
华为Atlas 300I Duo部署Qwen3-VL-8B多模态大模型
1. 说明
先大概说一下我部署的机器硬件:
- CPU 鲲鹏920(ARM架构)
- NPU 310P3(Atlas 300I Duo)
大家可以对号入座,看硬件条件是不是一致的。想使用该硬件部署vllm的朋友们,截止目前我还是不太推荐的,因为官方明确说明对该设备还处于实验性支持阶段,也就是说稳定性、性能等方面可能还存在一定的缺陷… 不过想尝试一下也没问题,一通百通😀
- 官方说明:https://docs.vllm.ai/projects/ascend/zh-cn/latest/index.html

2. 前期准备
- 硬件
| 硬件 | 内容 | 查询命令 | 截图 |
|---|---|---|---|
| CPU | Kunpeng-920 或 ARM架构的CPU均可 |
lscpu |  |
| NPU | 310P3(Atlas 300I Duo) | npu-smi info,查看具体类型: npu-smi info -t product -i {NPU ID} |
 |
- 软件
| 软件 | 版本 | 查询命令 |
|---|---|---|
| 显卡驱动 | 25.5.2 | npu-smi info |
| 固件版本 | 7.8.0.7.220 | npu-smi info -t board -i {NPU-ID} |
| vllm镜像版本 | v0.18.0rc1-310p | – |
| 多模态大模型 | Qwen3-VL-8B-Instruct | – |
注意:软件版本尽量和我保持一致,这是官方推荐的。使用旧的显卡驱动(如24.x,部署可能会遇到一堆问题),而且性能可能会很差,之前尝试使用过24.x显卡驱动+0.11.0版本vllm部署Qwen3-VL,踩了很多坑,虽然部署起来了,但是会遇到很多问题,比如:推理大图崩溃、推理耗时极长等(如果真想尝试,可以参考:https://github.com/vllm-project/vllm-ascend/issues/3860)。为了节省大家的时间,我这里整理了我使用的软件版本,大家可以自行下载:
