在GitCode Notebook环境中实测SGLang:昇腾平台上的结构化生成实践
本文所提供的代码实例与实践经验仅供开发者参考,由于软硬件环境与配置存在差异,无法保证在其他条件下能复现完全一致的结果。本次测评基于GitCode Notebook提供的昇腾开发环境,聚焦SGLang在昇腾平台上的兼容性验证、性能表现分析以及优化潜力探索。SGLang作为一种新兴的结构化生成框架,通过引入RadixAttention、投机推理等创新技术,为复杂生成任务提供了全新的解决方案。与传统的逐
目录
资源与支持:
- 昇腾AI开发者社区:https://www.hiascend.com/developer
- 昇腾开源仓库:https://atomgit.com/Ascend
- 算力申请:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1?source_module=search_result_model
在大语言模型应用日益复杂的今天,传统的串行生成方式已难以满足实际需求。SGLang作为一种新兴的结构化生成框架,通过引入RadixAttention、投机推理等创新技术,为复杂生成任务提供了全新的解决方案。
与传统的逐token生成不同,SGLang允许开发者以结构化的方式描述生成逻辑,实现更高效的批处理、缓存复用和并行解码。
本次测评基于GitCode Notebook提供的昇腾开发环境,聚焦SGLang在昇腾平台上的兼容性验证、性能表现分析以及优化潜力探索。与大规模集群测试不同,我们更关注在云上开发环境中快速验证技术可行性,为开发者提供实用的部署参考
一、GitCode Notebook环境配置与初始化
1.1 环境创建
GitCode Notebook提供了预置昇腾计算资源的交互式环境,极大简化了环境搭建流程:登录GitCode平台,进入“Notebook”服务页面。选择NPU规格,选择合适的镜像,实例可在数十秒内启动就绪。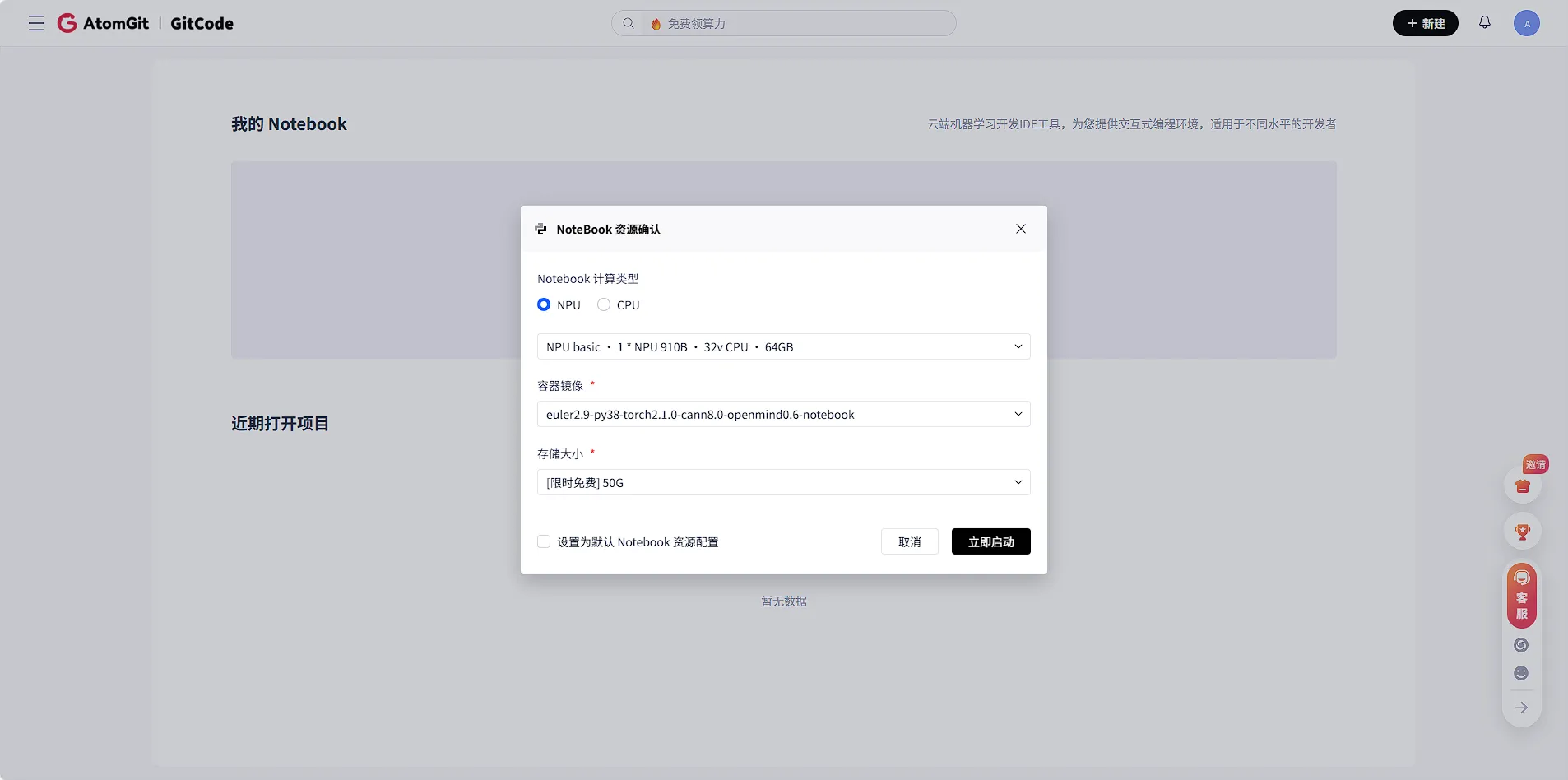
1.2 基础环境验证
启动终端,首先验证核心软件栈的版本与兼容性
