
技术时刻丨正则表达式次数符号“{}“在Oracle和openGauss中的差异
而为什么之前的业务代码中会有这个*,我猜想大概是当时的开发人员写的(\${1})匹配不到想要的数据时,发现加一个*就能匹配上,就这么用下去了,而该套系统多年以来,从未有超过9个参数的模板,因此该BUG一直未被人发现,直到进行本次国产化改造才挖出来。公司以“数据驱动,成就未来”为使命,致力于将创新的数据技术产品和解决方案带给全球的企业和组织,帮助客户构建安全、高效、敏捷且经济的数据环境,持续增强客户
一、前言
正则作为一种常用的字符串处理方式,在各种开发语言,甚至数据库中,都有自带的正则函数。但是正则函数有很多标准,不同标准对正则表达式的解析方式不一样,本次在迁移一个Oracle数据库到openGauss时发现了一个关于{}的差异点。
二、{}是做什么用的
在绝大部分的正则表达式规则中{}表示对前面字符的重复次数,支持的形式为 {m}、{m,}、{,n}、{m,n},其中m和n均为自然数,例如:
|
表达式 |
说明 |
|
b{1} |
匹配1次b |
|
b{2,} |
匹配2次到无穷次b |
|
b{,3} |
匹配0次到3次b |
|
b{2,3} |
匹配2次到3次b |
三、{}的使用歧义
以下三条SQL均可以在Oracle中执行:
--匹配一个 $符号,此时 {}里的1表示 $的出现次数select regexp_substr('aaaa${1}bbb','(\${1})') from dual;
--匹配${0个或任意个数的1},此时{}以及{}内的字符按照字符串识别select regexp_substr('aaaa${1}bbb','(\${1*})') from dual;
--匹配 ${一个空格加上0个或任意个数的1} ,此时{}以及{}内的字符按照字符串识别select regexp_substr('aaaa${ }bbb','(\${ 1*})') from dual;这里的规则在Oracle中大概可以这么描述:
{}内如果不满足 {m}、{m,}、{,n}、{m,n}这四者之一的格式,则{}不作为次数的声明符号,而是作为常规字符串进行识别。
但是上面第二个表达式在openGauss中会报错,因为这里还有一个规则:如果{}内的第一个字符是数字,则开始进入次数的解析逻辑,若解析不符合次数的规则,就报错。
查看openGauss源码,发现这段逻辑来自1998年的PG源码,数十年来未曾变过。
这里注意,此处并非BUG,只是正则标准不一致,我使用了7种开发语言来验证,发现JAVA和RUST中也同样是报错的,而PHP/JS/PYTHON/.NET/GO 中都不报错。
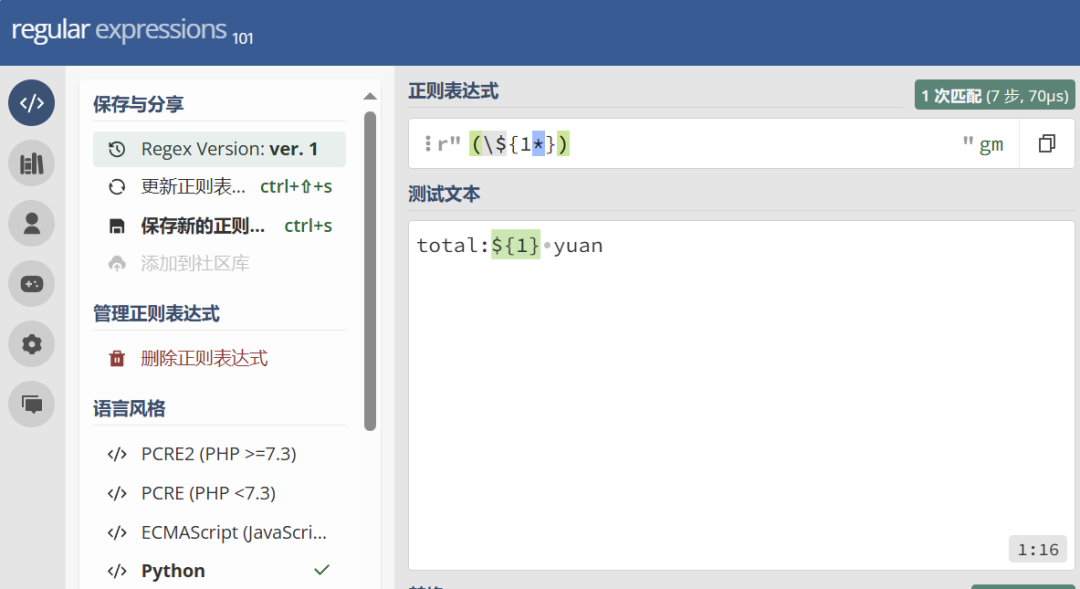
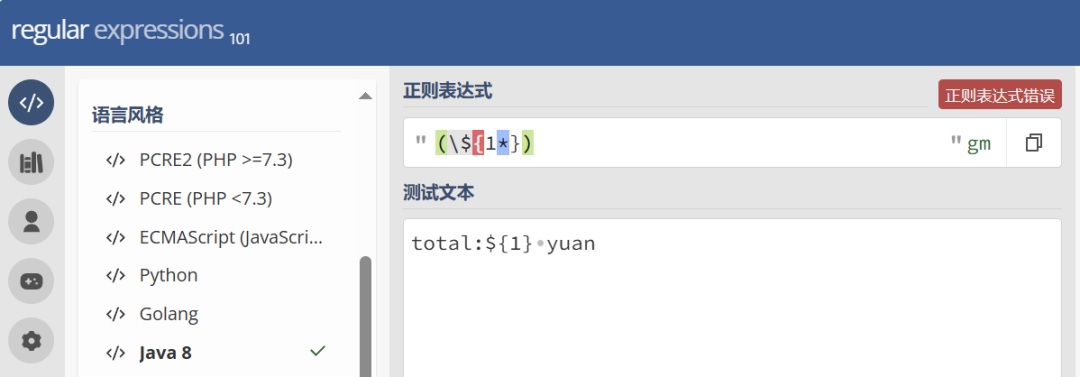
可以使用以下链接测试该正则表达式在不同开发语言中的表现:https://regex101.com/r/APc3is/1
四、相关源码
使用openGauss分析这个逻辑的时候,我断了几个点,找了几段源码:
6 breakpoint keep y 0x0000000000fc4cd7 in parseqatom(vars*, int, int, state*, state*, subre*) at regcomp.cpp:915 breakpoint already hit 2 times7 breakpoint keep y 0x0000000000fc42c4 in parsebranch(vars*, int, int, state*, state*, int) at regcomp.cpp:719 breakpoint already hit 2 times8 breakpoint keep y 0x0000000000fc5040 in parseqatom(vars*, int, int, state*, state*, subre*) at regcomp.cpp:9659 breakpoint keep y 0x0000000000fc510c in parseqatom(vars*, int, int, state*, state*, subre*) at regcomp.cpp:984regc_lex.cpp, line 412.regcomp.cpp, line 966.当第一个字符是数字,而第二个不是期望的字符(0-9以及",“和”}"),就走到default报错
