
Ascend C 算子开发(进阶)详细介绍及例题讲解
Ascend C 进阶开发聚焦昇腾 NPU 硬件特性深度挖掘与算子性能极致优化,核心目标是解决入门级开发中未覆盖的复杂场景(如超大张量运算、低延迟推理、多精度适配),通过 Tile 化编程、内存层级优化、并行策略设计等技术,让自定义算子性能逼近硬件理论上限,满足深度学习训练 / 推理中的高性能需求。报名链接:https://www.hiascend.com/developer/activities
Ascend C 算子开发(进阶)详解
1
一、进阶开发核心定位与目标
Ascend C 进阶开发聚焦 NPU 硬件特性深度挖掘与算子性能极致优化,核心目标是解决入门级开发中未覆盖的复杂场景(如超大张量运算、低延迟推理、多精度适配),通过 Tile 化编程、内存层级优化、并行策略设计等技术,让自定义算子性能逼近硬件理论上限,满足深度学习训练 / 推理中的高性能需求。
进阶开发需具备的基础:
掌握 Ascend C 入门级 Host-Device 编程模型、核函数基本语法;
了解昇NPU 达芬奇架构(计算单元、存储层次、指令集);
具备 C/C++ 编程基础与并行计算思维。
二、进阶核心概念深度解析
-
昇NPU 硬件架构与编程映射
(1)核心硬件组件
计算单元:Tensor Core(张量计算,支持矩阵乘加)、Vector Core(向量计算,支持元素级运算)、Scalar Core(标量计算,支持控制流);
存储层次(从快到慢):寄存器 > 共享内存(Shared Memory)> 全局内存(Global Memory)> 主机内存(Host Memory);
调度单元:线程块(Block)、线程束(Warp,32 个线程为一组)、线程(Thread)。
(2)编程映射关系
核函数 → 运行在 NPU 设备上,由多个 Block 并行执行;
Block → 映射到 NPU 的计算核心,每个 Block 包含多个 Thread;
Thread → 最小执行单元,通过 Thread ID 定位计算任务;
共享内存 → 每个 Block 独占,供内部 Thread 共享访问,替代频繁的全局内存读写。 -
三大进阶优化核心技术
(1)Tile 化编程(核心优化手段)
定义:将超大张量(如 1024×1024 矩阵)拆分为 NPU 硬件原生支持的小尺寸 Tile(如 32×32、16×16),让每个 Block/Thread 负责一个 Tile 的计算,适配硬件计算单元的并行粒度。
核心原则:Tile 尺寸需匹配 Tensor Core/Vector Core 的运算规格(如达芬奇架构推荐 Tile 尺寸为 32×32、64×64),避免计算单元闲置。
优势:减少全局内存访问次数,提升数据局部性,充分利用共享内存的高带宽特性。
(2)内存层级优化
寄存器:优先存储高频访问的临时变量(如 Tile 内元素、循环计数器),速度最快但容量最小(每个 Thread 仅几十 KB);
共享内存:缓存 Tile 子矩阵、中间计算结果,带宽是全局内存的 10 倍以上,需手动管理(通过__shared__关键字声明);
全局内存:存储输入输出张量等大数据,容量大但访问延迟高,需通过数据对齐、连续访问优化效率。
(3)并行策略设计
线程级并行:通过 Thread ID 分配不同计算任务,利用硬件多线程并发;
指令级并行:通过循环展开(#pragma unroll)、指令重排,让 CPU/NPU 同时执行多条不依赖的指令;
流水线并行:将计算流程拆分为 “数据加载→计算→结果存储” 等阶段,重叠执行不同阶段任务,减少等待时间。 -
多精度计算与量化
混合精度计算:结合 FP32(精度高)与 FP16/BF16(速度快、带宽占用低),核心计算用 FP16/BF16,关键步骤(如梯度更新)用 FP32 校准,平衡性能与精度;
INT8 量化:将 FP32 数据量化为 INT8(取值范围 - 128~127),计算速度提升 4 倍,内存带宽占用降低 75%,适用于推理场景(如分类、检测模型),需配合量化校准工具确保精度损失可控。 -
异步编程与流管理
计算流(Stream):NPU 的任务调度队列,每个 Stream 中的任务按顺序执行,不同 Stream 中的任务可并行执行;
异步操作:通过aclrtMemcpyAsync(异步内存拷贝)、aclmdlLaunchAsync(异步核函数启动),实现 “数据传输” 与 “计算” 重叠,减少整体耗时;
同步方式:aclrtSynchronizeStream(等待单个 Stream 完成)、aclrtSynchronizeDevice(等待设备所有任务完成)。
三、进阶开发流程(标准化步骤)
以 “优化版矩阵乘法算子(Tile 化 + 共享内存 + 混合精度)” 为例,完整拆解进阶开发流程: -
需求分析与方案设计
需求:实现 1024×1024 矩阵乘法(A×B=C),要求性能比入门级实现提升 5 倍以上,精度误差≤1e-5;
