
3月19日直播丨加速开发,释放生产力的必备利器!
CATLASS模板库已推出支持此流水的优化样例。TLA 作为 CATLASS 对Tensor的抽象,封装了张量的布局、坐标、位置和存储细节,让开发者能够以更统一的方式描述 GM、L1、L0、UB 等不同层级上的 Tensor 视图。面对Ascend 950PR/DT的重磅升级,CANN 以深度适配硬件新特性为核心,全新升级 Cube 模板库、Vector 模板库、算子直调工程、仿真工具四大算子开发
AI 大模型训练与推理、推荐、多模态等应用的爆发式发展,让新一代 AI 芯片的算力突破成为行业刚需,而要充分释放这些芯片的硬件潜能,算子开发效率则成为其中关键的一环。
面对Ascend 950PR/DT的重磅升级,CANN 以深度适配硬件新特性为核心,全新升级 Cube 模板库、Vector 模板库、算子直调工程、仿真工具四大算子开发利器,从算子开发、调试、部署全链路实现开发提效、生产力释放,让开发者低门槛驾驭新一代芯片的极致算力。
一、Cube 模板库CATLASS:适配张量算力新特性,让矩阵计算算子开发更高效
针对传统算子参考样例,CATLASS以 Device→Kernel→Block→Tile 清晰分层架构,让开发者无需深入理解芯片底层指令配置、同步匹配逻辑,即可快速开发适配MatMul、卷积以及大模型融合算子。
针对 Ascend 950 引入的MXFP4/MXFP8 等低精度格式支持、张量-向量协同计算新通路、搬运指令增强等新特性,CATLASS模板库完成全新升级。同时为了提升开发者编程易用性,CATLASS还同步扩展TLA接口能力、新增了EVG等新特性。
-
指令新特性增强
Ascend 950推出的Fixpipe指令新搬运模式将 Cube 核 L0C 中的单份数据拆分为两路,并行写入两个 Vector 核各自的 UB;同时每块 L0C/UB 支持独立开启 Double Buffer(DB)机制,在 DB 模式下,UB 可实现数据读写的流水线重叠,在向 GM 传输数据的同时,持续接收来自 L0C 的数据,有效提升数据搬运效率。CATLASS模板库已推出支持此流水的优化样例。
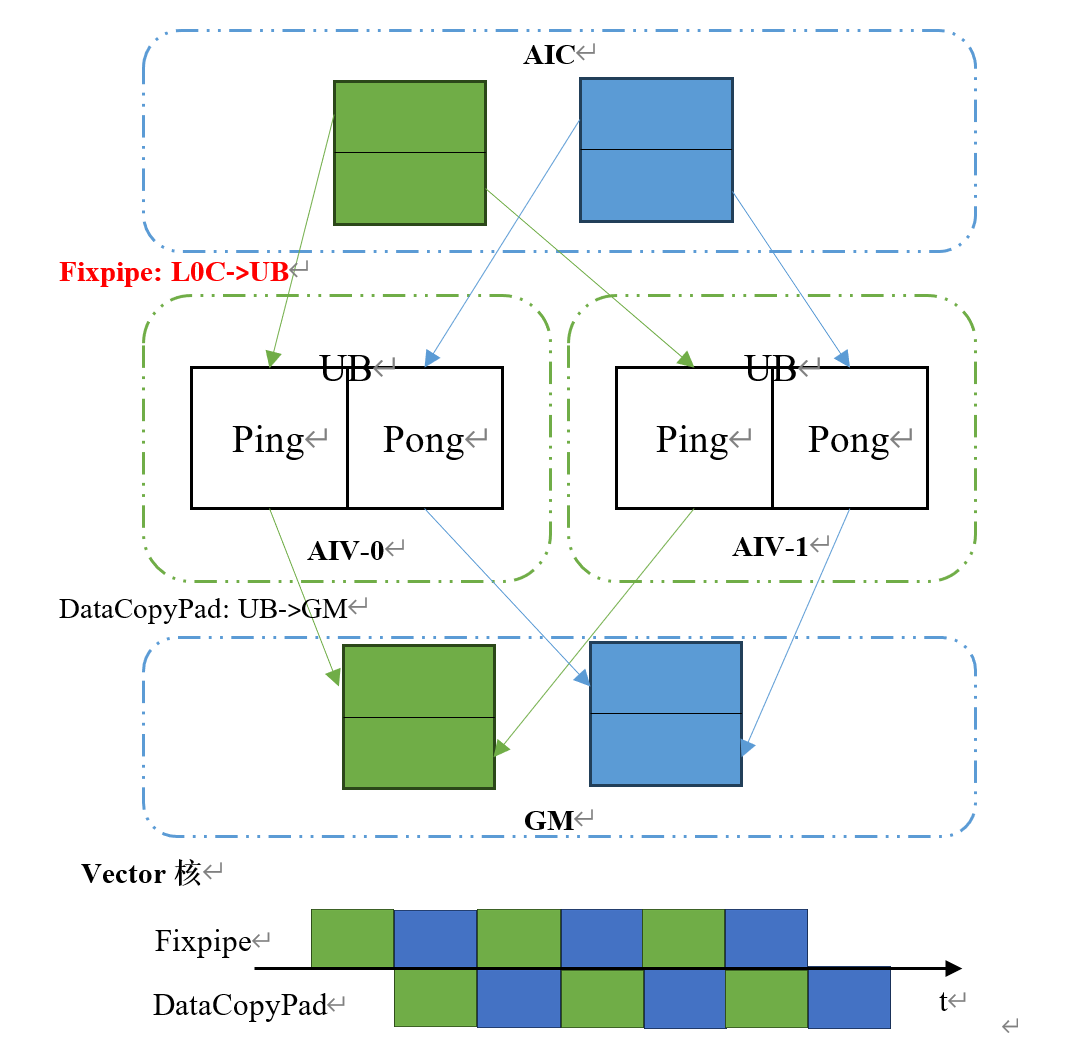
-
新增低比特数据类型
