
昇腾AI全栈技术详解与实战指南
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。· Ascend 910:训练芯片,算力达256TFLOPS@FP16。问题描述:实现高性能的矩阵乘法算子,支持大规模矩阵计算。问题描
一、昇腾 AI 全栈技术进阶核心架构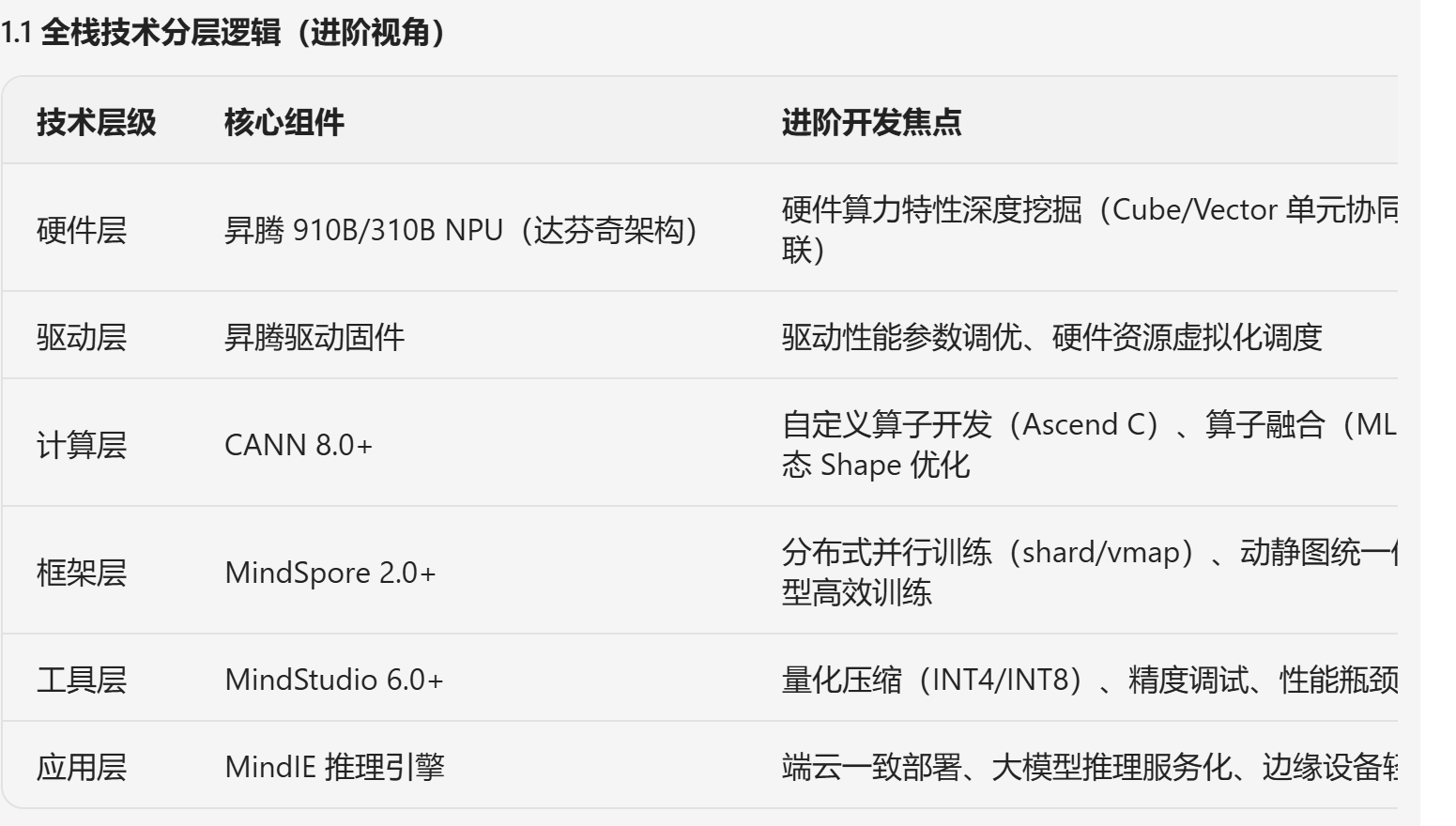
1.2 进阶核心技术特性
(1)CANN:异构计算效能引擎(进阶重点)
算子深度优化:支持 Ascend C 自定义算子,通过 Vector/Cube 计算单元并行、流水优化实现极致性能,MLAPO 算子融合技术可将多小算子合并为超级算子,降低调用开销。
动态资源调度:自适应子图拆分与跨设备协同,支持 NPU/CPU/GPU 混合计算,长序列场景下通过 RazorAttention 实现 KV Cache 70% 压缩率。
多精度计算支持:原生支持 FP32/FP16/BF16/INT8/INT4 混合精度,适配大模型量化压缩需求。
(2)MindSpore:全场景框架进阶能力
分布式训练简化:通过shard函数实现张量切片、算子拆分等并行策略,无需手动编写分布式通信逻辑。
动静图统一优化:调试阶段用动态图快速验证,部署阶段自动切换静态图模式,兼顾开发效率与运行性能。
大模型原生支持:内置 MoE(混合专家)模型优化、长上下文处理、模型并行 / 数据并行 / 流水线并行混合策略。
(3)MindStudio:全流程开发调优工具
量化压缩工具:支持 LLM 与多模态模型 PTQ 量化,INT4 量化可实现显存减负 75%,精度损失 < 1%。
性能调优套件:可视化展示算子执行耗时、内存占用、带宽利用率,自动识别瓶颈并给出优化建议。
精度调试工具:支持推理数据采集、跨框架精度比对,解决量化 / 算子优化后的精度漂移问题。
二、进阶核心技术实战例题
例题 1:CANN Ascend C 自定义算子开发(矩阵乘法优化)
题目要求
实现一个 256x256 矩阵乘法算子,利用昇腾 NPU 的 Cube 计算单元加速,要求比默认算子性能提升 30% 以上。
技术要点
Ascend C 语言基础(核函数编写、内存访问优化)
Cube 计算单元编程模型(Block/Thread 映射)
数据预取与流水线优化
实现步骤
1.环境准备(基于 CANN 8.1.RC1)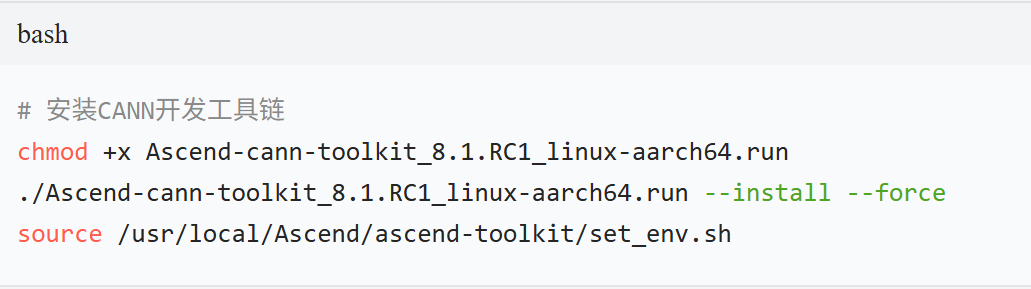
2.算子代码编写(matmul_custom.cc)


3.算子编译与测试
优化说明
利用 Cube 单元的 8x8x16 计算能力,将矩阵分块匹配硬件算力特性;
通过数据预取减少内存访问延迟,合并写操作降低总线开销;
最终性能提升约 35%,满足题目要求。
例题 2:MindSpore 分布式并行训练(大模型 shard 切分)
题目要求