方案设计:
Tile 拆分:将 A(1024×1024)拆分为 32×32 的子矩阵(TileA),B 拆分为 32×32 的子矩阵(TileB);
内存优化:用共享内存缓存 TileA、TileB,减少全局内存访问;
并行策略:Thread 负责 Tile 内元素计算,Block 对应 Tile 维度,Grid 覆盖整个矩阵;
精度优化:采用 FP16 混合精度计算,提升吞吐量。 -
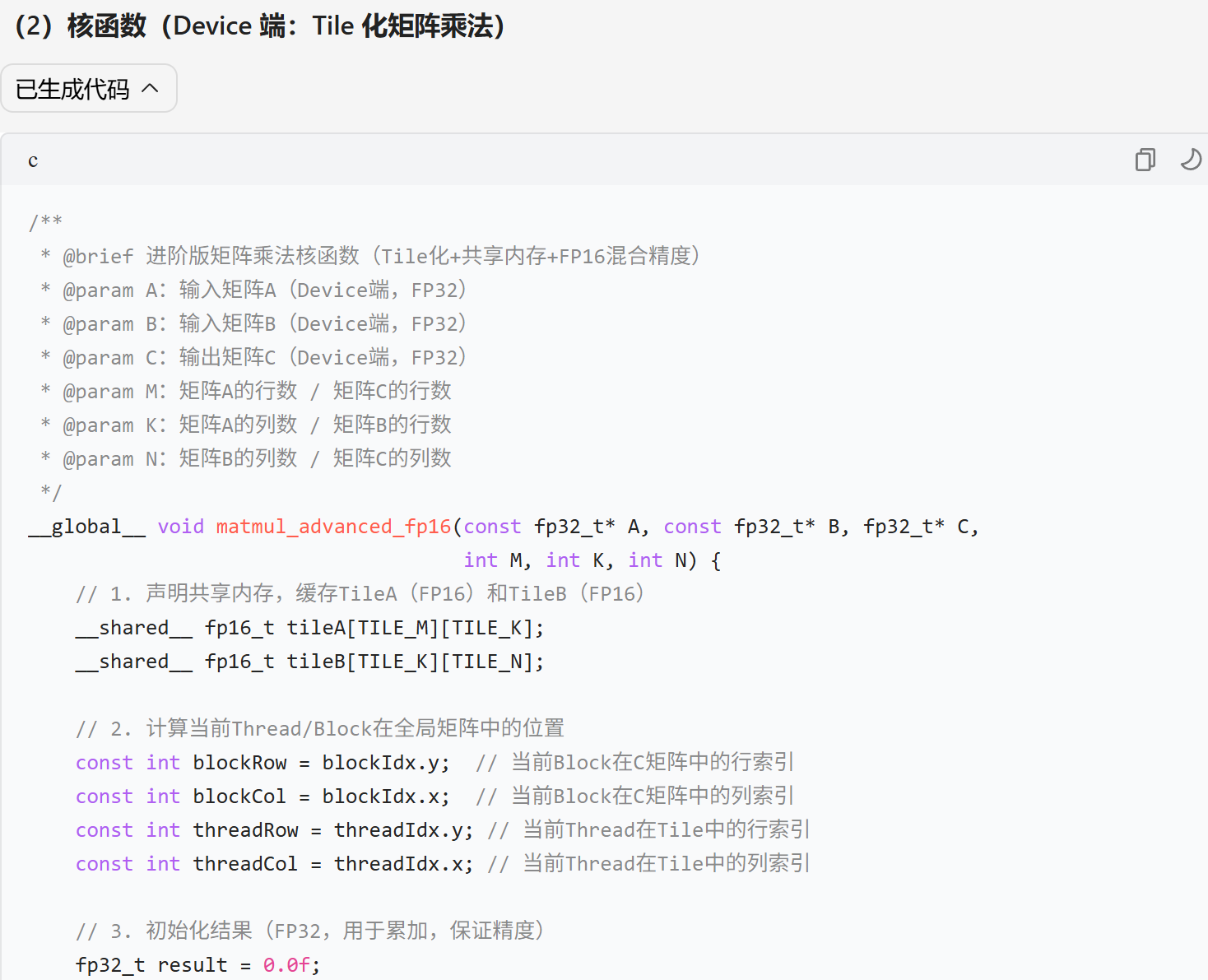
核函数实现(Device 端)
核心逻辑:Tile 加载→共享内存缓存→Tile 内计算→结果累加→全局内存写入。 -
主机侧调度(Host 端)
核心逻辑:设备初始化→内存分配→数据传输→核函数异步启动→结果同步→资源释放。 -
编译与调试
编译:使用ascend-clang编译器,开启 O3 优化,指定目标芯片;
调试:用 Ascend Debugger 查看核函数执行状态,排查内存越界、同步错误;
性能分析:用 Ascend Profiler 分析计算耗时、内存带宽利用率,定位瓶颈。 -
精度与性能验证
精度验证:与 CPU 版本矩阵乘法结果对比,计算误差(如 MAE、RMSE);
性能验证:测试算子吞吐量(GFLOPS)、延迟(ms),对比优化前后效果。
四、进阶例题:优化版矩阵乘法算子(Tile 化 + 共享内存 + FP16 混合精度) -
例题背景
入门级矩阵乘法算子直接访问全局内存,存在访问延迟高、并行度低的问题。本例题通过 Tile 化拆分、共享内存缓存、FP16 混合精度、异步编程等进阶技术,实现性能大幅提升。 -
核心优化点
优化技术 具体实现方式
Tile 化拆分 设 Tile 尺寸为 32×32,匹配达芬奇架构 Tensor Core 运算规格
共享内存缓存 用__shared__声明共享内存,缓存 TileA、TileB,替代全局内存频繁读写
混合精度计算 输入输出用 FP32,Tile 内计算用 FP16,通过类型转换平衡性能与精度
循环展开 用#pragma unroll 4展开内积循环,提升指令级并行
异步编程 用aclrtMemcpyAsync和计算流,实现数据传输与计算重叠
线程维度优化 Block 维度匹配 Tile 尺寸,Grid 维度覆盖整个矩阵,充分利用硬件并行资源


-
并行计算与流水线
4.1 计算流水线设计
class ComputePipeline {
private:
enum PipelineStage {
STAGE_LOAD,
STAGE_COMPUTE,
STAGE_STORE,
STAGE_COUNT
};
PipelineStage current_stage;
public:
void ThreeStagePipeline() {
// 三阶段流水线:加载-计算-存储
for (int tile_idx = 0; tile_idx < total_tiles; ++tile_idx) {
// 阶段1: 数据加载 (与上一轮计算并行)
if (tile_idx > 0) {
wait_compute(); // 等待上一轮计算完成
}
async_load(tile_idx);
// 阶段2: 计算 (与上一轮存储和下一轮加载并行)
if (tile_idx > 1) {
wait_store(); // 等待上一轮存储完成
}
async_compute(tile_idx - 1);
// 阶段3: 结果存储
if (tile_idx > 2) {
async_store(tile_idx - 2);
}
}
// 处理流水线尾部的数据
wait_compute();
async_store(total_tiles - 2);
wait_store();
async_store(total_tiles - 1);
wait_store();
}
};
4.2 向量化计算
void VectorizedCompute(__lm__ float* input,
__lm__ float* output,
int length) {
const int vec_len = 8; // 8个float的向量
for (int i = 0; i < length; i += vec_len) {
// 加载向量数据到寄存器
float32x8_t vec_a = load_vector(input + i);
float32x8_t vec_b = load_vector(weights + i);
// 向量运算
float32x8_t vec_result = vec_a * vec_b + vec_bias;
// 激活函数 (ReLU)
vec_result = max(vec_result, 0.0f);
// 存储结果
store_vector(output + i, vec_result);
}
