
从零开始学昇腾Ascend C算子开发-第八篇:算子调用方式
本文介绍了昇腾AI处理器中自定义算子的调用方式及aclnn API的详细使用方法。主要内容包括: 算子调用的三种方式: FrameworkLaunch(框架调用) KernelLaunch(直接调用核函数) 第三方框架调用(如PyTorch、TensorFlow) aclnn API的两段式接口设计: 第一段获取workspace大小并创建执行器 第二段实际执行算子计算 这种设计支持内存预分配和执
8.1 算子调用的几种方式
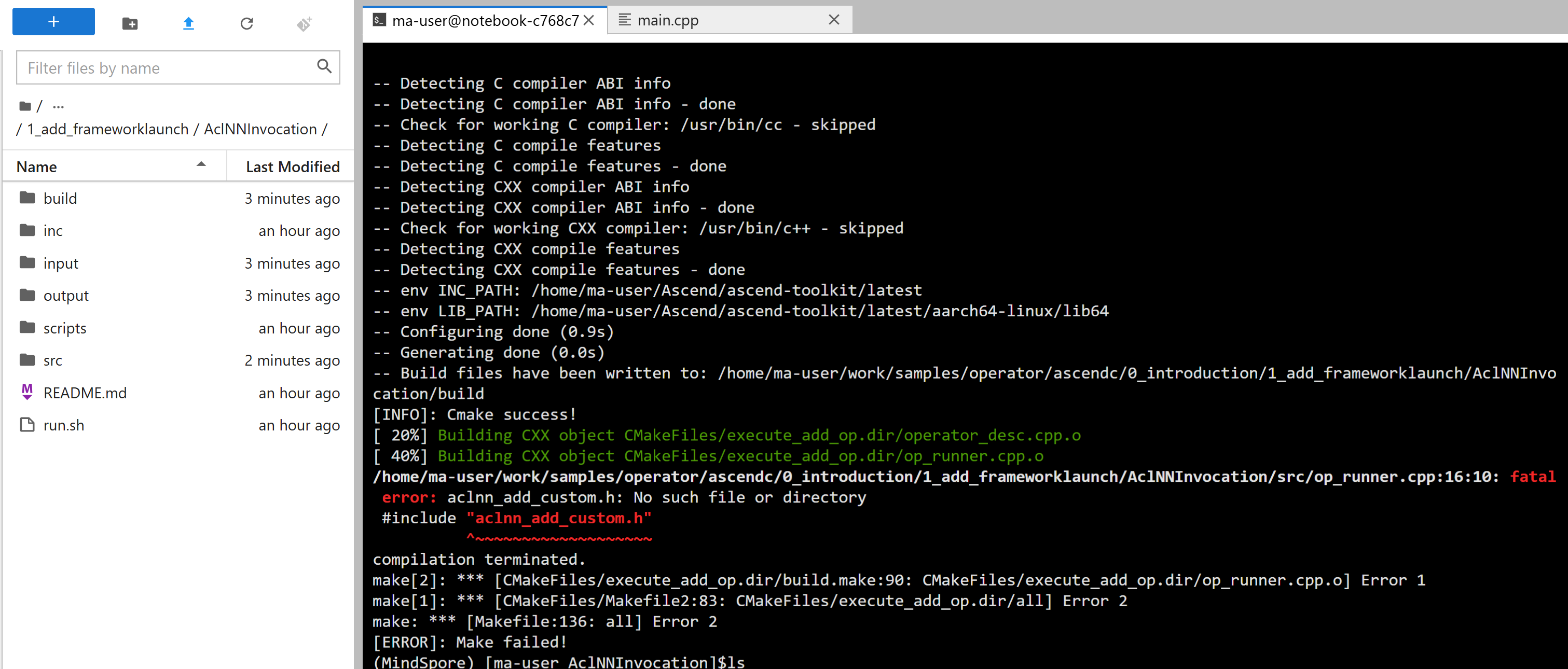
嗲用的方法得适当,不然就容易报错哦,用对了才能编译成功。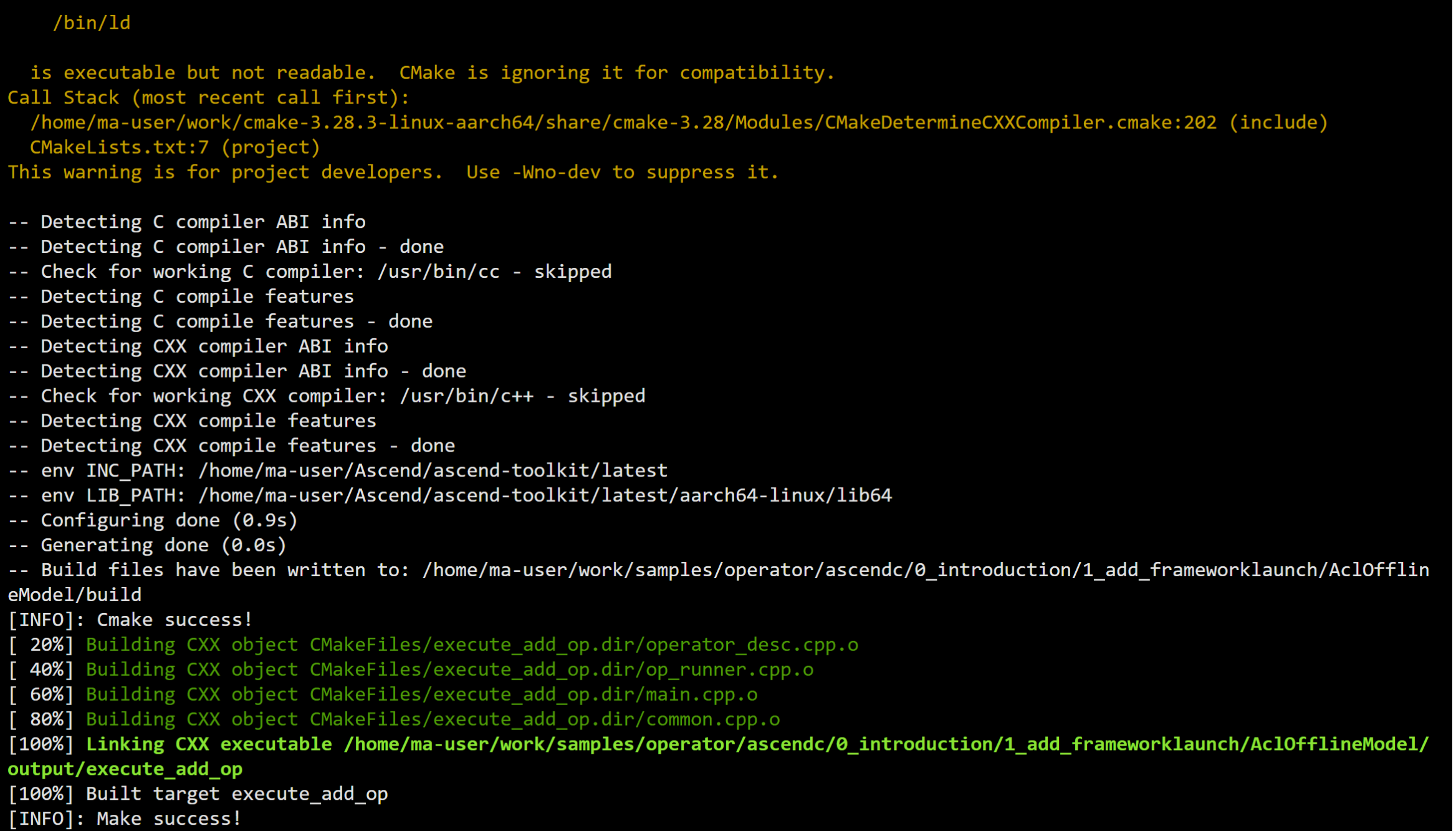
8.1.1 FrameworkLaunch方式
FrameworkLaunch是通过框架调用自定义算子的方式。算子编译部署后,会自动生成aclnn API,可以直接在应用程序中调用。这是最常用的调用方式,适合集成到实际应用中。
8.1.2 KernelLaunch方式
KernelLaunch是直接调用核函数的方式,更底层,适合快速验证和测试。不需要完整的算子工程,只需要核函数代码。
8.1.3 第三方框架调用
自定义算子也可以集成到PyTorch、TensorFlow等深度学习框架中,通过框架的接口调用。
8.2 aclnn API调用详解
8.2.1 什么是aclnn API
aclnn(Ascend Computing Language Neural Network)是昇腾提供的神经网络计算API。自定义算子编译部署后,会自动生成对应的aclnn API,比如AddCustom算子会生成aclnnAddCustom API。
8.2.2 两段式接口
aclnn API采用两段式接口设计:
第一段接口:获取workspace大小,准备执行器。
aclnnStatus aclnnAddCustomGetWorkspaceSize(
const aclTensor *x, // 输入tensor x
const aclTensor *y, // 输入tensor y
const aclTensor *out, // 输出tensor
uint64_t *workspaceSize, // 返回workspace大小
aclOpExecutor **executor // 返回执行器
);
这个接口会计算算子执行需要多少workspace内存,并创建执行器。workspace是算子执行时需要的临时内存,有些算子需要,有些不需要。
第二段接口:执行算子。
aclnnStatus aclnnAddCustom(
void *workspace, // workspace内存
int64_t workspaceSize, // workspace大小
aclOpExecutor *executor, // 执行器
aclrtStream stream // 执行流
);
这个接口实际执行算子计算。需要传入workspace内存、执行器和流。
