
VILA1.5-8b40b模型昇腾NPU迁移适配实践
VILA 是由 NVIDIA Research 和 麻省理工学院 联合开发的一系列高性能视觉语言模型,它融合了计算机视觉和自然语言处理两大领域的技术,旨在实现更加智能和自然的图像理解和语言交互。VILA 是一种将视觉信息引入 LLM 的视觉语言模型,由视觉编码器、LLM 和投影仪组成,它们桥接了来自两种模态的嵌入。为了利用强大的 LLM,VILA 使用视觉编码器将图像或视频编码为视觉标记,然后将这
关注公众号:AI模力圈
作者:昇腾实战派 x 哒妮滋
背景概述
VILA 是由 NVIDIA Research 和 麻省理工学院 联合开发的一系列高性能视觉语言模型,它融合了计算机视觉和自然语言处理两大领域的技术,旨在实现更加智能和自然的图像理解和语言交互。VILA 是一种将视觉信息引入 LLM 的视觉语言模型,由视觉编码器、LLM 和投影仪组成,它们桥接了来自两种模态的嵌入。为了利用强大的 LLM,VILA 使用视觉编码器将图像或视频编码为视觉标记,然后将这些视觉标记输入 LLM,就好像它们是外语一样。这种设计可以处理任意数量的交错图像文本输入。