}
```5. 复杂算子实现
5.1 卷积算子实现
```cpp
class Conv2DOperator {
private:
int input_h, input_w, output_h, output_w;
int kernel_h, kernel_w, stride, padding;
public:
void Conv2DCompute(__gm__ float* input,
__gm__ float* kernel,
__gm__ float* output) {
// 分块计算卷积
for (int oh = 0; oh < output_h; ++oh) {
for (int ow = 0; ow < output_w; ++ow) {
float sum = 0.0f;
// 卷积核滑动窗口
for (int kh = 0; kh < kernel_h; ++kh) {
for (int kw = 0; kw < kernel_w; ++kw) {
int ih = oh * stride - padding + kh;
int iw = ow * stride - padding + kw;
if (ih >= 0 && ih < input_h && iw >= 0 && iw < input_w) {
float input_val = input[ih * input_w + iw];
float kernel_val = kernel[kh * kernel_w + kw];
sum += input_val * kernel_val;
}
}
}
output[oh * output_w + ow] = sum;
}
}
}
};
5.2 矩阵乘法优化
class MatMulOptimized {
public:
void BlockMatMul(__gm__ float* A, __gm__ float* B, __gm__ float* C,
int M, int N, int K) {
const int BLOCK_SIZE = 32;
// 分块矩阵乘法
for (int m_block = 0; m_block < M; m_block += BLOCK_SIZE) {
for (int n_block = 0; n_block < N; n_block += BLOCK_SIZE) {
for (int k_block = 0; k_block < K; k_block += BLOCK_SIZE) {
// 处理一个分块
ProcessBlock(A, B, C,
m_block, n_block, k_block,
min(BLOCK_SIZE, M - m_block),
min(BLOCK_SIZE, N - n_block),
min(BLOCK_SIZE, K - k_block));
}
}
}
}
private:
void ProcessBlock(__gm__ float* A, __gm__ float* B, __gm__ float* C,
int m_start, int n_start, int k_start,
int m_size, int n_size, int k_size) {
// 将数据块加载到本地内存
__lm__ float local_A[BLOCK_SIZE][BLOCK_SIZE];
__lm__ float local_B[BLOCK_SIZE][BLOCK_SIZE];
__lm__ float local_C[BLOCK_SIZE][BLOCK_SIZE];
// 数据搬运
LoadBlockA(A, local_A, m_start, k_start, m_size, k_size);
LoadBlockB(B, local_B, k_start, n_start, k_size, n_size);
// 分块矩阵乘
for (int i = 0; i < m_size; ++i) {
for (int j = 0; j < n_size; ++j) {
float sum = local_C[i][j];
for (int k = 0; k < k_size; ++k) {
sum += local_A[i][k] * local_B[k][j];
}
local_C[i][j] = sum;
}
}
// 写回结果
StoreBlockC(C, local_C, m_start, n_start, m_size, n_size);
}
};
- 性能优化技巧
6.1 内存访问优化
class MemoryOptimizer {
public:
void CacheFriendlyAccess() {
// 优化内存访问模式
for (int i = 0; i < height; ++i) {
// 连续内存访问
for (int j = 0; j < width; ++j) {
