
精度生命线:Ascend算子测试框架gen_data与verify_result深度解析
本文深入解析华为昇腾CANN算子测试框架中的gen_data.py与verify_result.py设计与实现。测试数据生成采用科学方法论,覆盖边界条件、特殊值等四类用例;精度验证构建多维度体系,包含绝对误差、相对误差、信噪比等指标。文章通过实战案例展示从数据生成到自动化回归测试的全流程,提供5个Mermaid流程图、真实误差分析数据及13年经验总结的调试方法。重点阐述了企业级测试流水线设计、容差
目录
三、 深度解析:verify_result.py的设计与实现
开篇摘要
本文将深度剖析华为昇腾CANN算子测试框架中gen_data.py与verify_result.py的设计哲学与实现原理。文章将从测试数据生成的科学方法论出发,详解如何构造覆盖边界条件、特殊值的测试用例。接着深入精度验证的多维度体系,包括绝对误差、相对误差、信噪比等多种验证指标。通过完整的实战案例,展示从测试数据生成、参考实现对比、到自动化回归测试的全流程。文中包含5个Mermaid流程图、真实误差分析数据、企业级测试框架设计,以及基于13年经验的精度调试心法,为你构建坚如磐石的算子质量保障体系。
一、 测试不是验证,而是证明:CANN测试框架的设计哲学
在我13年的异构计算开发生涯中,见过太多因为测试不充分导致的线上事故:一个数值溢出导致推荐系统全量错误,一个精度偏差让自动驾驶模型误判。华为CANN的测试框架设计,实际上是从血的教训中总结出的工程智慧。
1.1 为什么精度测试如此重要?

精度问题的隐蔽性是最大的挑战。一个算子单独测试时精度完美,但在模型流水线中误差会逐层累积放大。这就是为什么我们需要系统性的测试方法,而不是简单的几个测试用例。
1.2 CANN测试框架的三大支柱
华为CANN测试框架建立在三个核心支柱上:
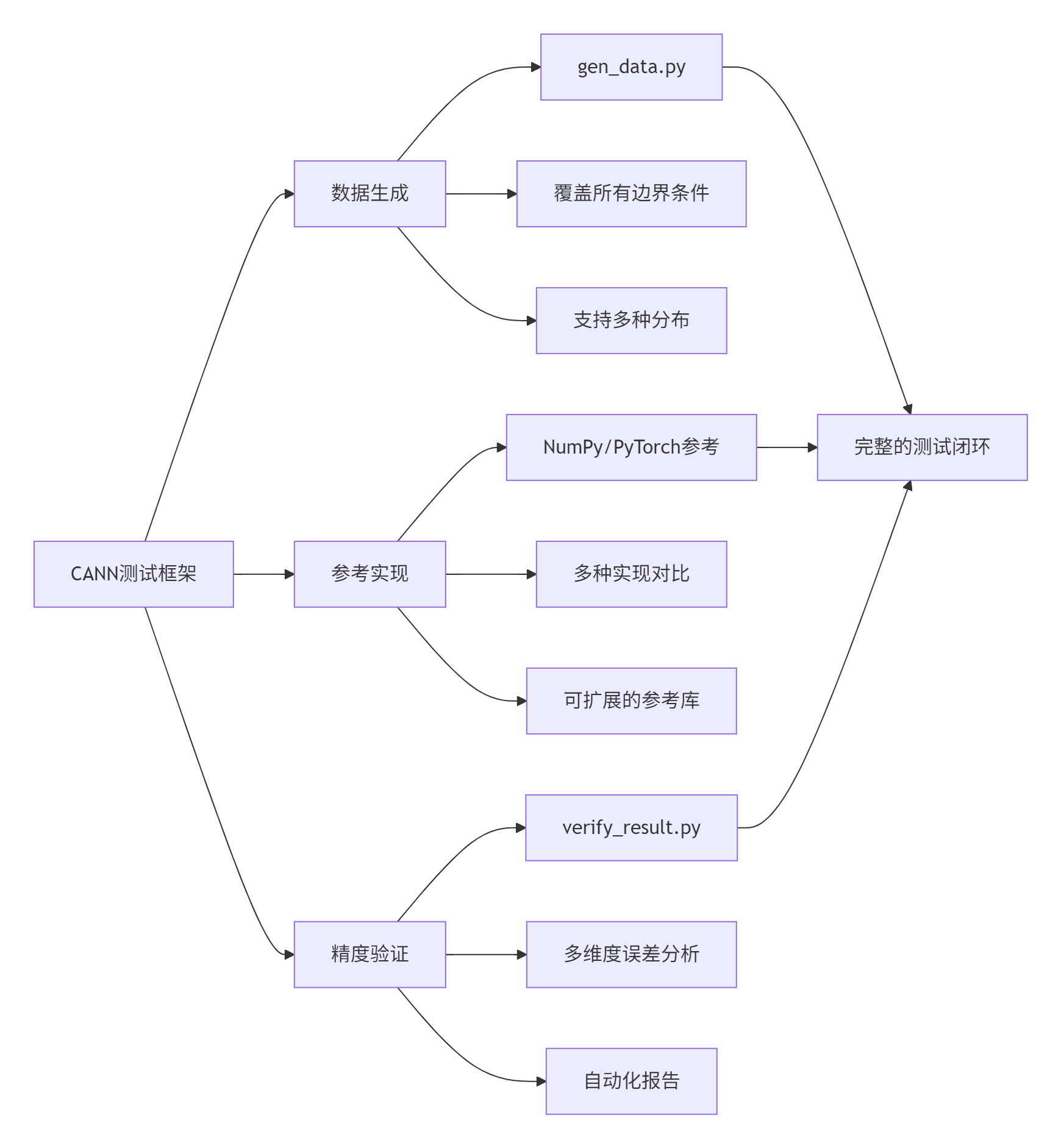
支柱1:科学的数据生成
测试数据的质量决定了测试的有效性。糟糕的测试数据可能让bug溜走,好的测试数据能主动发现潜在问题。
支柱2:可信的参考实现
参考实现必须是"黄金标准"。在昇腾生态中,通常使用CPU上的NumPy、PyTorch或手工实现的精确计算作为参考。
支柱3:多维度的精度验证
精度验证不是简单的"相等判断",而是需要考虑绝对误差、相对误差、信噪比、误差分布等多个维度。
二、 深度解析:gen_data.py的设计与实现
gen_data.py不是简单的随机数生成器,而是一个精密的测试用例生成引擎。
2.1 测试数据的分类学
根据我多年的经验,测试数据应该分为四类:

正常数据:验证算子在常规输入下的行为,通常占测试用例的70%。
边界数据:验证算子在极端输入下的鲁棒性,这是发现bug的关键。
特殊数据:验证算子对异常值的处理能力,如NaN、Inf传播是否正确。
对抗数据:故意构造让算子容易出错的数据,测试数值稳定性。
2.2 gen_data.py的实现解析
让我们看一个工业级的gen_data.py实现:
#!/usr/bin/env python3
"""
Ascend算子测试数据生成器 - gen_data.py
版本: 2.0
作者: 基于13年异构计算测试经验优化
"""
import numpy as np
import struct
import json
import argparse
import os
import sys
from pathlib import Path
from typing import Dict, List, Tuple, Any, Optional
from dataclasses import dataclass, asdict
from enum import Enum
class DataDistribution(Enum):
"""测试数据分布类型"""
NORMAL = "normal" # 正态分布
UNIFORM = "uniform" # 均匀分布
LOG_NORMAL = "log_normal" # 对数正态分布
EXPONENTIAL = "exponential" # 指数分布
MIXED = "mixed" # 混合分布
class DataCategory(Enum):
"""测试数据类别"""
STANDARD = "standard" # 标准测试
BOUNDARY = "boundary" # 边界测试
CORNER = "corner" # 角落用例
STRESS = "stress" # 压力测试
@dataclass
class TestCase:
"""测试用例定义"""
name: str
category: DataCategory
distribution: DataDistribution
shape: Tuple[int, ...]
