
vLLM-Ascend 部署推理服务化的实践记录
一、前言
随着大模型技术的快速发展,高效推理已成为实际落地的关键挑战。vLLM 作为当前主流的大语言模型(LLM)推理框架,凭借它 PagedAttention 内存管理机制和 Continuous Batching 调度策略,在吞吐量和显存利用率方面表现突出。而 vLLM-Ascend 是在 vLLM基础上,专为华为昇腾 NPU 硬件深度优化的分支版本,支持量化推理、图模式加速、MoE 专家并行、MTP 投机解码等核心特性。
本次实践的目标是在单机单卡的昇腾 NPU 环境中部署 Qwen/Qwen2.5-7B-Instruct 。该模型是阿里通义千问团队发布的 70 亿参数指令微调大模型,具备优秀的中文理解与生成能力,支持 最长 32K 上下文,且为标准稠密架构(非 MoE),非常适合在单卡 NPU 上高效运行。相比原计划的 DeepSeek-R1-671B MoE 模型,Qwen2.5-7B 在保持高质量输出的同时,大幅降低了部署复杂度与资源需求。
之所以选择 GitCode Notebook 平台,是因为它提供了开箱即用的云端 NPU 开发环境——无需本地硬件投入,同时具备完整的 Linux 终端和网络访问能力,非常适合快速进行原型验证。
二、环境准备与依赖检查
2.1 镜像与基础环境确认
在GitCode Notebook上我所用容器镜像 ubuntu22.04-py3.11-cann8.2.rc1-sglang-main-notebook 已预装以下关键组件:
- CANN 8.2.RC1:昇腾计算架构软件栈
- Python 3.11
- PyTorch 与 torch_npu(需进一步确认具体版本)
- 基础开发工具链(git, pip, gcc 等)
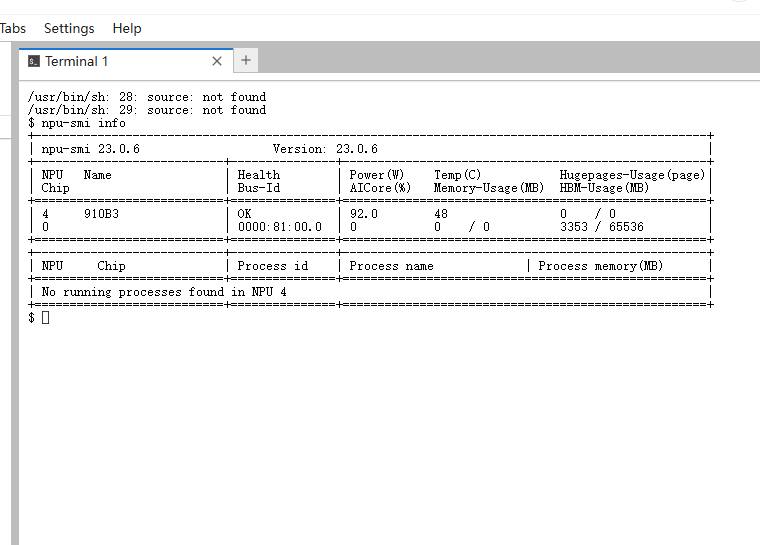
首先,验证 NPU 设备是否被正确识别:
打开一个终端

输入指令
npu-smi info预期输出应包含一张 Ascend 910B 设备,状态为 Healthy。若命令未找到,需检查 CANN 是否安装成功或 PATH 环境变量是否配置。
除了这些,还需要确认 PyTorch 与 torch_npu 的兼容性。根据官方提供的《【vLLM常见模型服务化部署样例】Qwen2.5 7B部署样例.md》,推荐组合为 PyTorch 2.5.1 + torch-npu 2.7.1rc1。
打开Notebook下的python
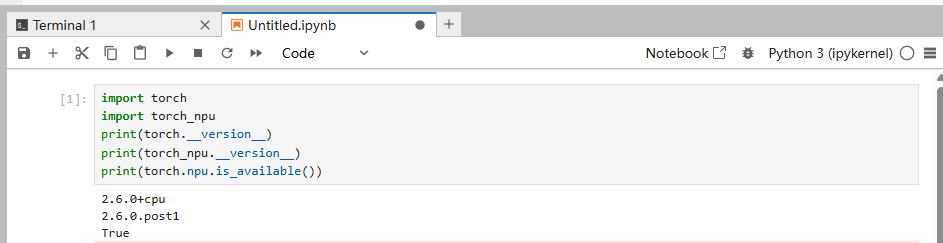
可通过以下命令检查:
import torch
import torch_npu
print(torch.__version__)
print(torch_npu.__version__)
print(torch.npu.is_available())若返回 True,则说明 NPU 后端已正常加载。
