
CPU 并行编程系列(三)《鲲鹏 CPU 矩阵加速与特性介绍》
华为鲲鹏超智融合芯片创新性地将AI矩阵计算单元集成到CPU中,开创了HPC与AI融合新范式。该芯片具备众核架构、片上矩阵计算单元和高带宽内存三大特性,通过鲲鹏统一并行库(KPL)提供矩阵编程、并行开发等核心能力,优化了传统HPC和AI科学计算的性能表现。在WASP地形模拟和AlphaFold蛋白质预测等应用中,优化策略实现了3-10倍的性能提升,部分场景超越GPU表现。华为通过开源策略构建软件生态
目录
鲲鹏统一并行库(Kunpeng Unified Parallel Library)
案例2:AlphaFold 蛋白质结构预测(AI for Science)
本次由来自华为公司的讲师讲解华为鲲鹏超智融合芯片,通过 CPU 集成矩阵计算单元,开启 HPC 与 AI 融合的新时代。
超智融合软件的背景与挑战
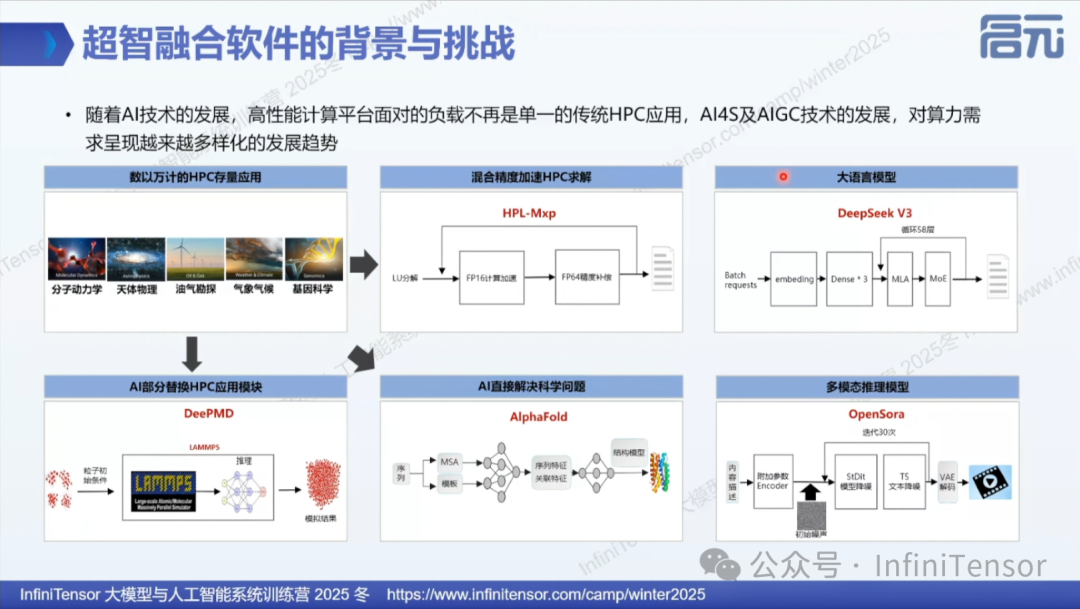
分子动力学、天体物理、蛋白质结构预测等科学计算任务既需要高精度仿真,又需要 AI 模型的智能辅助。然而,现有硬件架构往往难以同时满足 HPC 的高精度计算需求和 AI 的大规模矩阵运算需求。
华为鲲鹏最新推出的超智融合架构芯片,通过在 CPU 中集成专用矩阵计算单元,实现了 HPC 与 AI 负载的统一支撑,为科学计算提供了全新的硬件解决方案。
超智融合:HPC 与 AI 的协同发展
科学计算的新需求
-
• 传统 HPC 应用:分子动力学、天体物理、油气勘探、气象预报等仍需高精度仿真
-
• AI for Science:AlphaFold蛋白质结构预测、DMPD分子势能面计算等AI应用
-
• 混合负载:同一超算环境中同时运行HPC和AI任务
行业趋势
-
• GPU集群普及:通过GPU加速HPC和AI负载
-
• CPU技术演进:CPU厂商纷纷引入GPU技术优势
-
• 高带宽内存(HBM)
-
• 张量计算单元(Tensor Core)
-
-
• 架构融合:芯片厂商提供多功能芯片,满足多样化负载需求
鲲鹏超智融合芯片:三大硬件特性
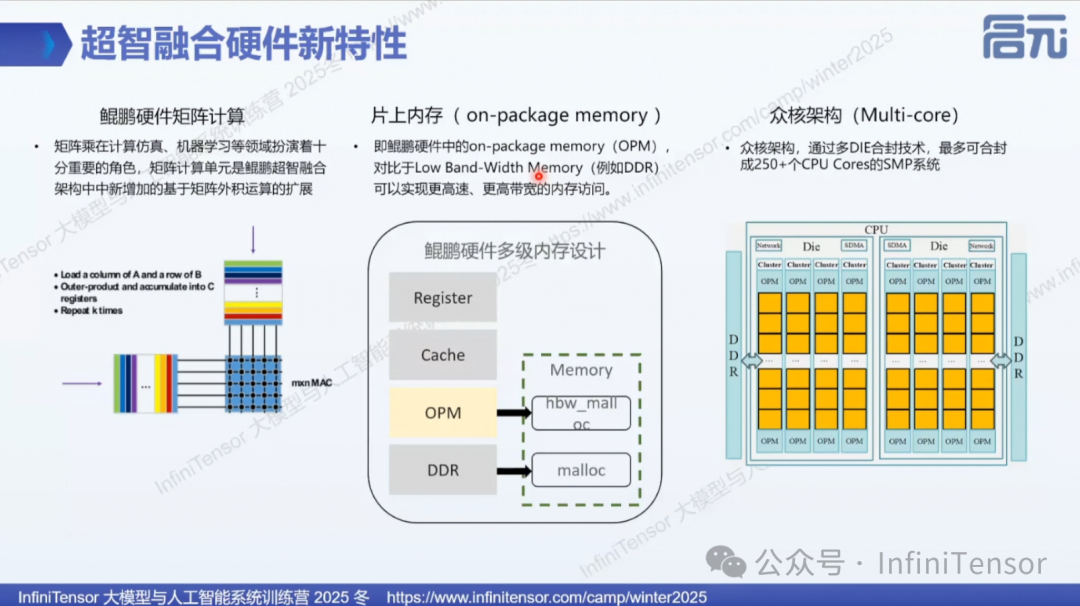
1. 众核架构
-
