
大模型表格识别能力实测
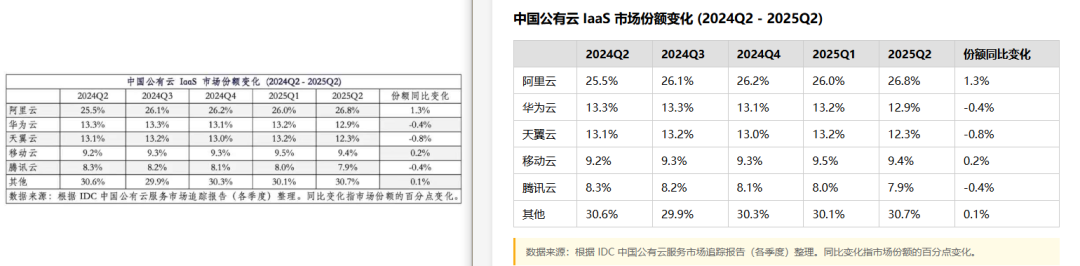
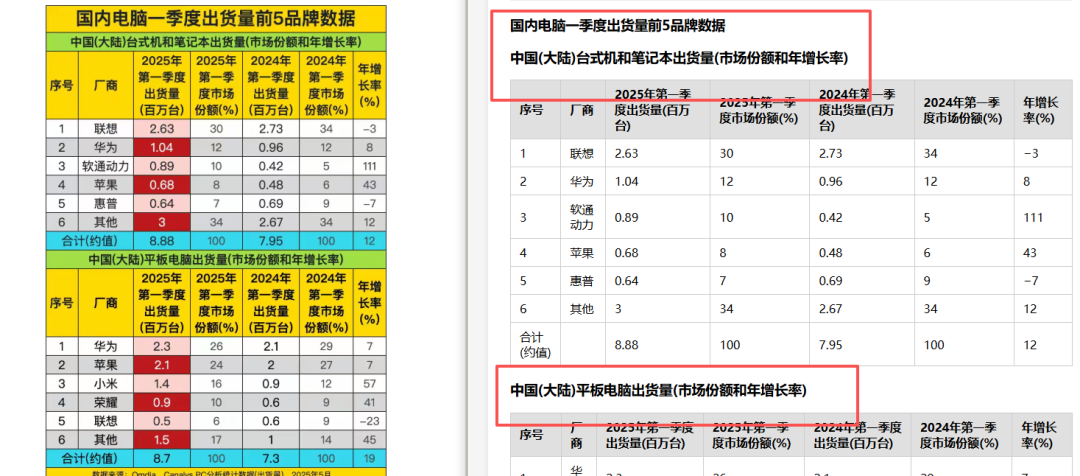
在「不同年代使用最多的10个名字」表中,问题更为严重:原表「2010-2019年」列下有「男」「女」两个子列,模型直接**将单元格内容「男」「女」错误地整合到了表头行中**,导致整列数据结构严重错乱,行列对应关系全面崩塌。对于表格识别这类以「感知精度」为核心的任务,更多的推理步骤并不总能带来更好的结果。在华为昇腾芯片产能表中,原表最后一列的列名是具体的新闻描述内容,但模型自作主张地将其替换为「相关
表格识别,是大模型多模态能力中具有「实用价值」的一环。
无论是政府统计年报、企业财务报表,还是新闻资讯中的数据看板,能否准确地从一张图片中还原出结构完整、数据无误的表格,决定了大模型在真实办公场景中的可用性。
我们从真实业务场景中积累了一批「大模型处理不好」的表格图片——涵盖学术政务型、彩色看板型、资讯长表型、简约列表型等多种类型,用这批数据对近期新发布的大模型进行了严格评测:只要表格结构或内容与原图不一致,即判定为错误。
─── RANKING ───
* 评测标准:表格结构与内容须与原图完全一致,任一不符即判错。
─── KEY FINDINGS ───
核心发现
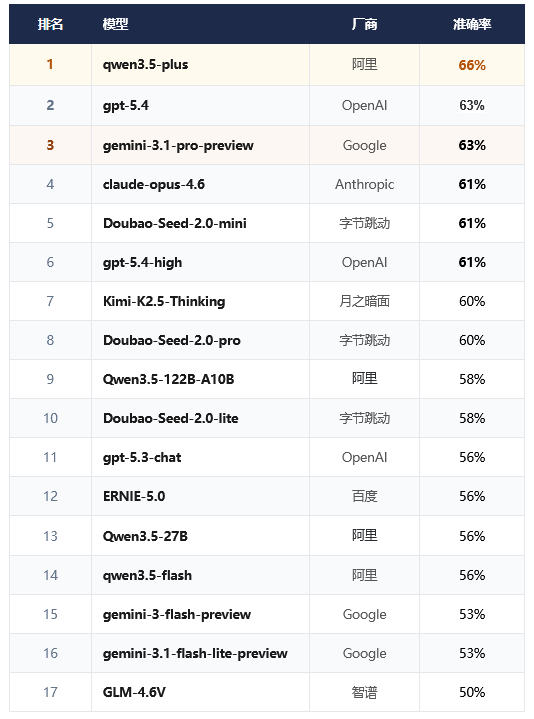
- 整体水平:及格线都难过
最高准确率仅66%,意味着即使是表现最好的模型,仍有近三分之一的表格无法正确还原。大部分模型集中在 56%~63% 区间,表格识别仍是多模态能力的「深水区」。
- qwen3.5-plus 断层领跑
qwen3.5-plus 以66%拿下第一,领先第二名近6个百分点,形成断层优势。gpt-5.4 和 gemini-3.1-pro-preview 并列第二(63%),三家头部厂商包揽前三。但同系列的 qwen3.5-flash(56%)和 Qwen3.5-27B(56%)表现平平。
- 思考模式未必更强
gpt-5.4(63%)反超其 High 思考模式(61%),Kimi-K2.5-Thinking(60%)也未能冲进前三。对于表格识别这类以「感知精度」为核心的任务,更多的推理步骤并不总能带来更好的结果。
- 字节 Doubao Seed 2.0系列:mini 反超 pro
Doubao-Seed-2.0-mini(61%)表现略优于 pro 版(60%)和 lite 版(58%),在表格识别场景下有着不错的性价比。
─── BAD CASES ───
数字好看不如案例说话。以下是评测中发现的典型失败模式——这些「翻车现场」揭示了大模型在表格识别中的真实短板(图片里的左边是原始表格图,右边是模型还原的结果)。
高频翻车:多层表头结构识别失败
这是本次评测中出现频率最高的错误类型,几乎所有模型都在此栽过跟头。
在「2025年前三季度GDP」排名表中,原表表头「2025↓前三季度」是一个完整的合并单元格,模型却将其拆分成上下两行——「2025」和「前三季度」各占一行,「2024前三季度」也遭到同样的拆分,整个表头层级关系完全走样。