8.2.3 为什么是两段式
两段式设计的好处:
提前知道内存需求:第一段接口告诉你需要多少workspace,你可以提前分配,避免执行时内存不足。
执行器复用:执行器可以复用,如果输入输出的形状不变,可以只调用一次第一段接口,多次调用第二段接口,提高效率。
异步执行:第二段接口是异步的,调用后立即返回,不会阻塞。需要同步的话调用aclrtSynchronizeStream。
8.3 AclNNInvocation示例详解
8.3.1 项目结构
基于samples中的AclNNInvocation示例,项目结构如下:
AclNNInvocation/
├── inc/ // 头文件
│ ├── common.h // 公共函数声明
│ ├── op_runner.h // 算子运行器声明
│ └── operator_desc.h // 算子描述声明
├── src/ // 源文件
│ ├── main.cpp // 主程序
│ ├── op_runner.cpp // 算子运行器实现
│ ├── operator_desc.cpp // 算子描述实现
│ └── common.cpp // 公共函数实现
├── scripts/ // 脚本
│ ├── gen_data.py // 生成测试数据
│ └── verify_result.py // 验证结果
├── input/ // 输入数据目录
├── output/ // 输出数据目录
└── run.sh // 运行脚本
8.3.2 算子描述(OperatorDesc)
算子描述定义了算子的输入输出信息:
// operator_desc.h
struct OperatorDesc {
OperatorDesc();
~OperatorDesc();
// 添加输入tensor描述
OperatorDesc &AddInputTensorDesc(
aclDataType dataType, // 数据类型,如ACL_FLOAT16
int numDims, // 维度数
const int64_t *dims, // 形状数组
aclFormat format // 数据格式,如ACL_FORMAT_ND
);
// 添加输出tensor描述
OperatorDesc &AddOutputTensorDesc(
aclDataType dataType,
int numDims,
const int64_t *dims,
aclFormat format
);
std::vector<aclTensorDesc *> inputDesc; // 输入描述列表
std::vector<aclTensorDesc *> outputDesc; // 输出描述列表
};
使用示例:
OperatorDesc CreateOpDesc()
{
// 定义算子:两个输入,一个输出,都是[8, 2048]的float16
std::vector<int64_t> shape{8, 2048};
aclDataType dataType = ACL_FLOAT16;