| 软件 | 下载方法 |
|---|---|
| 显卡驱动及固件(商业版) | 网盘分享:https://pan.baidu.com/s/1Ff4cDolPhUWm0LZKxbBp-Q 提取码: qyjj |
| 显卡驱动及固件(社区版) | 华为升腾固件与驱动下载,我使用的商业版,社区版应该区别不大 |
| vllm镜像 | 镜像源地址,里边包含所有可用版本,或者直接 docker pull quay.io/ascend/vllm-ascend:v0.18.0rc1-310p |
| 多模态大模型 | huggingface下载地址 / modelscope下载地址 |
3. 部署
环境配置好以后,部署其实就很简单了,大家可以参考官方文档进行(vllm-ascend 文档)。主要分为以下几个步骤:
3.1 创建并启动容器
# vllm-ascend是我叫的容器名字,可以自行修改
# 我这边有8张卡,所以device全都映射了,可以自行修改
# 如果需要映射宿主机路径,自行添加 -v 进行映射
docker run -it --name vllm-ascend \
--shm-size=1g \
--privileged \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it quay.io/ascend/vllm-ascend:v0.18.0rc1-310p
bash
3.2 启动vllm
# Set `max_split_size_mb` to reduce memory fragmentation and avoid out of memory
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256
# 启动命令
vllm serve <你的实际路径>/Qwen3-VL-8B-Instruct/ --served-model-name Qwen3-VL-8B-Instruct --gpu-memory-utilization 0.75 --max-model-len 8192 --tensor-parallel-size 2 --enforce-eager --dtype float16
3.3 简单测试
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d "{\"model\":\"Qwen3-VL-8B-Instruct\",\"messages\":[{\"role\":\"user\",\"content\":[{\"type\":\"image_url\",\"image_url\":{\"url\":\"http://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg\"}},{\"type\":\"text\",\"text\":\"请描述一下图片\"}]}],\"max_tokens\":256}"
一般来说,到这就没问题了,如果有问题,可以留言,或者去 issues 里边找找有没有同类问题的解决方案。
到此,部署就正式完成了🎉🎉🎉,如果测试过的小伙伴,应该就明白为什么我不推荐在该设备上部署vllm了,因为推理速度太慢了,简直不忍直视啊。官方回复:目前仅支持eager模式,不支持图推理模式。后续是我做的一些简单测试,感兴趣的小伙伴可以看看。
4. 性能测试
1. 测试维度
- prompt:描述一下图片
- 图片尺寸:1920x1080、1280x720、640x480
- 输出长度:max_tokens=256、64、32
- 并发:1、8、16、32、64
