
Ascend 硬件下书生大模型部署微调评测复现文档
未申请过书生API key的,在下面链接申请: https://internlm.intern-ai.org.cn/api/tokens?在opencompass/opencompass/configs文件夹下创建eval_tutorial_demo1.py。模型要求transformers>=4.55.2,但是5.2.0版本我是不能启动的,这里使用的是4.55.2版本。数据集 的json 文件需
一. 创建Ascend开发机
通过下面链接创建
https://internstudio-ascend.intern-ai.org.cn/console/instance/new
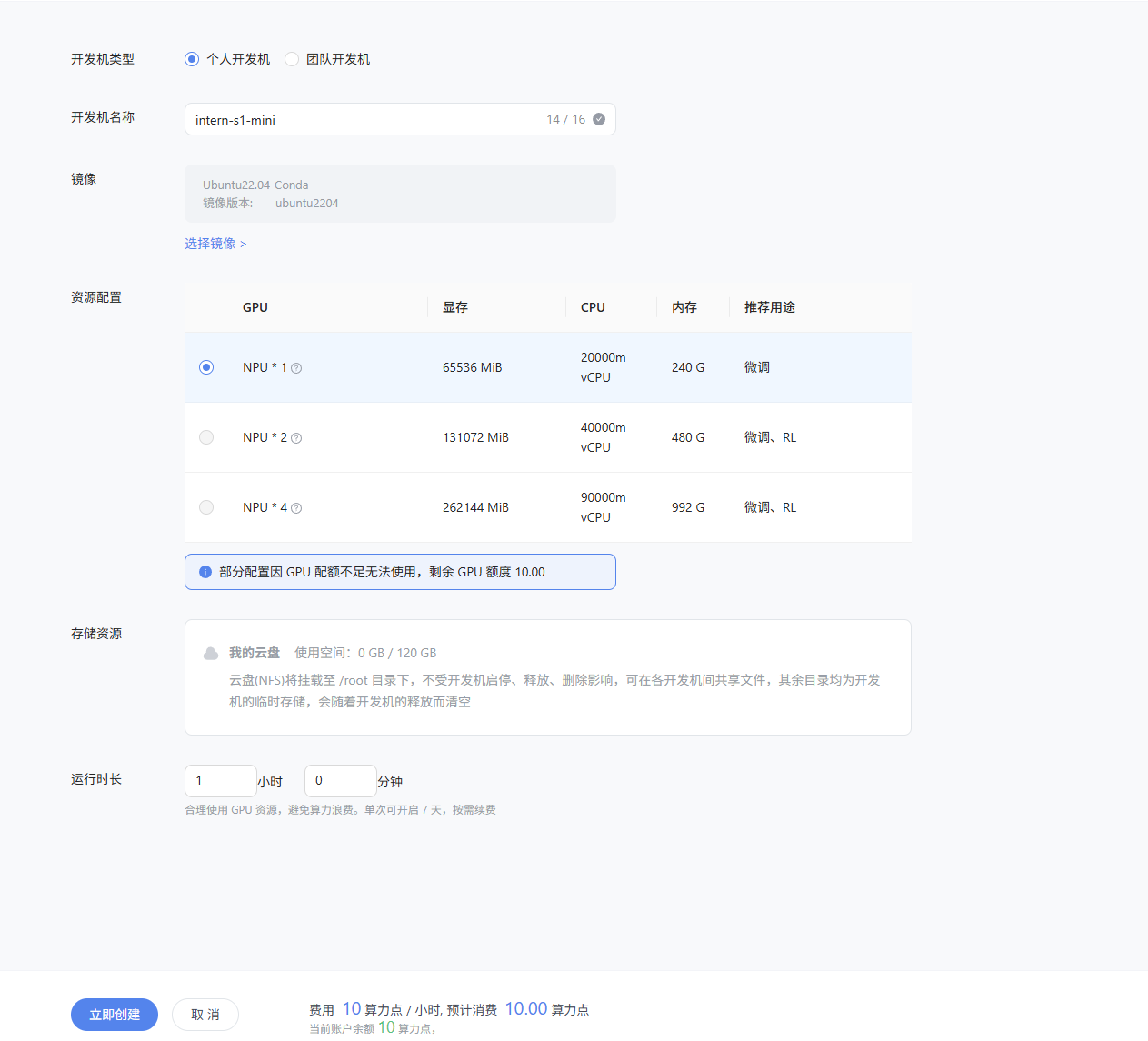
创建完成并且排完队后,点击进入开发机
打开VSCode
二. 部署
1. 准备vllm环境
创建conda环境python版本选择3.11
conda create -n ascend python=3.11 -y
激活conda环境并且安装 uv
conda activate ascend
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
pip install uv
安装vllm和vllm-ascend
uv pip install vllm==0.11.0
uv pip install vllm-ascend==0.11.0rc1
设置昇腾相关环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
2. 下载模型
安装modelscope
uv pip install modelscope
下载 Intern-S1-mini
modelscope download Shanghai_AI_Laboratory/Intern-S1-mini
3. 启动vLLM 服务
export VLLM_USE_MODELSCOPE=true
vllm serve Shanghai_AI_Laboratory/Intern-S1-mini --trust-remote-code --enforce-eager
观察启动日志,当出现如下图的日志时说明vllm服务启动成功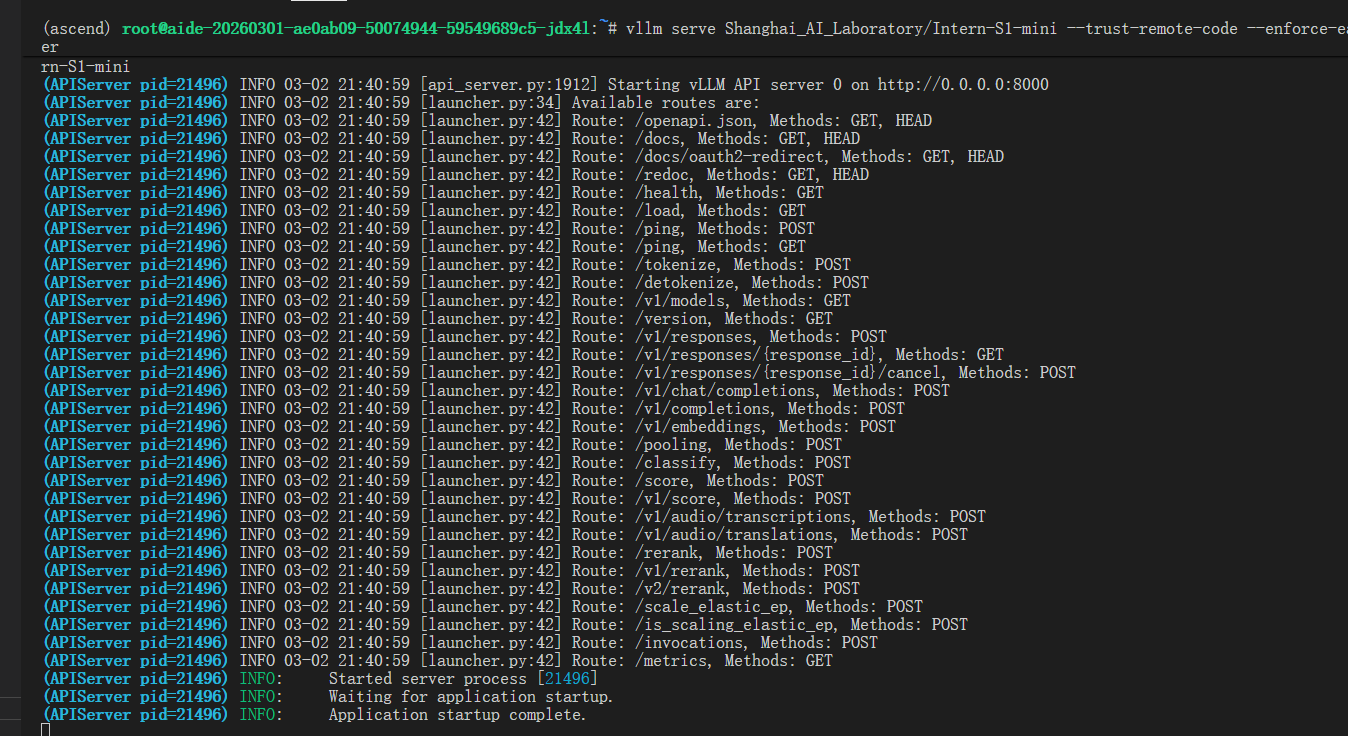
模型要求transformers>=4.55.2,但是5.2.0版本我是不能启动的,这里使用的是4.55.2版本
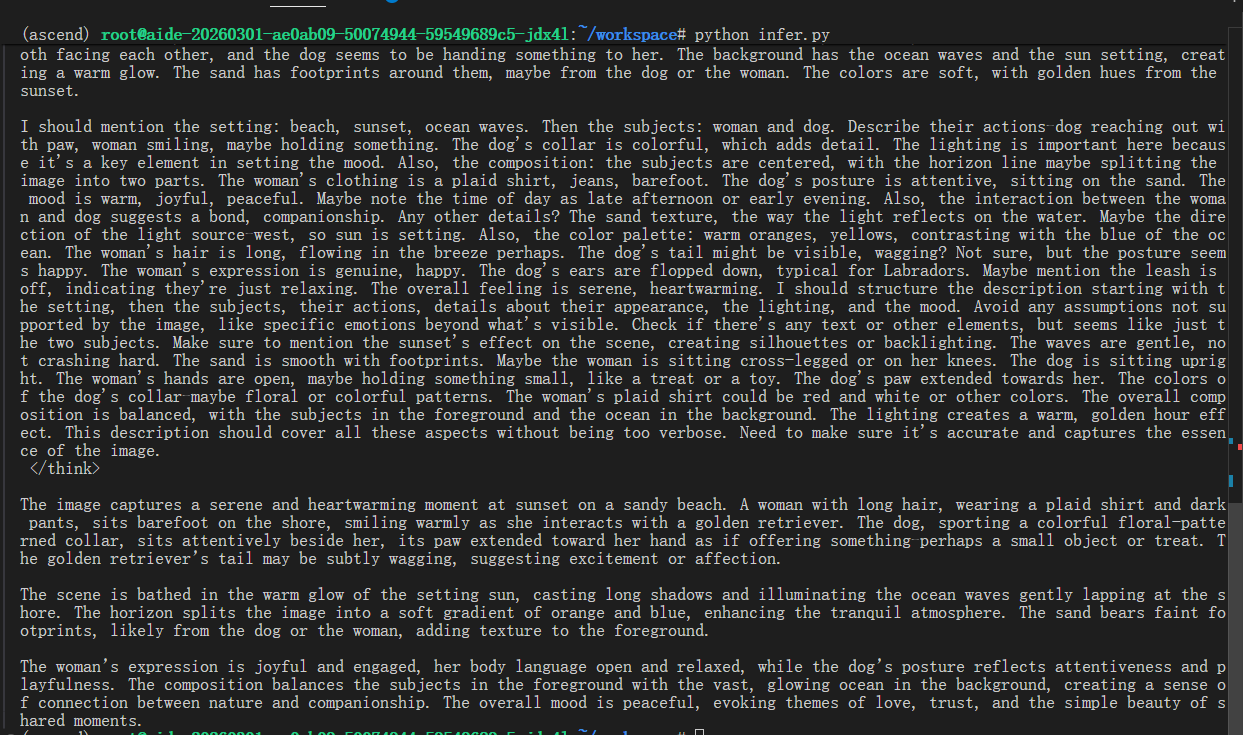
4. 推理测试
from openai import OpenAI
client = OpenAI(api_key='', base_url='http://0.0.0.0:8000/v1')
model_name = client.models.list().data[0].id
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url":{
