基于昇腾 NPU 部署 Llama-3-8B 实战教程:从环境搭建到构建昇腾问答智能体
本文介绍了在昇腾(Ascend)NPU平台上部署Meta-Llama-3-8B-Instruct大模型的全过程。首先通过npu-smi命令确认硬件状态,安装必要的Python依赖库后,从ModelScope社区下载模型权重文件。文章详细展示了基础推理测试的实现代码,包括环境配置、模型加载和推理生成等核心模块,并验证了模型在NPU上的运行效果。整个流程涵盖了从环境准备到实际部署的关键步骤,为开发者提
算力申请:https://ai.gitcode.com/ascend-tribe/openPangu-Ultra-MoE-718B-V1.1
模型地址:https://gitcode.com/test-oh-kb/Meta-Llama-3-8B-Instruct
前言
随着开源大模型生态的繁荣,越来越多的开发者开始探索在国产算力平台上运行主流模型。本文将详细记录如何在 昇腾(Ascend) 环境下,使用 ModelScope 社区提供的模型资源,通过AtomGit平台的notebook部署 Meta-Llama-3-8B-Instruct 模型,并基于此构建一个具备多轮对话能力的命令行智能体(Agent)。
一、 环境准备与硬件检查
在开始部署之前,首先确认 NPU 硬件状态是否正常。
1. 查看 NPU 信息
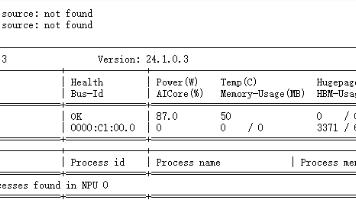
使用 npu-smi info 命令查看硬件详情。
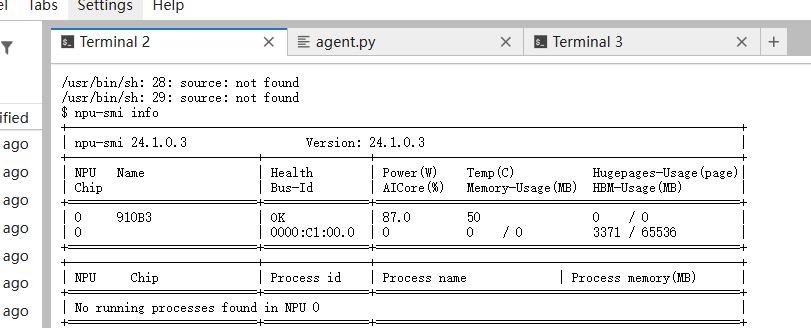
● NPU为昇腾 Atlas 800T 。
● Health: 显示为 OK,硬件状态良好。
● Memory: 显存(HBM)总共 64GB,当前占用极低,足以运行 8B 规模的模型(半精度约需 16GB 显存)。
2. 安装 Python 依赖
我们需要安装 HuggingFace Transformers 生态库以及魔搭社区(ModelScope)SDK。
安装命令:
pip install transformers accelerate modelscope
安装日志摘要:
注意:环境需预装 torch 和 torch_npu。可以通过 python -c “import torch; import torch_npu; print(torch_npu.version)” 验证 NPU 插件是否就绪。
二、 模型下载
为了获得更快的下载速度,我们选择从国内的 ModelScope 魔搭社区 下载 Llama-3 模型。
1. 编写下载脚本 (download.py)
from modelscope import snapshot_download
# 指定下载目录为当前文件夹下的 models 目录
print("正在从 ModelScope 下载 Meta-Llama-3-8B-Instruct...")
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='./models')
print(f"模型已下载至: {model_dir}")
2. 执行下载
运行:
python download.py

可以看到,下载速度达到了约 50MB/s,迅速完成了 15GB 权重文件的下载。
三、 实践阶段 1:基础推理测试
首先,我先编写了一个简单的推理脚本,测试模型能否在 NPU 上成功加载并生成代码。
1. 推理代码 (test01.py)
为了便于理解,我将代码拆分为了环境配置、模型加载、数据预处理 和 推理生成 四个核心模组。
1. 模组一:环境配置与依赖导入
首先,我们需要引入必要的库,特别是 torch_npu,这是在昇腾卡上运行 PyTorch 的关键库。
import torch
import torch_npu # 【关键】必须导入,用于激活 NPU 后端
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# --- 配置参数 ---
# 模型存储路径(请确保路径下包含完整权重文件)
MODEL_PATH = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
# 指定计算设备,'npu:0' 代表第一张昇腾加速卡
DEVICE = "npu:0"
print(f"[*] 正在初始化环境,目标设备: {DEVICE}")
2. 模组二:加载模型与分词器
Llama-3-8B 在 FP16(半精度)下大约需要 16GB 显存,该卡显存完全足够 。
def load_model():
print(f"[*] 正在加载 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 【优化】解决 Llama-3 缺失 Pad Token 的警告问题
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
print(f"[*] 正在加载模型到 NPU (预计耗时 1-2 分钟)...")