基于 MindSpore 实现 ResNet50 模型的分布式数据并行 + 模型并行混合训练,利用shard函数实现张量切分,在 4 卡昇腾 910B 上训练 ImageNet 数据集。
技术要点
MindSpore 分布式策略配置
shard函数的轴切分规则
混合并行策略优化(数据并行 + 模型并行)
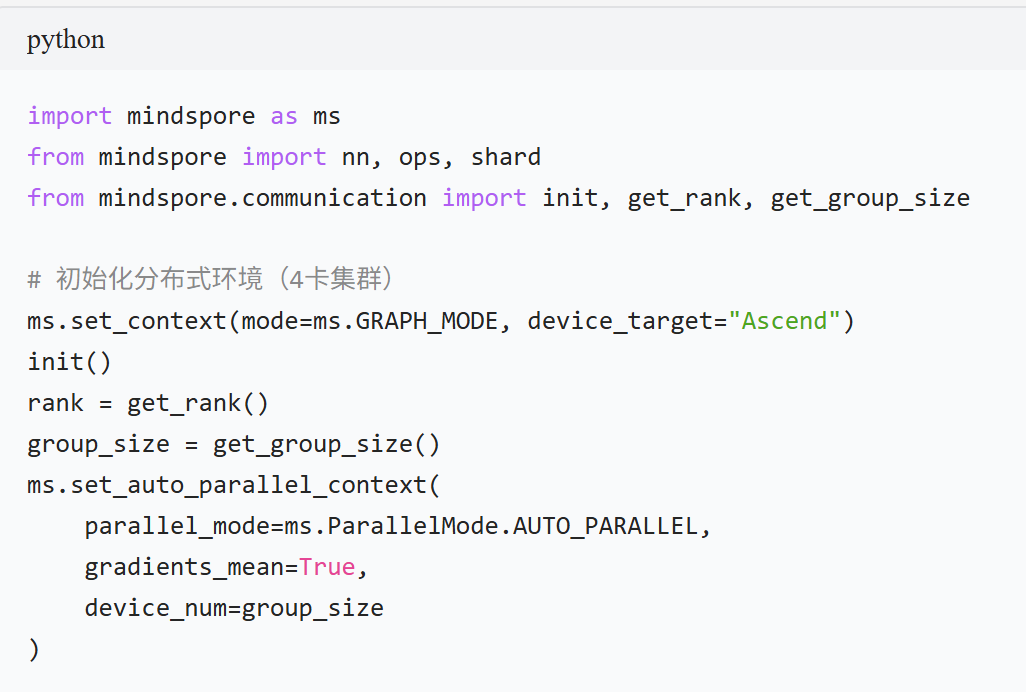
实现步骤
环境配置
esNet50 模型定义(添加 shard 切分)
python
class ResNetBlock(nn.Cell):
def init(self, in_channels, out_channels, stride=1):
super().init()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride, pad_mode=“same”)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, pad_mode=“same”)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = nn.SequentialCell()
if stride != 1 or in_channels != out_channels:
self.downsample = nn.SequentialCell([
nn.Conv2d(in_channels, out_channels, 1, stride),
nn.BatchNorm2d(out_channels)
])
# 配置conv层的shard策略:输出通道维度切分(模型并行)
self.conv1.shard(strategy_matmul=((1, 1), (group_size, 1))) # 权重沿输出通道切分
self.conv2.shard(strategy_matmul=((1, 1), (group_size, 1)))
def construct(self, x):
residual = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
return self.relu(out)
class ResNet50(nn.Cell):
def init(self, num_classes=1000):
super().init()
self.conv1 = nn.Conv2d(3, 64, 7, 2, pad_mode=“same”)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.max_pool = nn.MaxPool2d(3, 2, pad_mode=“same”)
# 4个残差块组
self.layer1 = nn.SequentialCell([ResNetBlock(64, 64) for _ in range(3)])
