
大模型推理显存评估与影响因素分析
——作者:昇腾实战派
1. 背景
在开发过程中,我们经常遇到的一个问题是:部署某个大模型至少需要多少张显卡。虽然昇腾社区提供了模型支持列表,但该列表覆盖的模型有限,无法满足所有需求。
此外,在性能要求不高的场景中,出于成本考虑,我们往往希望用最少的卡数进行部署,因此需要自行评估显存需求。本文对大模型推理显存的评估方法及主要影响因素进行简要总结。
2. 经验法则估计
2.1 公式1

以Qwen3-14B模型为例,若使用FP16精度(每参数占2字节),则最小显存需求为:14 × 2 + 10 = 38 GB。此时可使用一张显存为64 GB的昇腾910B卡或一张48 GB的300I Duo卡进行推理。
2.2 公式2
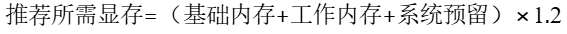
➢ 基础内存 = 模型参数量*精度
➢ 工作内存 = 激活值(包含kv cache和逐层计算释放的激活值)+ 临时缓存
➢ 系统预留:因为操作系统和其他程序也会占用显存资源,如果显存被模型完全占用,可能会导致系统不稳定甚至崩溃。根据经验,建议预留至少 500MB 到 1GB 的显存作为系统缓冲区。
如:Qwen3-14B模型,虽然在单卡910B4上可以运行,但推荐部署卡数为双卡,以保证性能和精度。
3. 精确计算方法与原理
| 显存占用的主要来源 | 说明 |
|---|---|
| 1. 模型参数(Model Parameters) | 如果希望获取最佳的推理性能需要将模型权重完全加载到显卡上,因此权重参数是显存占用的最大部分。 |
| 2. 激活值(Activations / KV Cache) | 激活值指的是前向传播过程中每一层的中间输出,在推理过程中大部分参数完成传播后会自行释放,除kv cache外需保留的部分只占总显存的1%左右可以忽略不计,但自回归生成的Key-Value 缓存(KV Cache)会一直保留,是推理时第二大显存开销。 |
| 3. 临时缓存(Temporary Buffers) | 部分临时变量,主要由框架动态分配,约占总显存的10%~20%。 |
3.1 模型参数
3.1.1 原理
模型参数是模型的核心权重,存储在显存中。每个参数的存储格式(精度FP16、INT8等)直接影响显存占用。
3.1.2 计算公式
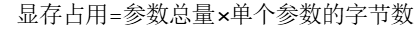
➢单个参数的字节数,取决于数据类型:
○ FP32(32位浮点数):4 字节
○ FP16/BF16(16位浮点数):2 字节
○ INT8(8位整型):1 字节
例如,Qwen3-14B模型有14B参数,使用FP16精度存储:
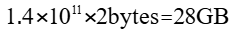
3.1.3 查看模型参数量:
部分模型直接标注参数量(如Qwen3-14B),未标注的模型可通过Hugging Face模型仓库等平台查询模型卡信息。例如,GLM-4.5的参数量为358B。
3.2 激活值(不含KV cache)
3.2.1 原理
激活值主要指的是模型在前向传播过程中产生的中间结果,其包含了各层的输出,并不单指激活函数相关的值,存储推理过程中每一层的中间结果,其大小与输入序列长度和模型的隐藏层大小直接相关。
对于推理任务,激活值具有逐层计算与释放的特点即每层激活值在计算完下一层后立即释放,不会长期占用。因此激活值在推理过程中占用显存相对较少,所以除kv cache外其他激活值对显存的占用几乎可以忽略。(在模型训练过程中,会存储前向传播的所有中间变量(激活)结果,称为 memory_activations,用以在反向传播过程中计算梯度时使用。)
| 类型 | 是否常驻 | 说明 |
|---|---|---|
| 1. 输入嵌入(Input Embeddings) | ✅ 是 | 序列长度 × 隐藏维度 |
| 2. 每层注意力输入/输出 | ❌ 否 | 计算完即释放,不累积 |
| 3. MLP 中间激活(如 SwiGLU) | ❌ 否 | 一般不缓存 |
| 4. KV Cache(Key/Value States) | ✅ 是 | 每层每头缓存,随序列增长 |
| 5. 残差连接输入 | ❌ 否 | 多数框架即时计算 |
| 6. LayerNorm 统计量 | ❌ 否 | 通常不缓存 |
3.3 KV-Cache
3.3.1 原理
理论上KV-Cache是激活值的子集,或者说是典型应用。在推理过程中大部分激活值完成当前层的前向传播后就会被释放,但是为了避免重复计算KV-Cache会被全部缓存,单独管理。
3.3.2 计算公式
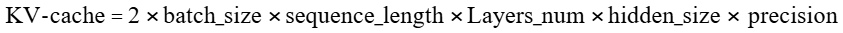
➢ 2:Key和Value两个矩阵各占一次存储
➢ batch_size:批大小
➢ sequence_length:序列长度即输入输出总token数
➢ Layers_num:模型层数
➢ hidden_size:Transformers的隐层维度
➢ precision:kv cache缓存精度,通常与模型精度一致
3.3.3 注意事项
kv cache的大小会随着序列长度线性增长,对于长文本推力需求需要提供更大的显存空间。
3.4 临时缓存
3.4.1原理:
临时缓存主要是框架开销,包括矩阵乘法、卷积等产生的中间变量,这些显存通常由框架动态分配,难以精确计算,估算值通常为模型参数和和激活值(含kv)总和的10%~20%。
4. 参考文献

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 0
0 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)