"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
}
},
{"type": "text", "text": "Describe this image."},
],
}
]
response = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=0.8,
top_p=0.8,
max_tokens=2048,
)
print(response.choices[0].message.content)
将以上代码保存成infer.py并运行:
uv run infer.py
或用python运行
python infer.py
三. 微调
1. 准备环境
cd /root/
conda create -n ms_swift python=3.10 -y
conda activate ms_swift
pip install torch==2.6.0 torch-npu==2.6.0 torchaudio==2.6.0 torchvision decorator \
-i https://pypi.tuna.tsinghua.edu.cn/simple
pip install ms-swift==3.12 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install timm==1.0.9 msgspec==0.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
2. 下载数据集
pip install modelscope
modelscope download --dataset JimmyMa99/VLM-formula-recognition-dataset_intern_camp --local_dir /root/dataset/VLM-formula-recognition-dataset_intern_camp
数据集 的json 文件需要转化处理下,将图片路径变成绝对路径,创建转换脚本convert.py
创建文件
mkdir /root/swift_workdir/
cd /root/swift_workdir/
vim convert.py
脚本内容:
import json, os, sys
in_path = "/root/dataset/VLM-formula-recognition-dataset_intern_camp/train/train_mini.jsonl" # 你的现用 jsonl
out_path = "/root/dataset/VLM-formula-recognition-dataset_intern_camp/train/train_mini_abs.jsonl" # 输出到新文件jsonl
base = "/root/dataset/VLM-formula-recognition-dataset_intern_camp/train/" # train_swift.jsonl所在的文件夹
def to_abs(p):