Ascend 950芯片还支持了包含缩放功能的矩阵乘,公式如下:
C = (ScaleA ⊗ A) ∗ (ScaleB ⊗ B) + C
ScaleA和ScaleB通过LoadData2DMX接口载入。
ScaleA的分形格式为小Z大Z ,shape为(16,2),数据类型为fp8_e8m0_t
ScaleB的分形格式为小N大N,shape为 (2,16),数据类型为fp8_e8m0_t
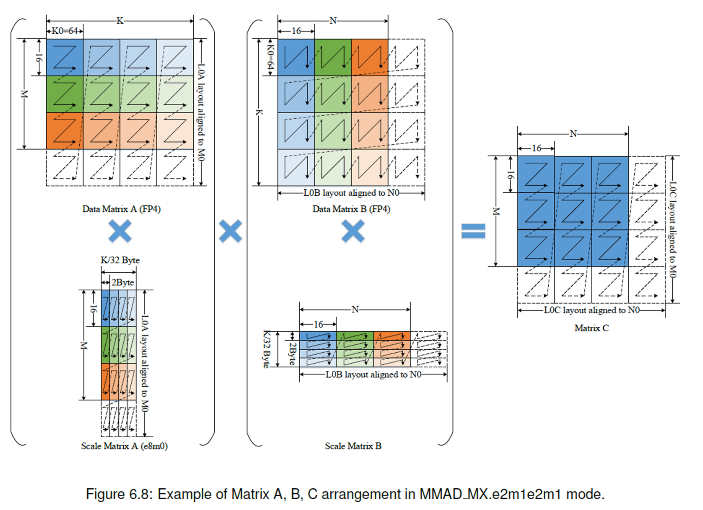
CATLASS模板库已完成MXFP4、MXFP8等新一代低精度数据类型深度适配,深化软硬协同优化,为 AI 计算构筑更高效、更经济的算力底座。
-
C-V新通路
Ascend 950新增 L0C→UB 、UB→L1专用数据通路,打通了 Cube 核与 Vector 核间的数据传输通道,使 Cube 核可直接将 L0C 内的数据高效分发至对应 Vector 核的 UB 中(同时也支持UB上的数据直接搬运至L1 Buffer上),无需再经由 GM 中转,避免了上一代芯片数据搬出GM再搬入UB的冗余操作,有效提升算子整体性能。 CATLASS模板库已深度适配以上优化新通路,有效提升融合算子的搬运效率。
-
扩展TLA(Tensor Layout Abstraction)接口
TLA 作为 CATLASS 对Tensor的抽象,封装了张量的布局、坐标、位置和存储细节,让开发者能够以更统一的方式描述 GM、L1、L0、UB 等不同层级上的 Tensor 视图。本次新增的 MakeTensor、MakeTensorLike、GetTile、TileView 等接口,进一步强化了Tensor的语义表达和Tile切分尾块边界处理的逻辑。
-
支持EVG(Epilouge Visitor Graph)的声明式Epilogue开发方式
在高性能 GEMM 场景中,Epilogue 往往承担着加法、类型转换、广播、规约、激活等一系列后处理逻辑,也是影响性能和开发复杂度的重要部分。本次更新CATLASS支持了EVG的声明式开发方式,通过将这些操作抽象为可组合的图节点,支持开发者像写表达式一样描述后处理流程,而无需手工处理底层的数据搬运、UB 空间申请、事件同步和流水编排。EVG 提供 TreeVisitor 和 TopologicalVisitor 两类结构,可分别适配树形表达和 DAG 拓扑表达场景。