昇腾ModelSlim工具:大模型量化推理优化实践指南
摘要:昇腾AI生态推出的MindStudio ModelSlim工具为大模型高效部署提供专业解决方案。该工具集成了低秩分解、稀疏训练、量化感知训练等多元压缩技术,特别针对昇腾AI处理器进行硬件级优化,支持W8A8等量化模式。本文详细介绍了从环境搭建到模型量化的完整流程,包括硬件配置要求、校准数据集准备、离群值抑制优化等关键技术环节,并提供了常见问题的解决方案。通过该工具,开发者可在保证精度的同时显
在人工智能大模型快速发展的当下,模型的高效部署成为企业落地AI应用的关键挑战。昇腾AI生态推出的MindStudio ModelSlim工具,以硬件亲和性为核心设计理念,通过多样化的压缩技术为大模型在昇腾硬件上的高效推理提供了强有力的支持。本文将全面解析该工具的技术原理与实操流程,为开发者提供从环境搭建到模型量化部署的完整指南。
一、工具核心能力解析
MindStudio ModelSlim作为昇腾生态专属的模型压缩工具,采用"硬件感知"的优化策略,将模型压缩与昇腾AI处理器的架构特性深度融合。其核心优势体现在三个维度:
- 首先是多元化的压缩技术矩阵,集成了低秩分解、稀疏训练、训练后量化(PTQ)和量化感知训练(QAT)等主流方法,形成覆盖模型生命周期各阶段的优化方案。其中量化技术作为提升推理效率的关键手段,可实现权值与激活值的低比特化(如W8A8模式),在保证精度的前提下显著降低计算资源消耗。
- 其次是硬件亲和性设计,所有压缩算法均针对昇腾AI处理器的计算特性进行专项优化,确保压缩后的模型能够充分发挥硬件算力。通过与CANN架构的深度协同,实现算子级别的高效调度,解决了传统通用压缩工具在专用硬件上的适配难题。