if not p: return p
# 仅当是相对路径时拼接;已是绝对路径则保留
return p if os.path.isabs(p) else os.path.join(base, p)
n=0;m=0
with open(in_path,'r',encoding='utf-8') as fin, open(out_path,'w',encoding='utf-8') as fout:
for line in fin:
if not line.strip(): continue
obj = json.loads(line)
changed = False
# 兼容两种常见结构:images: [..] 或 messages[].content[].image
if 'images' in obj and isinstance(obj['images'], list):
obj['images'] = [to_abs(x) for x in obj['images']]
changed = True
if 'messages' in obj:
for msg in obj['messages']:
c = msg.get('content')
if isinstance(c, list):
for part in c:
if part.get('type') == 'image' and 'image' in part:
part['image'] = to_abs(part['image'])
changed = True
fout.write(json.dumps(obj,ensure_ascii=False)+'\n')
n+=1
m+=changed
print(f"processed lines={n}, patched={m}, saved -> {out_path}")
执行
python convert.py
3. Intern-S1-mini 微调
3.1 创建微调配置文件
cd /root/workspace/swift_workdir
mkdir config
cd config
vim interns1-mini_train_npu.sh
配置文件内容
#!/bin/bash
# 创建日志目录
LOG_DIR="logs"
mkdir -p $LOG_DIR
# 获取当前时间戳
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
LOG_FILE="$LOG_DIR/interns1mini_sft_${TIMESTAMP}.log"
# 设置环境变量
# export ENABLE_AUDIO_OUTPUT=False
export NPROC_PER_NODE=1
export OMP_NUM_THREADS=1
export ASCEND_RT_VISIBLE_DEVICES=0
# 设置随机端口号,避免端口冲突
export MASTER_PORT=$((10000 + RANDOM % 50000))
# 先打印启动信息
echo "Starting training..."
