
华为昇腾CANN深度学习环境搭建-以搭建VLLM为例
为什么要截取90000,因为如果请求超过vllm的max_len 会报错,所以最好限制一下,不要超过vllm起服务时候的最大长度。下载toolkit和 kernels, 我是910b,如果是310请选择对照的版本。安装完了vllm以后呢,torch会被重新装一下,版本可能和你的驱动不搭配。安装完了以后,再安装一下这几个包,推荐使用conda安装。然后vllm-ascend版本和vllm版本要对照。
1 )首先确定vllm-ascend依赖。
 确定cann的版本8.3.rc2。
确定cann的版本8.3.rc2。
确定vllm和vllm-ascend的对照关系

2) 查询物理机的驱动版本
 假设不是cann8.3rc2,那就安装
假设不是cann8.3rc2,那就安装
网址在这里,需要自己注册登录一下:

下载toolkit和 kernels, 我是910b,如果是310请选择对照的版本。
下载完了以后就安装这俩驱动
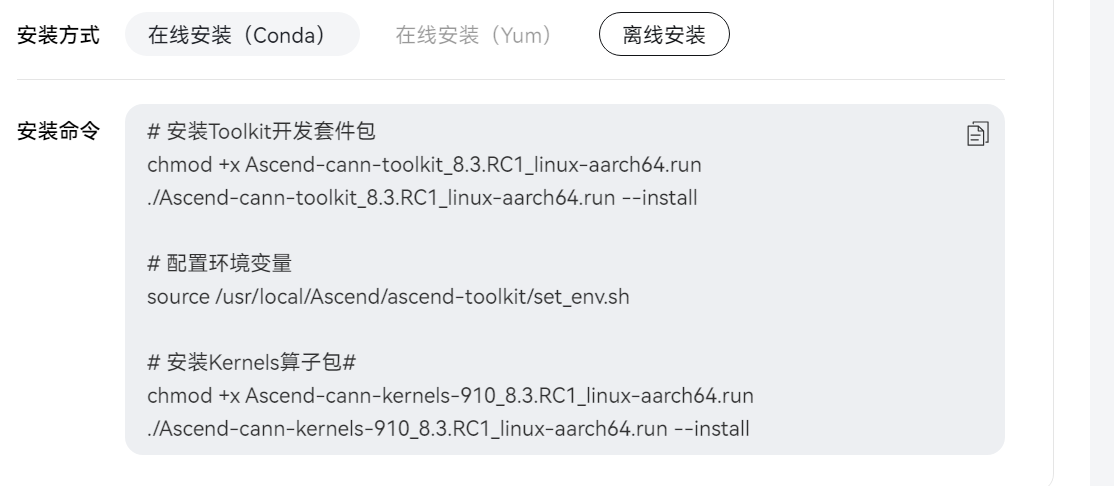 安装完了以后,再安装一下这几个包,推荐使用conda安装。
安装完了以后,再安装一下这几个包,推荐使用conda安装。
pip3 install attrs cython 'numpy>=1.19.2,<=1.24.0' decorator sympy cffi pyyaml pathlib2 psutil protobuf==3.20.0 scipy requests absl-py --user
到这个阶段,驱动安装完了。
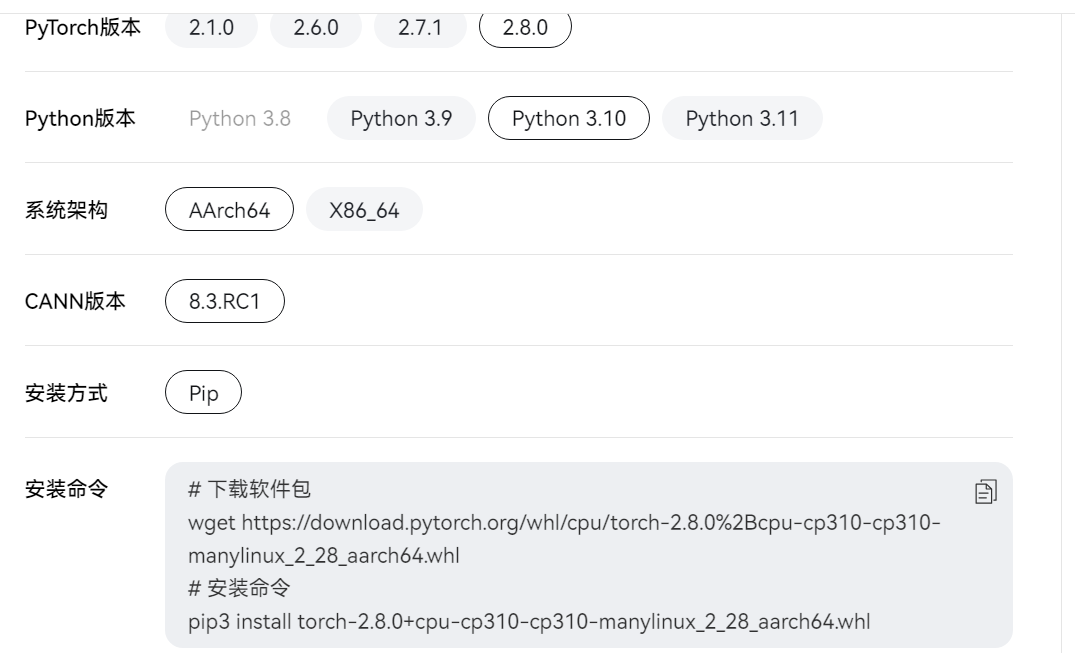
3)开始安装torch和torch-npu
这是下载地址:
https://www.hiascend.com/document/detail/zh/Pytorch/720/configandinstg/instg/insg_0004.html
其中8.3rc1和rc2可以通用。
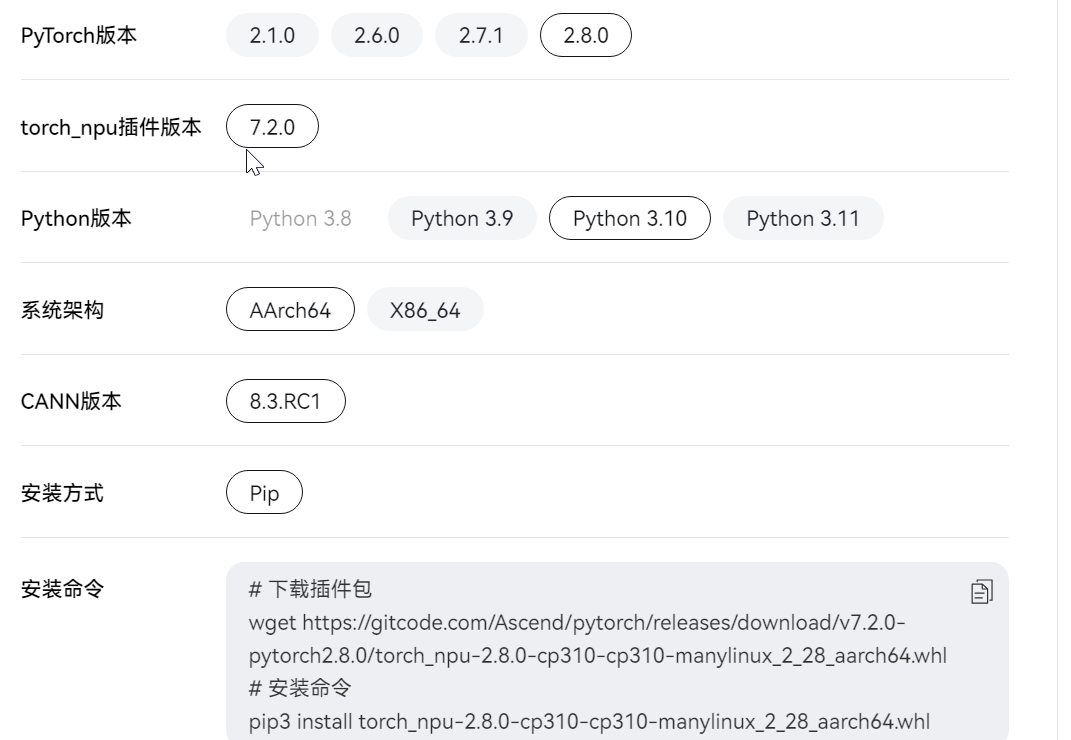
 然后安装npu-插件
然后安装npu-插件
安装完了以后,测试安装效果
python3 -c "import torch;import torch_npu; a = torch.randn(3, 4).npu(); print(a + a);"然后安装vllm