在「不同年代使用最多的10个名字」表中,问题更为严重:原表「2010-2019年」列下有「男」「女」两个子列,模型直接**将单元格内容「男」「女」错误地整合到了表头行中**,导致整列数据结构严重错乱,行列对应关系全面崩塌。

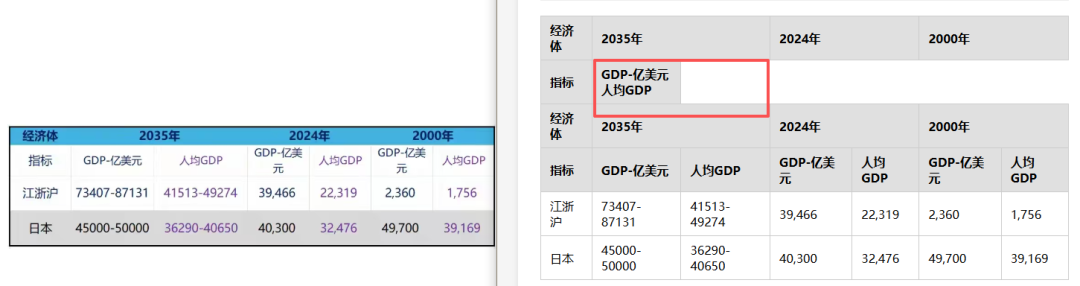
在「广州各区GDP」表中,多层嵌套表头同样出错——「增量/亿元」列的层级归属被打乱。在「江浙沪 vs 日本 GDP预测」表中,「2035年」下的「GDP-亿美元」和「人均GDP」两个子列头被混排到同一个单元格中。
可以说,多层表头是当前大模型表格识别的「阿喀琉斯之踵」——只要表头超过一层,准确率就断崖式下跌。
容易忽视:标题与元信息识别出错
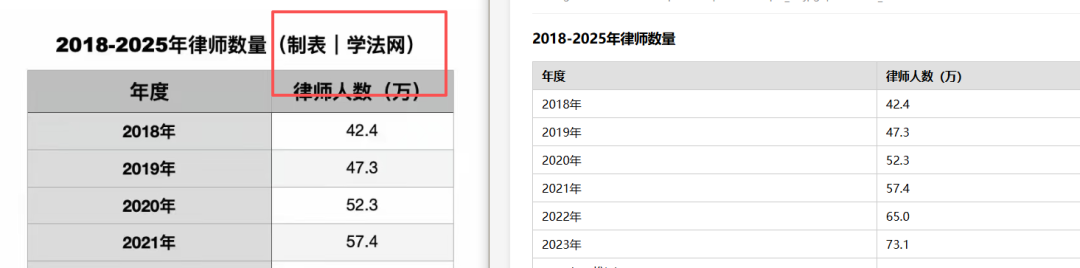
表格标题看似简单,实则暗藏陷阱。在「2018-2025年律师数量」表中,标题中附带的「(制表|学法网)」来源标注被模型直接丢弃,只保留了主标题文字。

在华为昇腾芯片产能表中,原表最后一列的列名是具体的新闻描述内容,但模型自作主张地将其替换为「相关说明」——这属于典型的「理解式改写」,模型没有忠实还原原文,而是用自己的理解替代了实际内容。
在「TOP6 通用大模型厂商中标排行榜(2025年第三季度)」表中,原图标题的「智能超参数根据公开招标信息整理统计」未被识别出来,模型自行去掉这部分文字内容。
视觉干扰:水印导致内容丢失