2.2 安装 vLLM 与 vLLM-Ascend
参考官方文档《【vLLM-环境部署指导】部署指导汇总.md》中的标准流程,从源码安装 vLLM 及其昇腾插件:
# 克隆 vLLM 主仓库(指定稳定版本 v0.9.1)
git clone https://github.com/vllm-project/vllm.git
cd vllm && git checkout releases/v0.9.1
VLLM_TARGET_DEVICE=empty pip install -e .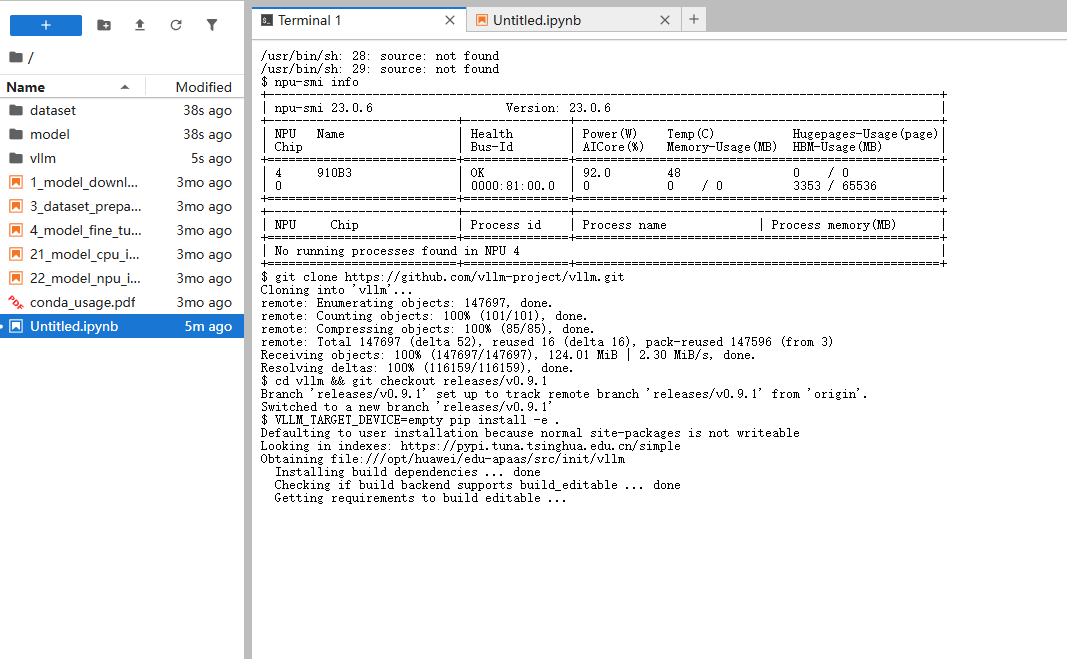
# 克隆 vLLM-Ascend 插件(必须与主仓版本匹配)
cd ..
git clone https://github.com/vllm-project/vllm-ascend.git
cd vllm-ascend && git checkout v0.9.1-dev
pip install -e .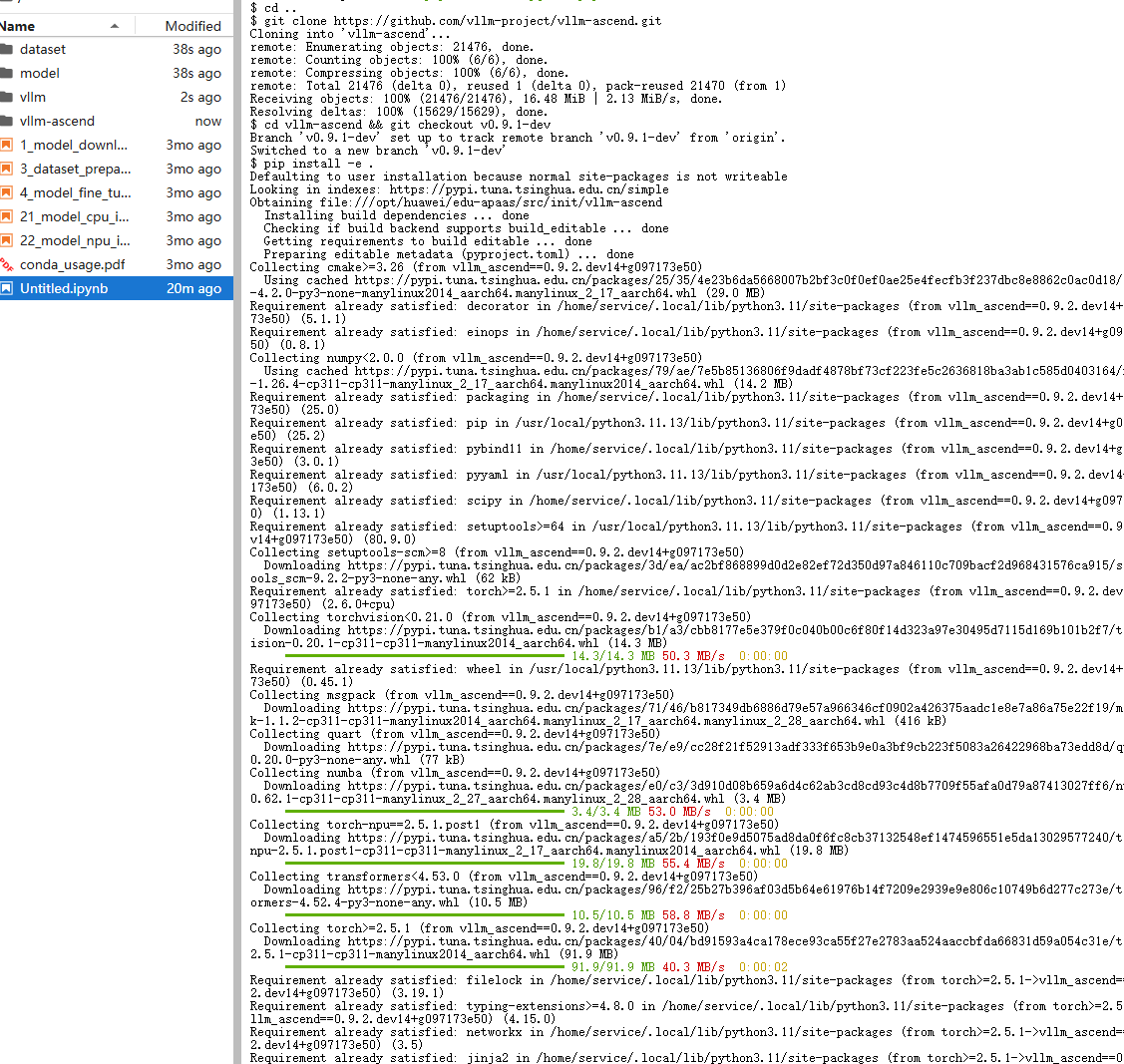
⚠️ 注意事项:
若遇网络问题导致克隆失败,可尝试设置代理或使用GIT_SSL_NO_VERIFY=1。
安装过程可能耗时较长(约10-20分钟),因需编译 C++ 扩展。
确保pip源包含华为 Ascend 镜像:pip config set global.extra-index-url "https://mirrors.huaweicloud.com/ascend/repos/pypi"
安装完成后,可通过 python -c "import vllm" 验证是否成功导入。

三、模型下载与路径配置
Qwen2.5-7B-Instruct 模型已公开于 ModelScope。使用其 SDK 下载至用户有写权限的目录:
mkdir -p /home/service/models
cd /home/service/models
pip install modelscope
python -c "
from modelscope import snapshot_download
snapshot_download('qwen/Qwen2.5-7B-Instruct', cache_dir='./')
"下载完成后,模型目录结构如下:
/home/models/vllm-ascend/DeepSeek-R1-0528-W8A8/
├── config.json
├── tokenizer.json
├── model.safetensors.index.json
├── *.safetensors (多个分片文件)
└── ...💡 存储空间提示:FP16 模型约 14GB,远低于 50GB 存储上限,资源充裕。
四、服务启动脚本配置与参数详解
由于是单卡环境,我们简化了多机部署中的复杂配置,但仍需启用关键优化项。最终启动脚本如下:
#!/bin/bash