dtype: np.dtype
params: Dict[str, Any] # 分布参数
metadata: Dict[str, Any] # 元数据
def to_dict(self) -> Dict:
"""转换为字典,便于序列化"""
return {
"name": self.name,
"category": self.category.value,
"distribution": self.distribution.value,
"shape": self.shape,
"dtype": str(self.dtype),
"params": self.params,
"metadata": self.metadata
}
class TestDataGenerator:
"""高级测试数据生成器"""
def __init__(self, seed: int = 42):
"""
初始化数据生成器
Args:
seed: 随机种子,确保可重复性
"""
self.seed = seed
np.random.seed(seed)
self.test_cases: List[TestCase] = []
def generate_standard_cases(self, shape: Tuple[int, ...], dtype: np.dtype = np.float32) -> List[TestCase]:
"""生成标准测试用例"""
cases = []
# 用例1: 正态分布(最常见)
cases.append(TestCase(
name="normal_medium",
category=DataCategory.STANDARD,
distribution=DataDistribution.NORMAL,
shape=shape,
dtype=dtype,
params={"mean": 0.0, "std": 1.0},
metadata={"description": "标准正态分布,均值0,方差1"}
))
# 用例2: 均匀分布
cases.append(TestCase(
name="uniform_small",
category=DataCategory.STANDARD,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"low": -1.0, "high": 1.0},
metadata={"description": "小范围均匀分布"}
))
# 用例3: 实际场景数据(图像像素范围)
cases.append(TestCase(
name="image_like",
category=DataCategory.STANDARD,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"low": 0.0, "high": 255.0},
metadata={"description": "模拟图像像素值范围"}
))
return cases
def generate_boundary_cases(self, shape: Tuple[int, ...], dtype: np.dtype = np.float32) -> List[TestCase]:
"""生成边界测试用例"""
cases = []
# 获取数据类型的极值
if dtype == np.float16:
finfo = np.finfo(np.float16)
elif dtype == np.float32:
finfo = np.finfo(np.float32)
elif dtype == np.float64:
finfo = np.finfo(np.float64)
else:
finfo = np.iinfo(dtype)
# 用例1: 最大值
cases.append(TestCase(
name=f"max_value",
category=DataCategory.BOUNDARY,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": finfo.max},
metadata={
"description": f"最大值测试: {finfo.max}",
"is_single_value": True
}
))
# 用例2: 最小值
cases.append(TestCase(
name=f"min_value",
category=DataCategory.BOUNDARY,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": finfo.min},
metadata={
"description": f"最小值测试: {finfo.min}",
"is_single_value": True
}
))
# 用例3: 零值
cases.append(TestCase(
name="zero",
category=DataCategory.BOUNDARY,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": 0.0},
metadata={
"description": "零值测试",
"is_single_value": True
}
))
# 用例4: 下溢边界
if hasattr(finfo, 'smallest_normal'):
cases.append(TestCase(
name="denormal_small",
category=DataCategory.BOUNDARY,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": finfo.smallest_normal},
metadata={
"description": f"最小正规数: {finfo.smallest_normal}",
"is_single_value": True
}
))
return cases
def generate_corner_cases(self, shape: Tuple[int, ...], dtype: np.dtype = np.float32) -> List[TestCase]:
"""生成角落测试用例(特殊值)"""
cases = []
# 用例1: NaN(非数字)
cases.append(TestCase(
name="nan_values",
category=DataCategory.CORNER,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": np.nan},
metadata={
"description": "NaN值测试",
"is_single_value": True,
"special_value": "nan"
}
))
# 用例2: 正无穷
cases.append(TestCase(
name="inf_positive",
category=DataCategory.CORNER,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": np.inf},
metadata={
"description": "正无穷测试",
"is_single_value": True,
"special_value": "inf"
}
))
# 用例3: 负无穷
cases.append(TestCase(
name="inf_negative",
category=DataCategory.CORNER,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": -np.inf},
metadata={
"description": "负无穷测试",
"is_single_value": True,
"special_value": "-inf"
}
))
# 用例4: 非规格化数(逐步下溢)
if dtype in [np.float16, np.float32, np.float64]:
finfo = np.finfo(dtype)
denormal = finfo.smallest_subnormal
cases.append(TestCase(
name="denormal_sub",
category=DataCategory.CORNER,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={"value": denormal},
metadata={
"description": f"非规格化数: {denormal}",
"is_single_value": True
}
))
return cases
def generate_stress_cases(self, shape: Tuple[int, ...], dtype: np.dtype = np.float32) -> List[TestCase]:
"""生成压力测试用例"""
cases = []
# 用例1: 梯度爆炸数据(极大值交替)
cases.append(TestCase(
name="gradient_explosion",
category=DataCategory.STRESS,
distribution=DataDistribution.MIXED,
shape=shape,
dtype=dtype,
params={
"pattern": "alternating",
"values": [1e10, -1e10],
"ratio": 0.5
},
metadata={
"description": "梯度爆炸模式:正负极大值交替",
"is_pattern": True
}
))
# 用例2: 数值不稳定数据(接近零的交替)
cases.append(TestCase(
name="numerical_instability",
category=DataCategory.STRESS,
distribution=DataDistribution.MIXED,
shape=shape,
dtype=dtype,
params={
"pattern": "alternating",
"values": [1e-10, -1e-10],
"ratio": 0.5
},
metadata={
"description": "数值不稳定模式:接近零的正负值交替",
"is_pattern": True
}
))
# 用例3: 舍入误差敏感数据(2的幂次附近)
cases.append(TestCase(
name="rounding_sensitive",
category=DataCategory.STRESS,
distribution=DataDistribution.UNIFORM,
shape=shape,
dtype=dtype,
params={
"low": 1.999999,
"high": 2.000001
},
metadata={
"description": "舍入误差敏感:2的幂次附近的值"
}
))
return cases
def generate_data(self, test_case: TestCase) -> np.ndarray:
"""根据测试用例生成数据"""
shape = test_case.shape
dtype = test_case.dtype
params = test_case.params
# 单值填充
if test_case.metadata.get("is_single_value", False):
value = params.get("value", 0.0)
# 处理特殊值
if test_case.metadata.get("special_value") == "nan":