- 最后是开发者友好的使用体验,提供简洁的Python API接口,支持灵活配置量化参数,同时兼容Hugging Face等主流模型库,降低技术落地门槛。
二、量化推理环境搭建
2.1 硬件与系统要求
昇腾ModelSlim工具对运行环境有明确的软硬件要求,硬件方面推荐采用Atlas 800I A2、Atlas 800T A2推理服务器或Atlas 300I Duo推理卡,这些设备搭载昇腾AI处理器,为量化推理提供专用加速能力。
系统环境需满足:
- 操作系统:openEuler 22.03 LTS
- Python版本:3.10或3.11
- CANN版本:8.2.RC2
为简化环境配置,推荐使用昇腾官方提供的配套镜像,可通过昇腾开发者社区获取。工具安装可参考官方仓库文档。
2.2 环境初始化配置
在进行模型量化前,需完成NPU编译环境的初始化配置,避免量化过程中出现算子编译问题。关键配置代码如下:
# 开启二进制编译模式,禁用即时编译
torch.npu.set_compile_mode(jit_compile=False)
# 配置编译选项,规避特定算子的模糊编译
option = {"NPU_FUZZY_COMPILE_BLACKLIST": "ReduceProd"}
torch.npu.set_option(option)
三、大模型量化全流程实操
3.1 模型加载策略
量化操作的第一步是将原始模型加载到NPU设备,需注意合理分配设备内存以避免加载失败。以Qwen2.5-72B-Instruct模型为例,推荐的加载方式如下:
model_path = '/data/Qwen2.5-72B-Instruct/'