在实际应用过程中,我们需要将VILA1.5系列模型迁移至昇腾NPU平台,并集成到MindIE-LLM推理套件中,以实现高效的加速推理。本文将详细介绍迁移过程中的技术方案、实现方法和问题解决方案。
软硬件环境
- 硬件环境:Atlas 800I A2
- 软件版本:
- MindIE:1.0.RC2
- CANN:8.0.RC2
- Pytorch:2.1.0
模型架构分析
模型结构
VILA模型由视觉编码器、大语言模型(LLM)和投影仪三部分组成,通过投影仪桥接视觉和文本两种模态的嵌入表示。模型利用视觉编码器将图像或视频编码为视觉标记,然后将这些标记输入LLM进行处理。
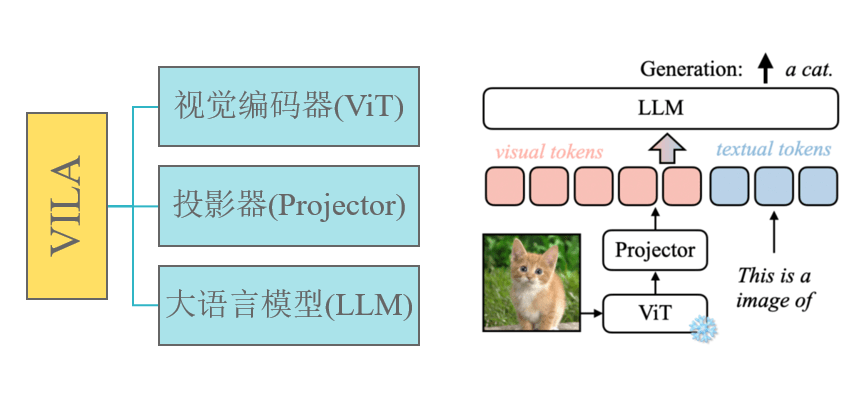
推理主要流程
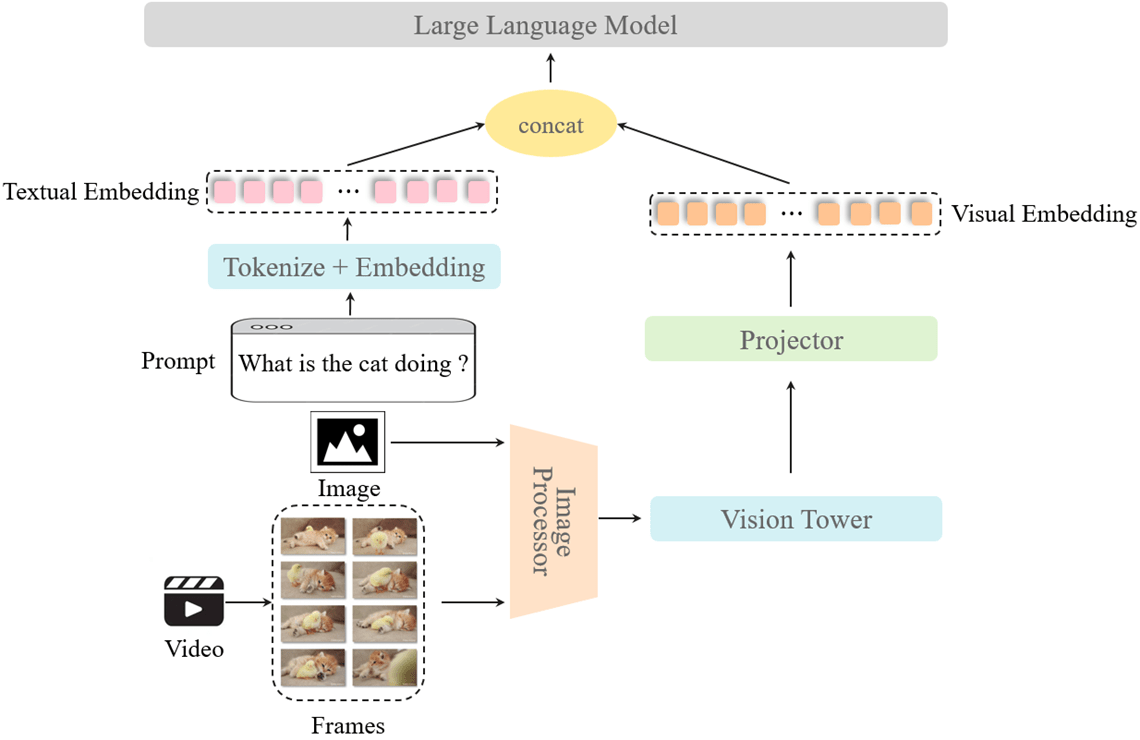
迁移方案设计
技术分析
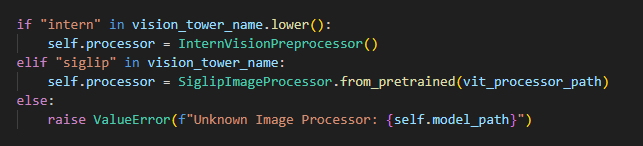
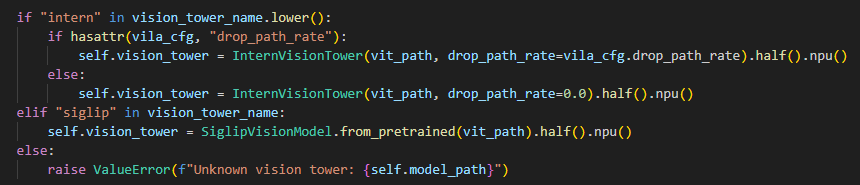