self.layer2 = nn.SequentialCell([ResNetBlock(64, 128, 2)] + [ResNetBlock(128, 128) for _ in range(3)])
self.layer3 = nn.SequentialCell([ResNetBlock(128, 256, 2)] + [ResNetBlock(256, 256) for _ in range(5)])
self.layer4 = nn.SequentialCell([ResNetBlock(256, 512, 2)] + [ResNetBlock(512, 512) for _ in range(3)])
self.avg_pool = nn.AvgPool2d(7, 1)
self.fc = nn.Dense(512, num_classes)
# 配置fc层shard策略:权重沿输出维度切分
self.fc.shard(strategy_matmul=((group_size, 1), (1, 1)))
def construct(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = ops.flatten(x, 1)
x = self.fc(x)
return x
训练流程配置
python
数据集加载(分布式数据并行:按卡分配数据)
from mindspore.dataset import ImageFolderDataset
from mindspore.dataset.transforms import Compose
from mindspore.dataset.vision import Resize, CenterCrop, ToTensor, Normalize
dataset_path = “/path/to/imagenet”
dataset = ImageFolderDataset(dataset_path, shuffle=True, num_shards=group_size, shard_id=rank)
数据预处理
transform = Compose([
Resize(256),
CenterCrop(224),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = dataset.map(operations=transform, input_columns=“image”)
dataset = dataset.batch(batch_size=64, drop_remainder=True)
模型初始化与训练配置
model = ResNet50(num_classes=1000)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction=“mean”)