• 核心技术:多芯片合封技术
-
• 核心规模:采用超大规模集成架构,单芯片集成极高密度的计算核心
-
• 优势:提供强大的并行计算能力,适合大规模科学计算
2. 片上矩阵计算单元
-
• 创新设计:在 CPU 内部引入矩阵计算加速能力
-
• 类比理解:相当于 CPU 内置的"张量核心"
-
• 硬件特性:
-
• 二维矩阵寄存器(区别于传统向量寄存器)
-
• 专为矩阵存储和计算优化
-
• 在特定规模和精度约束下,部分矩阵算子可获得显著性能提升
-
3. 片上高带宽内存(OPM)
-
• 技术名称:On Package Memory(OPM)
-
• 性能优势:
-
• 相比传统 DDR 内存,提供更高传输速率
-
• 更直接的内存访问路径
-
-
• 应用场景:满足矩阵计算单元的高带宽数据需求
众核架构的编程挑战
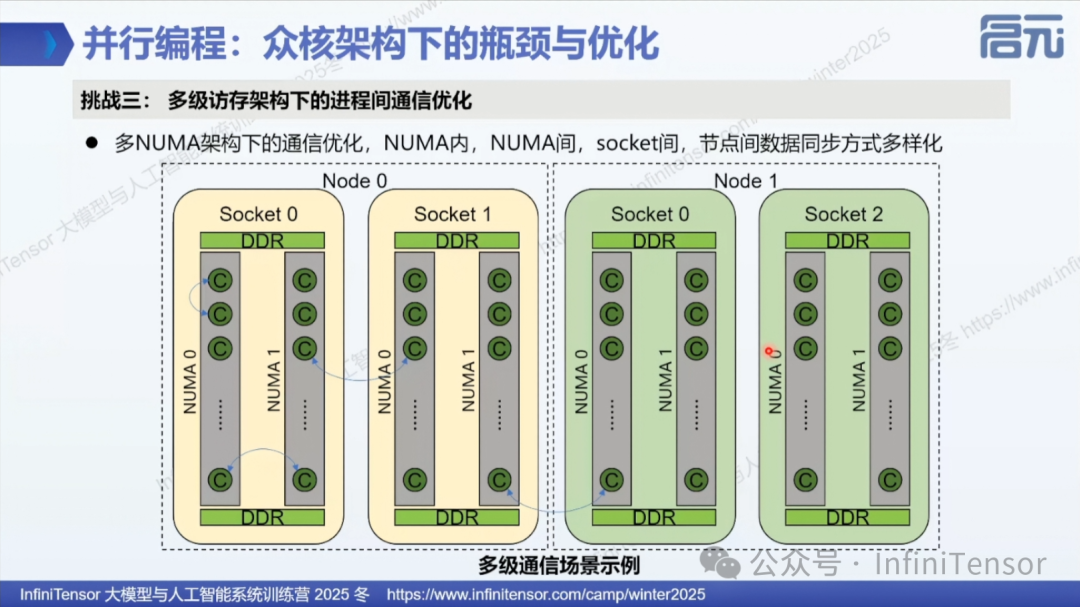
1. 并行编程挑战
-
• 线程池开销:众核架构下线程创建和初始化开销被放大
-
• Barrier效应:隐式屏障导致所有线程等待最慢线程
-
• 木桶效应:并行核心越多,最慢线程拖累整体性能的概率越大
2. 计算逻辑表达
-
• AI场景需求:计算图方式更适合表达 AI 计算流程
-
• 接口要求:需要简明接口来表达计算流程和调度硬件资源
3. 负载均衡问题
-
• 核心问题:工作切分不均导致部分核心闲置
-
• 影响:硬件资源利用率低,性能损失严重
4. 通信优化挑战
-
• 内存模型复杂:跨 NUMA、跨 Socket、跨节点访问
-
• 性能损耗:层级越高,数据传输性能损耗越大
-
• 优化目标:减少数据移动,降低跨层级通信次数
鲲鹏统一并行库(Kunpeng Unified Parallel Library)
设计理念
-
• 统一 API:兼容 OpenMP、OpenACC 等现有编程模型
-
• 底层优化:在并行抽象和运行时层面,提供类似于主流异构计算平台的统一编程接口
-
• 生态适配:支持 MPI、PyTorch、Cocos 等主流框架
核心能力
1. 矩阵编程能力
-
• 接口设计:类似 CUDA 的 MMA(Matrix Multiply Accumulate)接口
