
HCCL常见问题定位指南
在昇腾AI处理器的分布式训练场景中,HCCL(Huawei Collective Communication Library)作为集合通信库,承担着设备间数据通信的关键任务。在实际应用过程中,我们可能会遇到各种通信异常问题。本文系统梳理了HCCL常见问题的定位思路和解决方案。
作者:昇腾实战派
背景概述
在昇腾AI处理器的分布式训练场景中,HCCL(Huawei Collective Communication Library)作为集合通信库,承担着设备间数据通信的关键任务。在实际应用过程中,我们可能会遇到各种通信异常问题。本文系统梳理了HCCL常见问题的定位思路和解决方案。
1. Socket建链超时问题
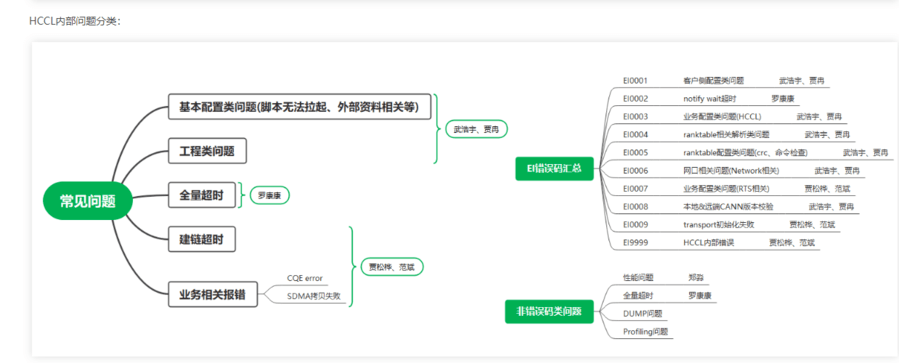
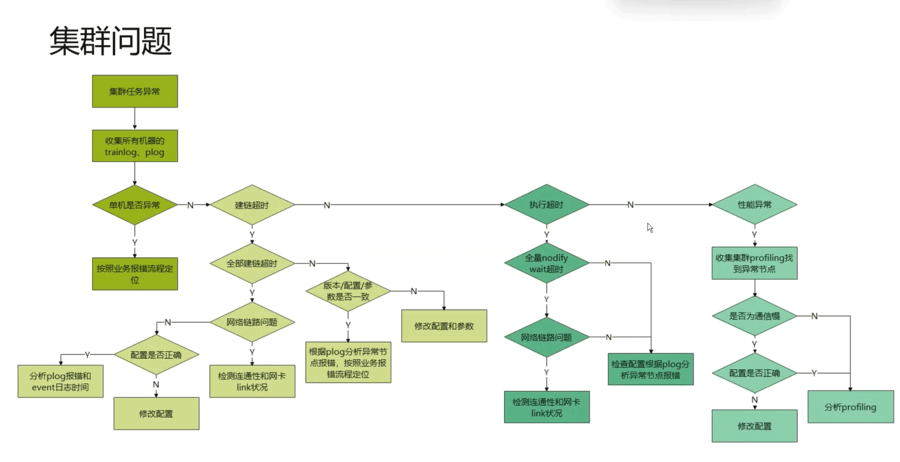
1. socket建链超时
定位思路
HCCL会在指定集群的每个device上运行,并在集群间建立socket链接,若任一个rank在建链前/中发生异常,则会导致集群建链失败。
原因分析
首先在host日志中搜索各个rank日志(Info级别)中,hcom初始化或者hcom报错算子对应的入口打印:
paraInfo(hcom init) grep -rn "hcom init" ./* 如果 8个卡,有8个hcom init success才正常
paraInfo(hcom allreduce) grep -rn "hcom allreduce" ./*
paraInfo(hcom allgather) grep -rn "hcom allgather" ./*
paraInfo(hcom broadcast) grep -rn "hcom broadcast" ./*
paraInfo(hcom reduceScatter)grep -rn "hcom reduceScatter" ./*
Broadcast,Scatter,Gather,Reduce,All-reduce详细介绍请点击查看
可能原因:
1. 部分rank建链前异常,导致和其他rank间的的建链超时
建链前其他组件异常,导致没有走到HCCL的建链处理;(最常见)如果在HCCL报错之前有HCCP异常请联系HCCP组件分析网络连接情况- 训练脚本有问题,训练拉起进程/docker数否和训练卡数不一致,导致实际拉起的进程和集群描述不符;
- TDT拉起失败/磁盘空间不足等,导致进程异常退出;
2. 各rank执行集合通信的时间相差过大(>120s)
确认各rank的入口打印日志的时间,是否相差超过120s,引起建联超时。
HCCL提供如下环境变量来配置超时阈值(默认为120s),如果在规模较大的集群上出现此问题,请灵活设置超时时间。
export HCCL_CONNECT_TIMEOUT=1800
3.各rank间集合通信算子的tag不一致
集合通信靠tag字符串来标识使用的资源,如果各rank上相对应的hccl接口使用的tag不一致,则会导致建链错位失败。 请确认上述接口入口打印日志的tag是否一致。不一致时请联系GE组件,确认各rank上HCCL算子加载顺序是否异常(要求加载顺序一直)。
※如需查询tag和计算图中node name的对应关系,需开启INFO日志,在host日志中搜索关键字 GetTagFromOpDesc: op 。
4.各rank的TLS设置不一致
各rank的TLS(安全增强)设置不一致时也会导致建链失败。 可通过hccl_tool来确认,如不一致请参考随软件包发布的hccl_tool使用指南进行TLS配置。(或者联系产品支撑人员赖尚校 00473539)
-
查询TLS状态命令:
hccn_tool -i 0 -tls -g hccn_tool -i 1 -tls -g hccn_tool -i 2 -tls -g hccn_tool -i 3 -tls -g hccn_tool -i 4 -tls -g hccn_tool -i 5 -tls -g hccn_tool -i 6 -tls -g hccn_tool -i 7 -tls -gTLS switch值为0表示关闭,1表示开启。如果提示
no certificate found,也表示TLS功能关闭。 如果各个rank的TLS情况不一致,可根据hccl_tool使用指南配置tls,或者关闭所有rank的TLS功能。 -
关闭TLS功能命令:
hccn_tool -i 0 -tls -s enable 0 hccn_tool -i 1 -tls -s enable 0 hccn_tool -i 2 -tls -s enable 0 hccn_tool -i 3 -tls -s enable 0 hccn_tool -i 4 -tls -s enable 0 hccn_tool -i 5 -tls -s enable 0 hccn_tool -i 6 -tls -s enable 0 hccn_tool -i 7 -tls -s enable 0
5.device工作模式不正确
AI server 需要 device 工作在 SMP 模式。