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=model_path,
torch_dtype=torch.bfloat16, # 采用bfloat16精度加载
trust_remote_code=True,
device_map="auto", # 自动设备映射
# 精细化内存分配,根据实际卡数调整
max_memory={0:"0GiB",1:"0GiB",2:"25GiB",3:"25GiB",
4:"25GiB",5:"25GiB",6:"25GiB",7:"25GiB"}
).eval() # 切换为评估模式
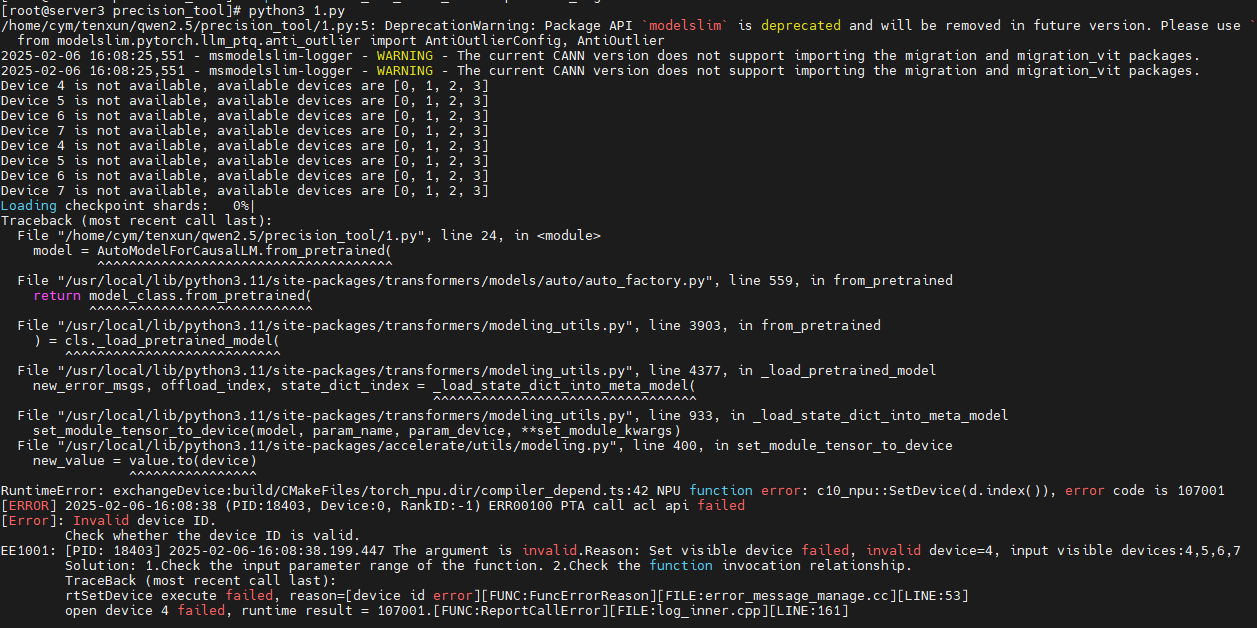
注意:Qwen2.5-72B等超大模型在Atlas 800I A2(32G显存)上至少需要6卡资源,使用4卡及以下配置可能出现内存不足错误(如图1所示)。
3.2 校准数据集准备
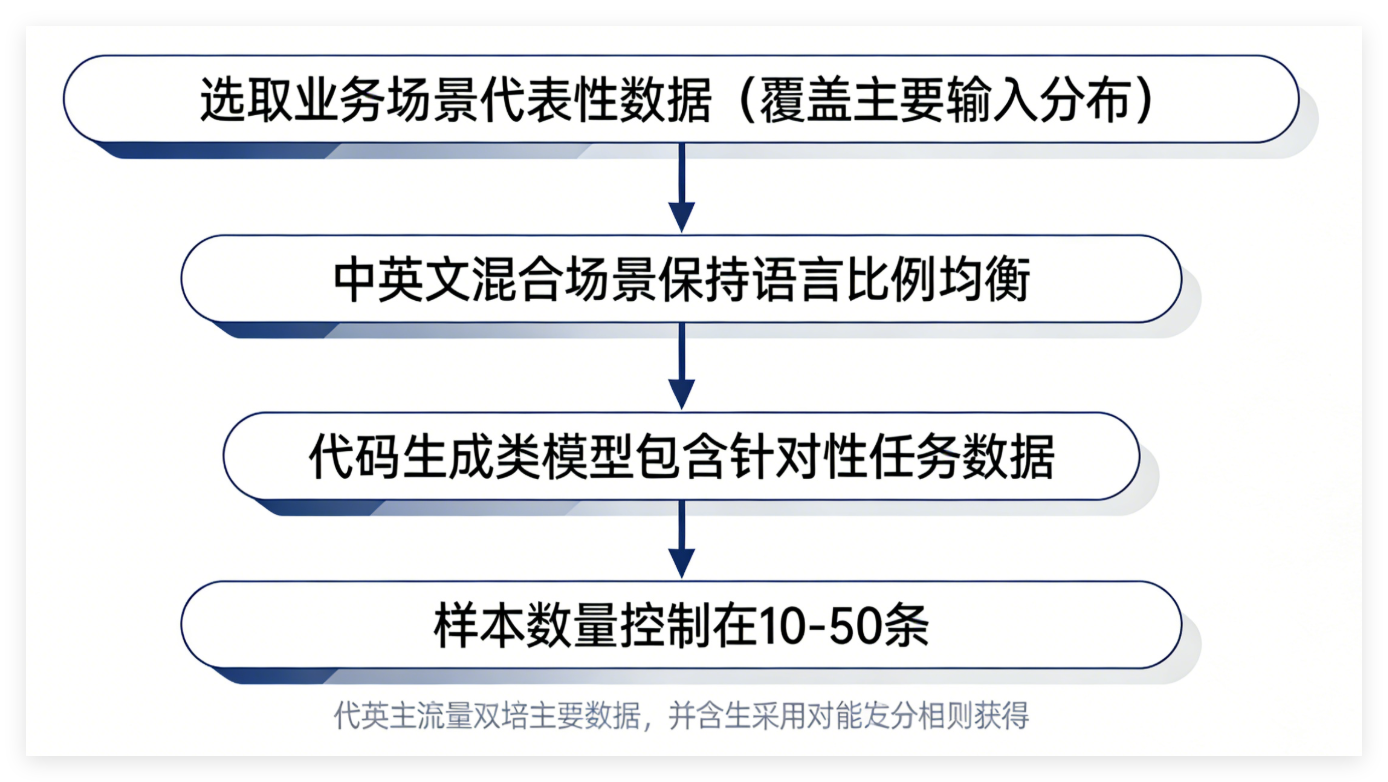
量化校准数据的质量直接影响量化精度,应遵循以下原则:
数据加载代码示例:
def get_calib_dataset(tokenizer, calib_list, device=model.device):
calib_dataset = []
for calib_data in calib_list:
inputs = tokenizer(calib_data, return_tensors='pt')
# 将输入张量迁移至NPU设备
calib_dataset.append([