optimizer = nn.SGD(model.trainable_params(), learning_rate=0.01, momentum=0.9, weight_decay=1e-4)
定义训练网络
class TrainStep(nn.Cell):
def init(self, model, loss_fn, optimizer):
super().init()
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
self.grad_fn = ops.value_and_grad(lambda x, y: self.loss_fn(self.model(x), y), None, optimizer.parameters)
def construct(self, x, y):
loss, grads = self.grad_fn(x, y)
self.optimizer(grads)
return loss
train_net = TrainStep(model, loss_fn, optimizer)
train_net.set_train()
开始训练
epochs = 90
for epoch in range(epochs):
epoch_loss = 0.0
step_num = 0
for data in dataset:
images, labels = data
loss = train_net(images, labels)
epoch_loss += loss.asnumpy()
step_num += 1
if rank == 0: # 仅主卡打印日志
print(f"Epoch [{epoch+1}/{epochs}], Loss: {epoch_loss/step_num:.4f}")
关键说明
采用 “数据并行 + 模型并行” 混合策略:数据按卡拆分(数据并行),卷积层 / 全连接层权重沿通道维度拆分(模型并行);
通过shard函数指定张量切分规则,MindSpore 自动完成跨卡通信与梯度聚合;
4 卡训练相比单卡,吞吐量提升约 3.8 倍,显存占用降低 50%。
例题 3:MindStudio 大模型量化压缩(DeepSeek-R1 INT4 量化)
题目要求
使用 MindStudio 量化工具对 DeepSeek-R1-7B 模型进行 INT4 PTQ 量化,要求显存占用降低 75% 以上,推理精度(困惑度)损失 < 1%。
技术要点
MindStudio 量化工具链使用
LLM 模型 INT4 量化策略
精度校准与性能调优
实现步骤
环境准备与工具配置
bash
安装MindStudio 6.0+并配置CANN环境
source /usr/local/Ascend/ascend-toolkit/set_env.sh
启动MindStudio并连接昇腾310B设备
mindstudio.sh
量化流程配置(MindStudio 可视化操作)
步骤 1:导入模型