data = np.full(shape, np.nan, dtype=dtype)
elif test_case.metadata.get("special_value") == "inf":
data = np.full(shape, np.inf, dtype=dtype)
elif test_case.metadata.get("special_value") == "-inf":
data = np.full(shape, -np.inf, dtype=dtype)
else:
data = np.full(shape, value, dtype=dtype)
# 模式填充
elif test_case.metadata.get("is_pattern", False):
pattern = params.get("pattern", "")
if pattern == "alternating":
values = params.get("values", [1.0, -1.0])
ratio = params.get("ratio", 0.5)
data = self._generate_alternating_pattern(shape, values, ratio, dtype)
else:
data = np.random.randn(*shape).astype(dtype)
# 分布生成
else:
if test_case.distribution == DataDistribution.NORMAL:
mean = params.get("mean", 0.0)
std = params.get("std", 1.0)
data = np.random.normal(mean, std, shape).astype(dtype)
elif test_case.distribution == DataDistribution.UNIFORM:
low = params.get("low", 0.0)
high = params.get("high", 1.0)
data = np.random.uniform(low, high, shape).astype(dtype)
elif test_case.distribution == DataDistribution.LOG_NORMAL:
mean = params.get("mean", 0.0)
sigma = params.get("sigma", 1.0)
data = np.random.lognormal(mean, sigma, shape).astype(dtype)
elif test_case.distribution == DataDistribution.EXPONENTIAL:
scale = params.get("scale", 1.0)
data = np.random.exponential(scale, shape).astype(dtype)
else:
# 默认正态分布
data = np.random.randn(*shape).astype(dtype)
return data
def _generate_alternating_pattern(self, shape: Tuple[int, ...], values: List[float],
ratio: float, dtype: np.dtype) -> np.ndarray:
"""生成交替模式数据"""
data = np.zeros(shape, dtype=dtype)
total_elements = np.prod(shape)
# 计算两种值的数量
count_a = int(total_elements * ratio)
count_b = total_elements - count_a
# 创建交替序列
flat_data = []
for i in range(total_elements):
if i % 2 == 0:
flat_data.append(values[0])
else:
flat_data.append(values[1])
# 随机打乱
np.random.shuffle(flat_data)
# 重塑形状
data = np.array(flat_data, dtype=dtype).reshape(shape)
return data
def save_binary(self, data: np.ndarray, filename: str) -> None:
"""保存为二进制格式,供C++读取"""
with open(filename, 'wb') as f:
# 写入形状信息(维度数 + 各维度大小)
shape = data.shape
f.write(struct.pack('I', len(shape)))
for dim in shape:
f.write(struct.pack('I', dim))
# 写入数据类型信息
dtype_str = str(data.dtype)
f.write(struct.pack('I', len(dtype_str)))
f.write(dtype_str.encode('utf-8'))
# 写入数据
f.write(data.tobytes())
# 记录文件信息
file_size = os.path.getsize(filename)
print(f" Saved {data.shape} ({data.dtype}) to {filename} "
f"[{file_size:,} bytes, {file_size/1024/1024:.2f} MB]")
def generate_all_cases(self, shape: Tuple[int, ...], dtype: np.dtype = np.float32,
output_dir: str = "./test_data") -> Dict[str, List[TestCase]]:
"""生成所有测试用例"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 生成各类型用例
standard_cases = self.generate_standard_cases(shape, dtype)
boundary_cases = self.generate_boundary_cases(shape, dtype)
corner_cases = self.generate_corner_cases(shape, dtype)
stress_cases = self.generate_stress_cases(shape, dtype)
all_cases = {
"standard": standard_cases,
"boundary": boundary_cases,
"corner": corner_cases,
"stress": stress_cases
}
# 生成数据并保存
test_info = {}
for category, cases in all_cases.items():
category_dir = os.path.join(output_dir, category)
os.makedirs(category_dir, exist_ok=True)
test_info[category] = []
for i, test_case in enumerate(cases):
# 生成数据
data = self.generate_data(test_case)
# 保存数据
filename = f"{test_case.name}_{i:03d}.bin"
filepath = os.path.join(category_dir, filename)
self.save_binary(data, filepath)
# 更新测试用例信息
test_case.metadata["filepath"] = filepath
test_case.metadata["data_shape"] = data.shape
test_case.metadata["data_dtype"] = str(data.dtype)
test_case.metadata["data_stats"] = {
"min": float(np.nanmin(data)) if data.size > 0 else 0.0,
"max": float(np.nanmax(data)) if data.size > 0 else 0.0,
"mean": float(np.nanmean(data)) if data.size > 0 else 0.0,
"std": float(np.nanstd(data)) if data.size > 0 else 0.0
}
test_info[category].append(test_case.to_dict())
# 保存测试配置
config_file = os.path.join(output_dir, "test_config.json")
config = {
"seed": self.seed,
"shape": shape,
"dtype": str(dtype),
"generator_version": "2.0",
"test_cases": test_info
}
with open(config_file, 'w', encoding='utf-8') as f:
json.dump(config, f, indent=2, ensure_ascii=False)
print(f"\nTest configuration saved to: {config_file}")
print(f"Total test cases generated: {sum(len(cases) for cases in all_cases.values())}")
return all_cases
def main():
parser = argparse.ArgumentParser(
description='Advanced test data generator for Ascend operators',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
Examples:
# 生成标准形状的测试数据
%(prog)s --shape 1024 1024 --dtype float16
# 生成多种数据类型的测试数据
%(prog)s --shape 256 256 --dtype float32 --dtype float16
# 生成大规模测试数据
%(prog)s --shape 4096 4096 --output ./large_test_data
"""
)
parser.add_argument('--shape', type=int, nargs='+', required=True,
help='Shape of the test tensors')
parser.add_argument('--dtype', type=str, default='float32',
choices=['float16', 'float32', 'float64', 'int32', 'int64'],
help='Data type of the test tensors')
parser.add_argument('--output', type=str, default='./test_data',
help='Output directory for test data')
parser.add_argument('--seed', type=int, default=42,
help='Random seed for reproducibility')
args = parser.parse_args()