通过对VILA1.5-8b和VILA1.5-40b模型结构的分析,发现两个模型的主要差异在于vision_tower部分:8b模型使用SiglipVisionModel,而40b模型使用InternVisionModel。其中SiglipVisionModel在transformers库中已有实现,可直接导入使用,而InternVisionModel需要自行实现并注册。
基于模型结构与LLaVA模型的相似性,我们决定在LLaVA模型基础上进行修改,主要修改点包括:
- 增加视频理解功能支持
- vila1.5-8b/40b 模型处理图片和视频时构造 prompt 的方式与llava模型不同,需要添加对应构造 prompt 的函数
- vila1.5-8b/40b 模型使用的 projector 与 llava 不一样,需要重写 LlavaMultiModalProjector 类,并注册到 transformers 模型库中
- vila1.5-8b/40b 模型使用的 vision_tower 模型分别为 SiglipVisionModel 和 InternVisionModel,需要根据 vila1.5 模型的不同选择不同的 vision_tower,且由于 Intern 模型 tansformers 库中没有,所有需要自行创建 InternVisionTower 和InternVisionPreprocessor 类并注册到 transformers 模型库中
- vila1.5-8b/40b 与 llava 桥接多种模态嵌入的方式不同,需要添加新的桥接方法;
具体实现内容
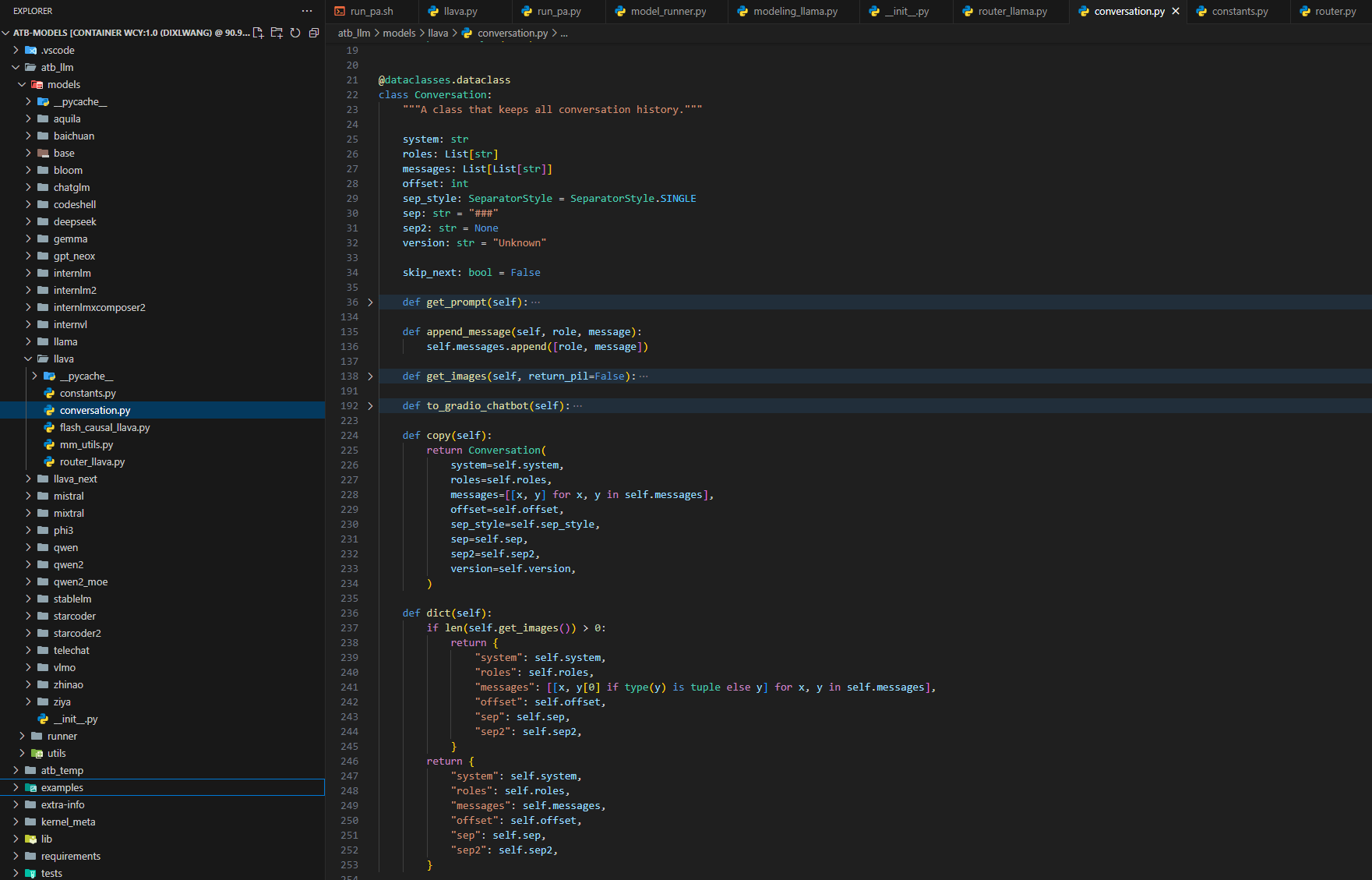
1. 多模态对话处理模块
在MindIE-LLM/examples/atb_models/atb_llm/models/llava 目录下新建conversation.py文件,实现图片和视频理解的prompt构造功能。
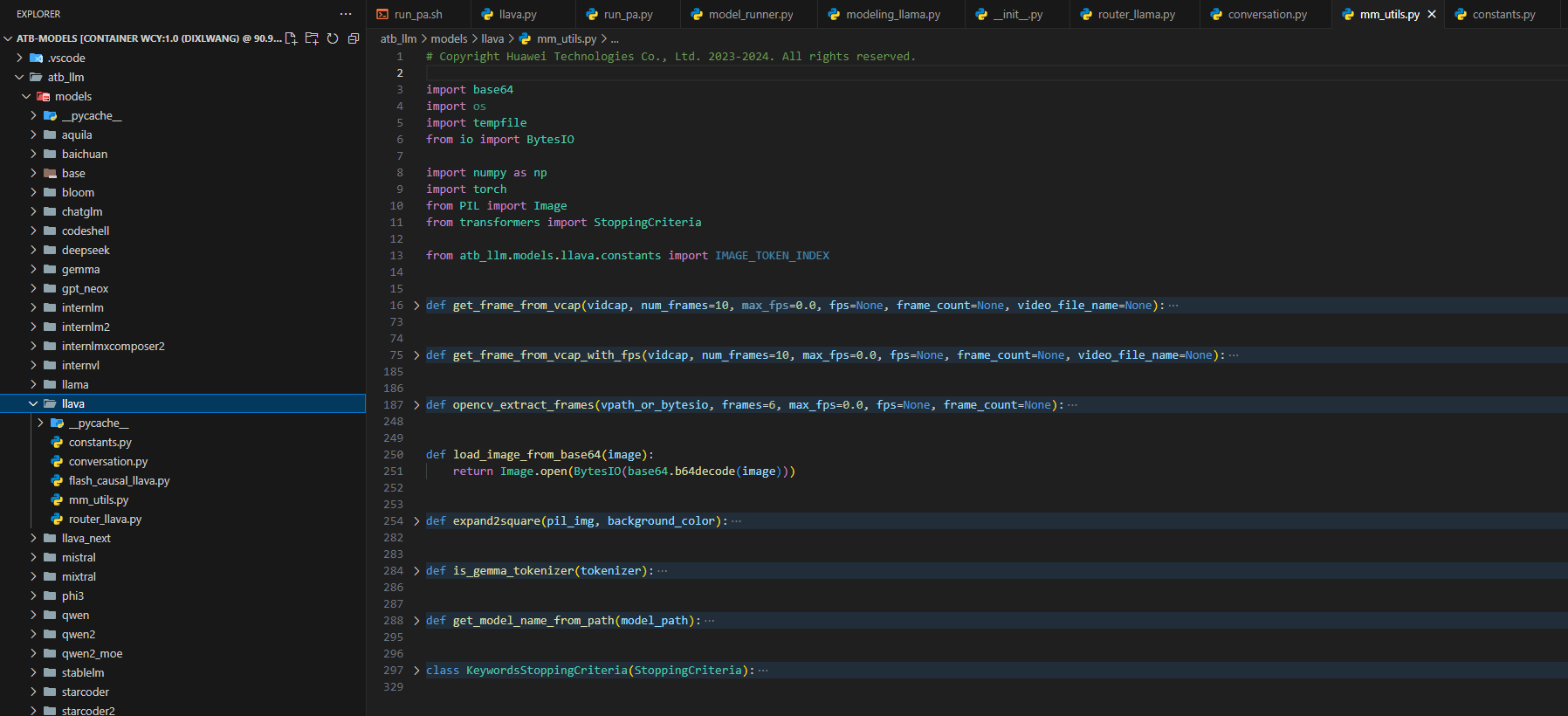
2. 视频处理工具模块
创建mm_utils.py文件,包含视频处理相关函数,支持视频帧提取和多模态数据处理。
3. 视频处理逻辑集成
在flash_causal_llava.py文件的prepare_prefill_token()函数中增加视频文件处理逻辑,确保模型能够正确处理视频输入。