开发者可以基于EVG更简便的实现复杂后处理逻辑,同时更方便复用已有节点和计算图结构,在降低开发复杂度的同时,尽可能保持接近手工优化的性能表现。从“手写后处理流程”到“声明式构建融合图”,EVG 正在帮助 CATLASS 把高性能算子开发带入一个更高效、更工程化的新阶段。
二、Vector 模板库ATVOSS:算子开发更简洁,性能再提升
CANN ATVOSS 向量算子模板库迎来能力升级,在原有高效开发框架基础上,全面优化易用性与运行性能,为 Ascend C 向量算子开发带来更高效、更便捷的全新体验。
本次升级中,CANN ATVOSS 对数学表达式编写进行深度简化,开发者无需复杂冗余的代码逻辑,即可以更简洁直观的方式完成数学逻辑表达,大幅降低代码编写成本,提升开发效率。同时,框架实现 buffer 自动分配能力,免去开发者手动配置的繁琐工作,让算子开发流程更加轻量化。
在性能优化层面,ATVOSS 通过 bufferid 静态分配机制,实现资源调度的精准高效,配合冗余 cast 消除技术,进一步减少计算过程中的无效开销,充分挖掘昇腾硬件 Vector Unit 并行计算潜力,让算子执行效率与运行稳定性同步提升。
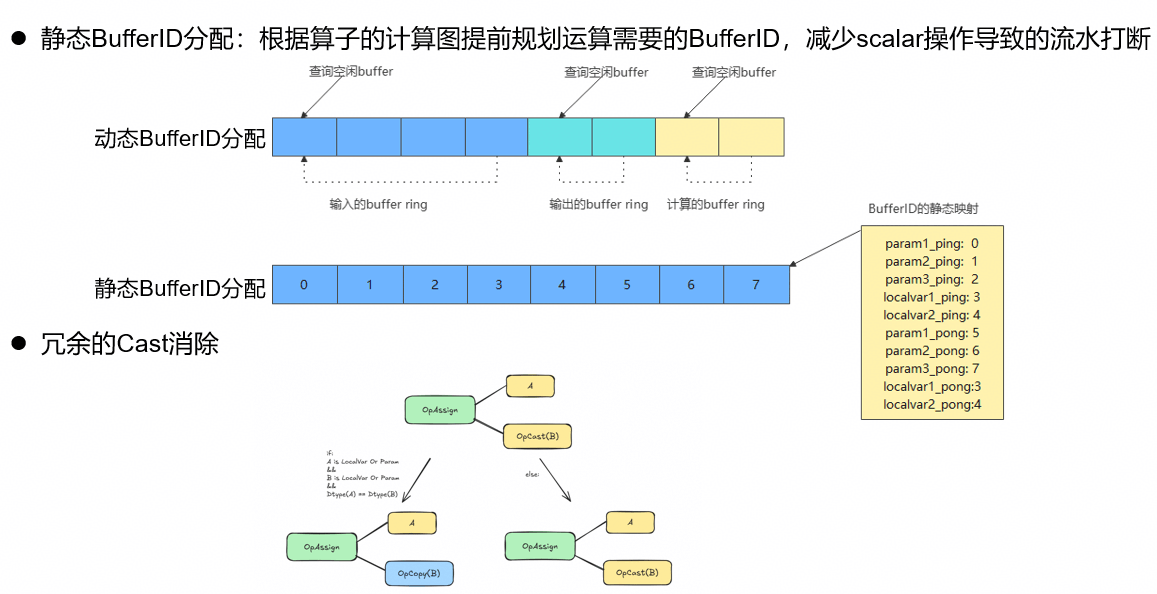
基于 C++ 模板元编程实现零开销逻辑抽象,CANN ATVOSS 持续屏蔽底层硬件适配、内存管理等复杂细节,支持向量类融合算子灵活组合与扩展,搭配流水线调度、双缓冲等优化机制,兼顾开发便捷性与计算高性能。
从开发极简到高性能,CANN ATVOSS 持续迭代升级,为 AI 推理、视觉计算、科学计算、多媒体处理等多场景应用提供强大支撑,助力开发者高效完成算子开发与迁移,全面加速昇腾平台 AI 应用创新落地。
三、算子直调工程:打通新特性适配最后一公里,算子调用部署零门槛
在传统的异构编程中,由于 CPU 和 NPU 拥有独立的内存空间和指令集,调用NPU核函数通常需要极长的准备:初始化上下文、手动管理队列、显式绑定内核镜像。
<<< >>> 的出现,本质上是编译器在 C++ 语法层面上开的一个“后门”。它将极其复杂的设备端初始化、参数压栈和调度逻辑,浓缩成了一个优雅的符号。对于开发者而言,它让“调用核函数”变得像“调用普通函数”一样自然。
