
昇思25天学习打卡营第12天|文本解码原理
·
这次是使用MindNLP库和GPT-2模型,进行文本生成,涵盖了多种文本解码策略
贪心搜索(Greedy search)
在每个时间步𝑡都简单地选择概率最高的词作为当前输出词:,缺点是会省略低概率词后面的高概率词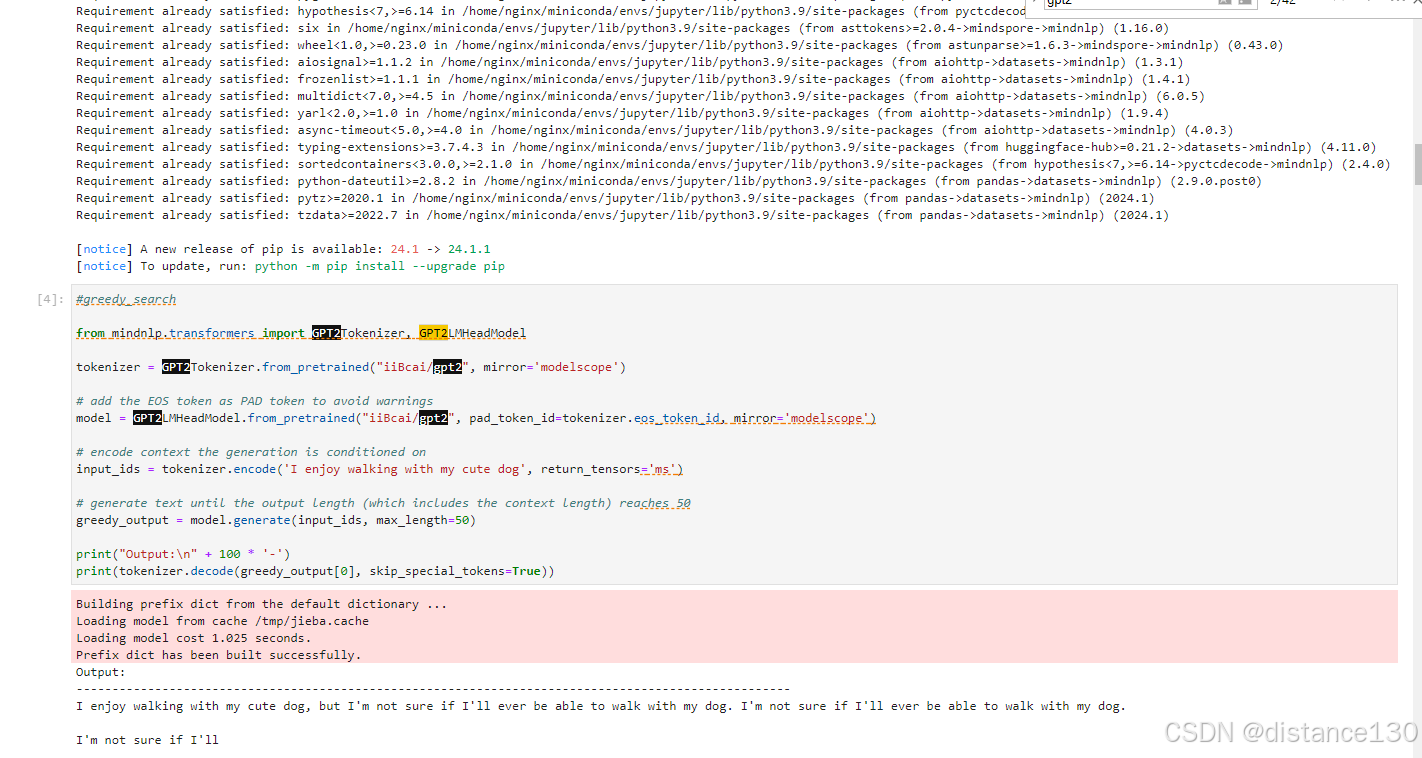 束搜索(Beam search)
束搜索(Beam search)
通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。