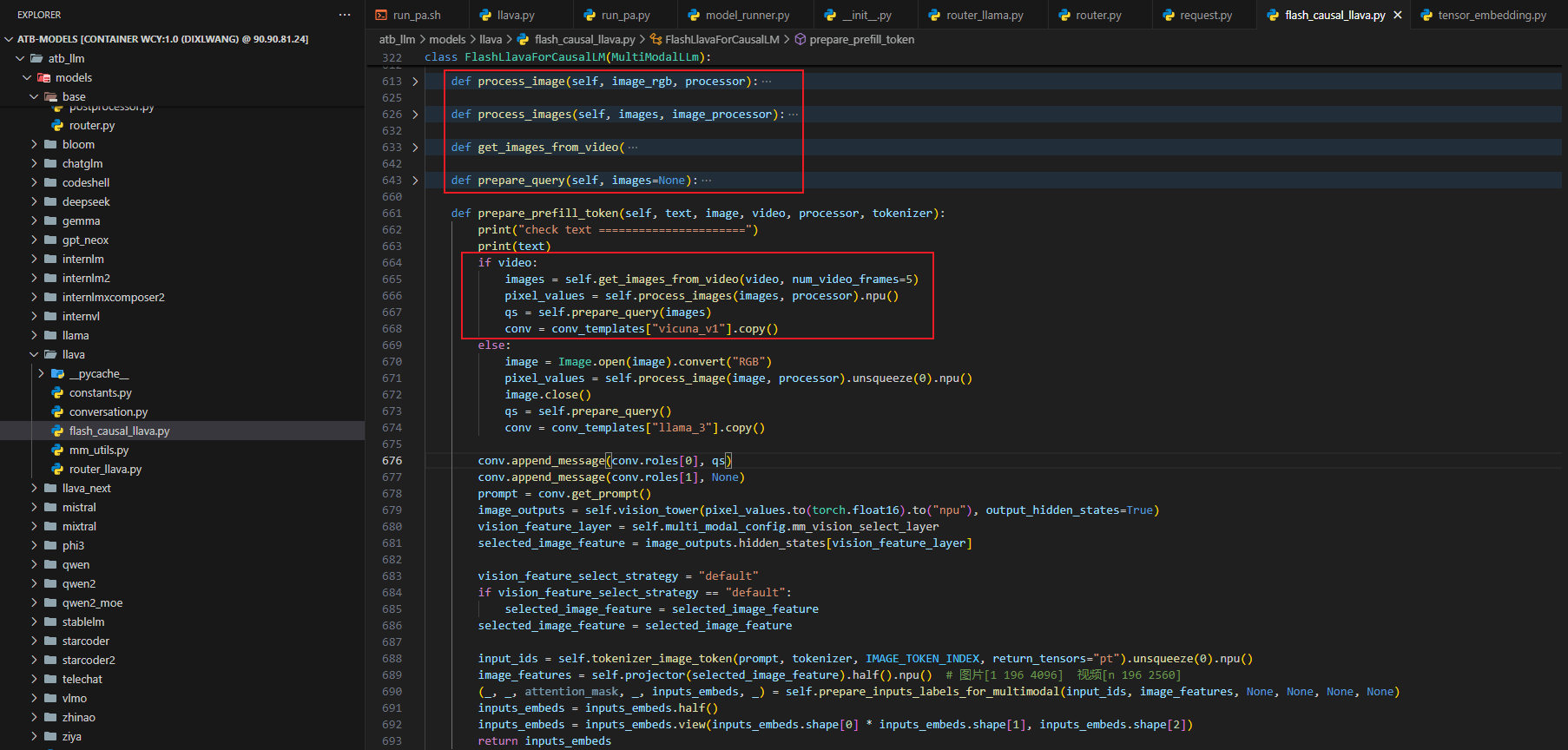
4. 多模态投影器重构
在 flash_causal_llava.py 文件中,重写LlavaMultiModalProjector类,适配VILA1.5模型的投影需求,并完成transformers库的注册。
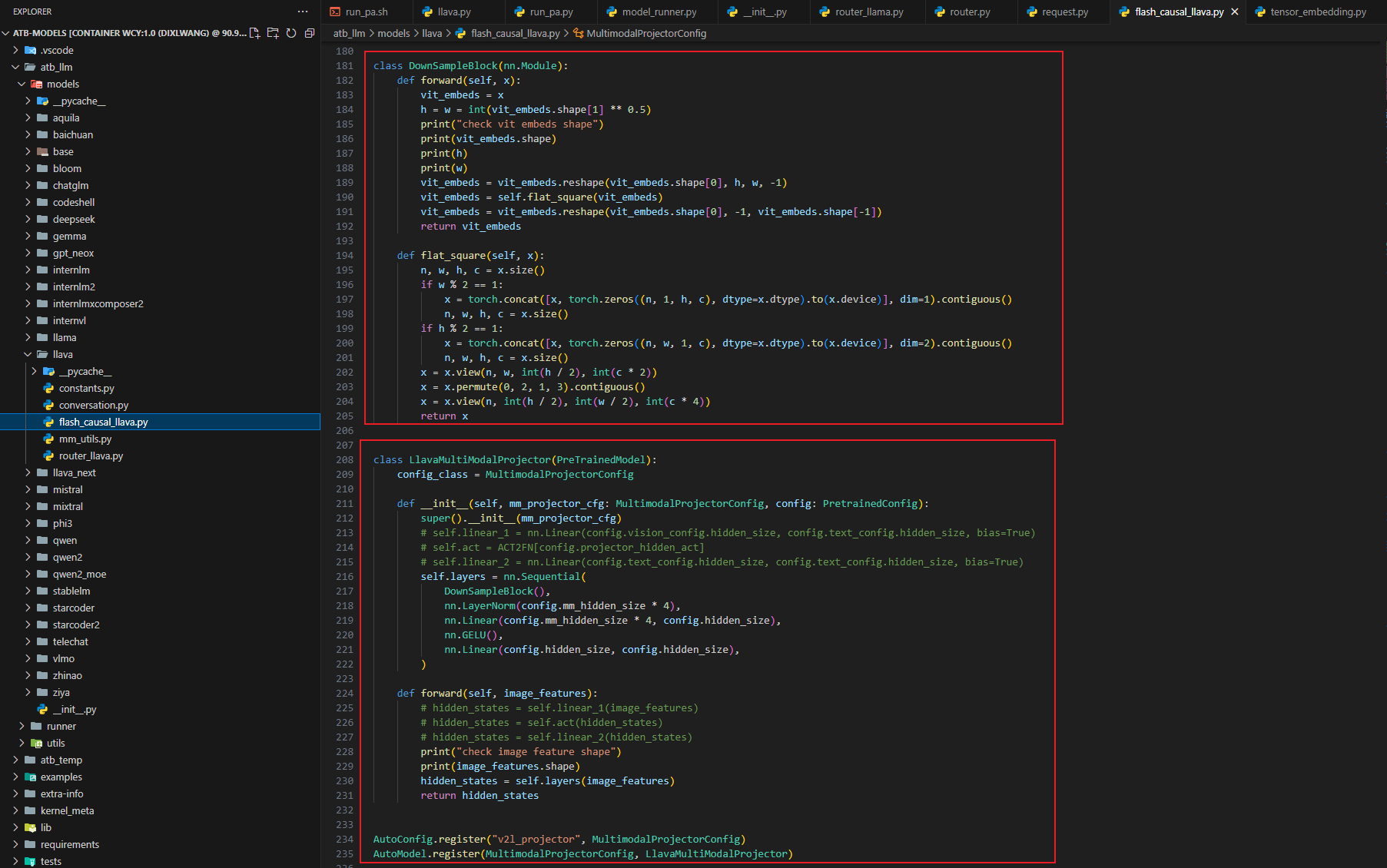
5. Intern视觉模型实现
创建modeling_intern_vit.py文件,实现InternVisionModel的完整结构。
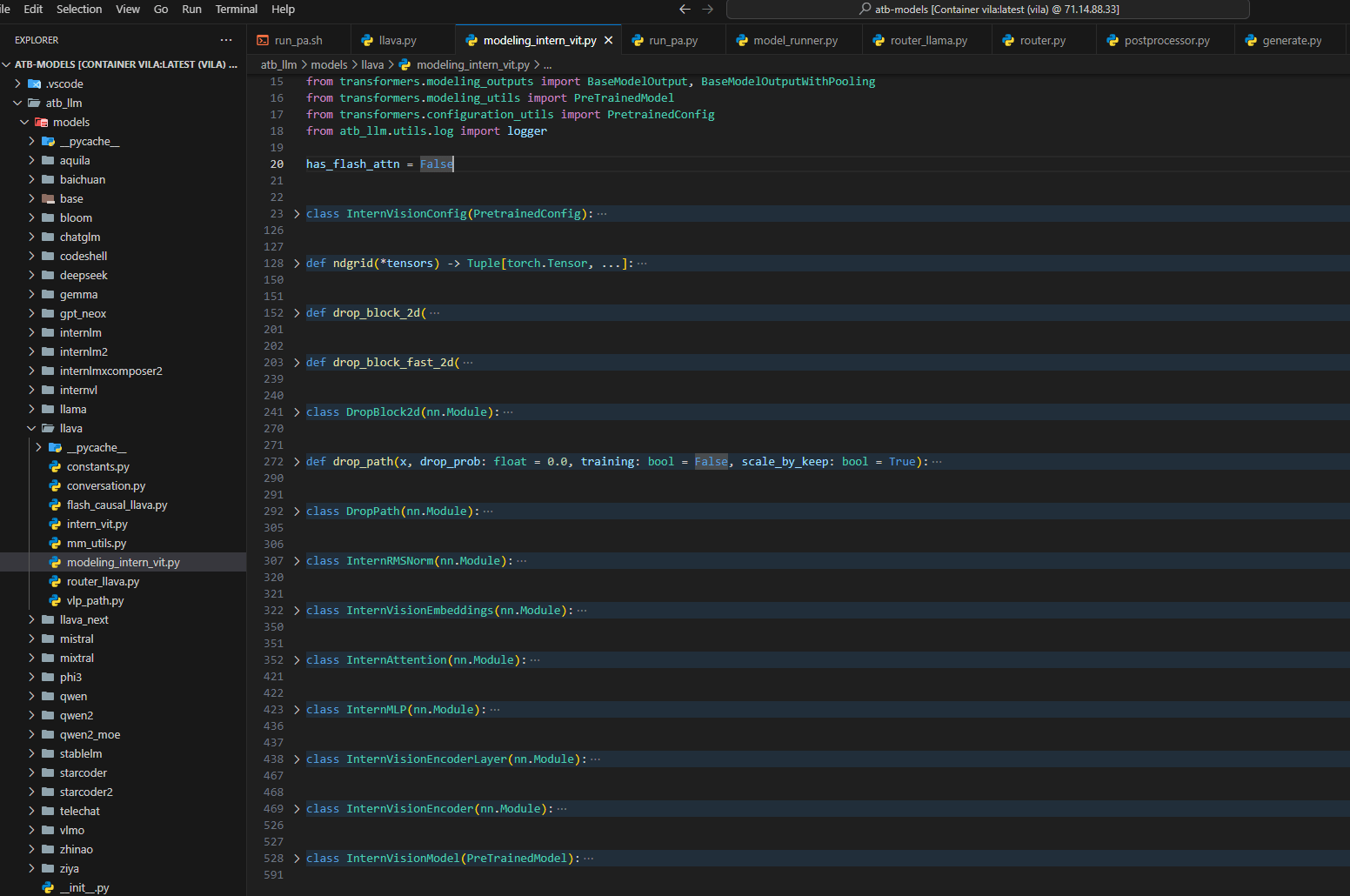
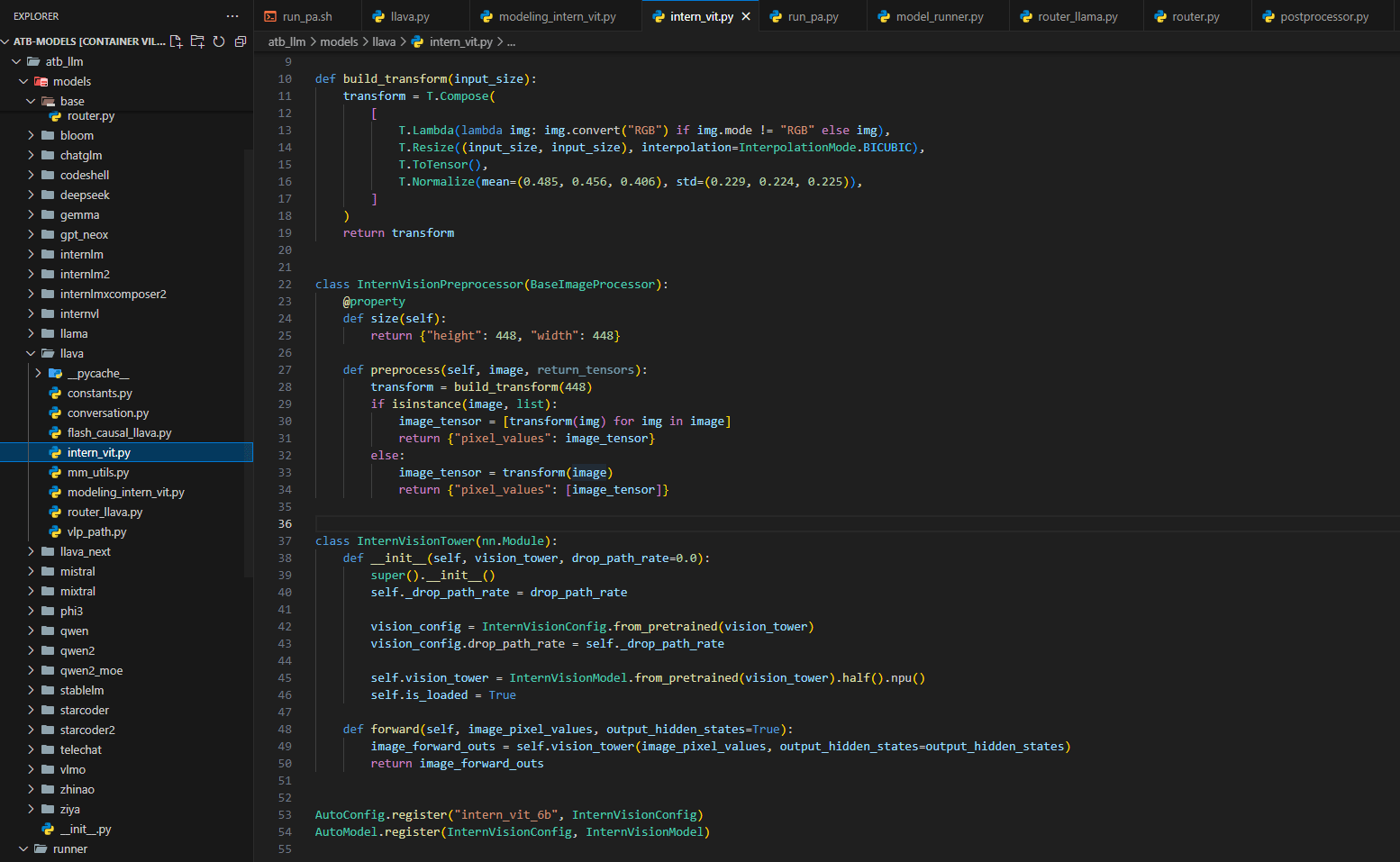
6. InternVisionTower和InternVisionPreprocessor
创建intern_vit.py文件,实现InternVisionTower和InternVisionPreprocessor类,完成transformers库的注册。
7. 模型组件动态选择
在业务代码中根据具体模型版本(8b或40b)动态选择对应的ImageProcessor和VisionTower。