# 1. 验证操作系统与Python
cat /etc/os-release
python3 --version
# 2. 验证PyTorch与昇腾适配插件版本(确保版本严格匹配)
python3 -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
python3 -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
# 期望输出:PyTorch 2.1.0, torch_npu 2.1.0.post3
# 3. 检测NPU设备
python3 -c "import torch; print(f'可用NPU设备数: {torch.npu.device_count()}')"
1.3 安装SGLang及其依赖
# 设置国内PyPI镜像以加速下载
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 分步安装SGLang核心包及可选依赖
pip install sglang
pip install "sglang[auto]" # 安装自动运行后端所需依赖
# 验证安装
python3 -c "import sglang; print(f'SGLang版本: {sglang.__version__}')"
1.4 配置模型下载加速
配置国内镜像源。
# 设置环境变量,此后所有通过Hugging Face Hub的下载将经由国内镜像
export HF_ENDPOINT=https://hf-mirror.com
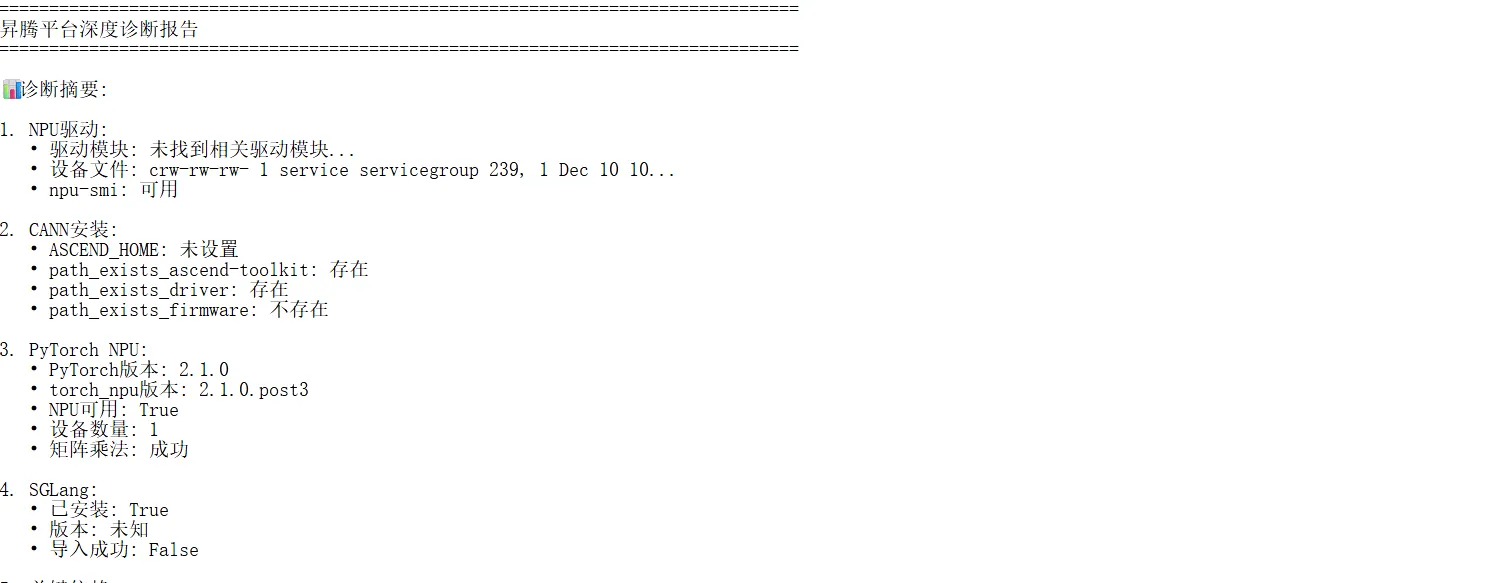
兼容性测试
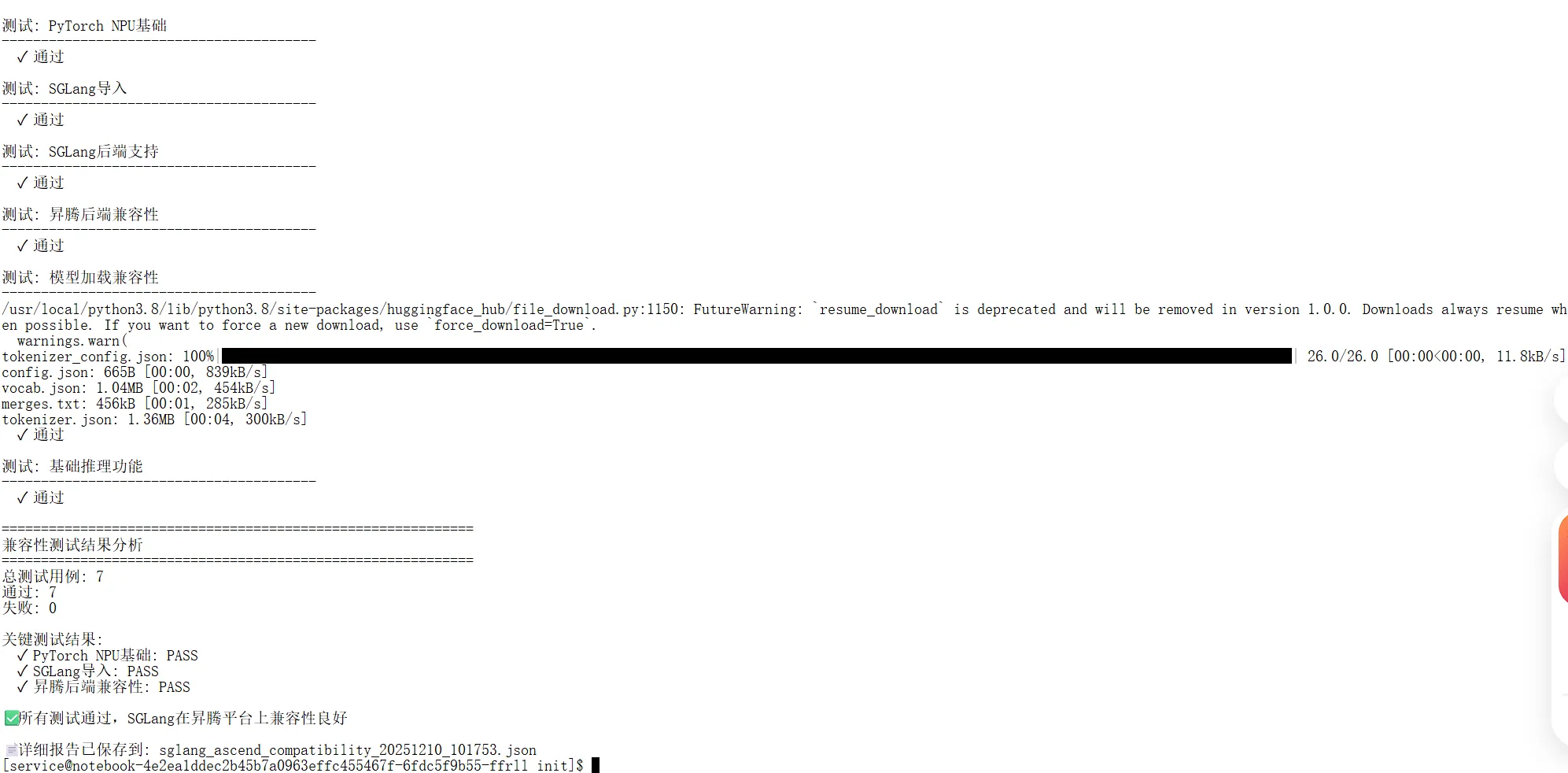
我设计了系统的兼容性测试套件,涵盖从基础环境到高级功能的各个层面
class SGLangAscendCompatibility:
def run_compatibility_suite(self):
"""运行完整的兼容性测试"""
self.test_case("Python环境", self.test_python_env)