inputs.data['input_ids'].to(device),
inputs.data['attention_mask'].to(device)
])
return calib_dataset
# 加载boolq数据集作为校准数据
with open("/dataset/boolq_lite/dev3.jsonl", 'r') as file:
calib_set = json.load(file)
dataset_calib = get_calib_dataset(tokenizer, calib_set)
3.3 离群值抑制优化
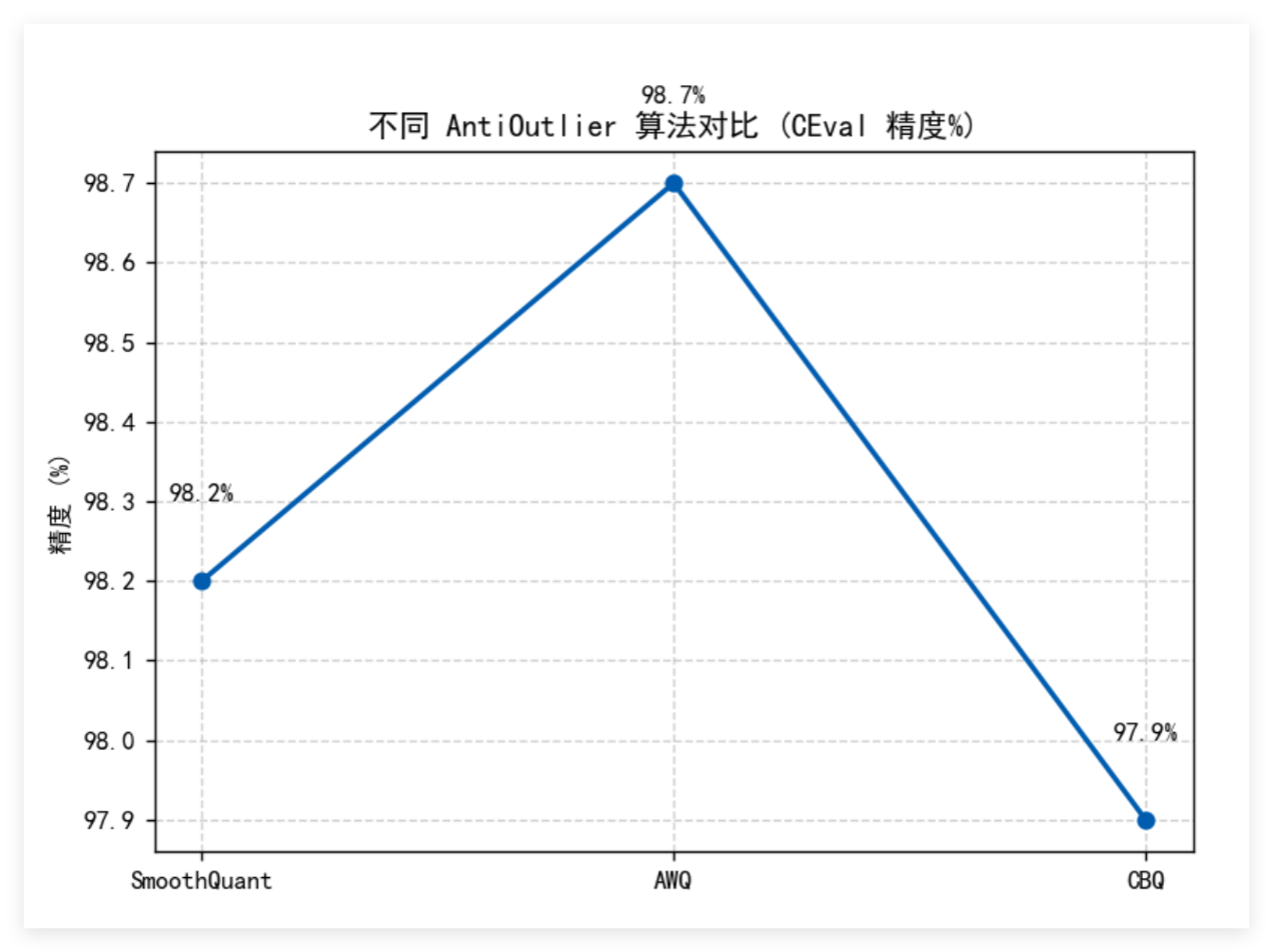
部分模型在直接进行W8A8量化时可能出现精度下降,可通过AntiOutlier模块抑制量化过程中的异常值。该模块提供多种算法选择:
| 算法标识 | 算法名称 | 适用场景 |
|---|---|---|
| m1 | SmoothQuant基础版 | 通用场景 |
| m2 | SmoothQuant升级版 | 高精度要求场景 |
| m3 | AWQ算法 | W8A16/W4A16量化 |
| m4 | SmoothQuant优化版 | 大模型通用 |
| m5 | CBQ算法 | 特定模型优化 |
| m6 | Flex smooth量化 | 动态范围场景 |
算法调用示例:
# 配置AWQ算法进行离群值抑制
anti_config = AntiOutlierConfig(
anti_method="m3", # 选择AWQ算法
dev_type="npu",
dev_id=model.device.index
)