8. 多模态嵌入桥接
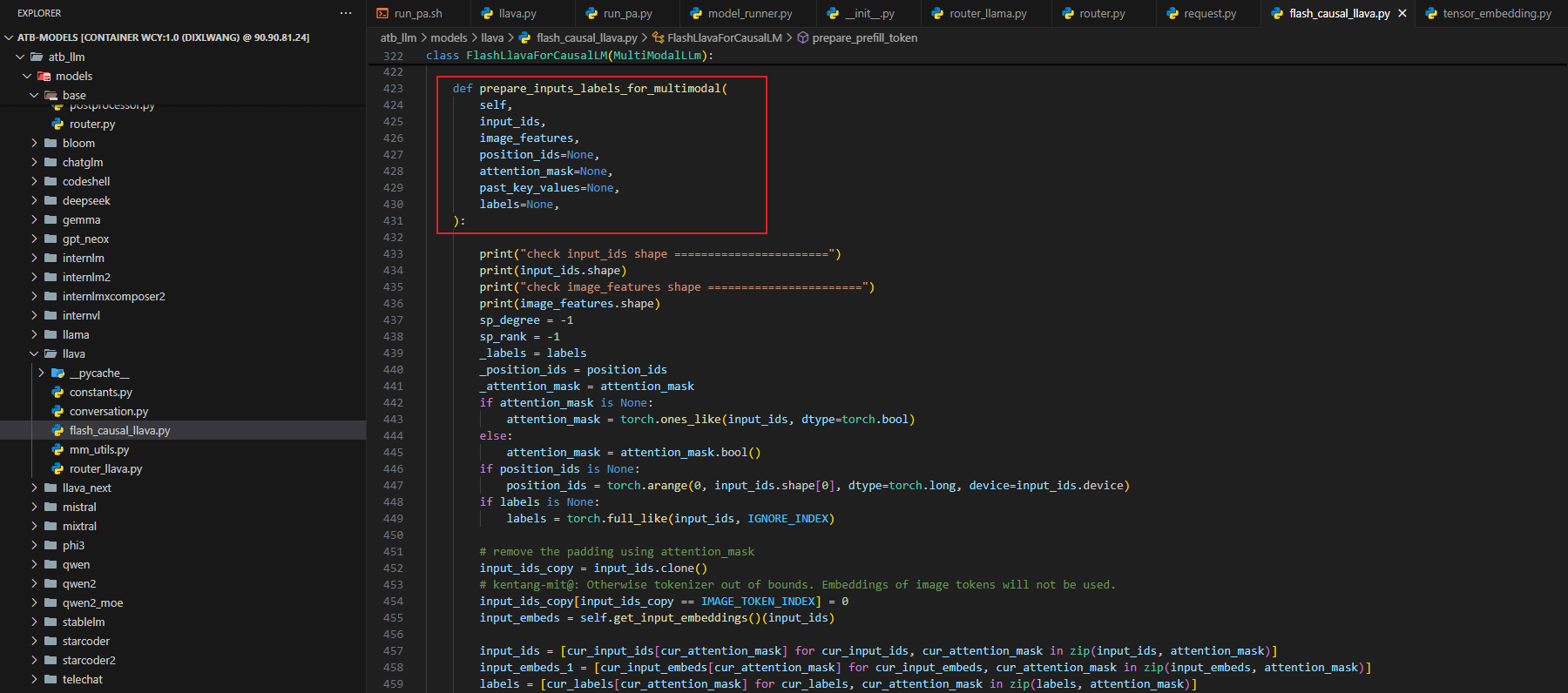
在 flash_causal_llava.py 文件中,实现prepare_inputs_labels_for_multimodal()函数,完成图片/视频嵌入与文本嵌入的有效桥接。
9. 配置文件优化
修改模型配置文件,在config.json 、./llm/config.json、./mm_projector/config.json和./vision_tower/config.json中将torch_dtype字段统一设置为"float16",确保模型精度一致性。
迁移效果验证
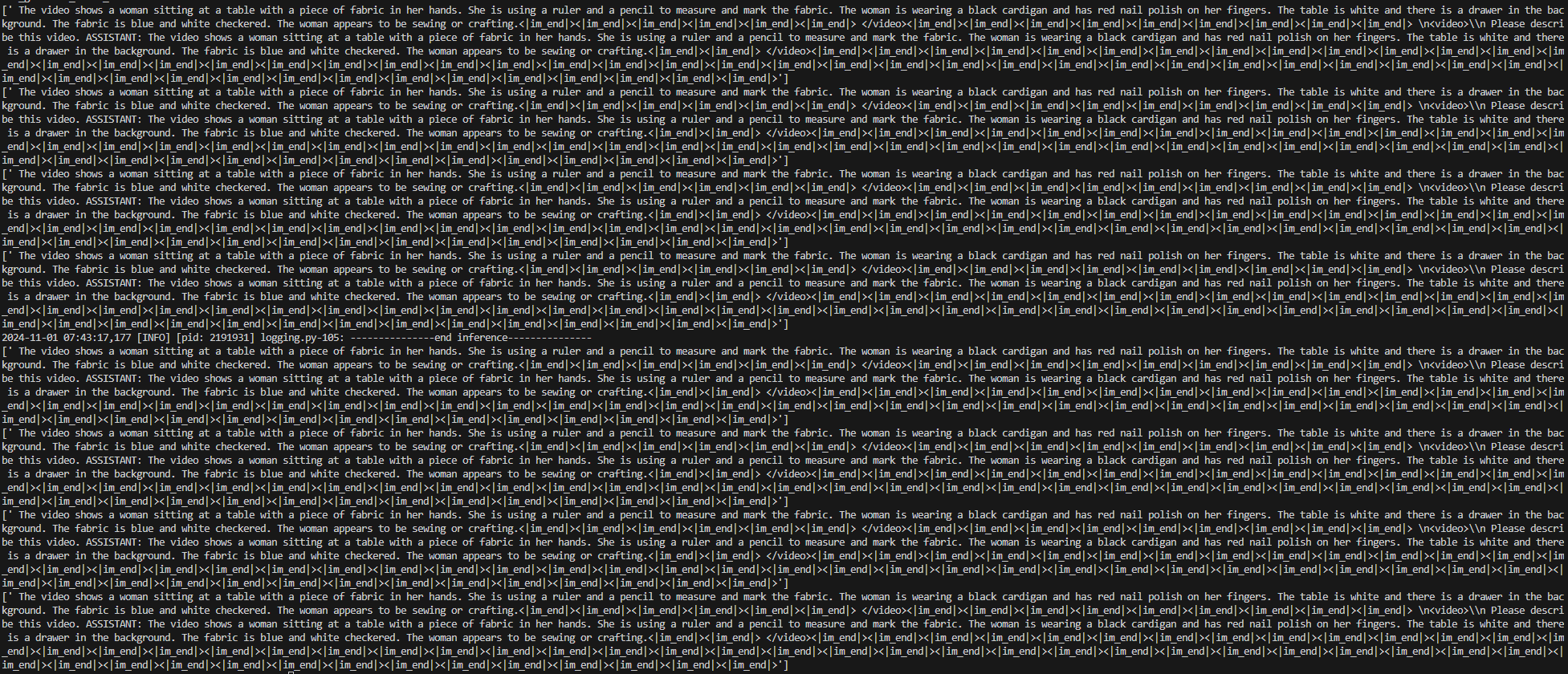
迁移完成后,使用样例视频进行推理测试,结果如下:
问题与解决方案
问题一:推理停止条件异常
现象发现推理精度没有问题,但输出结果多了很多 “<im_end>” 符号,甚至又开始了重新推理,直到 输出的 token 数达到预设的最大输出才停止。