echo "Log file: $LOG_FILE"
echo "Using port: $MASTER_PORT"
# 没有指定 model_type
# 启动训练并获取PID
nohup swift sft \
--model '/share/new_models/Intern-S1-mini' \
--dataset '/root/dataset/VLM-formula-recognition-dataset_intern_camp/train/train_mini_abs.jsonl' \
--eval_steps 1000 \
--train_type lora \
--lora_rank 16 \
--lora_dropout 0.01 \
--lora_alpha 32 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--warmup_ratio 0.05 \
--gradient_accumulation_steps 4 \
--save_steps 500 \
--save_total_limit 10 \
--gradient_checkpointing_kwargs '{"use_reentrant": false}' \
--logging_steps 1 \
--max_length 8000 \
--output_dir ./swift_output/SFT-Interns1mini \
--dataset_num_proc 16 \
--dataloader_num_workers 16 \
--model_author JeffDing \
--model_name SFT-camp6 \
--metric acc \
--freeze_vit true \
> "$LOG_FILE" 2>&1 &
# 获取PID并等待一下确保进程启动
TRAIN_PID=$!
sleep 2
# 检查进程是否还在运行
if kill -0 $TRAIN_PID 2>/dev/null; then
echo "Training started successfully with PID $TRAIN_PID"
echo "To view logs in real-time, use:"
echo "tail -f $LOG_FILE"
echo ""
echo "To stop training, use:"
echo "kill $TRAIN_PID"
else
echo "Failed to start training process"
echo "Check log file for errors: $LOG_FILE"
fi
3.2 启动微调
cd /root/workspace/swift_workdir
bash config/interns1-mini_train_npu.sh
使用npu-smi info命令可以查看NPU使用情况: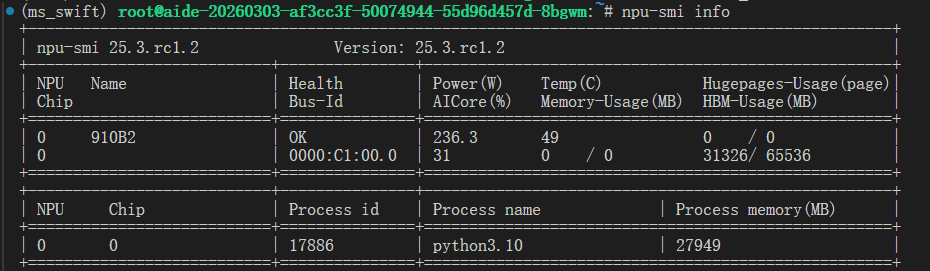
微调结束: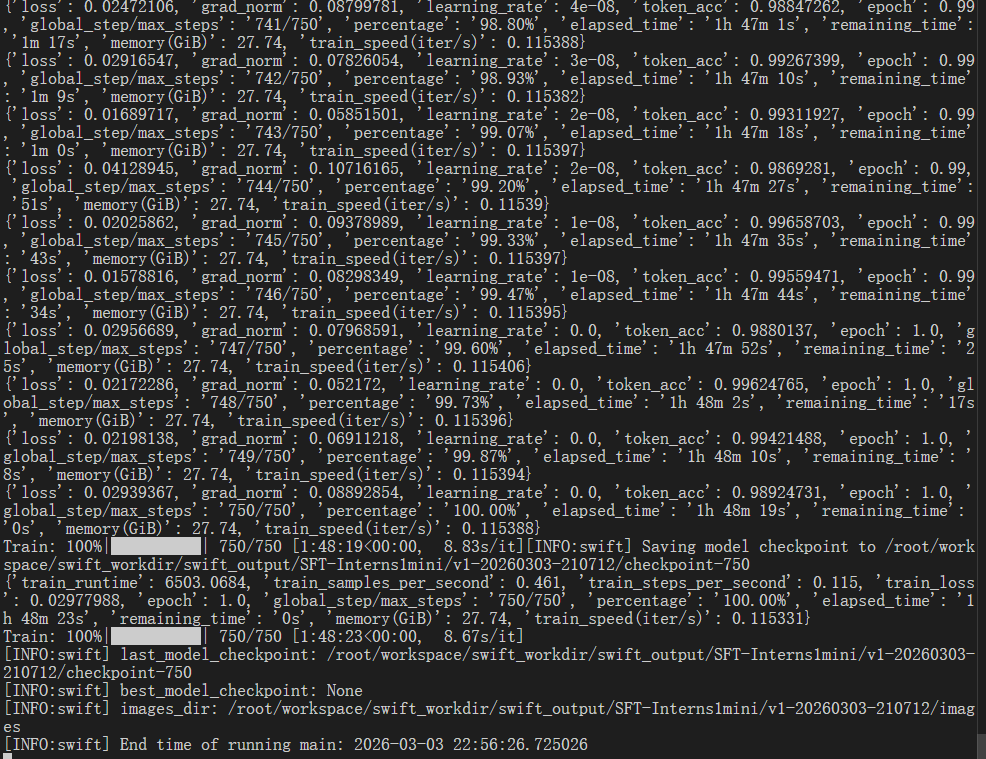
3.3 合并权重