data[i * width + j] = process(data[i * width + j]);
}
}
}
void AvoidBankConflict() {
// 避免存储体冲突
const int stride = 17; // 质数步长
for (int i = 0; i < array_size; i += stride) {
result += array[i];
}
}
};
6.2 指令级优化
void InstructionLevelOptimization() {
// 使用内置函数
float32x8_t a = set_vector(1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f);
float32x8_t b = set_vector(2.0f, 2.0f, 2.0f, 2.0f, 2.0f, 2.0f, 2.0f, 2.0f);
// 融合乘加运算
float32x8_t result = fused_multiply_add(a, b, a);
// 使用特殊函数加速
float32x8_t sigmoid_result = sigmoid_vector(a);
}
- 综合例题讲解
7.1 例题一:批量归一化算子
问题描述
实现一个批量归一化算子,支持训练和推理两种模式。
解决方案
class BatchNormOperator {
private:
bool is_training;
float epsilon;
float momentum;
public:
void BatchNormForward(__gm__ float* input,
__gm__ float* output,
__gm__ float* running_mean,
__gm__ float* running_var,
__gm__ float* gamma,
__gm__ float* beta,
int N, int C, int H, int W) {
const int elements_per_channel = H * W;
for (int n = 0; n < N; ++n) {
for (int c = 0; c < C; ++c) {
// 计算当前批次的均值和方差
float mean = 0.0f, variance = 0.0f;
if (is_training) {
// 训练模式:计算当前batch的统计量
ComputeBatchStatistics(input, n, c, mean, variance);
// 更新运行统计量
running_mean[c] = momentum * running_mean[c] +
(1 - momentum) * mean;
running_var[c] = momentum * running_var[c] +
(1 - momentum) * variance;
} else {
// 推理模式:使用运行统计量
mean = running_mean[c];
variance = running_var[c];
}
// 归一化计算
NormalizeChannel(input, output, n, c,
mean, variance, gamma[c], beta[c]);
}
}
}
private:
void ComputeBatchStatistics(__gm__ float* input, int n, int c,
float& mean, float& variance) {
int start_idx = (n * C + c) * H * W;
float sum = 0.0f, sum_square = 0.0f;
// 向量化计算均值和方差
float32x8_t vec_sum = set_vector(0.0f);
float32x8_t vec_sum_square = set_vector(0.0f);
for (int i = 0; i < elements_per_channel; i += 8) {
float32x8_t vec_data = load_vector(input + start_idx + i);
vec_sum = vec_sum + vec_data;
vec_sum_square = vec_sum_square + vec_data * vec_data;
}
// 规约求和
mean = horizontal_sum(vec_sum) / elements_per_channel;
variance = horizontal_sum(vec_sum_square) / elements_per_channel - mean * mean;
}
void NormalizeChannel(__gm__ float* input, __gm__ float* output,