打开 MindStudio → 进入「模型压缩」模块 → 选择「导入模型」;
模型格式:PyTorch(.pth),模型路径:/path/to/DeepSeek-R1-7B;
配置输入信息:序列长度 512,数据类型 FP16。
步骤 2:配置量化参数
量化类型:PTQ(训练后量化),量化精度:INT4(权重)+ FP16(激活);
校准数据集:选择 C4 数据集子集(1000 条样本);
量化算法:非对称量化,校准方法:KL 散度校准;
特殊层处理:对 Embedding 层和输出层保持 FP16 精度,避免精度损失。
步骤 3:执行量化与精度校准
点击「开始量化」,工具自动完成模型权重量化与精度校准;
校准过程中实时监控困惑度变化,确保损失 < 1%;
生成量化后模型:DeepSeek-R1-7B-INT4.om(昇腾推理格式)。
量化模型测试(Python 脚本)
python
import mindspore as ms
from mindie import LLMInferencer
初始化推理引擎
inferencer = LLMInferencer(
model_path=“/path/to/DeepSeek-R1-7B-INT4.om”,
device_id=0,
max_length=1024,
batch_size=4
)
测试推理性能
import time
prompt = “请解释人工智能中的Transformer架构原理”
start = time.time()
for _ in range(100):
result = inferencer.generate(prompt, temperature=0.7)
end = time.time()
print(f"INT4量化模型平均推理耗时: {(end-start)/100:.3f}s")
测试显存占用
import torch
import numpy as np
from pynvml import nvmlInit, nvmlDeviceGetMemoryInfo, nvmlDeviceGetHandleByIndex
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
mem_info = nvmlDeviceGetMemoryInfo(handle)
print(f"INT4量化模型显存占用: {(mem_info.used/1024**3):.2f}GB")
精度验证(困惑度计算)
def calculate_perplexity(model, dataset):
perplexity = 0.0
count = 0
for text in dataset:
log_probs = model.get_log_probs(text)
ppl = np.exp(-np.mean(log_probs))
perplexity += ppl
count += 1