一定程度保留最优路径 缺点 无法解决重复问题; 开放域生成效果差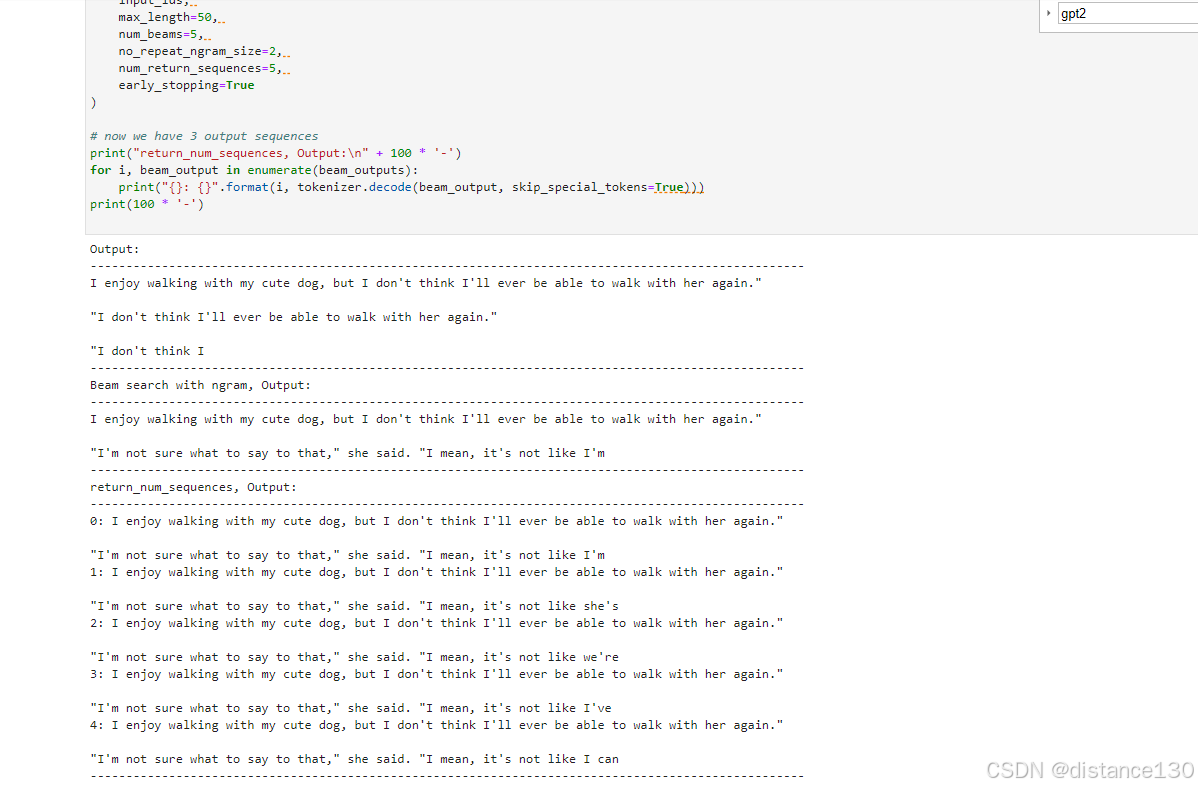 最后是采样(Sampling)
最后是采样(Sampling)
能根据当前条件概率分布随机选择输出词𝑤_𝑡,文本生成多样性高,但是不连续
最后课程结合通过TopK和TopP采样的优点,提供更平衡的文本生成结果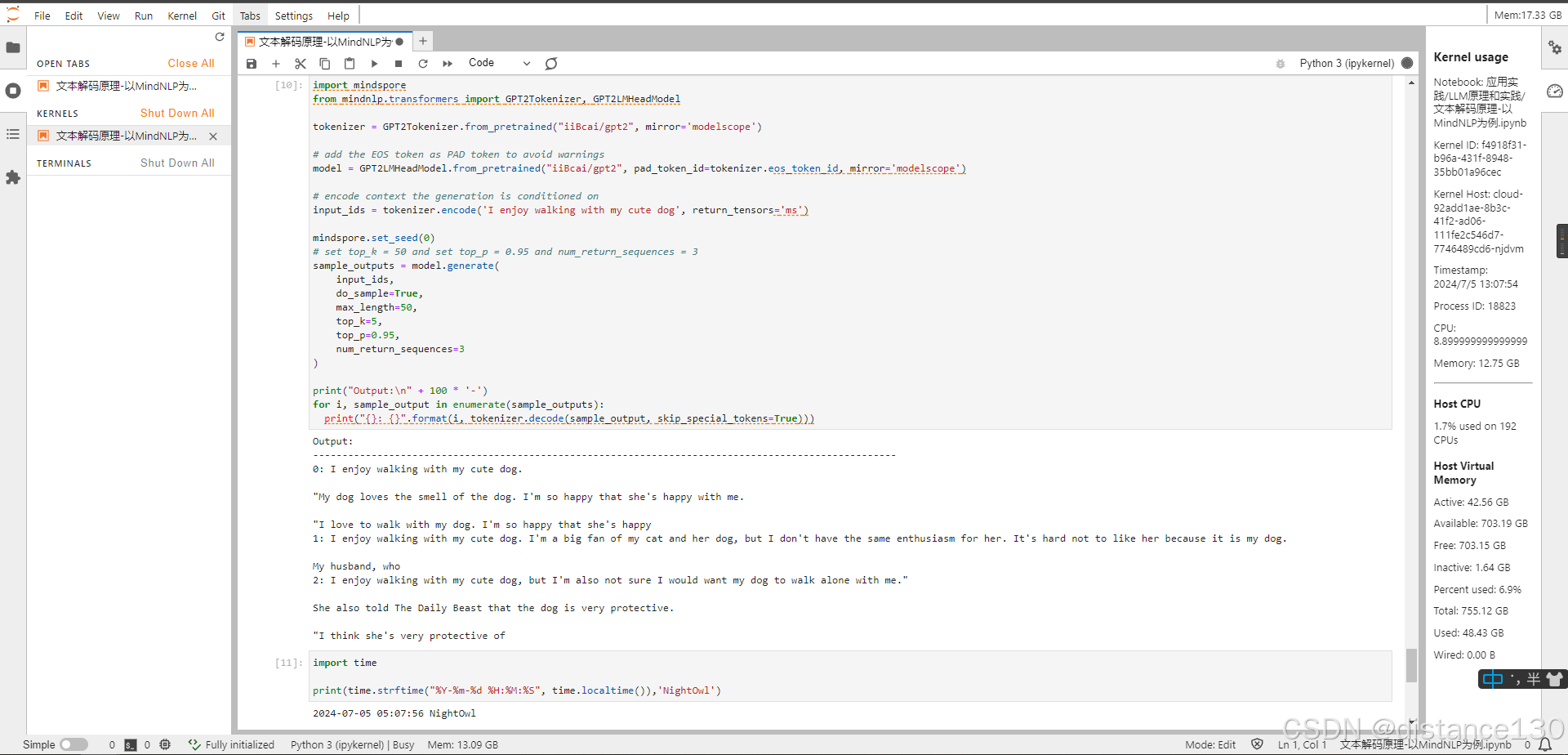

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 2
2 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)