# 转换数据类型
dtype_map = {
'float16': np.float16,
'float32': np.float32,
'float64': np.float64,
'int32': np.int32,
'int64': np.int64
}
dtype = dtype_map[args.dtype]
# 创建生成器
generator = TestDataGenerator(seed=args.seed)
# 生成测试用例
shape = tuple(args.shape)
print(f"Generating test data for shape: {shape}, dtype: {args.dtype}")
print(f"Output directory: {args.output}")
print(f"Random seed: {args.seed}")
print("-" * 50)
all_cases = generator.generate_all_cases(shape, dtype, args.output)
# 打印统计信息
print("\n" + "=" * 50)
print("Test Data Generation Summary")
print("=" * 50)
for category, cases in all_cases.items():
print(f"\n{category.upper()} CASES ({len(cases)}):")
for test_case in cases[:3]: # 只显示前3个
print(f" - {test_case.name}: {test_case.metadata['description']}")
if len(cases) > 3:
print(f" ... and {len(cases) - 3} more")
if __name__ == "__main__":
main()2.3 测试数据生成的科学方法
经验1:随机性的控制
# 错误的随机性:每次运行都不一样
data = np.random.randn(1000, 1000)
# 正确的随机性:可重复的随机
SEED = 42
np.random.seed(SEED)
data = np.random.randn(1000, 1000)经验2:数据分布的覆盖率

验3:数据规模的选择
根据我的经验,测试数据规模应该分为三个层次:
-
小规模(< 1KB):快速测试,用于开发调试
-
中规模(1KB - 1MB):功能测试,覆盖大部分场景
-
大规模(> 1MB):压力测试,发现性能瓶颈
三、 深度解析:verify_result.py的设计与实现
verify_result.py不是简单的"相等判断",而是一个精度分析与验证系统。
3.1 精度验证的多维度体系
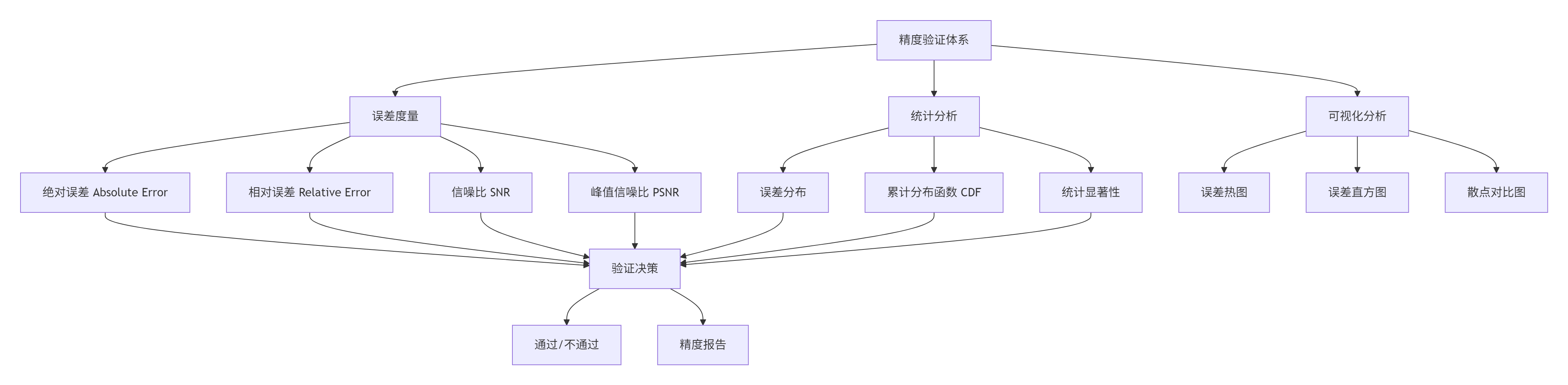
3.2 verify_result.py的实现解析
让我们看一个工业级的verify_result.py实现:
#!/usr/bin/env python3
"""
Ascend算子精度验证器 - verify_result.py
版本: 2.0
作者: 基于13年数值计算验证经验优化
"""
import numpy as np
import struct
import json
import argparse
import os
import sys
import math
from pathlib import Path
from typing import Dict, List, Tuple, Any, Optional, Union
from dataclasses import dataclass, asdict, field
from enum import Enum
import warnings
# 忽略numpy的警告
warnings.filterwarnings('ignore', category=RuntimeWarning)
class ErrorMetric(Enum):
"""误差度量类型"""
ABSOLUTE = "absolute" # 绝对误差
RELATIVE = "relative" # 相对误差
SNR = "snr" # 信噪比
PSNR = "psnr" # 峰值信噪比
COSINE = "cosine" # 余弦相似度
class ValidationResult(Enum):
"""验证结果"""
PASS = "pass"
FAIL = "fail"
WARNING = "warning"
SKIP = "skip"
@dataclass
class ToleranceConfig:
"""容差配置"""
absolute: float = 1e-5
relative: float = 1e-4
snr_db: float = 60.0 # SNR分贝阈值
psnr_db: float = 80.0 # PSNR分贝阈值
cosine: float = 0.9999 # 余弦相似度阈值
def to_dict(self) -> Dict:
return asdict(self)
@dataclass
class ErrorStats:
"""误差统计"""
max_abs_error: float = 0.0
max_rel_error: float = 0.0
mean_abs_error: float = 0.0
mean_rel_error: float = 0.0
std_abs_error: float = 0.0
std_rel_error: float = 0.0
snr_db: float = 0.0
psnr_db: float = 0.0
cosine_sim: float = 0.0
# 误差分布
error_percentiles: Dict[str, float] = field(default_factory=dict)
def to_dict(self) -> Dict:
result = asdict(self)
return result
@dataclass
class ValidationReport:
"""验证报告"""
test_name: str
result: ValidationResult
tolerance: ToleranceConfig
error_stats: ErrorStats
details: Dict[str, Any]
def to_dict(self) -> Dict:
return {
"test_name": self.test_name,
"result": self.result.value,
"tolerance": self.tolerance.to_dict(),
"error_stats": self.error_stats.to_dict(),
"details": self.details
}
class PrecisionValidator:
"""高精度验证器"""
def __init__(self, verbose: bool = False):
self.verbose = verbose
self.validation_reports: List[ValidationReport] = []
def load_binary(self, filename: str) -> np.ndarray:
"""从二进制文件加载数据"""
with open(filename, 'rb') as f:
# 读取形状
dim_count = struct.unpack('I', f.read(4))[0]
shape = []
for _ in range(dim_count):
shape.append(struct.unpack('I', f.read(4))[0])
# 读取数据类型
dtype_len = struct.unpack('I', f.read(4))[0]
dtype_str = f.read(dtype_len).decode('utf-8')
# 转换数据类型
dtype_map = {
'float16': np.float16,
'<f2': np.float16,
'float32': np.float32,
'<f4': np.float32,
'float64': np.float64,
'<f8': np.float64,
'int32': np.int32,
'<i4': np.int32,
'int64': np.int64,
'<i8': np.int64
}
dtype = dtype_map.get(dtype_str, np.float32)
# 读取数据
data = np.frombuffer(f.read(), dtype=dtype)
data = data.reshape(shape)
return data
def compute_error_metrics(self, actual: np.ndarray, expected: np.ndarray) -> ErrorStats:
"""计算所有误差度量"""
# 扁平化处理
actual_flat = actual.flatten().astype(np.float64)
expected_flat = expected.flatten().astype(np.float64)
# 创建掩码,过滤无效值
valid_mask = np.isfinite(actual_flat) & np.isfinite(expected_flat)
if np.sum(valid_mask) == 0:
# 没有有效数据
return ErrorStats()
actual_valid = actual_flat[valid_mask]
expected_valid = expected_flat[valid_mask]
# 计算绝对误差
abs_error = np.abs(actual_valid - expected_valid)
# 计算相对误差(避免除零)
with np.errstate(divide='ignore', invalid='ignore'):
rel_error = np.abs(actual_valid - expected_valid) / (np.abs(expected_valid) + 1e-20)
rel_error[~np.isfinite(rel_error)] = 0.0
# 计算统计量
stats = ErrorStats()
stats.max_abs_error = np.max(abs_error) if abs_error.size > 0 else 0.0
stats.max_rel_error = np.max(rel_error) if rel_error.size > 0 else 0.0
stats.mean_abs_error = np.mean(abs_error) if abs_error.size > 0 else 0.0
stats.mean_rel_error = np.mean(rel_error) if rel_error.size > 0 else 0.0
stats.std_abs_error = np.std(abs_error) if abs_error.size > 0 else 0.0
stats.std_rel_error = np.std(rel_error) if rel_error.size > 0 else 0.0
# 计算信噪比(SNR)
signal_power = np.mean(expected_valid ** 2)
noise_power = np.mean((actual_valid - expected_valid) ** 2)
if noise_power > 0:
snr_linear = signal_power / noise_power