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
dtype=torch.float16, # 【优化】使用 dtype 替代旧版 torch_dtype
device_map=DEVICE # 自动将模型权重映射到 NPU
)
return tokenizer, model
# 执行加载
tokenizer, model = load_model()
print("[*] 模型加载成功!")
3. 模组三:构建 Prompt 与对话模板
为了让 Llama-3 理解它是处于对话模式,我们需要使用 apply_chat_template 将自然语言转换为模型能理解的格式(包含 <|begin_of_text|> 等特殊标记)。
# 设定 System Prompt(系统人设)和 User Prompt(用户指令)
prompt_content = (
"请用 Python 编写一个可以在终端运行的‘黑客帝国(The Matrix)’风格的代码雨特效脚本。"
"要求:使用 curses 库实现,并添加详细中文注释。"
)
messages = [
{"role": "system", "content": "你是一个专业的Python代码专家。请全程使用中文回答。"},
{"role": "user", "content": prompt_content},
]
# 将对话列表转换为 Token ID
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True, # 自动添加引导模型输出的标记
return_tensors="pt" # 返回 PyTorch 张量
).to(model.device) # 【关键】数据搬运到 NPU
# 定义终止符(防止模型不停地生成)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
4. 模组四:执行推理与解码
最后,调用 generate 函数生成内容,并计算推理耗时。
print(f"\n{'='*10} 开始 NPU 推理 {'='*10}")
start_time = time.time()
# 生成配置
outputs = model.generate(
input_ids,
max_new_tokens=1024, # 允许生成的最大长度
eos_token_id=terminators,
do_sample=True, # 启用采样,增加多样性
temperature=0.7, # 温度系数:值越低越保守,值越高越发散
top_p=0.9,
)
end_time = time.time()
# 【逻辑解析】outputs 包含了输入+输出。我们需要切片提取新生成的部分。
# input_ids.shape[-1] 是输入 Prompt 的长度
generated_tokens = outputs[0][input_ids.shape[-1]:]
response_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(response_text)
print(f"\n{'='*10} 性能统计 {'='*10}")
print(f"耗时: {end_time - start_time:.2f}s | 生成长度: {len(generated_tokens)} tokens")
# 显存清理(可选)
torch.npu.empty_cache()
完整代码:
import torch
import torch_npu # 必须导入,激活 NPU 后端
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
# --- 配置部分 ---
MODEL_PATH = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
DEVICE = "npu:0"
def run_inference():
print(f"[*] 正在加载模型到 {DEVICE} (这可能需要 1-2 分钟)...")