swift export --adapters "/root/workspace/swift_workdir/swift_output/SFT-Interns1mini/v1-20260303-210712/checkpoint-750" --merge_lora True
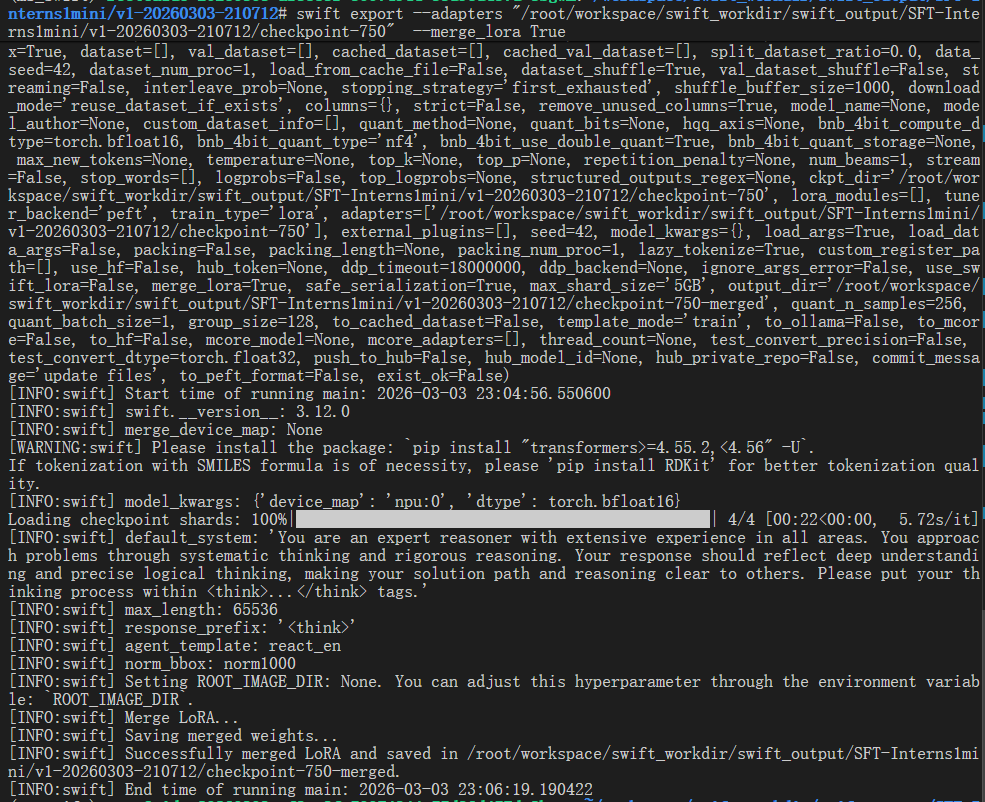
4. InternVL3_5-1B 微调
4.1 创建微调配置文件
cd /root/workspace/swift_workdir
mkdir config
cd config
vim internvl3.5_1b_train_npu.sh
配置文件内容
#!/bin/bash
# 创建日志目录
LOG_DIR="logs"
mkdir -p $LOG_DIR
# 获取当前时间戳
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
LOG_FILE="$LOG_DIR/internvl3.5_1b_sft_${TIMESTAMP}.log"
# 设置环境变量
# export ENABLE_AUDIO_OUTPUT=False
export OMP_NUM_THREADS=1
export ASCEND_RT_VISIBLE_DEVICES=0
export NPROC_PER_NODE=1
# 设置随机端口号,避免端口冲突
export MASTER_PORT=$((10000 + RANDOM % 50000))
# 先打印启动信息
echo "Starting training..."
echo "Log file: $LOG_FILE"
echo "Using port: $MASTER_PORT"
# 没有指定 model_type
# 启动训练并获取PID
nohup swift sft \
--model '/share/new_models/InternVL3.5/InternVL3_5-1B'\
--dataset '/root/dataset/VLM-formula-recognition-dataset_intern_camp/train/train_mini_abs.jsonl' \
--eval_steps 100 \
--train_type lora \
--lora_rank 16 \
--lora_dropout 0.01 \
--lora_alpha 32 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 5e-5 \
--warmup_ratio 0.05 \
--gradient_accumulation_steps 4 \
--save_steps 500 \
--save_total_limit 3 \
--gradient_checkpointing_kwargs '{"use_reentrant": false}' \
--logging_steps 10 \
--max_length 8000 \
--output_dir ./swift_output/SFT-InternVL3_5-1B\
--dataset_num_proc 8 \
--dataloader_num_workers 8 \
--metric acc \
--freeze_vit true \
> "$LOG_FILE" 2>&1 &
# 获取PID并等待一下确保进程启动
TRAIN_PID=$!