- 每组请求数:64
- 统计指标
- avg latency:平均延迟(所有请求耗时加起来 ÷ 请求总数)
- p95 latency:95分位延迟(把所有请求耗时从小到大排序,取第95%位置的值)
- RPS:Requests Per Second(每秒能处理多少个请求)
- total tokens/s:每秒模型总共处理多少token
- prompt tokens:提示词token数(输入给模型的token数量)
- completion tokens:模型输出回答的长度
2. 固定max_tokens=256,不同图片尺寸下的 p95 推理耗时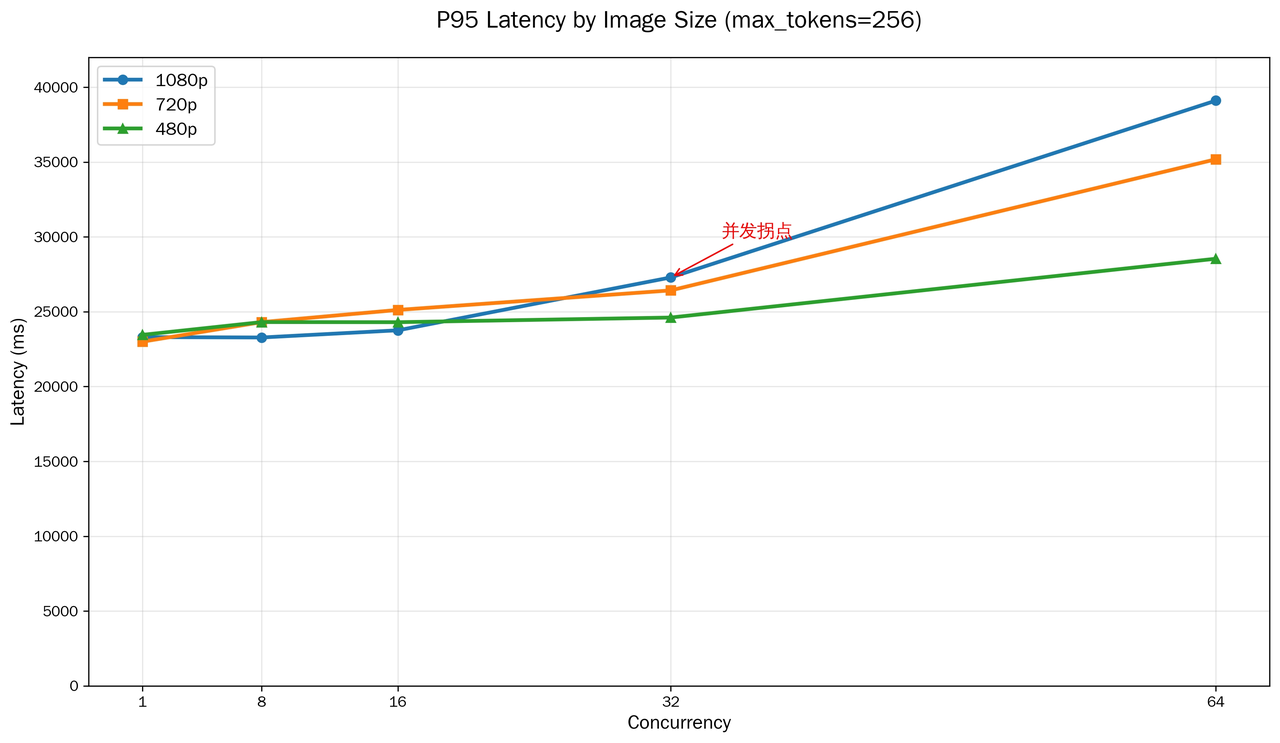
结论:
- 三种尺寸在 max_tokens=256 下,单请求耗时都在 23s+
- 图片尺寸缩小后,时延下降并不明显
- 当前场景中,图片尺寸不是主要瓶颈
3. 固定 1080p,不同max_tokens下的 p95 推理耗时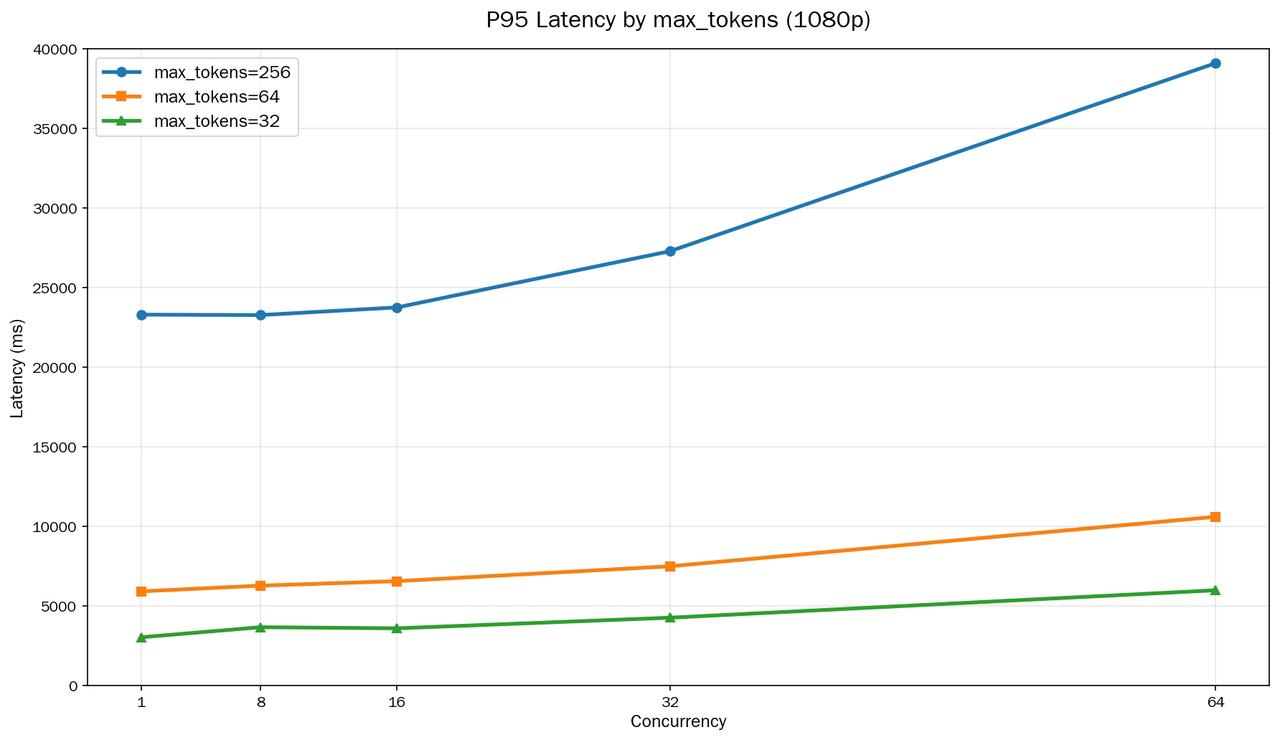
结论:
- max_tokens 对时延影响最明显
- 从 256 -> 64,时延大幅下降
- 从 64 -> 32,时延继续显著下降
- 输出长度越短,越接近在线响应需求
4. 固定 1080p,不同max_tokens下的吞吐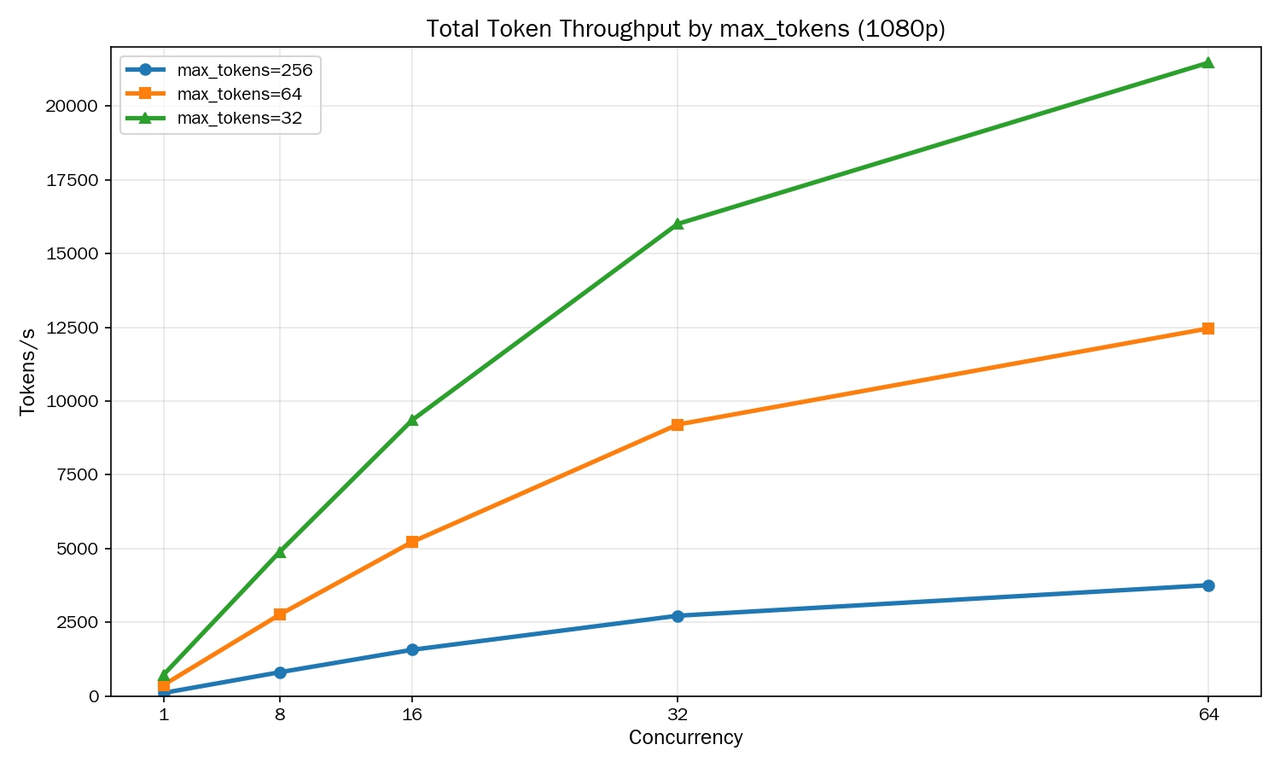
结论:
- 并发上升后,吞吐持续增加
- 建议并发在32左右最优
在我测试的数据中最优情况(图片尺寸:640x480,max_tokens:32,并发:32)P95 latency:~4.2s,整体来说,性能还是比较差的。当然以上仅为我做的简单测试,可能存在一定的偏差和遗漏,仅作参考🌹。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)