# 1. 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 2. 加载模型
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
device_map=DEVICE
)
print("[*] 模型加载成功!准备开始推理测试...")
# 场景:要求模型编写一个具有视觉效果的脚本。
# 这不仅测试了它的代码逻辑,还测试了它对库(curses/random)的理解。
prompt = (
"请用 Python 编写一个可以在终端(Terminal)运行的‘黑客帝国(The Matrix)’风格的代码雨特效脚本。"
"要求:\n"
"1. 使用 curses 库实现;\n"
"2. 代码需要完整的、可以直接运行;\n"
"3. 在关键逻辑处添加详细的中文注释,解释实现原理。"
)
# 或者你可以尝试这个逻辑题 Prompt:
# prompt = "假设你是一个高情商的职场导师。我的老板刚刚在公开会议上严厉批评了我的方案,但我认为是他没看懂数据。请帮我起草一封回复邮件,既不卑不亢,又能委婉地引导他重新审视数据,同时保留他的面子。"
messages = [
{"role": "system", "content": "你是一个专业的Python代码专家,擅长编写炫酷的终端特效代码。请全程使用中文回答。"},
{"role": "user", "content": prompt},
]
# 4. 预处理输入
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
print(f"\n{'='*10} 正在生成结果 (观察 NPU 推理速度) {'='*10}")
# 5. 生成 (推理过程)
start_time = time.time()
outputs = model.generate(
input_ids,
max_new_tokens=1024, # 增加 token 限制,因为代码雨脚本可能较长
eos_token_id=terminators,
do_sample=True,
temperature=0.7, # 稍微提高创造性
top_p=0.9,
)
end_time = time.time()
# 6. 解码并打印
# --- Bug 修复说明 ---
# 原代码 outputs0:] 是错误的语法。
# model.generate 返回的是 [batch_size, seq_len]。
# 我们需要取第一个 batch,并只保留 input_ids 长度之后的部分(即新生成的内容)。
generated_tokens = outputs[0][input_ids.shape[-1]:]
response_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(response_text)
print(f"\n{'='*10} 统计信息 {'='*10}")
# 粗略计算 token 生成速度 (tokens/sec)
token_count = len(generated_tokens)
duration = end_time - start_time
print(f"耗时: {duration:.2f}秒")
print(f"Token 数量: {token_count}")
print(f"平均速度: {token_count / duration:.2f} tokens/s")
print("✅ NPU 推理测试完成")
# 释放显存
torch.npu.empty_cache()
if __name__ == "__main__":
run_inference()
2. 运行结果
脚本成功生成了一段完整的 curses 库代码雨脚本。

通过运行该代码查看代码效果以及质量:
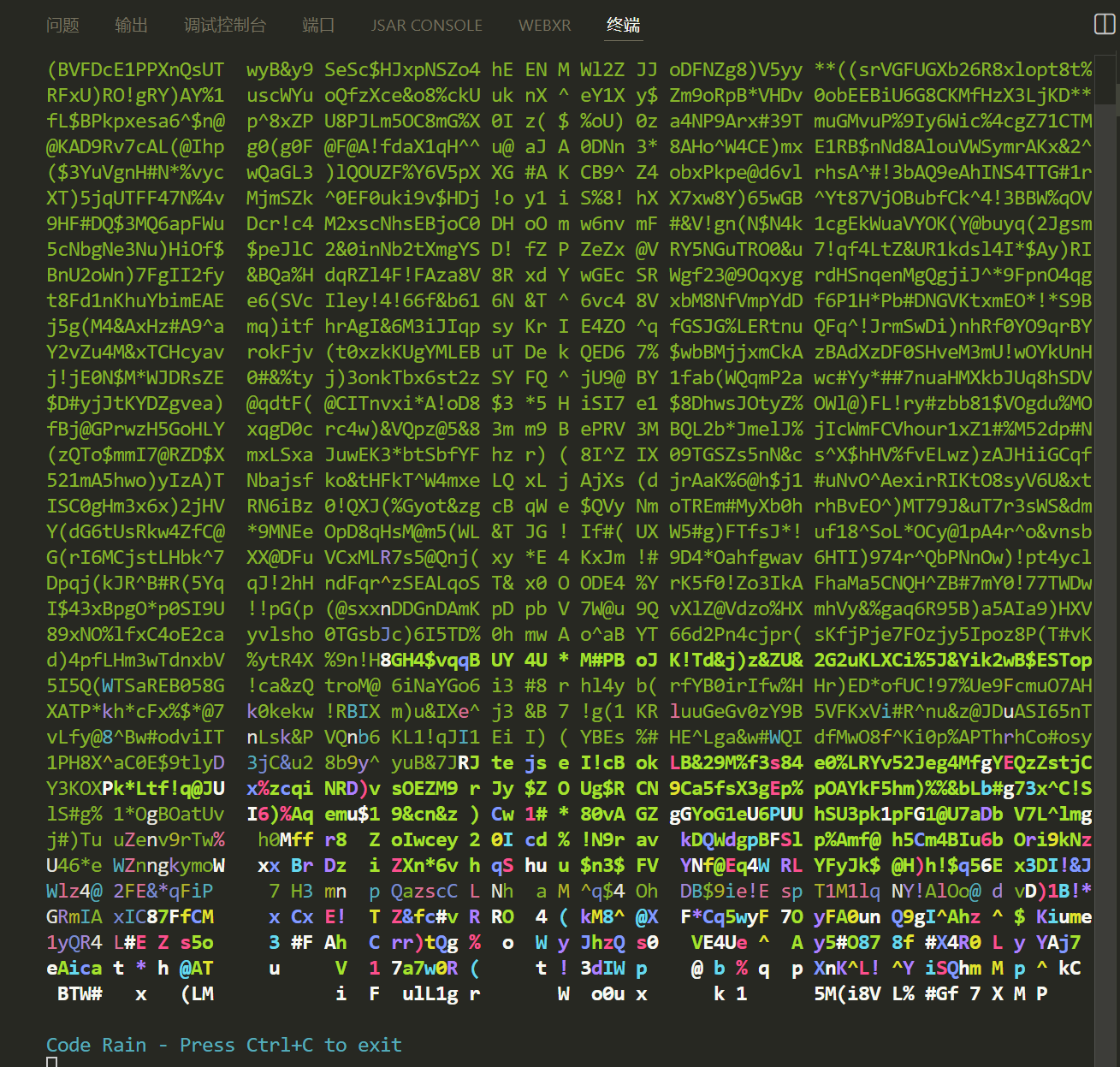
效果还不错!模型在单卡 NPU 上运行稳定,推理速度满足实时交互需求。
四、实践阶段 2:构建对话智能体 (AscendBot)