sleep 2
# 检查进程是否还在运行
if kill -0 $TRAIN_PID 2>/dev/null; then
echo "Training started successfully with PID $TRAIN_PID"
echo "To view logs in real-time, use:"
echo "tail -f $LOG_FILE"
echo ""
echo "To stop training, use:"
echo "kill -9 $TRAIN_PID"
else
echo "Failed to start training process"
echo "Check log file for errors: $LOG_FILE"
fi
4.2 启动微调
cd /root/workspace/swift_workdir
bash config/internvl3.5_1b_train_npu.sh
微调完成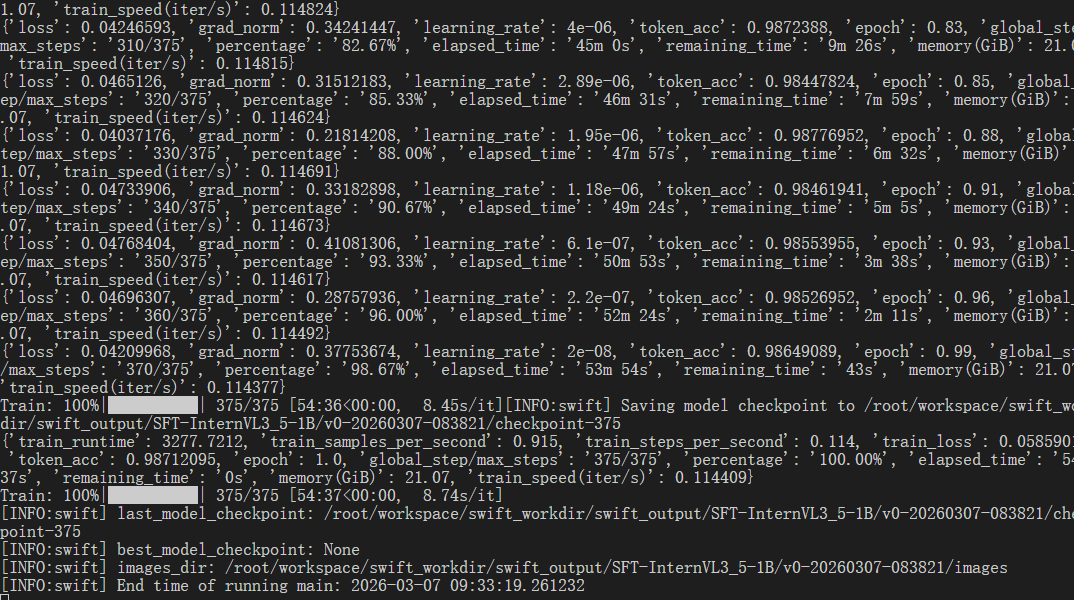
4.3 合并权重
swift export --adapters "微调生成的checkpoint文件目录" --merge_lora True
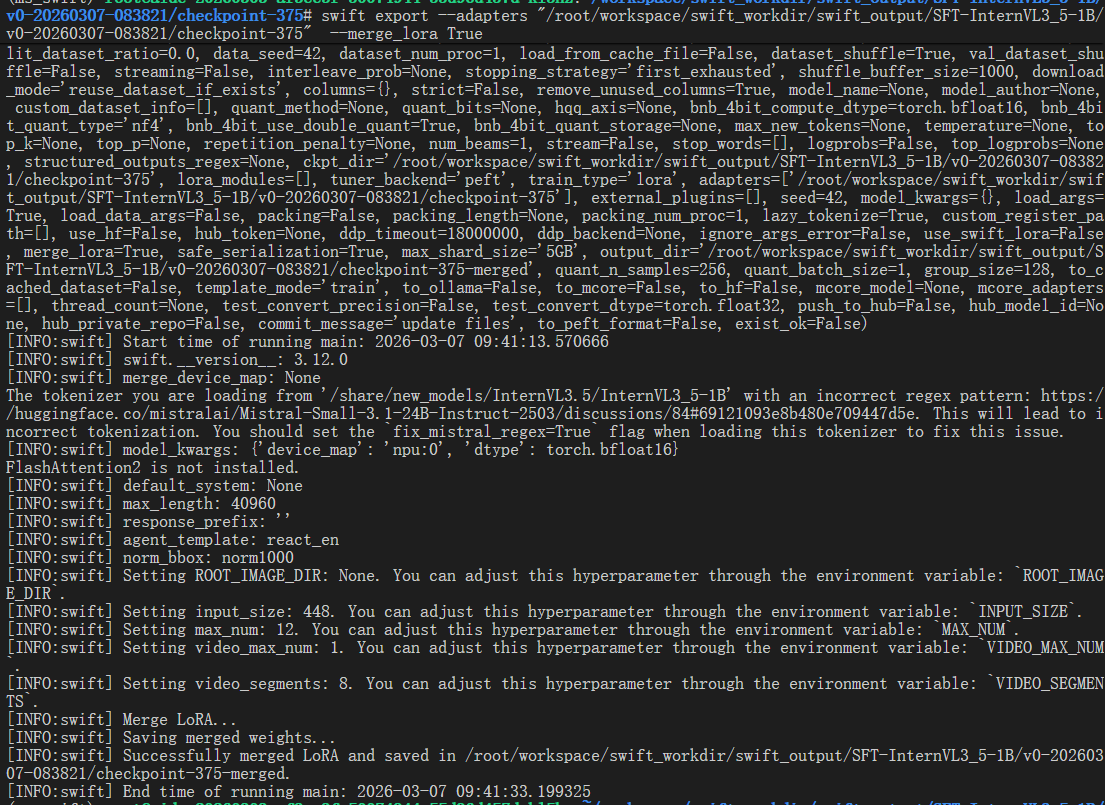
4.4 补全模型文件
SRC="/share/new_models/InternVL3.5/InternVL3_5-1B-HF" #源模型地址
DST="/root/workspace/swift_workdir/swift_output/SFT-InternVL3_5-1B/v0-20260307-083821/checkpoint-375-merged" #微调后模型地址
rsync -ah --ignore-existing --exclude='/proc' --exclude='proc' "$SRC"/ "$DST"/
5. 提交结果
创建upload.py脚本
cd /root/swift_workdir
vim upload.py
脚本内容:
from modelscope.hub.api import HubApi
from modelscope.hub.constants import Licenses, ModelVisibility
# 配置基本信息
YOUR_ACCESS_TOKEN = "ms-9fxx7e" # 填写自己的 api token ,获取方式点击:https://modelscope.cn/my/myaccesstoken
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)
# 取名字
owner_name = "xx" # ModelScope 的用户名
model_name = "xx" # 为模型库取个响亮优雅又好听的名字,需根据自己情况修改
model_id = f"{owner_name}/{model_name}"