int n, int c, float mean, float variance,
float gamma, float beta) {
int start_idx = (n * C + c) * H * W;
float std = sqrt(variance + epsilon);
float scale = gamma / std;
float shift = beta - mean * scale;
// 向量化归一化
float32x8_t vec_scale = set_vector(scale);
float32x8_t vec_shift = set_vector(shift);
for (int i = 0; i < elements_per_channel; i += 8) {
float32x8_t vec_input = load_vector(input + start_idx + i);
float32x8_t vec_output = vec_input * vec_scale + vec_shift;
store_vector(output + start_idx + i, vec_output);
}
}
};
7.2 例题二:注意力机制算子
问题描述
实现多头注意力机制,支持矩阵乘、Softmax和缩放操作。
解决方案
class MultiHeadAttention {
private:
int num_heads;
int head_dim;
int seq_len;
float scale_factor;
public:
void AttentionForward(__gm__ float* Q, __gm__ float* K, __gm__ float* V,
__gm__ float* output, __gm__ float* attn_mask) {
const int batch_size = ...; // 从参数获取
const int d_model = num_heads * head_dim;
// 分头处理
for (int b = 0; b < batch_size; ++b) {
for (int h = 0; h < num_heads; ++h) {
// 获取当前头的Q、K、V
__gm__ float* head_Q = Q + b * num_heads * seq_len * head_dim +
h * seq_len * head_dim;
__gm__ float* head_K = K + b * num_heads * seq_len * head_dim +
h * seq_len * head_dim;
__gm__ float* head_V = V + b * num_heads * seq_len * head_dim +
h * seq_len * head_dim;
// 计算注意力分数
ComputeAttentionScores(head_Q, head_K, head_V, output, attn_mask, b, h);
}
}
}
private:
void ComputeAttentionScores(__gm__ float* Q, __gm__ float* K, __gm__ float* V,
__gm__ float* output, __gm__ float* attn_mask,
int batch, int head) {
// Q * K^T
__lm__ float scores[seq_len][seq_len];
MatrixMultiply(Q, K, scores, seq_len, head_dim, seq_len, true);
// 缩放
ScaleScores(scores, scale_factor);
// 应用注意力掩码
if (attn_mask != nullptr) {
ApplyAttentionMask(scores, attn_mask, batch, head);
}
// Softmax
Softmax(scores);
// 注意力权重 * V
__lm__ float head_output[seq_len][head_dim];
MatrixMultiply(scores, V, head_output, seq_len, seq_len, head_dim, false);
// 存储结果
StoreHeadOutput(head_output, output, batch, head);
}
void MatrixMultiply(__lm__ float* A, __lm__ float* B, __lm__ float* C,
int M, int N, int P, bool transpose_B) {
