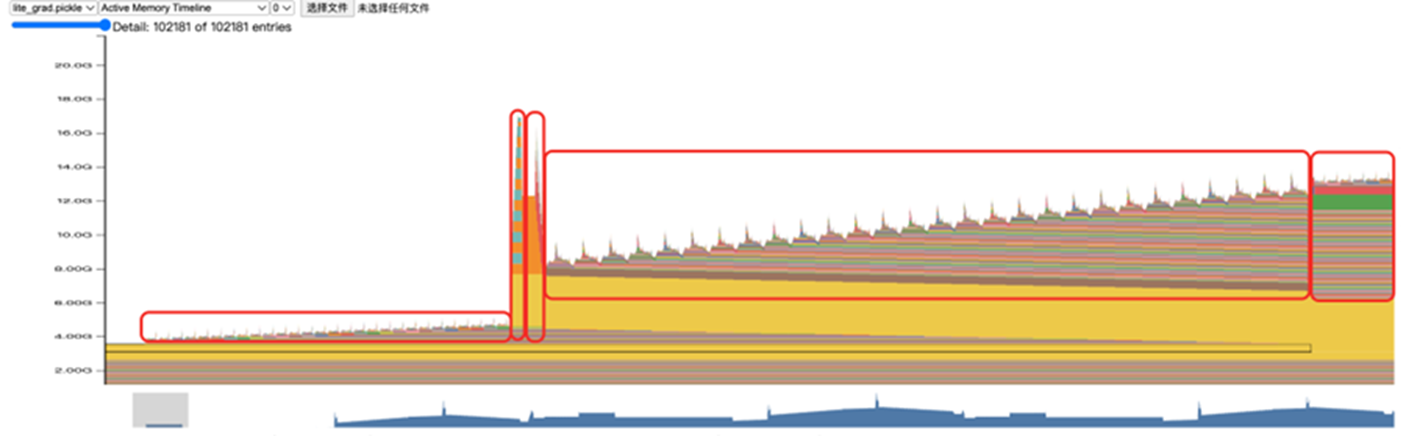
权重 resharding 特性支持
权重 Resharding 是强化学习训练中连接“训练更新”与“推理生成”的桥梁,它通过快速、无缝地重组权重格式,实现模型的热切换,避免训练与推理间的等待瓶颈,从而大幅提升RL迭代效率。AReaL中的权重resharding分为disk和xccl两种方式。disk指的是训练端把更新后的权重转为huggingface格式并离线保存,然后推理端再加载这份huggingface权重。xccl方式指训练端把更新后的权重通过设备通信的方式传输给推理端。
若使用disk方式,NPU 和 GPU上是没有区别的,缺点是对小模型友好,对于参数量大的模型需要占用大量磁盘空间且读写磁盘或共享存储花费大量时间,训练性能低下。而AReaL在使用xccl方式进行权重resharding时,会重新构建一个以训练0卡为rank0,推理卡顺延为后续rank的特殊通信域,在这个通信域上调用hccl的broadcast通信算子,将训练0卡作为广播源,把权重参数broadcast到推理卡。这种建立通信域的方式在NPU上较为少见,昇腾通过支持broadcast通信算子,适配xccl_update_weights功能,完成权重Resharding特性的支持。
如何在 Ascend NPU 上使用 AReaL?
Step 1:使用官方 NPU Docker 镜像
|
1 2 |
|
以上地址为 Atlas A3系列产品 镜像,Atlas A2系列产品用户请将镜像地址中替换为 v0.5.0-a2。
镜像内已包含:Ascend CANN 兼容环境、torch-npu / vLLM-Ascend 适配AReaL 昇腾平台运行依赖。
Step 2:启动容器(单机 /多机一致),按照设备调整--device配置
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
多节点场景只需保证 共享存储挂载一致。
Step 3:进入容器并拉取 AReaL NPU 分支安装
|
1 2 3 4 5 |
|
Step 4(可选):启动 Ray 集群(多节点)
|
1 2 3 4 |
|
AReaL 会自动感知集群资源并分配 Worker。
Step 5:运行 NPU 示例
训练脚本:
|
1 |
|
配置文件:
|
1 |
|
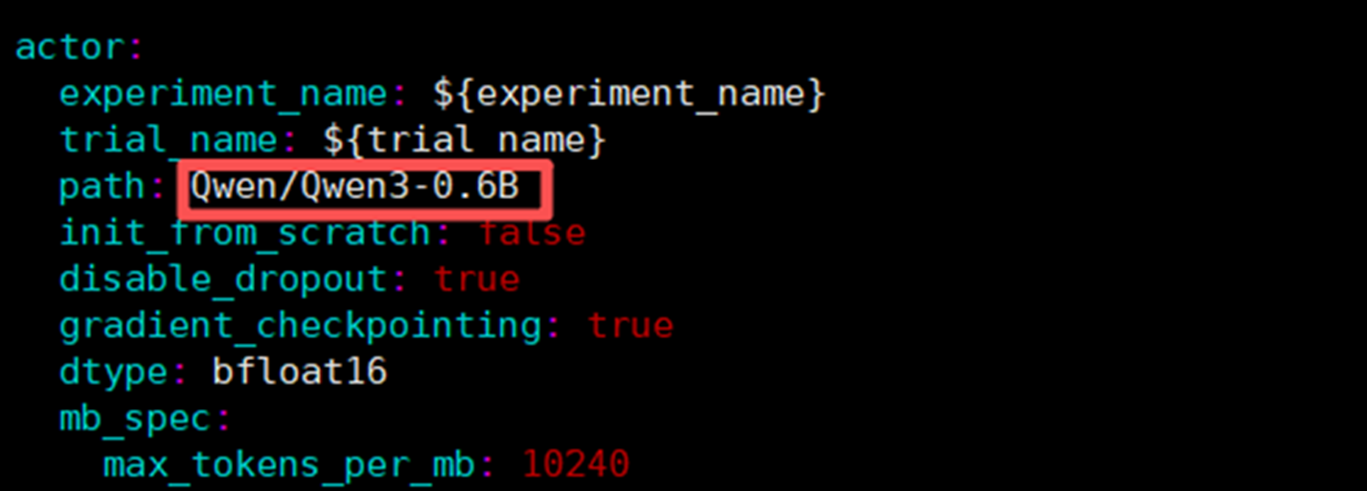
修改配置文件gsm8k_grpo_npu.yaml将模型配置为Qwen3-0.6B模型:
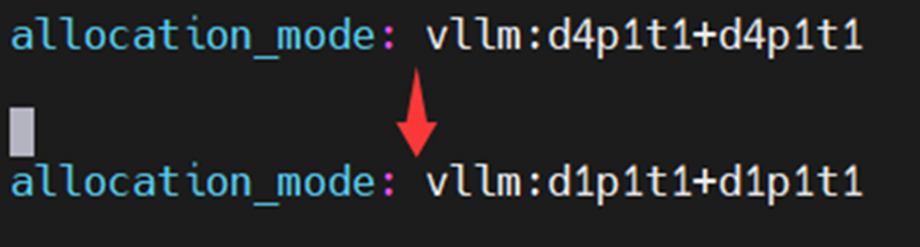
修改配置文件gsm8k_grpo_npu.yaml调整训推的卡资源分配以及并行方式,默认为4卡推理+4卡训练,都使用DP并行,下面给出调整为单卡推理+单卡训练的配置调整方式:
执行以下命令,无需修改核心算法逻辑,即可在 NPU 上跑通 RL 训练:
|
1 2 |
|
当图中信息循环显示时RL训练便在正常运行了:

训练完成显示如下:

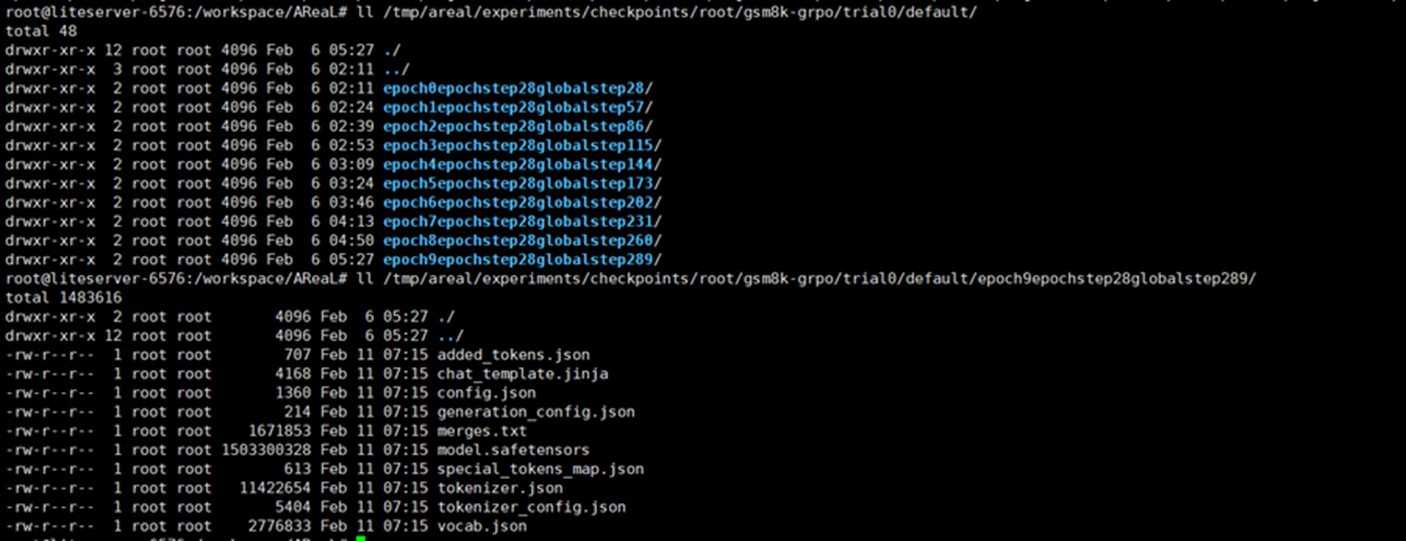
训练结束后新的模型文件默认在/tmp/areal/experiments/下,可通过gsm8k_grpo_npu.yaml配置文件fileroot参数调整文件路径:

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)