# 创建模型仓库
api.create_model(
model_id,
visibility=ModelVisibility.PUBLIC,
license=Licenses.APACHE_V2,
chinese_name=f"{owner_name}的书生大模型实战营-公式微调分类比赛",
)
# 上传模型到仓库
api.upload_folder(
repo_id=f"{owner_name}/{model_name}",
folder_path="xx", # 微调后模型的文件夹名称
commit_message="upload model folder to repo", # 写上传信息
)
运行upload.py上传模型
python upload.py
提交表单的 prompt 参考如下,这里也有优化空间,可自行探索最优 prompt:
请根据图片中的公式生成对应的 latex 公式文本
四. 评测
1. 安装OpenCompass
# 创建虚拟环境
conda create -n opencompass python=3.10 -y
conda activate opencompass
cd /root
git clone https://gh.llkk.cc/https://github.com/open-compass/opencompass.git opencompass
cd opencompass
pip install -e .
pip install opencompass[api]
pip install cloudpickle ml-dtypes tornado
2. Intern-S1 API评测
2.1 数据集下载
首先将数据集下载到本地:
apt-get update && apt-get install -y unzip
cd /root/opencompass
wget https://ghfast.top/https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
查看解压后的数据集
ls /root/opencompass/data
可以看到 OpenCompass 下data文件夹里面包含的数据集。
2.2 使用Intern-s1 API评测C-Eval 选择题
在opencompass/opencompass/configs文件夹下创建eval_tutorial_demo1.py
cd /root/opencompass/opencompass/configs
touch eval_tutorial_demo1.py
打开eval_tutorial_demo1.py 输入以下代码。注意需要将key替换为自己的key。未申请过书生API key的,在下面链接申请: https://internlm.intern-ai.org.cn/api/tokens?lang=zh-CN