现象
在 SMP 模式,slog 目录下有两个 device-os 目录:
device-os-0 device-os-4
如果在 AMP 模式,slog 目录下会有多个 device-os 目录:
device-os-0 device-os-1 device-os-2 device-os-3 device-os-4 device-os-5 device-os-6 device-os-7
或者
device-os-0 device-os-1 device-os-2 device-os-3 device-os-4
或者
device-os-0 device-os-4 device-os-5 device-os-6 device-os-7
查看 device 日志确认是否为 SMP 模式:
在 device 日志中 grep 关键字
board。 如果 board id 为 1040,则为 AMP 模式;如果 board id 为 1042,则为 SMP 模式。
切换 SMP/AMP 方法:
- 登录网页 BMC,下电
- ssh 登录 BMC
- 执行命令
maint_debug_cli- 执行命令
regread 0x34b- 执行命令
regread 0x37b- 读到值是 0x30,则是 SMP 模式;读到的值是 0x20,则是 AMP 模式。如果是 AMP 模式,需要执行命令
regwrite 0x34b 0x30或者regwrite 0x37b 0x30, 将 device 工作模式设置为 SMP- 登录网页 BMC,上电
2. notify wait timeout
现象
定位思路
HCCL算子执行时,会在所有rank间使用notify进行同步。如果有任何一个rank发生异常,多会导致剩余所有rank均发生 notify wait timeout。 P.S. 目前notify wait timeout的阈值为 500s 。
原因分析
1.判断是否所有的rank均发生notify wait timeout
在所有参与训练server的 device-0 ~ device-7 的日志中搜索关键字 [ERROR] TSCH,确认:
- 是否所有卡均有
task_type=14的报错;- 如存在部分卡报错为非
task_type=14的报错,请联系RTS或其他相应报错组件; - 如存在部分卡未报错,请联系RTS组件排查未报错的卡是否存在task未启动执行或训练提前结束的情况;
- 如存在部分卡报错为非
- 所有device日志中notify wait timeout报错的时间是否基本一致(最大偏差不超过500s),如有报错时间不一致请检查各个device上训练开始的时间是否相同。
2.多Server训练的场景,需判断是否存在网络拥塞,导致网路数据丢包
在所有参与训练server的device-os-* 的日志中搜索关键字 error cqe , 如存在此报错,则说明网络配置存在问题,请联系HCCP组件解决。
3.其他原因(所有device均为 notify wait timeout 报错,且无网络拥塞)
需获取profiling日志分析下沉task的执行情况,请采集以下profiling日志,使用集群维持工具mywatch进行分析。
- HCCL:HCCL.host.*
- HWTS:hwts.log.*
- 迭代轨迹:training_trace* (如迭代数小于100可不采集迭代轨迹)
集群维持工具mywatch使用请参考:
http://3ms.huawei.com/hi/group/1503879/wiki_5772784.html?for_statistic_from=all_group_wiki
3. get P2P status timeout现象定位思路HCCL初始化会在AIserver内的各rank(device)间建立P2P使能链接,若任一个rank在建链前/中发生异常,则会导致本AI server初始化失败。原因分析首先在host日志中搜索HCCL初始化的入口打印 <START hccl(world group) initialize>或者paraInfo(hcom init) 。可能的原因1. 部分rank在P2P使能前异常,导致和其他rank间的使能超时确认各rank上HCCL初始化日志打印是否有缺失,若有缺失请排查上游调用逻辑。P2P使能前其他组件异常,导致没有走到HCCL初始化(典型问题:TSD没有拉起失败);训练脚本有问题,训练拉起进程/docker数否和训练卡数不一致,导致实际拉起的进程和集群描述不符;TDT拉起失败/磁盘空间不足等,导致进程异常退出;2. 各rank上HCCL的调用时差超过120s,引起使能超时确认各rank的入口打印日志的时间,是否相差超过120s,若超过则为集合通信拉起时间相差过大。常见场景: 训练启动脚本有问题,多卡训练时应同时运行多个进程(每张卡对应一个进程),而不是一个进程结束后再启动下一个进程。# 典型错误
for i in ${DEVICE_LIST}
do
export DEVICE_ID=$i
export RANK_ID=$i
echo "start train ing device $i"