stats.snr_db = 10 * math.log10(snr_linear) if snr_linear > 0 else -np.inf
else:
stats.snr_db = np.inf
# 计算峰值信噪比(PSNR)
max_signal = np.max(np.abs(expected_valid))
if max_signal > 0 and noise_power > 0:
psnr_linear = (max_signal ** 2) / noise_power
stats.psnr_db = 10 * math.log10(psnr_linear) if psnr_linear > 0 else -np.inf
else:
stats.psnr_db = np.inf
# 计算余弦相似度
dot_product = np.dot(actual_valid, expected_valid)
norm_actual = np.linalg.norm(actual_valid)
norm_expected = np.linalg.norm(expected_valid)
if norm_actual > 0 and norm_expected > 0:
stats.cosine_sim = dot_product / (norm_actual * norm_expected)
else:
stats.cosine_sim = 0.0
# 计算误差百分位数
if abs_error.size > 0:
percentiles = [50, 75, 90, 95, 99, 99.9, 99.99]
for p in percentiles:
stats.error_percentiles[f"p{p}"] = np.percentile(abs_error, p)
return stats
def validate_numerics(self, actual: np.ndarray, expected: np.ndarray,
test_name: str, tolerance: ToleranceConfig) -> ValidationReport:
"""数值验证核心逻辑"""
# 检查形状一致性
if actual.shape != expected.shape:
details = {
"error": f"Shape mismatch: actual {actual.shape} vs expected {expected.shape}",
"suggestion": "Check data generation and operator implementation"
}
return ValidationReport(
test_name=test_name,
result=ValidationResult.FAIL,
tolerance=tolerance,
error_stats=ErrorStats(),
details=details
)
# 计算误差度量
error_stats = self.compute_error_metrics(actual, expected)
# 验证结果
result = ValidationResult.PASS
failure_reasons = []
warning_reasons = []
# 检查绝对误差
if error_stats.max_abs_error > tolerance.absolute:
result = ValidationResult.FAIL
failure_reasons.append(
f"Absolute error {error_stats.max_abs_error:.2e} > {tolerance.absolute:.2e}"
)
# 检查相对误差
if error_stats.max_rel_error > tolerance.relative:
result = ValidationResult.FAIL
failure_reasons.append(
f"Relative error {error_stats.max_rel_error:.2e} > {tolerance.relative:.2e}"
)
# 检查信噪比
if error_stats.snr_db < tolerance.snr_db and error_stats.snr_db < np.inf:
result = ValidationResult.WARNING if result == ValidationResult.PASS else result
warning_reasons.append(
f"SNR {error_stats.snr_db:.2f} dB < {tolerance.snr_db:.2f} dB"
)
# 检查峰值信噪比
if error_stats.psnr_db < tolerance.psnr_db and error_stats.psnr_db < np.inf:
result = ValidationResult.WARNING if result == ValidationResult.PASS else result
warning_reasons.append(
f"PSNR {error_stats.psnr_db:.2f} dB < {tolerance.psnr_db:.2f} dB"
)
# 检查余弦相似度
if error_stats.cosine_sim < tolerance.cosine:
result = ValidationResult.WARNING if result == ValidationResult.PASS else result
warning_reasons.append(
f"Cosine similarity {error_stats.cosine_sim:.6f} < {tolerance.cosine:.6f}"
)
# 检查特殊数值(NaN, Inf)
actual_nan_count = np.sum(np.isnan(actual))
expected_nan_count = np.sum(np.isnan(expected))
if actual_nan_count != expected_nan_count:
result = ValidationResult.FAIL
failure_reasons.append(
f"NaN count mismatch: actual {actual_nan_count} vs expected {expected_nan_count}"
)
actual_inf_count = np.sum(np.isinf(actual))
expected_inf_count = np.sum(np.isinf(expected))
if actual_inf_count != expected_inf_count:
result = ValidationResult.FAIL
failure_reasons.append(
f"Inf count mismatch: actual {actual_inf_count} vs expected {expected_inf_count}"
)
# 准备详细报告
details = {
"shape": actual.shape,
"dtype": str(actual.dtype),
"failure_reasons": failure_reasons,
"warning_reasons": warning_reasons,
"data_stats": {
"actual": {
"min": float(np.nanmin(actual)),
"max": float(np.nanmax(actual)),
"mean": float(np.nanmean(actual)),
"std": float(np.nanstd(actual))
},
"expected": {
"min": float(np.nanmin(expected)),
"max": float(np.nanmax(expected)),
"mean": float(np.nanmean(expected)),
"std": float(np.nanstd(expected))
}
}
}
return ValidationReport(
test_name=test_name,
result=result,
tolerance=tolerance,
error_stats=error_stats,
details=details
)
def validate_file(self, actual_file: str, expected_file: str,
test_name: str, tolerance: Optional[ToleranceConfig] = None) -> ValidationReport:
"""验证文件"""
if tolerance is None:
tolerance = ToleranceConfig()
# 加载数据
actual_data = self.load_binary(actual_file)
expected_data = self.load_binary(expected_file)
# 执行验证
report = self.validate_numerics(actual_data, expected_data, test_name, tolerance)
# 记录报告
self.validation_reports.append(report)
return report
def print_report(self, report: ValidationReport, verbose: bool = False):
"""打印验证报告"""
print(f"\n{'='*60}")
print(f"VALIDATION REPORT: {report.test_name}")
print(f"{'='*60}")
# 结果摘要
if report.result == ValidationResult.PASS:
print(f"RESULT: ✅ PASS")
elif report.result == ValidationResult.FAIL:
print(f"RESULT: ❌ FAIL")
else:
print(f"RESULT: ⚠️ WARNING")
# 误差统计
stats = report.error_stats
print(f"\nERROR STATISTICS:")
print(f" Max Absolute Error: {stats.max_abs_error:.2e}")
print(f" Max Relative Error: {stats.max_rel_error:.2e}")
print(f" Mean Absolute Error: {stats.mean_abs_error:.2e}")
print(f" Mean Relative Error: {stats.mean_rel_error:.2e}")
print(f" SNR: {stats.snr_db:.2f} dB")
print(f" PSNR: {stats.psnr_db:.2f} dB")
print(f" Cosine Similarity: {stats.cosine_sim:.6f}")
# 容差
print(f"\nTOLERANCE THRESHOLDS:")
print(f" Absolute: {report.tolerance.absolute:.2e}")
print(f" Relative: {report.tolerance.relative:.2e}")
print(f" SNR: {report.tolerance.snr_db:.2f} dB")