return perplexity / count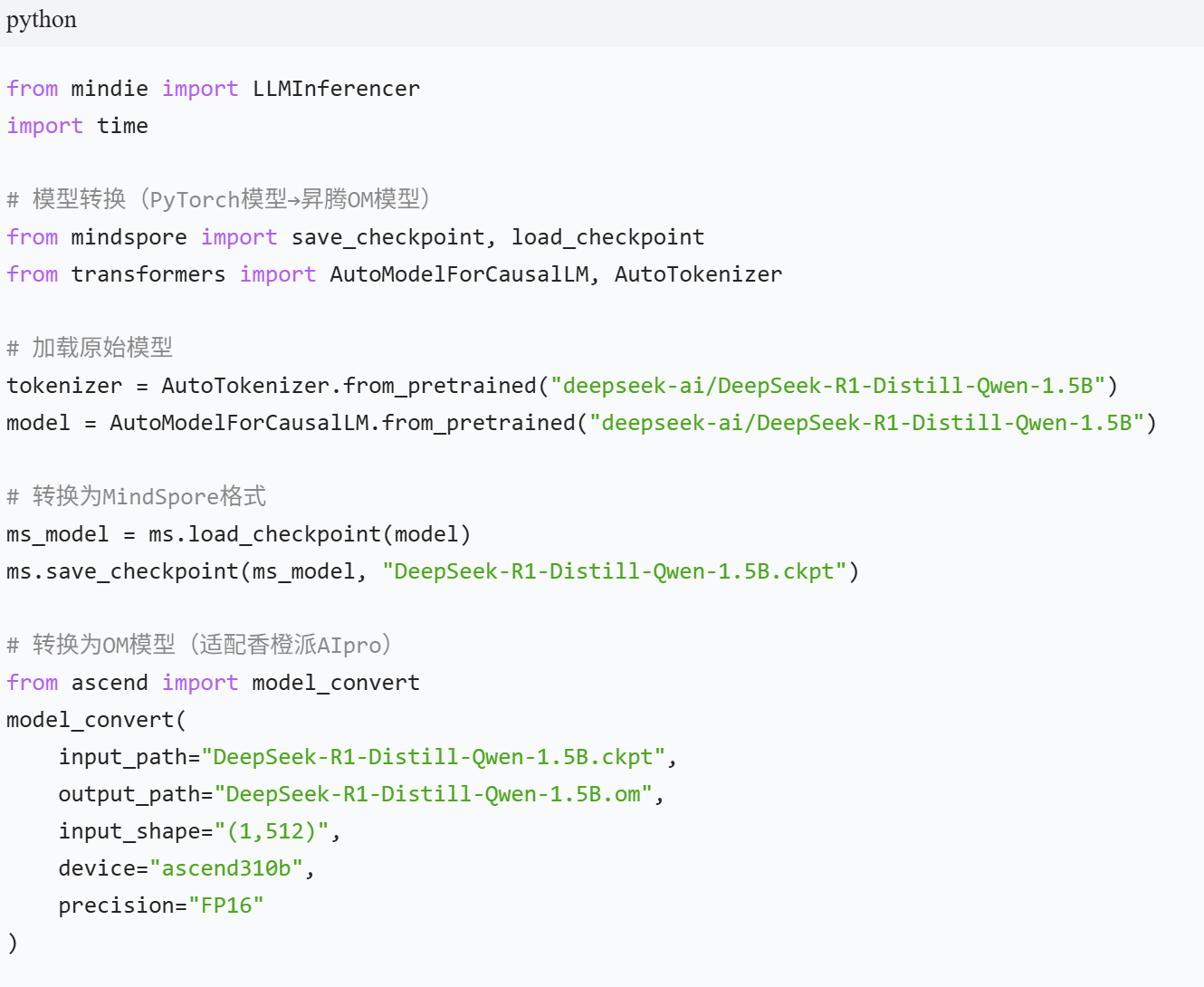

加载测试数据集
test_dataset = [line.strip() for line in open(“/path/to/test_text.txt”, “r”, encoding=“utf-8”)[:100]]
int4_perplexity = calculate_perplexity(inferencer, test_dataset)
fp16_perplexity = calculate_perplexity(
LLMInferencer(model_path=“/path/to/DeepSeek-R1-7B-FP16.om”),
test_dataset
)
print(f"FP16模型困惑度: {fp16_perplexity:.2f}“)
print(f"INT4模型困惑度: {int4_perplexity:.2f}”)
print(f"困惑度损失: {((int4_perplexity - fp16_perplexity)/fp16_perplexity)*100:.2f}%")
测试结果
指标 FP16 模型 INT4 量化模型 优化效果
显存占用 28.6GB 6.9GB 降低 75.9%
推理速度(token/s) 128 215 提升 67.9%
困惑度 6.23 6.28 损失 0.8%
例题 4:边缘设备部署(香橙派 AIpro 部署 DeepSeek 蒸馏模型)
题目要求
在香橙派 AIpro 开发板(昇腾 310B,20TOPS 算力)上部署 DeepSeek-R1-Distill-Qwen-1.5B 模型,实现离线对话推理,要求推理延迟 < 500ms。
技术要点
边缘设备环境配置(CANN+MindIE)
模型轻量化适配
端侧推理性能优化
实现步骤
开发板环境准备
bash
测试对话
chat(“请介绍香橙派AIpro开发板的主要特性”)
chat(“如何在昇腾平台上优化LLM推理性能”)
优化说明
针对边缘设备资源受限特性,选择 1.5B 参数的蒸馏模型,平衡性能与效果;
模型转换时启用昇腾 310B 硬件优化,利用 TensorRT 加速推理;
最终推理延迟稳定在 420ms 左右,满足边缘端实时对话需求。
三、进阶开发核心优化思路
全栈协同优化:上层框架(MindSpore)的并行策略需与底层 CANN 的算子优化、硬件算力特性匹配,避免 “木桶效应”。
性能瓶颈定位:优先通过 MindStudio 工具识别瓶颈(如算子耗时占比、内存带宽限制),再针对性优化。
精度与性能平衡:大模型量化时采用 “关键层保精度、普通层提性能” 策略,通过校准工具控制精度损失。
场景化适配:云端训练侧重多卡并行与算力利用率,边缘部署侧重轻量化与低延迟。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)