安装完了vllm以后呢,torch会被重新装一下,版本可能和你的驱动不搭配。所以
这一步,需要按照第2步重新装一下torch和torch-npu
然后vllm-ascend版本和vllm版本要对照。
然后就结束了。大功告成。
(根据本人的经验,vllm0.11比0.12要快一些。)
4)vllm起量化模型。
vllm serve ./model_path --served-model-name qwen_quant --quantization ascend --max-model-len 90000 --port 8999 访问vllm接口:
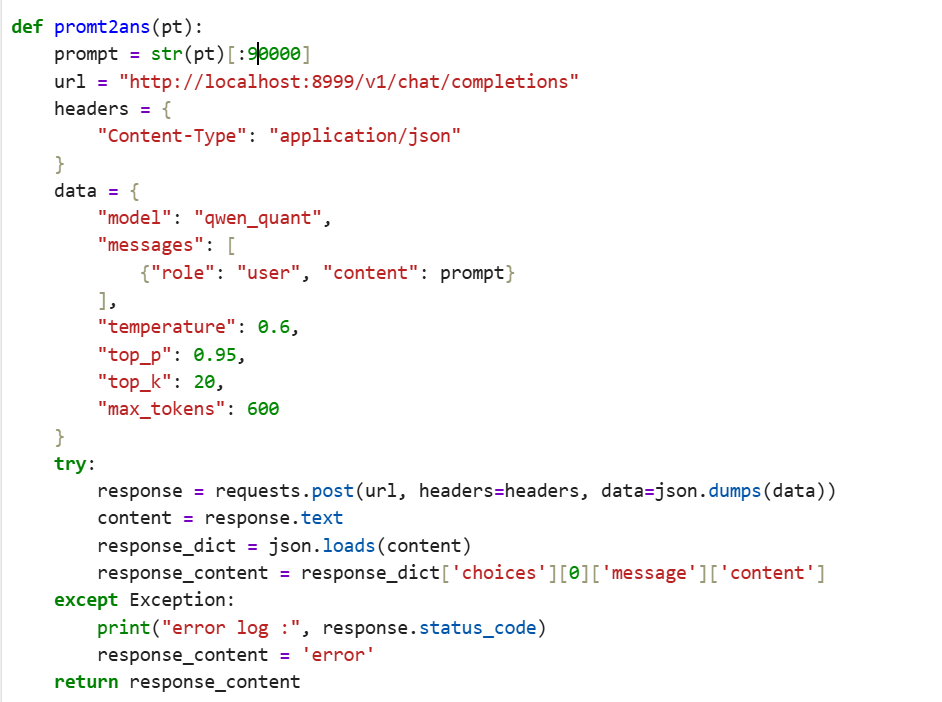
为什么要截取90000,因为如果请求超过vllm的max_len 会报错,所以最好限制一下,不要超过vllm起服务时候的最大长度。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)