python3.7.5 /home/HwHiAiUser/train.py # 阻塞执行
done
# ------------------------------------------------------------------------------
# 解决方法
for i in ${DEVICE_LIST}
do
export DEVICE_ID=$i
export RANK_ID=$i
echo "start train ing device $i"
python3.7.5 /home/HwHiAiUser/train.py & # 后台执行
done
3. 配置的rank_table和实际使用的device不一致
在日志(EVENT级别)中 grep 关键字 paraInfo(hcom init(下沉模式) 或者 paraInfo(HcclCommInitClusterInfo)(单算子模式), 打开日志中打印的 rank table 文件,确认该 server 上启动的 rank 数是否和 rank table 文件上配置的一致。
例如,实际使用 2P,但是 rank table 是按照 8P 进行配置的,HCCL 在初始化时会出现该现象。
3. get P2P status timeout
现象
定位思路
HCCL初始化会在AIserver内的各rank(device)间建立P2P使能链接,若任一个rank在建链前/中发生异常,则会导致本AI server初始化失败。
原因分析
首先在host日志中搜索HCCL初始化的入口打印 <START hccl(world group) initialize>或者paraInfo(hcom init) 。
可能的原因
1. 部分rank在P2P使能前异常,导致和其他rank间的使能超时
确认各rank上HCCL初始化日志打印是否有缺失,若有缺失请排查上游调用逻辑。
P2P使能前其他组件异常,导致没有走到HCCL初始化(典型问题:TSD没有拉起失败);- 训练脚本有问题,训练拉起进程/docker数否和训练卡数不一致,导致实际拉起的进程和集群描述不符;
- TDT拉起失败/磁盘空间不足等,导致进程异常退出;
2. 各rank上HCCL的调用时差超过120s,引起使能超时
确认各rank的入口打印日志的时间,是否相差超过120s,若超过则为集合通信拉起时间相差过大。
常见场景: 训练启动脚本有问题,多卡训练时应同时运行多个进程(每张卡对应一个进程),而不是一个进程结束后再启动下一个进程。
# 典型错误
for i in ${DEVICE_LIST}
do
export DEVICE_ID=$i
export RANK_ID=$i
echo "start train ing device $i"
python3.7.5 /home/HwHiAiUser/train.py # 阻塞执行
done
# ------------------------------------------------------------------------------
# 解决方法
for i in ${DEVICE_LIST}
do
export DEVICE_ID=$i
export RANK_ID=$i
echo "start train ing device $i"
python3.7.5 /home/HwHiAiUser/train.py & # 后台执行
done
3. 配置的rank_table和实际使用的device不一致
在日志(EVENT级别)中 grep 关键字 paraInfo(hcom init(下沉模式) 或者 paraInfo(HcclCommInitClusterInfo)(单算子模式), 打开日志中打印的 rank table 文件,确认该 server 上启动的 rank 数是否和 rank table 文件上配置的一致。
例如,实际使用 2P,但是 rank table 是按照 8P 进行配置的,HCCL 在初始化时会出现该现象。
4.ra init failed
现象
HCCL 初始化网卡失败,HCCP 报错误码 -17。
定位思路
HCCL 在初始化时会根据 rank table 中的 device ip 初始化 device 网卡。 如果初始化使用的 device ip 和实际网卡的 ip 不一致,HCCP 会初始化网卡失败并返回错误码 -17。
HCCL 初始化时根据 rank id 在 rank table 查找对应 rank id 的 device ip,使用该 ip 去初始化网卡。
因此,对于此问题需要确认: 初始化hccl时的 rank id 在 rank table 中对应的 device ip 是否和该 server 的 device ip 一致。
- 如何确认该 device 的 rank id 和 rank table ?在用户态host日志(需打开EVENT日志)中, grep 关键字
paraInfo(hcom init(下沉模式) 或者paraInfo(HcclCommInitClusterInfo)(单算子模式)。 - 如果确认该 server 的 device ip ?