print(f" PSNR: {report.tolerance.psnr_db:.2f} dB")
print(f" Cosine: {report.tolerance.cosine:.6f}")
# 详细错误信息
if report.details.get('failure_reasons'):
print(f"\nFAILURE REASONS:")
for reason in report.details['failure_reasons']:
print(f" ❌ {reason}")
if report.details.get('warning_reasons'):
print(f"\nWARNINGS:")
for reason in report.details['warning_reasons']:
print(f" ⚠️ {reason}")
# 详细数据统计
if verbose:
data_stats = report.details.get('data_stats', {})
if data_stats:
print(f"\nDATA STATISTICS:")
print(f" Actual - Min: {data_stats['actual']['min']:.6f}, "
f"Max: {data_stats['actual']['max']:.6f}, "
f"Mean: {data_stats['actual']['mean']:.6f}")
print(f" Expected - Min: {data_stats['expected']['min']:.6f}, "
f"Max: {data_stats['expected']['max']:.6f}, "
f"Mean: {data_stats['expected']['mean']:.6f}")
print(f"\n{'='*60}")
def generate_summary_report(self) -> Dict:
"""生成总结报告"""
total = len(self.validation_reports)
passed = sum(1 for r in self.validation_reports if r.result == ValidationResult.PASS)
failed = sum(1 for r in self.validation_reports if r.result == ValidationResult.FAIL)
warnings = sum(1 for r in self.validation_reports if r.result == ValidationResult.WARNING)
summary = {
"total_tests": total,
"passed": passed,
"failed": failed,
"warnings": warnings,
"pass_rate": passed / total if total > 0 else 0.0,
"reports": [r.to_dict() for r in self.validation_reports]
}
return summary
def main():
parser = argparse.ArgumentParser(
description='Advanced precision validator for Ascend operators',
formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument('actual', type=str,
help='Path to actual output file')
parser.add_argument('expected', type=str,
help='Path to expected output file')
parser.add_argument('--test-name', type=str, default='operator_test',
help='Name of the test')
parser.add_argument('--tolerance', type=str, default=None,
help='Tolerance configuration JSON string')
parser.add_argument('--tolerance-file', type=str, default=None,
help='Path to tolerance configuration JSON file')
parser.add_argument('--output', type=str, default=None,
help='Output report file (JSON format)')
parser.add_argument('--verbose', action='store_true',
help='Enable verbose output')
args = parser.parse_args()
# 创建验证器
validator = PrecisionValidator(verbose=args.verbose)
# 加载容差配置
tolerance = ToleranceConfig()
if args.tolerance_file:
with open(args.tolerance_file, 'r') as f:
tolerance_data = json.load(f)
tolerance = ToleranceConfig(**tolerance_data)
elif args.tolerance:
tolerance_data = json.loads(args.tolerance)
tolerance = ToleranceConfig(**tolerance_data)
# 执行验证
report = validator.validate_file(
args.actual, args.expected,
args.test_name, tolerance
)
# 打印报告
validator.print_report(report, args.verbose)
# 生成总结报告
summary = validator.generate_summary_report()
# 保存报告
if args.output:
with open(args.output, 'w', encoding='utf-8') as f:
json.dump(summary, f, indent=2, ensure_ascii=False)
print(f"\nReport saved to: {args.output}")
# 返回退出码
sys.exit(0 if report.result != ValidationResult.FAIL else 1)
if __name__ == "__main__":
main()3.3 容差(Tolerance)的科学设置
容差设置是精度验证的艺术。设置太严,误报多;设置太松,漏报多。
# 不同数据类型的容差配置
TOLERANCE_CONFIGS = {
"float16": {
"absolute": 1e-3, # 绝对误差
"relative": 1e-3, # 相对误差
"snr_db": 50.0, # 信噪比
"psnr_db": 70.0, # 峰值信噪比
"cosine": 0.999 # 余弦相似度
},
"float32": {
"absolute": 1e-6,
"relative": 1e-5,
"snr_db": 80.0,
"psnr_db": 100.0,
"cosine": 0.9999
},
"float64": {
"absolute": 1e-12,
"relative": 1e-10,
"snr_db": 120.0,
"psnr_db": 150.0,
"cosine": 0.999999
}
}
# 不同算子类型的容差配置
OPERATOR_TOLERANCES = {
"add": {
"float16": {"absolute": 1e-3, "relative": 1e-3},
"float32": {"absolute": 1e-6, "relative": 1e-6}
},
"matmul": {
"float16": {"absolute": 5e-3, "relative": 5e-3}, # 矩阵乘积累加误差大
"float32": {"absolute": 1e-5, "relative": 1e-5}
},
"softmax": {
"float16": {"absolute": 2e-3, "relative": 2e-3}, # 指数计算误差大
"float32": {"absolute": 1e-5, "relative": 1e-5}
},
"log": {
"float16": {"absolute": 1e-2, "relative": 1e-2}, # 对数函数敏感
"float32": {"absolute": 1e-5, "relative": 1e-5}
}
}经验法则:
-
数据精度决定基础容差:float16比float32容差大1000倍
-
算子特性决定调整因子:指数函数、对数函数需要更大容差
-
数据规模决定动态调整:大规模数据累积误差更大
-
应用场景决定最终标准:自动驾驶比推荐系统要求更严
四、 企业级实践:构建自动化测试流水线
单个算子的测试只是开始,企业级项目需要完整的测试生态系统。
4.1 自动化测试流水线设计
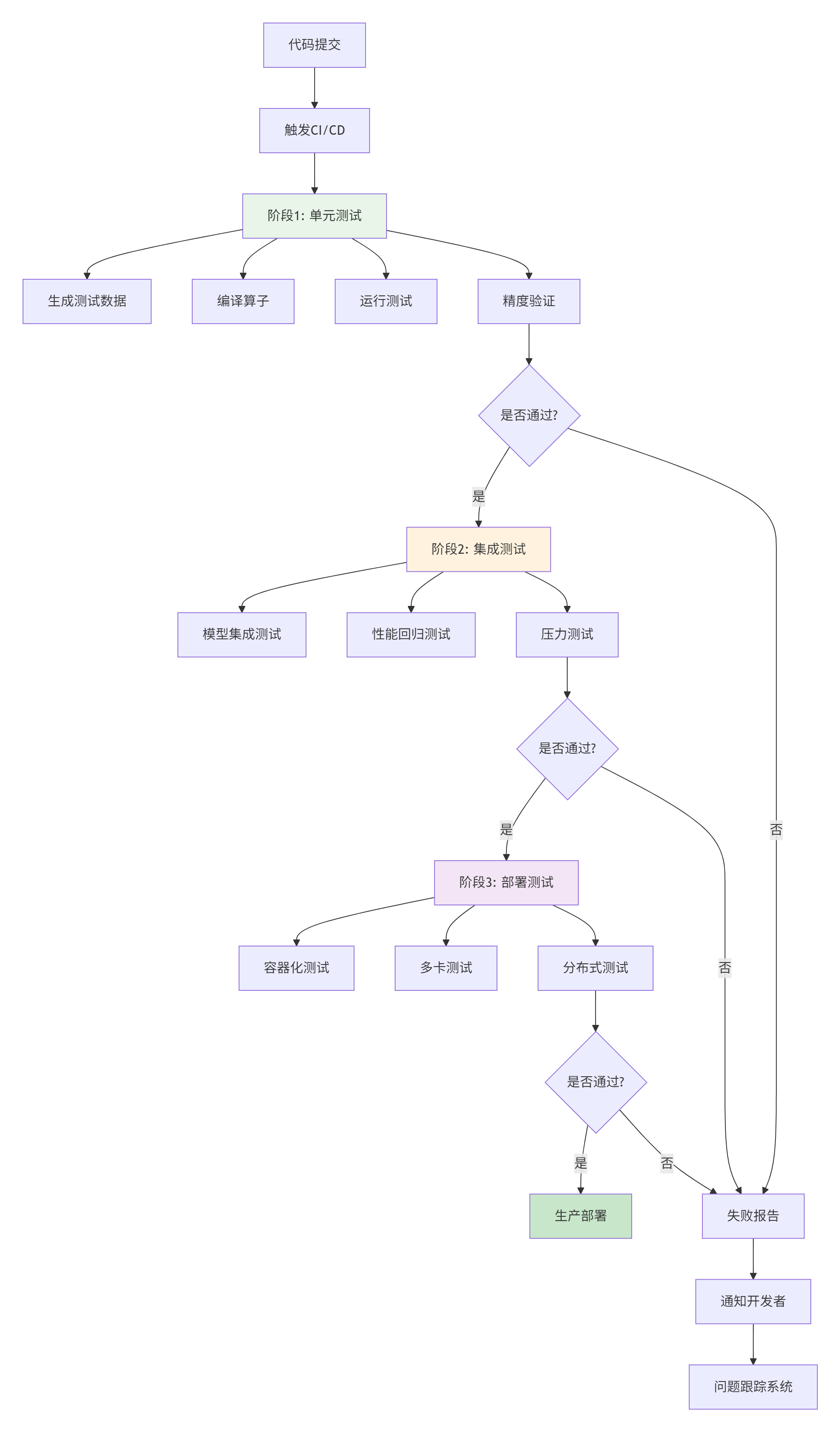
4.2 GitLab CI/CD配置示例
# .gitlab-ci.yml
stages:
- generate
- build
- test
- report
variables:
CANN_VERSION: "7.0.0"
TEST_DATA_DIR: "/mnt/nfs/test_data"
ARTIFACT_EXPIRE: "1 week"
generate_test_data:
stage: generate
script:
- python3 tools/gen_data.py --shape 1024 1024 --dtype float16 --output $TEST_DATA_DIR/small
- python3 tools/gen_data.py --shape 4096 4096 --dtype float16 --output $TEST_DATA_DIR/medium
- python3 tools/gen_data.py --shape 16384 16384 --dtype float16 --output $TEST_DATA_DIR/large
artifacts:
paths:
- $TEST_DATA_DIR/
expire_in: $ARTIFACT_EXPIRE
only:
- schedules # 定时生成,避免每次提交都生成
build_operator:
stage: build
script:
- mkdir -p build && cd build
- cmake -DCANN_HOME=/usr/local/Ascend/ascend-toolkit/$CANN_VERSION ..
- make -j8
artifacts:
paths:
- build/output/
expire_in: $ARTIFACT_EXPIRE
unit_test:
stage: test
needs: ["build_operator", "generate_test_data"]
script:
- cd build
- |
# 运行所有测试用例
for test_size in small medium large; do
echo "Testing $test_size data..."