aclFormat format = ACL_FORMAT_ND;
OperatorDesc opDesc;
opDesc.AddInputTensorDesc(dataType, shape.size(), shape.data(), format);
opDesc.AddInputTensorDesc(dataType, shape.size(), shape.data(), format);
opDesc.AddOutputTensorDesc(dataType, shape.size(), shape.data(), format);
return opDesc;
}
8.3.3 算子运行器(OpRunner)
OpRunner封装了算子调用的完整流程,包括内存管理、数据拷贝、算子执行等。
初始化:
bool OpRunner::Init()
{
// 为每个输入分配内存
for (size_t i = 0; i < numInputs_; ++i) {
auto size = GetInputSize(i);
// 分配Device内存
void *devMem = nullptr;
aclrtMalloc(&devMem, size, ACL_MEM_MALLOC_HUGE_FIRST);
devInputs_.emplace_back(devMem);
// 创建DataBuffer
inputBuffers_.emplace_back(aclCreateDataBuffer(devMem, size));
// 分配Host内存(用于数据拷贝)
void *hostInput = nullptr;
if (g_isDevice) {
aclrtMalloc(&hostInput, size, ACL_MEM_MALLOC_HUGE_FIRST);
} else {
aclrtMallocHost(&hostInput, size);
}
hostInputs_.emplace_back(hostInput);
// 创建Tensor
aclTensor *inputTensor = aclCreateTensor(
GetInputShape(i).data(),
GetInputNumDims(i),
GetInputDataType(i),
nullptr, 0,
GetInputFormat(i),
GetInputShape(i).data(),
GetInputNumDims(i),
devInputs_[i]
);
inputTensor_.emplace_back(inputTensor);
}
// 为每个输出分配内存(类似输入)
// ...
return true;
}
执行算子:
bool OpRunner::RunOp()
{
// 1. 拷贝输入数据到Device
for (size_t i = 0; i < numInputs_; ++i) {
auto size = GetInputSize(i);
aclrtMemcpyKind kind = g_isDevice ?