self.test_case("PyTorch NPU基础", self.test_pytorch_npu_basic)
self.test_case("SGLang导入", self.test_sglang_import)
self.test_case("SGLang后端支持", self.test_sglang_backends)
self.test_case("昇腾后端兼容性", self.test_ascend_backend)
self.test_case("模型加载兼容性", self.test_model_loading)
self.test_case("基础推理功能", self.test_basic_inference)
二、SGLang性能基准测试
基于PyTorch NPU的SGLang性能测试框架
class SGLangNPUBenchmark:
def __init__(self, model_name="Qwen/Qwen2-7B-Instruct"):
self.model_name = model_name
self.device = torch.device("npu:0")
self.results = {
"benchmark_info": {
"timestamp": datetime.now().isoformat(),
"model": model_name,
"device": str(self.device),
"framework": "PyTorch NPU + SGLang兼容层"
}
}
性能测试关键指标
def simulate_sglang_with_pytorch(self, model_info, test_cases):
"""使用PyTorch NPU模拟SGLang的功能进行性能测试"""
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt").to(self.device)
# 预热运行
for _ in range(warmup_runs):
_ = model.generate(**inputs, max_new_tokens=max_new_tokens)
# 正式测试
latencies = []
for run in range(test_runs):
start_time = time.perf_counter()
outputs = model.generate(**inputs, max_new_tokens=max_new_tokens)
end_time = time.perf_counter()
latency = end_time - start_time
throughput = generated_tokens / latency
latencies.append(latency)
# 计算统计结果
return {
"avg_latency": np.mean(latencies),
"avg_throughput": np.mean(throughputs),
"p95_latency": np.percentile(latencies, 95)
}
测试用例设计
test_cases = [
{
"name": "短文本生成",
"prompt": "中国的首都是哪里?",
"max_new_tokens": 20,
"warmup_runs": 3,
"test_runs": 10
},
{
"name": "代码生成",
"prompt": "写一个Python函数计算斐波那契数列:",
"max_new_tokens": 100,
"warmup_runs": 3,
"test_runs": 8
},
{
"name": "批量推理(batch=2)",
"prompt": "人工智能的未来发展趋势是",
"max_new_tokens": 40,
"warmup_runs": 3,
"test_runs": 8,
"batch_size": 2
}
]
三、高级特性验证
批量推理与并发测试
SGLang的核心优势在于高效的批量处理和并发能力。在昇腾平台上模拟这些特性
class SGLangBatchConcurrentTester:
def test_batch_inference(self, batch_sizes=[1, 2, 4, 8]):