在<<< >>>之后的括号里,开发者可以自由传递 C++ 任意类型的模板、结构体、指针或基本类型。
-
泛型编程:你可以直接通过kernel<T><<<numBlocks>>>(params)传递任意 C++ 模板。无论是自定义的结构体、复杂的指针组合,还是各种数值类型,编译器都会在编译阶段进行严格的类型检查
-
告别原始 API:如果没有这三个尖括号,你可能需要面对 aclrtLaunchKernel底层 API,处理那一堆令人头大的 void** 指针数组和复杂的内存偏移。
-
混合编译:支持Host侧代码和Device侧代码混写在一个编译单元,无需手动隔离Host侧文件和Device侧文件。
四、CANNSIM 重磅适配 Ascend 950:
算子开发调试效率全新升级CANNSIM 正式完成对 Ascend 950 的深度适配,为Ascend 950 硬件平台的算子开发、调试与性能优化打造全流程仿真利器。无需依赖物理硬件,即可完成 Ascend 950 平台算子的开发与验证,全面降低开发门槛,加速创新迭代。
本次适配聚焦精准仿真与高效调优两大核心需求,具体能力包括:
-
精度仿真:输出 bit 级精度结果,协助用户完成算子的精度验证。
-
性能仿真:输出 指令流水图,协助用户定位算子性能瓶颈问题。
CANNSIM 为 Ascend 950 算子开发提供全链路支撑,让开发者摆脱硬件束缚,高效打造高性能算子。
五、结语
从算子快速开发到精准调优,再到一键部署,CANN 四大核心工具形成适配Ascend 950的全链路开发流程,每一处升级都紧扣硬件新特性、直击开发者痛点:让开发者更好地去适应新架构,轻松适配Ascend 950硬件新能力;让算子开发从 “从零手写” 变为 “模板复用”,调试验证从 “上板试错” 变为 “仿真预判”,部署集成从 “复杂适配” 变为 “一键直达”。

B站直播预约:https://www.bilibili.com/opus/1181116410146848771?spm_id_from=333.1387.0.0

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 5
5 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)