在CBA赛程表和广东购物中心排名表中,表格右下角区域叠加了半透明水印文字。面对这种视觉干扰,模型的表现非常脆弱——水印覆盖区域的表格内容直接丢失,输出为空白或破折号。
现实中,带水印的表格图片极为常见(截图来源标识、版权声明等),模型对这类「噪声」的鲁棒性严重不足。
细节魔鬼:数值识别错误

在「黄埔区2025年1-7月主要经济指标」表中,固定资产投资的同比增长率原值为 -4.2,但模型输出为 -1.2——数字本身就识别错了。这类错误最为隐蔽:表格结构完全正确,乍一看没问题,但关键数据已经失真。
对于金融、统计等对数据精度要求极高的场景,一个数字的偏差就可能导致决策失误。这也提醒我们:表格识别不能只看「结构对不对」,还必须逐字核对数值的准确性。
集体翻车:首行变标题、末行变附注
这是本次评测中一个极为有趣的发现:所有模型在特定类型的表格上犯了完全一样的错误,举几个例子: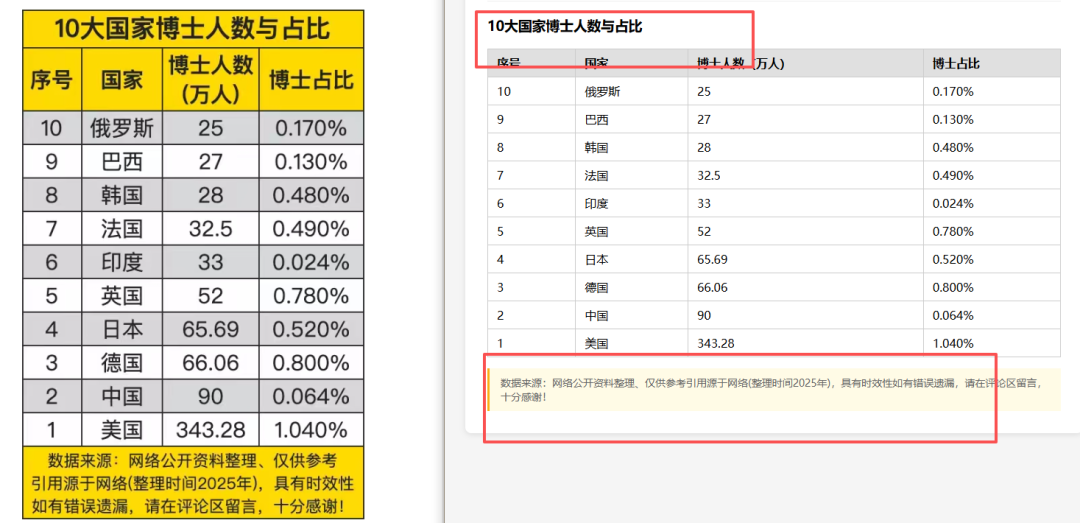
例如,在「10大国家博士人数与占比」表中,原图的表格结构非常清晰,但所有模型都将第一行从表格主体中剥离出去,识别为独立的「表格标题」;同时将末行的数据来源声明识别为表格外的附注,而非表格的组成部分。
─── 评测方法 ───
✦ 关于本次评测
- 数据来源:全部表格图片来自真实业务场景,涵盖学术政务型(统计局报表、经济指标等)、彩色看板型(带底色/高亮的数据面板)、资讯长表型(新闻媒体中的多列数据表)、简约列表型(黑白简单排列)等类型。
- 评判标准:逐项核对表格结构(行列数、合并单元格、表头层级)与数据内容(数值、文字、符号),任何一项不一致即判定为错误。不评判排版美观度,只看「还原准确性」。
- 调用方式:全部通过 NoneLinear 模型超市统一调用,使用各模型默认参数,确保公平可复现。
─── NONELINEAR 模型超市 ───
本次评测的多模态大模型,全部通过 NoneLinear 模型超市(https://nonelinear.com/static/models.html)一站式完成调用 —— 一套代码、统一接口、零适配成本。
# QUICK START · 表格识别调用示例
## 一套代码,调用任意多模态模型
import base64``from openai import OpenAI
def file_to_base64(file_path):
with open(file_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
# 1. 设置 NoneLinear API 密钥与base url
API_KEY = "your-api-key"
BASE_URL = "https://api.nonelinear.com/v1"
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# 2. 准备图片数据
image_path = "sample_table.jpg" # 替换为您的待测试图片路径
base64_image = file_to_base64(image_path)
data_url = f"data:image/jpeg;base64,{base64_image}"
response = client.chat.completions.create(
model="gpt-5.4", # 只需更换这里的 ID,即可随意切换多款多模态大模型
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": data_url}},
{"type": "text", "text": "请识别图片中的表格内容,并以 HTML 格式输出。"}
],
}]
)
print(response.choices[0].message.content)
目前所有大模型评测文章在公众号:大模型评测及优化NoneLinear

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)