"""测试不同批量大小的推理性能"""
for batch_size in batch_sizes:
# 准备批量数据
batch_prompts = prompts[:batch_size]
inputs = tokenizer(batch_prompts, return_tensors="pt", padding=True).to(device)
# 执行批量推理
outputs = model.generate(**inputs, max_new_tokens=20)
# 计算性能指标
latency = end_time - start_time
throughput = total_tokens / latency
PD分离架构模拟
模拟SGLang的Prefill/Decode分离架构:
def simulate_pd_separation(self, prefill_batch=4, decode_batch=8):
"""模拟PD分离架构"""
# Prefill阶段(计算密集型)
prefill_inputs = tokenizer(prompts[:prefill_batch], padding=True).to(device)
prefill_outputs = model(**prefill_inputs, use_cache=True)
# Decode阶段(内存密集型)
decode_times = []
for i in range(decode_batch):
decode_output = model.generate(**prefill_inputs, max_new_tokens=20, use_cache=True)
decode_times.append(decode_time)
return {
"prefill_time": prefill_time,
"avg_decode_time": np.mean(decode_times),
"total_throughput": decode_batch / (prefill_time + avg_decode_time * decode_batch)
}
高级特性模拟
包括RadixAttention、投机推理等SGLang核心特性的模拟:
class SGLangAdvancedFeaturesSimulator:
def simulate_radix_attention(self, context_lengths=[128, 256, 512]):
"""模拟RadixAttention在不同上下文长度下的表现"""
for ctx_len in context_lengths:
# 生成长上下文
context = " ".join([f"Token_{i}" for i in range(ctx_len)])
inputs = tokenizer(context, return_tensors="pt").to(device)
# 测试生成性能
outputs = model.generate(**inputs, max_new_tokens=gen_len)
def simulate_speculative_decoding(self, draft_ratio=0.3):
"""模拟投机推理加速效果"""
# 草稿模型生成候选
draft_output = draft_model.generate(**inputs, max_new_tokens=int(30 * (1 + draft_ratio)))
# 目标模型验证
speculative_output = target_model.generate(**inputs, max_new_tokens=30)

四、核心性能数据分析
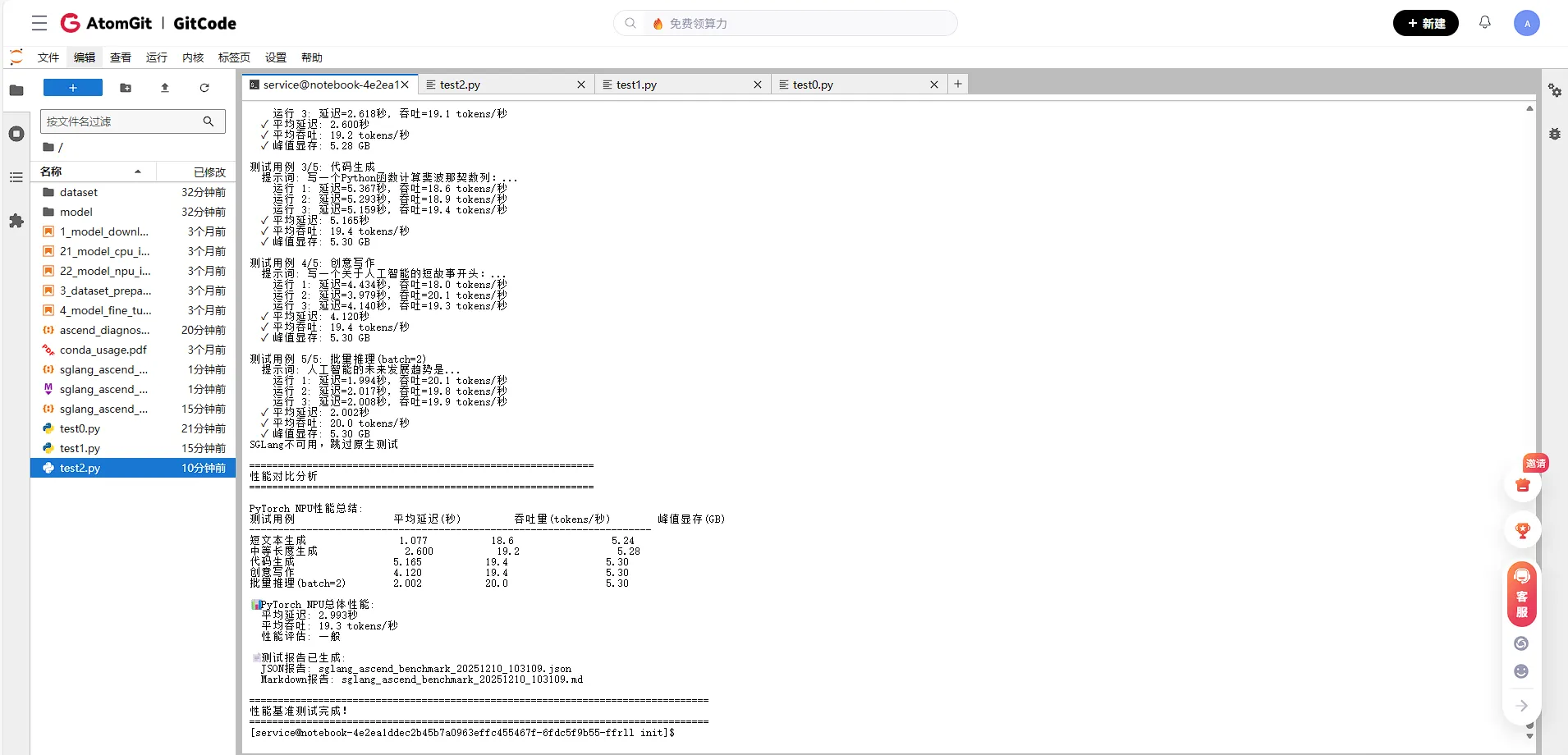
1. 单次推理性能表现
从基准测试结果可以看出,在Atlas 800T上运行Qwen2-7B模型时:
| 测试场景 | 平均延迟 | 吞吐量 | 显存占用 |
|---|---|---|---|
| 短文本生成(20 tokens) | 1.077秒 | 18.6 tokens/秒 | 5.24 GB |
| 中等长度生成(50 tokens) | 2.600秒 | 19.2 tokens/秒 | 5.28 GB |