anti_outlier = AntiOutlier(
model,
calib_data=dataset_calib,
cfg=anti_config
)
anti_outlier.process() # 执行抑制处理
3.4 量化参数配置
QuantConfig接口提供灵活的量化参数配置,核心参数说明如下:
quant_config = QuantConfig(
a_bit=8, # 激活值量化位数
w_bit=8, # 权值量化位数
disable_names=disable_names, # 回退层列表
dev_type='npu', # 设备类型
dev_id=model.device.index, # 设备ID
act_method=3, # 激活值量化方式(1:min-max,2:histogram,3:混合)
pr=1.0, # 量化比例
w_sym=True, # 权值对称量化
mm_tensor=False
).fa_quant(fa_amp=0) # 配置FA3量化特性
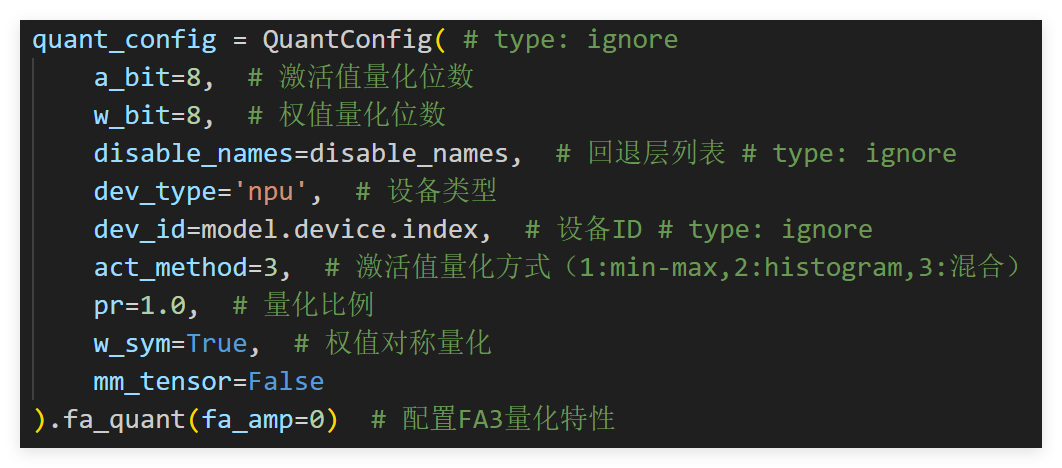
经验值:LLM大模型场景下,act_method=3(混合量化方式)通常能取得更优的精度-性能平衡。
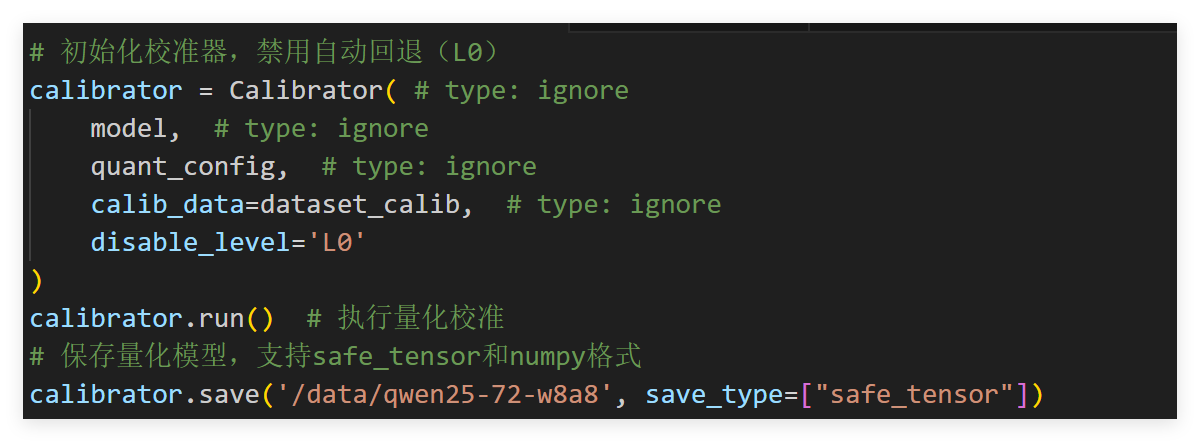
3.5 量化执行与模型保存
完成配置后,通过Calibrator执行量化流程并保存结果:
# 初始化校准器,禁用自动回退(L0)
calibrator = Calibrator(
model,
quant_config,
calib_data=dataset_calib,