- • 使用方式:
// 创建矩阵对象 auto tensor = kpl::Tensor(...); // 矩阵乘加计算 kpl::mma(tensor_a, tensor_b, tensor_c, tensor_d); // 写回结果 kpl::store(result, tensor_d);
2. 并行开发接口
-
• 编程模型:类 OpenMP 的并行循环接口
-
• 调度策略:
-
• 静态策略:静态决定线程和任务映射
-
• 动态策略:由调度器动态分配任务
-
-
• 数据切分:支持二维、三维数据切分
3. 图编程与多队列
-
• 静态图:描述复杂的 DAG 依赖关系
-
• 多队列:不同流间操作可并行执行
-
• 性能提升:典型优化效果可达 2-3 倍
4. OPM 内存管理
-
• 统一地址空间:OPM 和 DDR 共享同一地址空间
-
• 无数据搬运:避免 GPU 显存与内存间的数据拷贝问题
- • 接口设计:
// 申请OPM内存 void* opm_mem = kpl::malloc_opm(size); // 申请DDR内存 void* ddr_mem = kpl::malloc_ddr(size);
5. 异步数据拷贝
-
• 硬件支持:利用 SDMA(System DMA)硬件单元
-
• 优势:数据移动不占用 CPU 资源,实现计算与通信重叠
-
• 应用场景:OPM 与 DDR 间的高效数据传输
6. 共享内存通信优化
-
• 传统方案:发送进程→中间 buffer→接收进程(两次拷贝)
-
• 优化方案:发送进程↔共享内存↔接收进程(一次拷贝)
-
• 性能提升:BCAST、Alltoall、Allreduce 等接口性能成倍提升
框架生态适配
多框架支持
-
• MPI:在 HMPI 中新增 CUCUM MCA 组件
-
• OpenMP/OpenACC:通过编译器生成基于 KPL 的运行时库
-
• PyTorch:通过定制后端插件探索与 PyTorch 的适配,支持部分算子在 KPL 上运行
-
• Cocos:基于 Cocos Runtime 新增 KPL 并行后端
开源策略
-
• 组件开源:除 Cocos 外,其他框架适配组件均已开源
-