使用 hccn_tool 可查看 device 网卡信息。
hccn_tool -i 0 -ip -g
hccn_tool -i 1 -ip -g
hccn_tool -i 2 -ip -g
hccn_tool -i 3 -ip -g
hccn_tool -i 4 -ip -g
hccn_tool -i 5 -ip -g
hccn_tool -i 6 -ip -g
hccn_tool -i 7 -ip -g
5.配置环境变量 HCCL_WHITELIST_DISABLE 为1,关闭HCCL通信白名单。
单机场景
配置环境变量 HCCL_WHITELIST_DISABLE 为1,关闭HCCL通信白名单。
export HCCL_WHITELIST_DISABLE=1
多机场景
- 配置环境变量 HCCL_WHITELIST_DISABLE 为1,关闭HCCL通信白名单。
- 配置环境变量 HCCL_IF_IP 为使用的host网卡IP。(要求保证使用的该网卡在集群内互通)
示例
export HCCL_WHITELIST_DISABLE=1
export HCCL_IF_IP=hostname -I|awk '{print $1}'
或
export HCCL_IF_IP=ip addr | grep 'state UP' -A2 | tail -n1 | awk '{print $2}' | awk -F"/" '{print $1}'
6、跑集群失败,报卡之间的建链超时,报the connection failure between this device and target device may be due to the following reasons,可能原因是服务器上的device_id 跟其他服务器上的device_id 有冲突,重新设置一下device_id看是否解决问题

服务器a
hccn_tool -i 0 -ip -s address 192.168.220.100 netmask 255.255.255.0
hccn_tool -i 1 -ip -s address 192.168.221.100 netmask 255.255.255.0
hccn_tool -i 2 -ip -s address 192.168.222.100 netmask 255.255.255.0
hccn_tool -i 3 -ip -s address 192.168.223.100 netmask 255.255.255.0
hccn_tool -i 4 -ip -s address 192.168.220.101 netmask 255.255.255.0
hccn_tool -i 5 -ip -s address 192.168.221.101 netmask 255.255.255.0
hccn_tool -i 6 -ip -s address 192.168.222.101 netmask 255.255.255.0
hccn_tool -i 7 -ip -s address 192.168.223.101 netmask 255.255.255.0
服务器b
hccn_tool -i 0 -ip -s address 192.168.220.110 netmask 255.255.255.0
hccn_tool -i 1 -ip -s address 192.168.221.110 netmask 255.255.255.0
hccn_tool -i 2 -ip -s address 192.168.222.110 netmask 255.255.255.0
hccn_tool -i 3 -ip -s address 192.168.223.110 netmask 255.255.255.0
hccn_tool -i 4 -ip -s address 192.168.220.111 netmask 255.255.255.0
hccn_tool -i 5 -ip -s address 192.168.221.111 netmask 255.255.255.0
hccn_tool -i 6 -ip -s address 192.168.222.111 netmask 255.255.255.0
hccn_tool -i 7 -ip -s address 192.168.223.111 netmask 255.255.255.0
7、在B板(aicore数量是30)的服务器上跑精度,batch_size需要设置成30的倍数,如果设置成32会导致数据切分不均衡,进而导致卡间不同步,进而导致hccl集合通信超时。现象是7张卡报notify超时,1张还在继续跑而没有任何报错。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)