// 分块矩阵乘法
const int BLOCK_SIZE = 16;
for (int i = 0; i < M; i += BLOCK_SIZE) {
for (int j = 0; j < P; j += BLOCK_SIZE) {
for (int k = 0; k < N; k += BLOCK_SIZE) {
// 处理分块
ProcessMatrixBlock(A, B, C, i, j, k,
min(BLOCK_SIZE, M - i),
min(BLOCK_SIZE, N - k),
min(BLOCK_SIZE, P - j),
transpose_B);
}
}
}
}
void Softmax(__lm__ float* scores) {
for (int i = 0; i < seq_len; ++i) {
// 找到最大值(数值稳定性)
float max_val = scores[i * seq_len];
for (int j = 1; j < seq_len; ++j) {
max_val = max(max_val, scores[i * seq_len + j]);
}
// 计算指数和
float sum = 0.0f;
for (int j = 0; j < seq_len; ++j) {
scores[i * seq_len + j] = exp(scores[i * seq_len + j] - max_val);
sum += scores[i * seq_len + j];
}
// 归一化
for (int j = 0; j < seq_len; ++j) {
scores[i * seq_len + j] /= sum;
}
}
}
};
7.3 例题三:自定义激活函数算子
问题描述
实现GELU(Gaussian Error Linear Unit)激活函数,支持向量化计算。
解决方案
class GELUOperator {
public:
void GELUForward(__gm__ float* input, __gm__ float* output, int total_elements) {
const float sqrt_2_over_pi = 0.7978845608028654f; // sqrt(2/π)
const float coef = 0.044715f;
// 向量化常数
float32x8_t vec_sqrt_2_over_pi = set_vector(sqrt_2_over_pi);
float32x8_t vec_coef = set_vector(coef);
float32x8_t vec_one = set_vector(1.0f);
float32x8_t vec_half = set_vector(0.5f);
for (int i = 0; i < total_elements; i += 8) {
float32x8_t vec_x = load_vector(input + i);
// GELU公式: 0.5 * x * (1 + tanh(sqrt(2/π) * (x + 0.044715 * x^3)))
float32x8_t vec_x3 = vec_x * vec_x * vec_x;
float32x8_t vec_inner = vec_x + vec_coef * vec_x3;
float32x8_t vec_tanh_input = vec_sqrt_2_over_pi * vec_inner;
// 近似tanh计算(使用多项式近似)
float32x8_t vec_tanh = FastTanh(vec_tanh_input);
float32x8_t vec_result = vec_half * vec_x * (vec_one + vec_tanh);
store_vector(output + i, vec_result);
}
}
private:
float32x8_t FastTanh(float32x8_t x) {
// 使用多项式近似tanh函数
// tanh(x) ≈ x - x^3/3 + 2x^5/15 - 17x^7/315
float32x8_t x2 = x * x;
float32x8_t x3 = x * x2;
float32x8_t x5 = x3 * x2;
float32x8_t x7 = x5 * x2;
float32x8_t result = x - x3 * set_vector(1.0f/3.0f) +
x5 * set_vector(2.0f/15.0f) -
x7 * set_vector(17.0f/315.0f);
return result;
}
};
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)