
昇思25天学习打卡营第10天|K近邻算法
【代码】昇思25天学习打卡营第10天|K近邻算法。
 ITop K algorithm as a famous algorithm put up long long ago doesnot not need to use too much calculation reusources, here we explore the execution of it.
ITop K algorithm as a famous algorithm put up long long ago doesnot not need to use too much calculation reusources, here we explore the execution of it.
A prediction algorithm of nearest problem:
1) find the 1-th to k-th nearest samples we have to the given samples(to be tested), and we count their numbers.
2) take the argmax.
we take Eucild distance.
Here is an example.
Wine dataset contains three kinds of wine produced in one place in Italy. They have some characteristics like :1.alcohol, 2. malic acid. 3. ash... 13. Proline.
Q: give you 13 features of some wine, predict which kind it is.
we read some data.
with open("wine.data") as csv_file:
data = list(csv.reader(csv_file, delimiter=','))
print(data[56:62]+ data[130:133])looks like:
 some little skills to treat data:
some little skills to treat data:
process 13 features as X and 3 kinds as Y
X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
Y = np.array([s[0] for s in data[:178]], np.int32)Visualize:
attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue','OD280/OD315 of diluted wines', 'Proline']
plt.figure(figsize = (10,8))
for i in range(0,4):
plt.subplot(2,2, i+1)
a1,a2 = 2*i, 2*i+1
plt.scatter(X[:59,a1],X[:59,a2],label='1')
plt.scatter(X[59:130,a1], X[59:130,a2], label = '2')
plt.scatter(X[130:,a1], X[130:, a2], label = '3')
plt.xlabel(attrs[a1])
plt.ylabel(attrs[a2])
plt.legend
plt.show()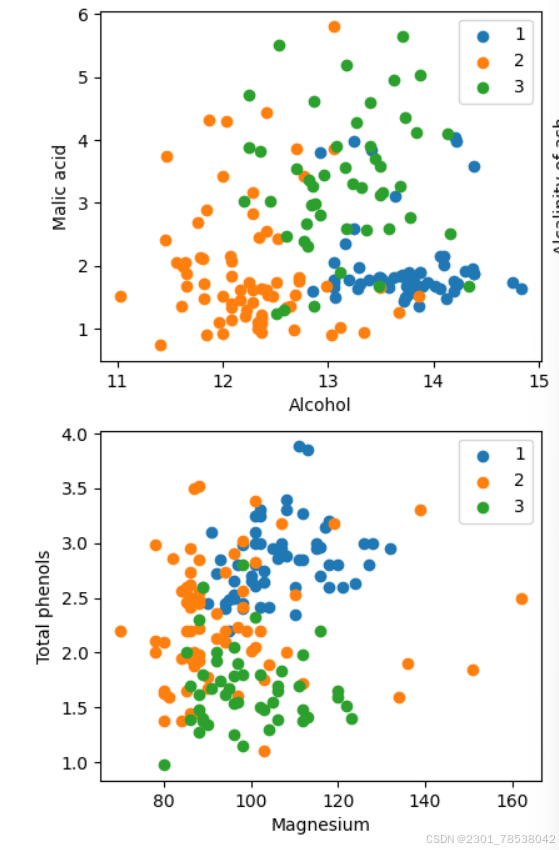
after seperating them as train and test subsets.
define the model:
class KnnNet(nn.Cell):
def __init__(self,k):
super(KnnNet,self).__init__()
self.k = k
def construct(self, x, X_train):
x_title = ops.title(x,(128, 1))
square_diff = ops.square(x_title - X_train)
square_dist = ops.sum(square_diff, 1)
dist = ops.sqrt(square_dist)
values, indices = ops.topk(-dist, self.k)
return indices
def knn(knn_net, x, X_train, Y_train):
x,X_train = ms.Tensor(x), ms.Tensor(X_train)
indices = knn_net(x,X_train)
topk_cls = [0]*len(indices.asnumpy())
for idx in indices.asnumpy():
topk_cls[Y_train[idx]] +=1
cls = np.argmax(topk_cls)
return clswe defined a model just calculating the euclid dist. we sum the too_k kinds.
we predict.
acc = 0
knn_net = KnnNet(5)
for x, y in zip(X_test, Y_test):
pred = knn(knn_net, x, X_train, Y_train)
acc += (pred == y)
print("label :%d ,prediction:%s" %(y,pred))
print("Val acc: %f" % (acc/len(Y_test)))
Not very good.

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)