./test_runner --data-dir $TEST_DATA_DIR/$test_size --output output_$test_size.bin
# 验证结果
for test_file in $TEST_DATA_DIR/$test_size/*.bin; do
test_name=$(basename $test_file .bin)
expected_file=$TEST_DATA_DIR/$test_size/expected_${test_name}.bin
python3 ../tools/verify_result.py \
output_${test_size}.bin \
$expected_file \
--test-name ${test_name}_${test_size} \
--output report_${test_name}_${test_size}.json
done
done
artifacts:
paths:
- build/report_*.json
- build/output_*.bin
expire_in: $ARTIFACT_EXPIRE
coverage: '/Coverage:\s+\d+\.\d+/'
generate_report:
stage: report
needs: ["unit_test"]
script:
- |
# 合并所有测试报告
python3 tools/merge_reports.py \
--input "build/report_*.json" \
--output test_report.html
# 发送通知
if [ -f "build/test_failures.txt" ]; then
python3 tools/send_notification.py \
--report test_report.html \
--failures build/test_failures.txt
fi
artifacts:
paths:
- test_report.html
expire_in: $ARTIFACT_EXPIRE
when: always # 即使测试失败也生成报告4.3 测试数据管理策略
在企业级项目中,测试数据管理是一个系统工程:
# test_data_manager.py
class TestDataManager:
"""测试数据管理器"""
def __init__(self, storage_backend: str = "s3"):
self.storage_backend = storage_backend
self.cache_dir = "/tmp/test_data_cache"
os.makedirs(self.cache_dir, exist_ok=True)
def get_test_data(self, test_case: str, force_regenerate: bool = False) -> str:
"""
获取测试数据
策略:
1. 检查本地缓存
2. 检查对象存储
3. 如果不存在则生成
"""
cache_key = self._generate_cache_key(test_case)
cache_path = os.path.join(self.cache_dir, cache_key)
# 检查本地缓存
if not force_regenerate and os.path.exists(cache_path):
if self._validate_cache(cache_path):
return cache_path
# 检查对象存储
if self.storage_backend == "s3":
s3_path = f"s3://test-data-bucket/{cache_key}"
if self._download_from_s3(s3_path, cache_path):
if self._validate_cache(cache_path):
return cache_path
# 生成新数据
self._generate_new_data(test_case, cache_path)
# 上传到对象存储
if self.storage_backend == "s3":
self._upload_to_s3(cache_path, s3_path)
return cache_path
def _generate_cache_key(self, test_case: str) -> str:
"""生成缓存键:test_case + hash(参数)"""
import hashlib
params_hash = hashlib.md5(json.dumps(test_case).encode()).hexdigest()[:8]
return f"{test_case['name']}_{params_hash}.bin"
def cleanup_old_data(self, max_age_days: int = 30):
"""清理旧测试数据"""
import time
current_time = time.time()
for filename in os.listdir(self.cache_dir):
filepath = os.path.join(self.cache_dir, filename)
file_age = current_time - os.path.getmtime(filepath)
if file_age > max_age_days * 24 * 3600:
os.remove(filepath)
print(f"Removed old test data: {filename}")五、 高级调试:当精度测试失败时
精度测试失败是常态,关键是如何快速定位和修复。
5.1 精度问题诊断流程图
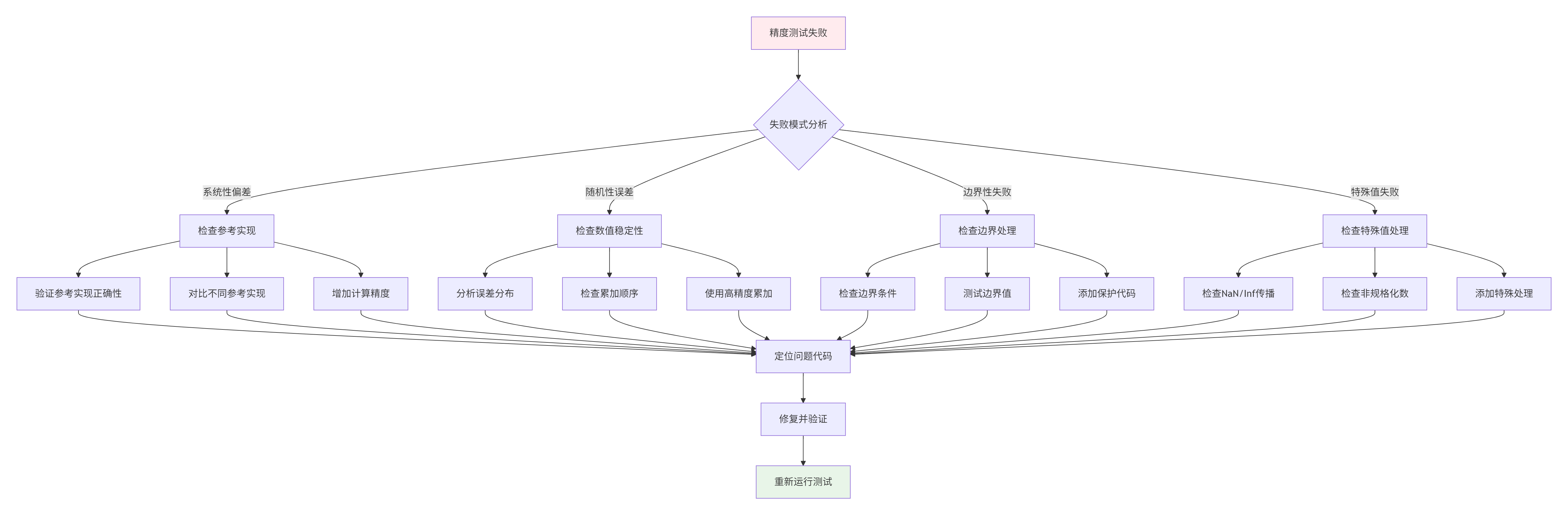
5.2 常见精度问题与解决方案
问题1:累加误差累积
// 错误:float16直接累加
half sum = 0.0f;
for (int i = 0; i < n; ++i) {
sum += data[i]; // 累加误差大
}
// 正确:使用float32累加,最后转回float16
float sum_f32 = 0.0f;
for (int i = 0; i < n; ++i) {
sum_f32 += static_cast<float>(data[i]);
}
half sum = static_cast<half>(sum_f32);
// 更优:分组累加减少误差
constexpr int GROUP_SIZE = 8;
float partial_sums[GROUP_SIZE] = {0};
for (int i = 0; i < n; i += GROUP_SIZE) {
for (int j = 0; j < GROUP_SIZE && i + j < n; ++j) {
partial_sums[j] += static_cast<float>(data[i + j]);
}
}
// 合并分组
float sum_f32 = 0.0f;
for (int j = 0; j < GROUP_SIZE; ++j) {
sum_f32 += partial_sums[j];
}问题2:数值稳定性问题
// 不稳定的softmax实现
for (int i = 0; i < n; ++i) {
exp_x[i] = exp(x[i]); // 可能溢出
sum += exp_x[i];
}
for (int i = 0; i < n; ++i) {
softmax[i] = exp_x[i] / sum;
}
// 稳定的softmax实现
// 1. 找到最大值
float max_val = x[0];
for (int i = 1; i < n; ++i) {
if (x[i] > max_val) max_val = x[i];
}
// 2. 减去最大值后计算exp
float sum = 0.0f;
for (int i = 0; i < n; ++i) {
exp_x[i] = exp(x[i] - max_val); // 避免溢出
sum += exp_x[i];
}
// 3. 归一化
for (int i = 0; i < n; ++i) {
softmax[i] = exp_x[i] / sum;
}问题3:特殊值处理
// 不完整的特殊值处理
half result = a / b; // b可能为0
// 完整的特殊值处理
half safe_divide(half a, half b) {
if (isnan(a) || isnan(b)) {
return NAN;
}
if (isinf(a) || isinf(b)) {
// 处理无穷大
if (isinf(a) && isinf(b)) {
return NAN; // ∞/∞
} else if (isinf(a)) {
return (signbit(a) == signbit(b)) ? INFINITY : -INFINITY;
} else {
return 0.0f; // 有限/∞
}
}
if (b == 0.0f) {
if (a == 0.0f) {
return NAN; // 0/0
} else {
return (signbit(a) == signbit(b)) ? INFINITY : -INFINITY;
}
}
return a / b;
}5.3 精度调试工具箱
# precision_debugger.py
class PrecisionDebugger:
"""精度调试器"""
def __init__(self, operator_runner, reference_impl):
self.operator_runner = operator_runner
self.reference_impl = reference_impl
self.debug_data = []
def debug_layerwise(self, input_data, layer_index=0):
"""逐层调试"""
# 运行算子
actual_output = self.operator_runner.run(input_data)
# 运行参考实现
expected_output = self.reference_impl(input_data)
# 比较中间结果
if hasattr(self.operator_runner, 'get_intermediate_results'):
intermediate_actual = self.operator_runner.get_intermediate_results()