ACL_MEMCPY_DEVICE_TO_DEVICE :
ACL_MEMCPY_HOST_TO_DEVICE;
aclrtMemcpy(devInputs_[i], size, hostInputs_[i], size, kind);
}
// 2. 创建执行流
aclrtStream stream = nullptr;
aclrtCreateStream(&stream);
// 3. 第一段接口:获取workspace大小
size_t workspaceSize = 0;
aclOpExecutor *handle = nullptr;
auto ret = aclnnAddCustomGetWorkspaceSize(
inputTensor_[0],
inputTensor_[1],
outputTensor_[0],
&workspaceSize,
&handle
);
if (ret != ACL_SUCCESS) {
ERROR_LOG("Get Workspace failed");
return false;
}
// 4. 分配workspace内存(如果需要)
void *workspace_ = nullptr;
if (workspaceSize != 0) {
aclrtMalloc(&workspace_, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
}
// 5. 第二段接口:执行算子
ret = aclnnAddCustom(workspace_, workspaceSize, handle, stream);
if (ret != ACL_SUCCESS) {
ERROR_LOG("Execute Operator failed");
return false;
}
// 6. 同步等待执行完成
aclrtSynchronizeStreamWithTimeout(stream, 5000);
// 7. 拷贝输出数据到Host
for (size_t i = 0; i < numOutputs_; ++i) {
auto size = GetOutputSize(i);
aclrtMemcpyKind kind = g_isDevice ?
ACL_MEMCPY_DEVICE_TO_DEVICE :
ACL_MEMCPY_DEVICE_TO_HOST;
aclrtMemcpy(hostOutputs_[i], size, devOutputs_[i], size, kind);
}
aclrtDestroyStream(stream);
return true;
}
8.3.4 主程序流程
main.cpp展示了完整的调用流程:
int main(int argc, char **argv)
{
// 1. 初始化资源
if (!InitResource()) {
ERROR_LOG("Init resource failed");
return FAILED;
}
// 2. 运行算子
if (!RunOp()) {
DestroyResource();
return FAILED;
}
// 3. 清理资源
DestroyResource();
return SUCCESS;
}
bool RunOp()
{
// 创建算子描述
OperatorDesc opDesc = CreateOpDesc();
// 创建算子运行器
OpRunner opRunner(&opDesc);
if (!opRunner.Init()) {
return false;
}
// 加载输入数据
if (!SetInputData(opRunner)) {
return false;
}
// 执行算子
if (!opRunner.RunOp()) {
return false;
}
// 处理输出数据
if (!ProcessOutputData(opRunner)) {
return false;
}
return true;
}
8.3.5 数据生成和验证
生成测试数据:
# gen_data.py
import numpy as np
def gen_golden_data_simple():
# 生成随机输入数据
input_x = np.random.uniform(1, 100, [8, 2048]).astype(np.float16)
input_y = np.random.uniform(1, 100, [8, 2048]).astype(np.float16)
# 计算真值(参考结果)
golden = (input_x + input_y).astype(np.float16)
# 保存为二进制文件
input_x.tofile("./input/input_x.bin")
input_y.tofile("./input/input_y.bin")
golden.tofile("./output/golden.bin")
验证结果:
# verify_result.py
# 读取输出结果和真值,对比验证
8.3.6 运行脚本
run.sh脚本自动化了整个流程:
#!/bin/bash
# 1. 清除遗留文件
rm -rf ./input/*.bin
rm -rf ./output/*.bin
# 2. 生成测试数据
python3 scripts/gen_data.py
# 3. 编译可执行文件
mkdir -p build
cd build
cmake ../src
make
# 4. 运行算子
cd ../output
./execute_add_op
# 5. 验证结果
cd ..