case '{': NEXT(); m = scannum(v); //扫描数字static int scannum(struct vars* v){ int n = 0; while (SEE(DIGIT) && n < DUPMAX) { n = n * 10 + v->nextvalue; NEXT(); } if (SEE(DIGIT) || n > DUPMAX) { ERR(REG_BADBR); return 0; } return n;}case L_EBND: switch (c) { case CHR('0'): case CHR('1'): case CHR('2'): case CHR('3'): case CHR('4'): case CHR('5'): case CHR('6'): case CHR('7'): case CHR('8'): case CHR('9'): RETV(DIGIT, (chr)DIGITVAL(c)); // {1*} 会在处理1的时候走到这里 break; case CHR(','): RET(','); break; case CHR('}'): /* ERE bound ends with } */ if (INCON(L_EBND)) { INTOCON(L_ERE); if ((v->cflags & REG_ADVF) && NEXT1('?')) { v->now++; NOTE(REG_UNONPOSIX); RETV('}', 0); } RETV('}', 1); } else FAILW(REG_BADBR); break; case CHR('\\'): /* BRE bound ends with \} */ if (INCON(L_BBND) && NEXT1('}')) { v->now++; INTOCON(L_BRE); RET('}'); } else FAILW(REG_BADBR); break; default: FAILW(REG_BADBR); // {1*} 会在处理*的时候走到这里 break; }有兴趣的可以自己下载源码去调试分析一下,这里我就不详细解读源码了。
五、其他国产数据库对{}的处理
DM8和YashanDB和Oracle保持一致,能在{}内不为次数时正确当成字符串;而其他几款基于PostgreSQL、openGauss的数据库以及纯自研的OceanBase在这种情况下都会报错(MySQL系不报错,但执行返回空)。
DM 8
SQL> select regexp_substr('aaaa${1}bbb','(\${1*})') ;LINEID REGEXP_SUBSTR('aaaa${1}bbb','(\${1*})')---------- ---------------------------------------1 ${1}YashanDB 23
SQL> select regexp_substr('aaaa${1}bbb','(\${1*})') from dual;REGEXP_SUBSTR('AAAA$--------------------${1}KingbaseES 9
kingbase=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;kingbase-# /ERROR: invalid regular expression: invalid repetition count(s)HighGO DB 6