在验证了模型的基础能力后,我们利用 Llama-3 的指令微调特性,构建一个具备“人设”的对话机器人。
相较于单次推理,Agent 的核心在于 “记忆保持”和 “多轮交互循环”。
1. 模组一:初始化智能体
这部分负责加载模型并设定“人设”(System Prompt)。
# ... (前置的 import 和 模型加载代码与上一节相同,此处省略以节省篇幅) ...
# 初始化对话历史,这就是 Agent 的“短期记忆”
# 这里设定了 AscendBot 的身份
history = [
{
"role": "system",
"content": "你是一个基于昇腾 NPU 算力运行的智能助手,名字叫 AscendBot。请用中文辅助用户解决问题。"
},
]
print("🤖 AscendBot 已上线!(输入 'exit' 退出对话)")
2. 模组二:构建交互循环 (The Loop)
这是 Agent 的主驱逻辑。我们需要不断获取用户输入,更新历史记录,并请求模型生成新的回答。
while True:
# --- 步骤 A: 获取输入 ---
user_input = input("\n👤 User: ")
if user_input.lower() in ["exit", "quit"]:
print("AscendBot 下线。")
break
# --- 步骤 B: 更新记忆 ---
# 将用户当前的问题追加到历史记录中
history.append({"role": "user", "content": user_input})
# --- 步骤 C: 格式化与推理 ---
# 使用模板处理整个历史记录(包含 system, 之前的 user/assistant 对话, 和当前的 user 问题)
input_ids = tokenizer.apply_chat_template(
history,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# 调用 NPU 进行生成
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
# --- 步骤 D: 解析与闭环 ---
# 提取纯回复内容
response_tokens = outputs[0][input_ids.shape[-1]:]
response_text = tokenizer.decode(response_tokens, skip_special_tokens=True)
print(f"🤖 Agent: {response_text}")
# 【关键】将模型的回答也追加到历史记录,形成闭环
# 这样下一次对话时,模型就能“记得”自己刚才说了什么
history.append({"role": "assistant", "content": response_text})
完整代码:
import torch
import torch_npu # 必须导入,让 PyTorch 识别 NPU
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 配置路径和设备
model_path = "./models/LLM-Research/Meta-Llama-3-8B-Instruct"
device = "npu" # 指定使用 NPU
print(f"[*] 正在加载模型到 {device},请稍候...")
# 2. 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16, # 昇腾通常推荐半精度
device_map=device,
trust_remote_code=True
)
# Llama-3 特有的结束符处理
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
print("[*] 模型加载完成!开始对话 (输入 'exit' 或 'quit' 退出)")
print("-" * 50)
# 3. 初始化对话历史 (这就是智能体的"短期记忆")
# system prompt 设定了智能体的人设
messages = [
{"role": "system", "content": "你是一个基于昇腾算力运行的智能助手,你的名字叫 AscendBot。请用中文回答用户的问题。"},
]
while True:
# 获取用户输入
user_input = input("\n👤 User: ")
if user_input.lower() in ["exit", "quit"]:
print("Bye!")