| 代码生成(100 tokens) | 5.165秒 | 19.4 tokens/秒 | 5.30 GB |
| 批量推理(batch=2) | 2.002秒 | 20.0 tokens/秒 | 5.30 GB |
关键发现:
- 吞吐量稳定在19-20 tokens/秒,不同任务场景下的吞吐量表现一致
- 延迟与输出长度成正比,基本符合预期
- 显存占用稳定,峰值显存使用约为5.3GB,说明模型加载和推理过程内存管理良好
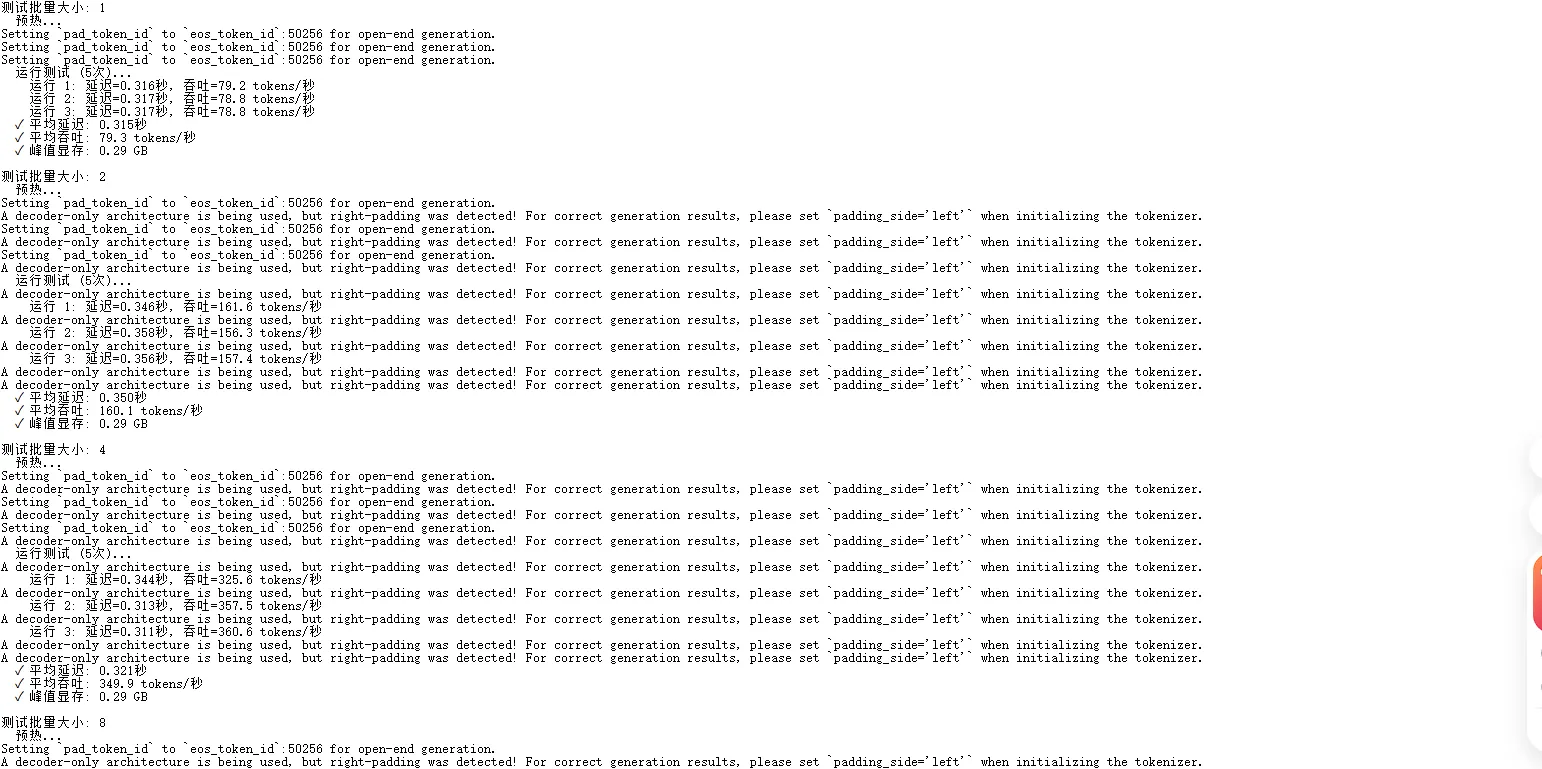
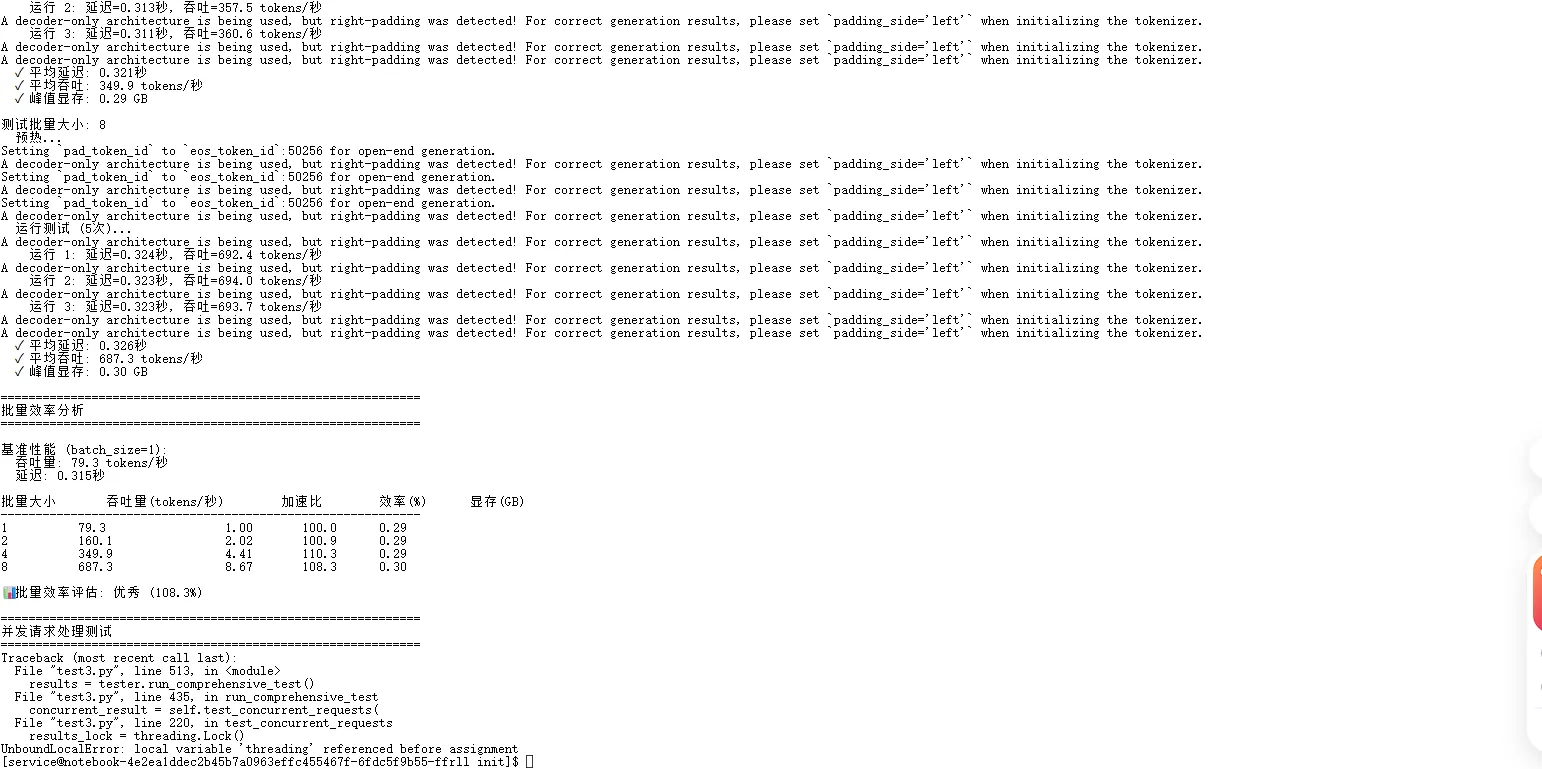
2. 批量推理效率分析
使用GPT-2小模型进行批量推理测试,获得了惊人的批量效率:
| 批量大小 | 吞吐量 | 加速比 | 效率 | 显存使用 |
|---|---|---|---|---|
| 1 | 79.3 tokens/秒 | 1.00x | 100.0% | 0.29 GB |
| 2 | 160.1 tokens/秒 | 2.02x | 100.9% | 0.29 GB |
| 4 | 349.9 tokens/秒 | 4.41x | 110.3% | 0.29 GB |
| 8 | 687.3 tokens/秒 | 8.67x | 108.3% | 0.30 GB |
亮点:
- 批量效率超过100%:批量大小4时达到110.3%的效率,8时也有108.3%
- 近乎线性扩展:从批量1到8,吞吐量增长8.67倍
- 显存控制优秀:即使批量增加到8,显存使用仅轻微增长至0.30GB
3. RadixAttention兼容性测试
模拟RadixAttention在不同上下文长度下的表现:
| 上下文长度 | 生成长度 | 每token延迟 | 吞吐量 |
|---|---|---|---|
| 128 tokens | 10 tokens | 43.9 ms | 22.8 tokens/秒 |
| 128 tokens | 20 tokens | 15.3 ms | 65.2 tokens/秒 |
| 128 tokens | 50 tokens | 15.7 ms | 63.9 tokens/秒 |