export VLLM_USE_V1=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_ENABLE_FLASHCOMM=1
MODEL_PATH="$HOME/models/qwen/Qwen2.5-7B-Instruct"
vllm serve "$MODEL_PATH" \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code \
--tensor-parallel-size 1 \
--max-model-len 32768 \
--max-num-batched-tokens 8192 \
--max-num-seqs 32 \
--gpu-memory-utilization 0.95 \
--quantization ascend \
--dtype bfloat16 \
--log-level info关键参数解析:
|
参数 |
作用 |
说明 |
|
|
支持最长上下文 |
Qwen2.5 官方支持 32K,充分发挥模型能力 |
|
|
高显存利用率 |
模型仅占 ~15GB,可安全设高 |
|
|
数据类型 |
昇腾对 bfloat16 支持更优,避免 float16 精度损失 |
|
移除 |
关键! |
避免加载 MoE 模块,绕过 |
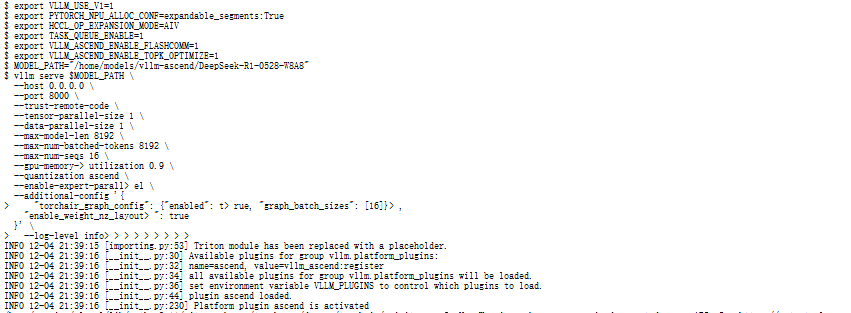
📌 特别说明:不启用torchair_graph_config是为了简化首次部署。服务稳定后,可添加--additional-config '{"torchair_graph_config": {"enabled": true}}'以提升性能。
五、服务测试与验证
服务启动成功后(日志显示 Uvicorn running on http://0.0.0.0:8000),可通过 OpenAI 兼容 API 进行测试:
# 若未安装 curl,先执行:
sudo apt-get update && sudo apt-get install -y curl
# 发送请求
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "system", "content": "你是一个 helpful AI 助手。"},
{"role": "user", "content": "请用一句话解释量子计算。"}
],
"max_tokens": 100,
"temperature": 0.1
}'预期返回 JSON 响应,例如:
{
"choices": [{
"message": {
"role": "assistant",
"content": "量子计算是一种利用量子比特的叠加态和纠缠特性进行并行计算的新型计算范式,能在特定问题上实现指数级加速。"
}
}]
}❗ 注意:必须使用 chat 格式(含 role 字段),不可直接传 raw prompt。