• 社区贡献:鼓励开发者基于 KPL 开发高性能算子
实际应用案例
案例1:WASP 地形原理应用(传统 HPC)
优化策略
-
1. 并行优化:将串行算子拆分为计算图,实现多计算流并行
-
2. 通信优化:基于共享内存实现 MPI Alltoall,性能提升 3-4 倍
-
3. 矩阵优化:利用MMA编程接口优化矩阵计算
优化效果
-
• 整体性能提升:3-5 倍
-
• 超越GPU性能:在特定场景下性能优于 GPU 实现
案例2:AlphaFold 蛋白质结构预测(AI for Science)
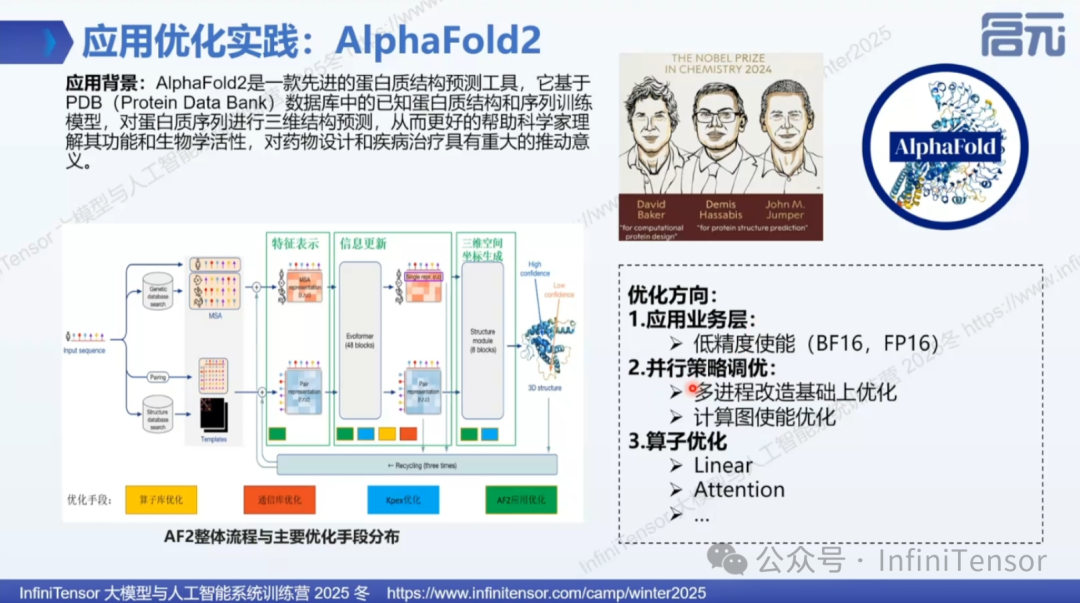
优化策略
-
1. 并行化:多进程并行化,权重分布到不同进程的共享内存
-
2. 通信优化:针对 Alltoall 操作的特殊需求,实现定制化算子
-
3. 算子融合:融合 Attention、Outer Product 等关键算子
优化效果
-
• 性能提升:约 10 倍(从 650 秒降至 65 秒)
-
• 对标GPU:性能与 GPU 持平,某些场景甚至超越
软件生态与工具链
HBCK 高性能计算套件
-
• 组件构成:
-
• KPL(鲲鹏统一并行库)
-
• Kunlun 数据库
-
• HMPI(Hyper MPI)
-
-
• 安装方式:一键安装脚本,简化部署流程
开发环境
-
• 模块管理:通过 module 环境管理工具加载
-
• 编译链接:链接 KPL 动态库即可使用
-
• 头文件:所有 API 定义在 KPL 头文件中
开源社区
-
• 代码开源:优化案例、融合算子库、共享内存代码等均已开源
-
• 社区支持:鲲鹏共享社区提供完整文档和示例
总结
鲲鹏超智融合架构代表了 CPU 技术演进的新方向——通过集成专用加速单元,实现通用计算与专用计算的深度融合。这种架构不仅解决了 HPC 与 AI 负载的统一支撑问题,更为科学计算提供了更高效的硬件平台。随着 KPL 生态的不断完善和更多应用的适配,鲲鹏超智融合芯片有望在 AI for Science 领域发挥重要作用,推动科学研究的数字化转型。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)