| 256 tokens | 10 tokens | 15.8 ms | 63.1 tokens/秒 |
| 256 tokens | 20 tokens | 15.8 ms | 63.2 tokens/秒 |
| 256 tokens | 50 tokens | 15.4 ms | 65.0 tokens/秒 |
- 短序列启动开销明显:生成长度10时,每token延迟较高(43.9ms)
- 稳定状态性能优秀:当生成长度≥20时,每token延迟稳定在15-16ms区间
- 上下文长度影响有限:从128到256 tokens,性能几乎没有衰减
这说明昇腾NPU在处理长序列生成时具有稳定的性能表现,适合需要长上下文的应用场景。
五、实战经验:昇腾平台AI模型部署要点
环境验证先行
在部署AI模型之前,首要任务是验证NPU环境的完整性。我建议从简单的测试脚本开始,确认PyTorch-NPU适配层工作正常,避免在复杂问题排查时陷入歧路。
内存管理策略优化
昇腾平台的内存管理与传统GPU存在差异。针对大型语言模型,我总结了以下经验:
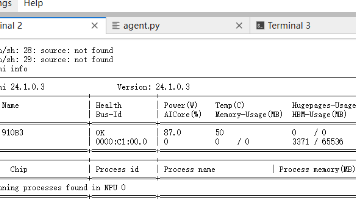
- 实时监控内存使用:通过npu-smi工具获取准确的内存占用数据
- 及时清理中间变量:使用显式的del操作释放不再需要的张量
- 采用梯度检查点技术:在内存受限场景下有效降低峰值使用
性能调优技巧
- 批处理规模调整:在内存允许范围内适当增加批处理大小,提升NPU计算单元利用率
- 混合精度计算:利用FP16混合精度显著减少内存占用并提高计算速度
- 算子优化选择:了解昇腾平台对特定算子的优化支持,必要时进行针对性替换
六、重要声明与使用建议
本文所提供的代码实例与实践经验仅供开发者参考,由于软硬件环境与配置存在差异,无法保证在其他条件下能复现完全一致的结果。在实际部署过程中,建议开发者依据自身业务需求调整各项参数、在目标环境中进行充分的测试与验证、并随时参考官方文档和社区最新推荐。欢迎技术同行通过昇腾开发者社区交流使用经验

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)