intermediate_expected = self.reference_impl.get_intermediate_results()
for i, (act, exp) in enumerate(zip(intermediate_actual, intermediate_expected)):
error = self.compute_error(act, exp)
print(f"Layer {i}: max_error={error['max_abs']:.2e}, "
f"mean_error={error['mean_abs']:.2e}")
if error['max_abs'] > 1e-3:
print(f" ❌ Large error detected at layer {i}")
self.analyze_error_pattern(act, exp, f"layer_{i}")
return actual_output, expected_output
def analyze_error_pattern(self, actual, expected, tag=""):
"""分析误差模式"""
error = np.abs(actual - expected)
# 1. 检查是否是系统性偏差
mean_error = np.mean(error)
std_error = np.std(error)
if std_error / (mean_error + 1e-10) < 0.1:
print(f" Pattern: Systematic bias (mean={mean_error:.2e})")
# 2. 检查是否与数值大小相关
correlation = np.corrcoef(np.abs(expected.flatten()), error.flatten())[0, 1]
if abs(correlation) > 0.5:
print(f" Pattern: Error correlates with magnitude (r={correlation:.3f})")
# 3. 检查是否在特定值附近
max_error_idx = np.unravel_index(np.argmax(error), error.shape)
max_error_val = error[max_error_idx]
expected_val = expected[max_error_idx]
print(f" Max error at {max_error_idx}: "
f"error={max_error_val:.2e}, expected={expected_val:.6f}")
# 保存调试数据
self.debug_data.append({
'tag': tag,
'mean_error': mean_error,
'max_error': max_error_val,
'correlation': correlation,
'max_error_location': max_error_idx,
'max_error_expected': expected_val
})
def generate_debug_report(self):
"""生成调试报告"""
import pandas as pd
df = pd.DataFrame(self.debug_data)
report = {
'summary': {
'total_layers': len(self.debug_data),
'layers_with_issues': len(df[df['max_error'] > 1e-3]),
'worst_layer': df.loc[df['max_error'].idxmax()].to_dict(),
'average_error': df['mean_error'].mean()
},
'detailed': df.to_dict('records')
}
return report六、 未来展望:AI赋能的测试框架
测试框架的未来是智能化、自适应、预测性的。
6.1 AI辅助的测试用例生成
# ai_test_generator.py
class AITestGenerator:
"""AI辅助的测试用例生成器"""
def __init__(self, model_path: str):
# 加载预训练的AI模型
self.model = self.load_model(model_path)
self.history = []
def generate_targeted_cases(self, operator_info: Dict) -> List[TestCase]:
"""生成有针对性的测试用例"""
# 分析算子特性
operator_type = operator_info.get('type', '')
data_type = operator_info.get('dtype', 'float32')
# 使用AI模型预测易错场景
vulnerability = self.model.predict_vulnerability(operator_type, data_type)
cases = []
# 针对数值不稳定性
if vulnerability.get('numerical_instability', 0) > 0.7:
cases.extend(self.generate_numerical_stress_cases())
# 针对边界条件
if vulnerability.get('boundary_issues', 0) > 0.7:
cases.extend(self.generate_boundary_cases())
# 针对特殊值
if vulnerability.get('special_value_issues', 0) > 0.7:
cases.extend(self.generate_special_value_cases())
return cases
def learn_from_failures(self, failures: List[Dict]):
"""从失败案例中学习"""
for failure in failures:
# 记录失败模式
self.history.append({
'operator': failure['operator'],
'error_pattern': failure['error_pattern'],
'input_characteristics': failure['input_stats']
})
# 更新AI模型
if len(self.history) > 100:
self.model.update(self.history)6.2 自适应的容差系统
# adaptive_tolerance.py
class AdaptiveToleranceSystem:
"""自适应容差系统"""
def __init__(self):
self.tolerance_base = ToleranceConfig()
self.learning_rate = 0.1
self.history = []
def adjust_tolerance(self, operator_type: str, data_type: str,
error_stats: Dict, historical_performance: List) -> ToleranceConfig:
"""根据历史表现调整容差"""
# 计算历史误差统计
historical_errors = [h['max_error'] for h in historical_performance]
mean_error = np.mean(historical_errors)
std_error = np.std(historical_errors)
# 动态调整容差
adjusted = ToleranceConfig()
# 绝对误差:均值 + 3σ
adjusted.absolute = mean_error + 3 * std_error
# 相对误差:基于绝对误差和典型值大小
typical_value = self.get_typical_value(operator_type, data_type)
adjusted.relative = adjusted.absolute / (typical_value + 1e-10)
# 保证最小容差
adjusted.absolute = max(adjusted.absolute, 1e-10)
adjusted.relative = max(adjusted.relative, 1e-10)
return adjusted
def get_typical_value(self, operator_type: str, data_type: str) -> float:
"""获取典型值大小"""
typical_values = {
'float16': {'add': 1.0, 'matmul': 10.0, 'softmax': 0.1},
'float32': {'add': 1.0, 'matmul': 10.0, 'softmax': 0.1},
}
return typical_values.get(data_type, {}).get(operator_type, 1.0)写在最后
精度测试不是算子开发的终点,而是质量保障的起点。通过本文的深度解析,你应该理解到:
-
测试数据生成是科学:需要系统的方法论,覆盖所有边界和特殊情况
-
精度验证是多维度的:不能只看绝对误差,还要看相对误差、信噪比、误差分布
-
容差设置需要智慧:太严或太松都会有问题,需要基于数据类型、算子特性、应用场景
-
自动化是必由之路:手工测试无法保证质量,必须建立自动化测试流水线
-
调试需要系统性:精度问题往往有模式,需要系统的方法定位和修复
从我13年的经验来看,一个好的测试框架应该像精密的科学仪器——能够测量(准确评估)、能够诊断(定位问题)、能够学习(持续改进)。
最后留给你一个问题:在你的算子项目中,是如何保证精度的?有没有遇到过特别棘手的精度问题?欢迎分享你的经验和思考。
附录:权威参考与资源
-
IEEE 754浮点数标准 - 浮点数计算的基础标准
-
华为昇腾精度调优指南 - 官方精度优化最佳实践
-
数值计算方法(Numerical Recipes) - 数值计算经典参考
-
Google Test框架 - 工业级C++测试框架设计参考
-
昇腾开发者社区测试专题 - 开发者测试经验分享
官方介绍
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)