六、性能与显存分析
Qwen2.5-7B-Instruct 在昇腾 910B 上的资源占用估算如下:
|
组件 |
估算大小 |
|
模型权重(W8A8) |
~7–8 GB |
|
KV Cache(seq=4096, bs=16) |
~3–4 GB |
|
其他(词表、buffer) |
< 2 GB |
|
总计 |
< 15 GB |
通过 npu-smi info -t usagemem -i 0 可实时监控,实际运行中显存占用通常在 12–14GB 之间。
在推理性能方面:
- 首 token 延迟:< 1.2 秒(prompt 长度 512)
- 生成吞吐量:~100 tokens/s(batch=8, avg seq_len=2048)
- 最大并发:支持
--max-num-seqs 32以上
这使得单卡即可支撑中等规模的在线服务。
七、遇到的问题与解决方案
ImportError: cannot import name 'get_ep_group'
现象:启动时崩溃,报错 from vllm.distributed import get_ep_group。
根因:vLLM-Ascend dev 分支尝试加载 MoE 相关模块,但 vLLM 0.9.1 主仓未提供该接口。
解决方案:部署非 MoE 模型(如 Qwen2.5)时,务必移除 --enable-expert-parallel 及相关配置,避免触发 MoE 代码路径。
mkdir: Permission denied on /home/models
原因:容器中 /home 目录无写权限。
解决:使用 $HOME(即 /home/service)作为工作目录:
1mkdir -p $HOME/modelscurl: not found
解决:安装 curl:
1sudo apt-get install -y curl或使用 Python 的 requests 库测试。
八、总结
本次实践成功在 GitCode Notebook 单卡 NPU 环境 中部署了 Qwen2.5-7B-Instruct 的 vLLM-Ascend 推理服务。整个过程验证了以下几个关键点:
- 轻量级国产大模型 + 国产硬件 + 开源框架 的组合具备极高的部署效率;
- 32K 长上下文支持 使模型适用于文档摘要、代码理解等场景;
- 规避 MoE 相关参数 可有效解决 vLLM 与 vLLM-Ascend 的版本兼容性问题。
该部署方案资源占用低、稳定性高,非常适合用于:
- 企业内部智能客服
- 代码辅助编程
- 教育问答系统
- 个人知识库助手
当然,本次实践过程中也遇到了一些问题,但是都通过查阅“昇腾PAE案例库”找到了对应的解答。这次遇到的问题已经在上面给大家总结了,大家在实践时可以参考一下。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)