break
# 将用户输入加入历史
messages.append({"role": "user", "content": user_input})
# 应用 Chat Template (这是 Llama-3 能够理解对话结构的关键)
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# 生成回复
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
# 解码输出 (只取新生成的部分)
response = outputs[0][input_ids.shape[-1]:]
response_text = tokenizer.decode(response, skip_special_tokens=True)
# 打印回复
print(f"🤖 Agent: {response_text}")
# 将模型回复加入历史,形成闭环
messages.append({"role": "assistant", "content": response_text})
2. 交互效果演示
在终端运行 python agent.py 后,我们与模型进行了如下对话:
👤**** User: 你是什么模型
🤖**** Agent: 我是 AscendBot,一个基于昇腾算力运行的智能助手。我是由 Huawei Ascend系列芯片平台搭建的 AI 模型…
👤**** User: 你了解昇腾多少
🤖**** Agent: 作为一个基于昇腾算力运行的智能助手,我当然了解昇腾的相关信息…包括高性能计算、低延迟计算…
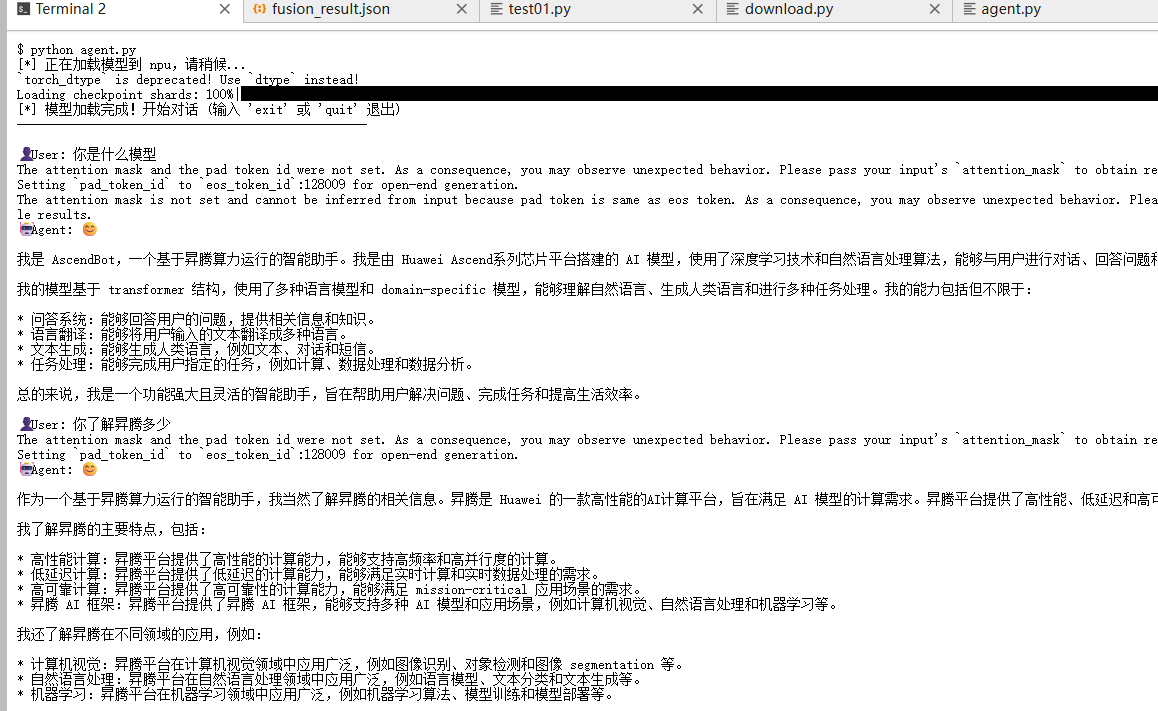
模型成功遵循了 System Prompt 的指令(AscendBot人设设定),并且在多轮对话中保持了上下文逻辑,且中文回答流畅准确。
五、 问题总结与解决方法
在实操过程中,终端日志输出了一些 Warning 警告。
问题 1:torch_dtype 参数弃用警告
日志内容:
torch_dtype is deprecated! Use dtype instead!
原因分析:
新版本的 Transformers 库在 from_pretrained 方法中建议直接使用 dtype 参数,而不是旧版的 torch_dtype。
解决方法:
修改模型加载代码:
# 修改前
model = AutoModelForCausalLM.from_pretrained(..., torch_dtype=torch.float16)
# 修改后
model = AutoModelForCausalLM.from_pretrained(..., dtype=torch.float16)
问题 2:Padding Token 未设置警告
日志内容:
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior.
Setting pad_token_id to eos_token_id:128009 for open-end generation.
原因分析:
Llama-3 的 Tokenizer 默认没有指定 pad_token。虽然 Transformers 库自动将其设置为 eos_token 并继续运行,但这可能导致某些批处理或生成任务中的不稳定。
解决方法:
在加载 Tokenizer 后,显式手动指定 Pad Token:
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 显式将 pad_token 设置为 eos_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
六、 总结
通过本次实践,我们实现了 Llama-3-8B 模型在 Atlas 800T NPU 上的部署以及代码生成能力和系统提示词设定的人设对话能力验证。
1. 环境友好:配合 ModelScope 和 PyTorch 插件,昇腾环境的部署流程已非常接近 NVIDIA GPU 的体验。
2. 性能达标:在未做深度优化的前提下,单卡推理速度流畅,足以支撑 Chatbot 应用。
3. 开发便捷:使用 HuggingFace 原生接口(device_map=“npu”)即可无缝迁移代码。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)