**分析:**查看 llm 的 tokenizer_config.json 配置文件可知,“<im_end>” 为 eos_token ,且 token_id 为 7,说明推理过程中遇到 eos_token 没有停止。
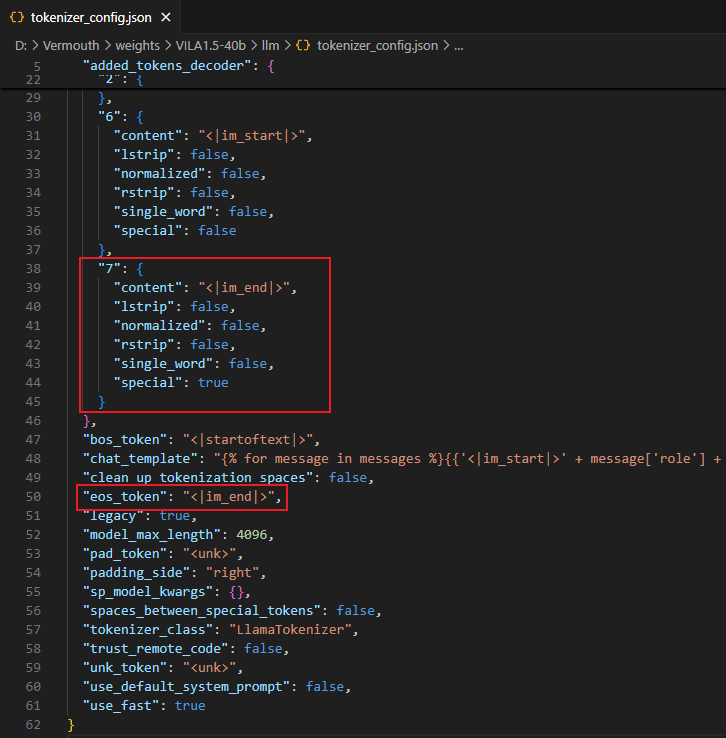
**解决方案:**查看推理停止的判断逻辑,发现其停止推理的功能是由 Postprocessor 类实现,实现逻辑是:判断当前生成的 token_id 和 与类中属性 eos_token_id 是否相等,相等就停止。
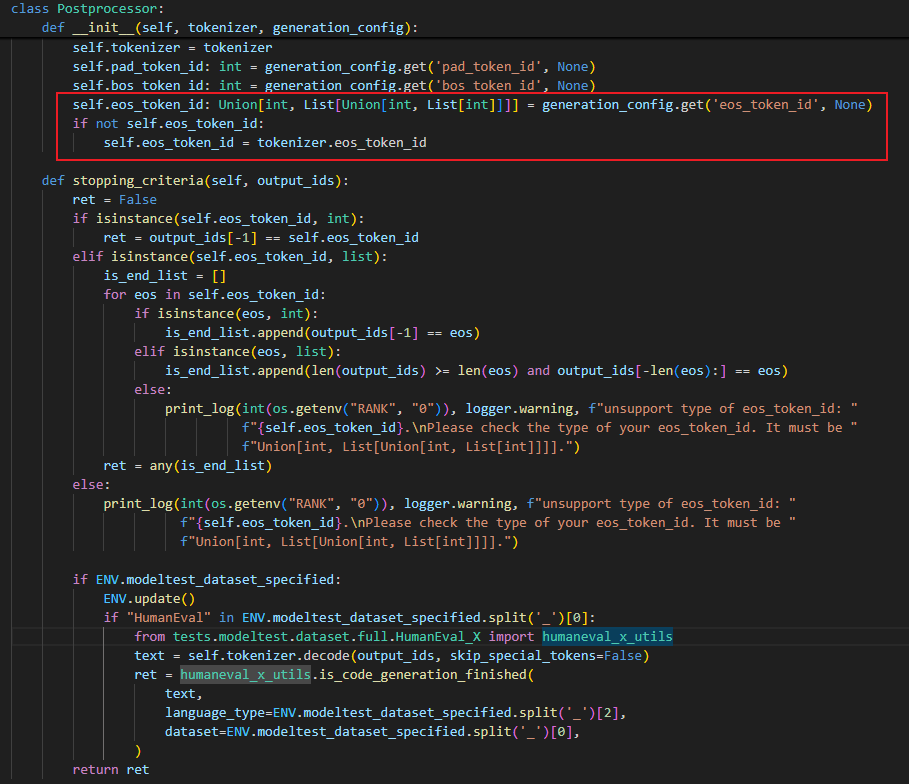
可以看出,该类中的属性 eos_token 是由 generation_cofig.json 配置文件中读取的,而原仓下载下来的配置文件为
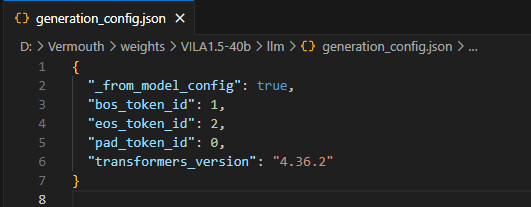
可见 eos_token_id = 2, 因此找到问题根因,将其修改为 eos_token_id = 7,重新推理,输出结果如下,问题得到解决。

问题二:40B模型显存溢出