highgo=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;ERROR: invalid regular expression: invalidGaussDB 503
gaussdb=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;ERROR: invalid regular expression: invalid repetition count(s)CONTEXT: referenced column: regexp_substropenGauss 6.0
openGauss=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;ERROR: invalid regular expression: invalid repetition count(s)CONTEXT: referenced column: regexp_substrGBASE 8c
postgres=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;ERROR: invalid regular expression: invalid repetition count(s)CONTEXT: referenced column: regexp_substrVastbase v2.2 build 16
postgres=# select regexp_substr('aaaa${1}bbb','(\${1*})') ;ERROR: invalid regular expression: invalid repetition count(s)CONTEXT: referenced column: regexp_substrOceanBase 4.3
执行以下 SQL 失败select regexp_substr('aaaa${1}bbb','(\${1*})') from dual失败原因:ErrorCode = 600, SQLState = 42000, Details = OBE-00600: internal error code, arguments: -5115, Got error 'U_REGEX_BAD_INTERVAL' from regexp六、回到业务应用
其实本文中这种歧义用法,虽然在Oracle中不报错,但是正确的编码方式应该是,对于想要识别成字符的保留符号,需要加上\进行转义,即(\$\{1*\})。
但结合实际业务规则来看,加转义的方式虽然看上去结果是对的,但逻辑其实是错的。
该段业务程序是在做模板字符串处理,系统中配置了多个字符串模板,模板中使用${1} ${2}这样的标记作为填充值的占位符。如果使用占位符使用到了 ${11} ,则(\$\{1*\})也能匹配上,导致结果错误。所以准确的做法应该为(\$\{1\}),即不应该有这个*,此时想替换第几个参数均能正确匹配。而为什么之前的业务代码中会有这个*,我猜想大概是当时的开发人员写的(\${1})匹配不到想要的数据时,发现加一个*就能匹配上,就这么用下去了,而该套系统多年以来,从未有超过9个参数的模板,因此该BUG一直未被人发现,直到进行本次国产化改造才挖出来。
七、总结
有很多所谓的"标准功能",在不同的环境下有不同的"标准",这些"标准"各有各的准则,经过多年的发展,很难强求其一致性。就连正则表达式这样常用的功能都有不同的标准,就不要指望ANSI SQL能让任意相同语句在每个数据库中执行结果完全一致了。在去O的过程中,经常能发现以往很多写得不标准的应用代码,此时正是好机会将这些代码变得更加规范。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 6
6 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)