from mmengine.config import read_base
from opencompass.models import OpenAISDK
# 配置模型
models = [
dict(
type=OpenAISDK,
path='intern-s1', # 明确模型名称
key='xxx', # 替换为的API密钥
openai_api_base='https://chat.intern-ai.org.cn/api/v1', # API地址
rpm_verbose=True,
query_per_second=1, # 根据 rpm 限制,进行调整.rpm==30
max_out_len=512,
max_seq_len=4096,
temperature=0.01,
batch_size=10,# 根据 rpm 限制,进行调整.rpm==30
retry=5, # 增加重试次数
)
]
# 配置数据集(只取每个子数据集的1个样本)
with read_base():
from .datasets.ceval.ceval_gen import ceval_datasets
#datasets=ceval_datasets #测试完整的数据集
# 缩小数据集规模为五个子数据集,每个子数据集仅保留10个样本,缩短测评时间
datasets = []
for d in ceval_datasets[:5]:
# 添加前缀标识这是演示用的精简数据集
d['abbr'] = 'demo_' + d['abbr']
# 仅使用第1个样本(索引0)
d['reader_cfg']['test_range'] = '[0:10]'
datasets.append(d)
启动评测
cd /root/opencompass
python run.py opencompass/configs/eval_tutorial_demo1.py --debug
评测过程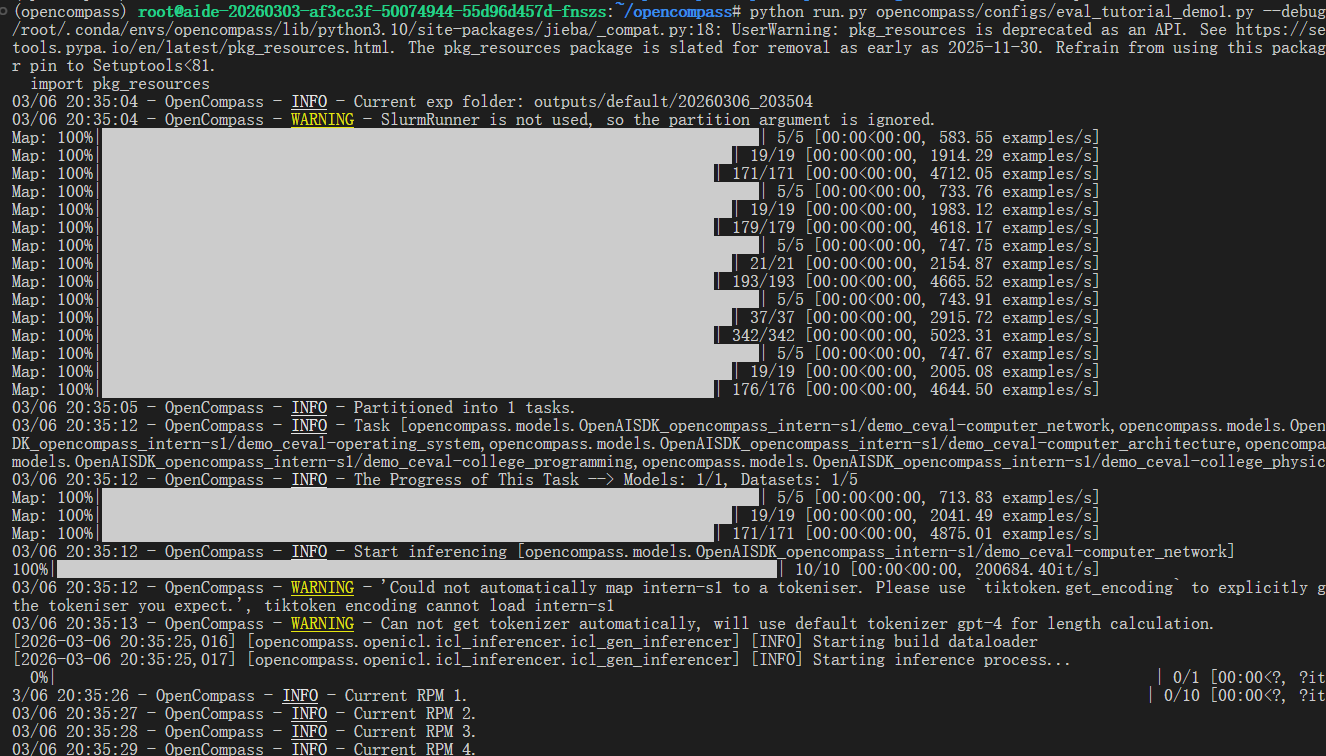
评测结果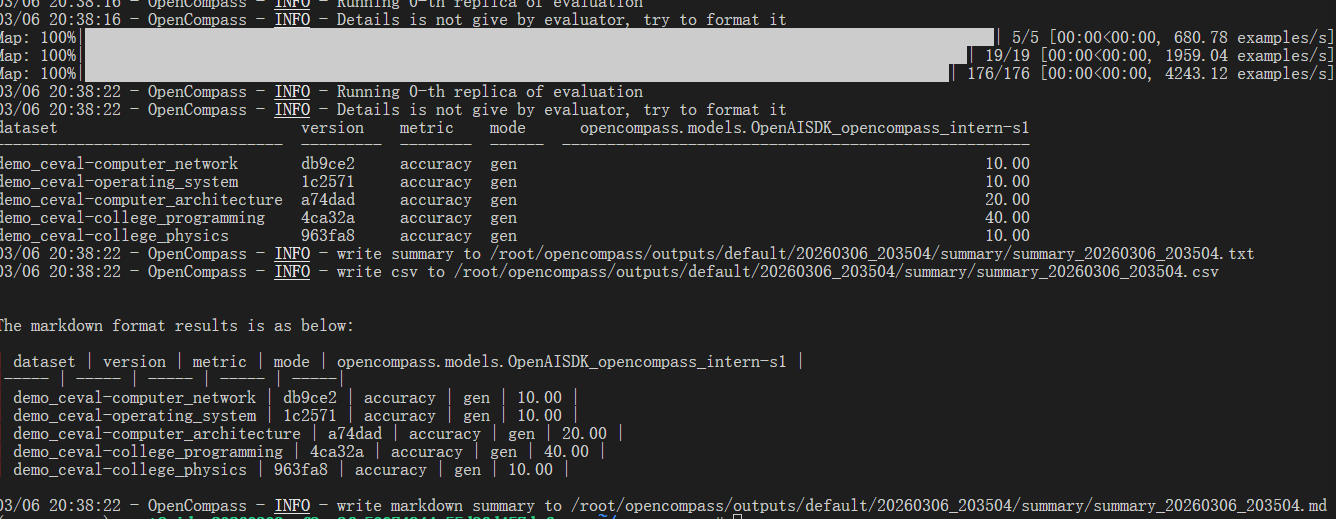
所有运行输出默认放在 outputs/default/ 目录,结构如下:
outputs/default/
├── 20200220_120000
├── 20230220_183030 # 每个实验一个文件夹
│ ├── configs # 用于记录的已转储的配置文件。如果在同一个实验文件夹中重新运行了不同的实验,可能会保留多个配置
│ ├── logs # 推理和评估阶段的日志文件
│ │ ├── eval
│ │ └── infer
│ ├── predictions # 每个任务的推理结果
│ ├── results # 每个任务的评估结果
│ └── summary # 单个实验的汇总评估结果
├── ...

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)