现象对于40B模型,基于MindIE-LLM迁移后在910B4(32G)4卡推理显存溢出,甚至8张卡跑显存也溢出,这显然是不正常的。
**分析:**检查40B模型发现其ViT模型为InternVisionModel,是一个6B模型,光是模型的参数就有约12G大小。在代码中直接使用Pytorch框架的from_pretrained()方法导入,没有实现多卡切分逻辑,因此每张卡上都导入了一个完成的ViT模型,造成了显存的异常占用。


**解决方案:**使用Tensor Parallel方式对InternVisionModel做多卡切分
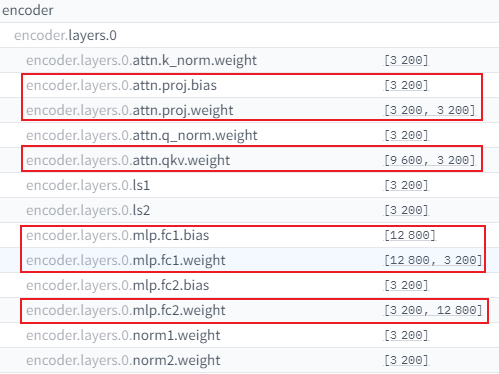
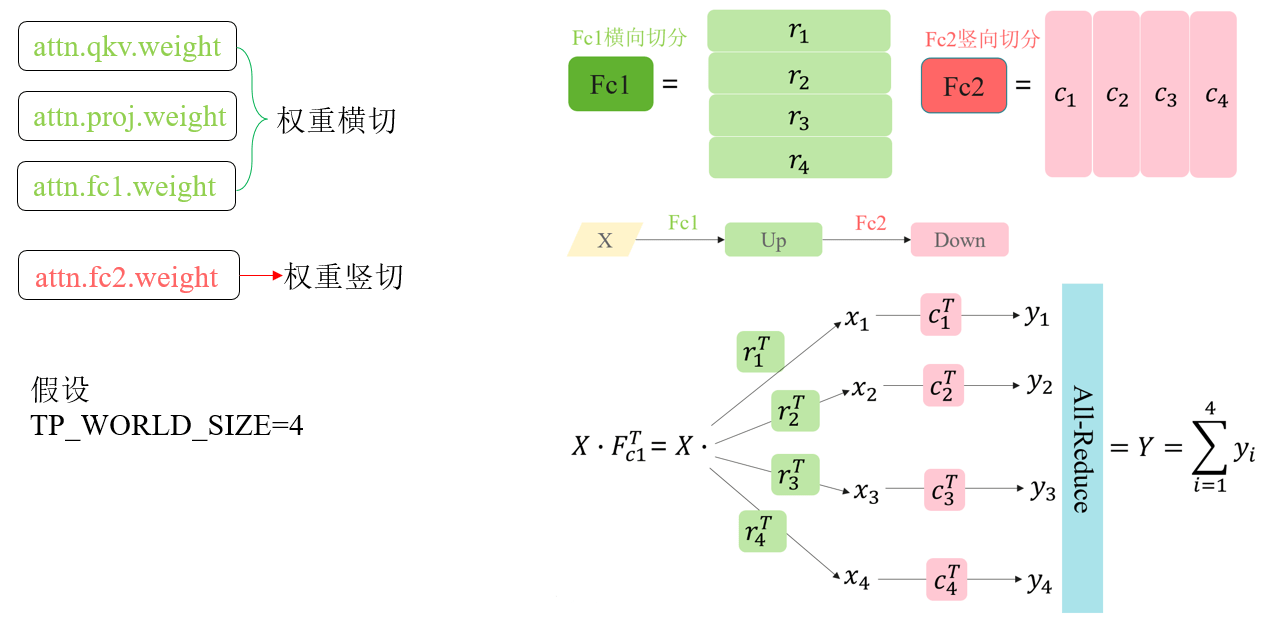
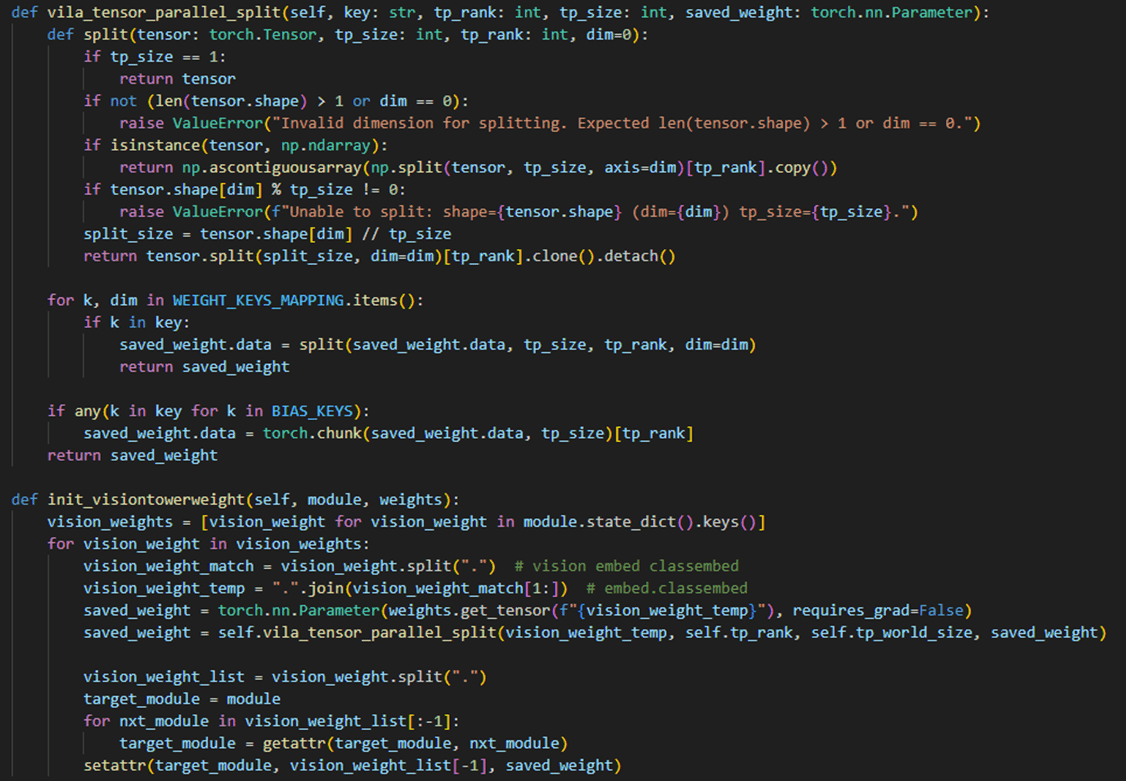
代码实现:
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化
图解版、速读版内容也会同步更新到公众号 / 小红书。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)