disable_level='L0'
)
calibrator.run() # 执行量化校准
# 保存量化模型,支持safe_tensor和numpy格式
calibrator.save('/data/qwen25-72-w8a8', save_type=["safe_tensor"])
其中disable_level参数控制自动回退策略,'Lx’表示回退对精度影响最大的x个Linear层,开发者可根据量化后精度表现动态调整。
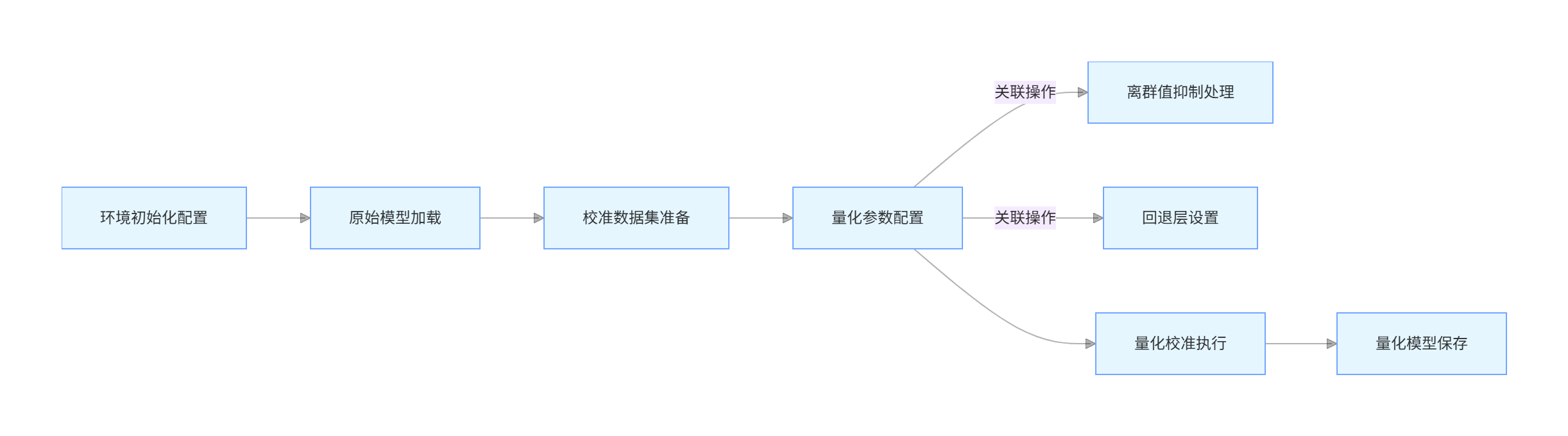
四、完整量化流程架构
下图展示了基于ModelSlim的大模型量化推理全流程架构:
五、常见问题与解决方案
- 模型加载失败:通常由内存分配不足导致,需检查max_memory配置,确保总分配内存满足模型需求。72B模型推荐使用6卡及以上配置。
- 量化精度下降:可尝试以下方案:
- 更换AntiOutlier算法(如m3/AWQ)
- 调整act_method为3(混合量化)
- 启用自动回退(设置disable_level='L5’等)
- 算子编译错误:确保已正确执行二进制编译配置,特别是NPU_FUZZY_COMPILE_BLACKLIST设置。
通过ModelSlim工具的量化优化,Qwen2.5-72B等大模型可在昇腾硬件上实现高效推理,在保持精度的同时,显著降低内存占用与推理时延,为大模型的工业化部署提供关键技术支撑。开发者可根据具体业务场景,灵活调整量化策略,实现最优的性能表现。
注明:昇腾PAE案例库对本文写作亦有帮助。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)