python3 scripts/verify_result.py output/output_z.bin output/golden.bin
8.4 内存管理详解
8.4.1 Host内存和Device内存
在昇腾系统中,有两类内存:
Host内存:CPU侧的内存,应用程序可以直接访问。
Device内存:NPU侧的内存,需要通过DMA传输访问。
数据要在Host和Device之间传输,需要分别分配Host内存和Device内存。
8.4.2 内存分配
Device内存分配:
void *devMem = nullptr;
aclrtMalloc(&devMem, size, ACL_MEM_MALLOC_HUGE_FIRST);
ACL_MEM_MALLOC_HUGE_FIRST表示优先分配大页内存,性能更好。
Host内存分配:
void *hostMem = nullptr;
// 如果运行在Device侧
if (g_isDevice) {
aclrtMalloc(&hostMem, size, ACL_MEM_MALLOC_HUGE_FIRST);
} else {
// 如果运行在Host侧
aclrtMallocHost(&hostMem, size);
}
8.4.3 数据拷贝
数据在Host和Device之间拷贝:
// Host到Device
aclrtMemcpy(devMem, size, hostMem, size, ACL_MEMCPY_HOST_TO_DEVICE);
// Device到Host
aclrtMemcpy(hostMem, size, devMem, size, ACL_MEMCPY_DEVICE_TO_HOST);
// Device到Device(如果运行在Device侧)
aclrtMemcpy(devMem2, size, devMem1, size, ACL_MEMCPY_DEVICE_TO_DEVICE);
8.4.4 Tensor和DataBuffer
aclTensor:描述tensor的元数据,包括形状、数据类型、格式等。
aclDataBuffer:描述实际的数据缓冲区,指向Device内存。
两者配合使用,Tensor描述数据,DataBuffer指向实际内存。
8.5 执行流程详解
8.5.1 完整执行流程
调用自定义算子的完整流程:
-
初始化ACL:aclInit(),初始化ACL环境。
-
设置设备:aclrtSetDevice(),选择要使用的NPU设备。
-
创建算子描述:定义输入输出的形状、数据类型等。
-
分配内存:为输入输出分配Host和Device内存。
-
创建Tensor:根据算子描述创建aclTensor。
-
加载输入数据:从文件读取数据,拷贝到Device内存。
-
获取workspace:调用第一段接口,获取workspace大小。
-
分配workspace:如果需要,分配workspace内存。
-
执行算子:调用第二段接口,执行算子计算。
-
同步等待:等待算子执行完成。
-
拷贝输出:从Device内存拷贝结果到Host内存。
-
保存结果:将结果保存到文件。
-
清理资源:释放内存,销毁资源。
8.5.2 异步执行
aclnn API是异步的,调用后立即返回,不会阻塞。如果需要等待执行完成,要调用同步接口:
// 同步等待,超时时间5000ms
aclrtSynchronizeStreamWithTimeout(stream, 5000);
异步执行的好处是可以让多个算子并发执行,提高效率。
8.5.3 Stream的使用
Stream是执行流,用于管理异步执行。可以创建多个Stream,让不同的算子在不同的Stream上并发执行。
// 创建Stream
aclrtStream stream = nullptr;
aclrtCreateStream(&stream);
// 在Stream上执行算子
aclnnAddCustom(workspace_, workspaceSize, handle, stream);
// 同步Stream
aclrtSynchronizeStream(stream);
// 销毁Stream
aclrtDestroyStream(stream);
8.6 错误处理
8.6.1 返回值检查
所有的ACL API都有返回值,要检查返回值:
auto ret = aclrtMalloc(&devMem, size, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_SUCCESS) {
ERROR_LOG("Malloc failed, error code: %d", ret);
return false;
}
8.6.2 常见错误
内存分配失败:可能是内存不足,或者参数错误。
Tensor创建失败:可能是形状、数据类型等参数不匹配。
算子执行失败:可能是输入数据有问题,或者算子实现有bug。
同步超时:可能是算子执行时间太长,或者有死锁。
8.6.3 调试技巧
打印日志:在关键位置打印日志,追踪执行流程。
检查数据:打印输入输出数据,验证数据是否正确。
检查内存:检查内存是否分配成功,是否越界。
检查返回值:所有API调用都要检查返回值。
8.7 性能优化建议
8.7.1 内存分配优化
大页内存:使用ACL_MEM_MALLOC_HUGE_FIRST分配大页内存,性能更好。
内存复用:如果可能,复用已分配的内存,减少分配释放开销。
批量分配:一次分配多点内存,减少分配次数。
8.7.2 数据拷贝优化
减少拷贝:尽量减少Host和Device之间的数据拷贝。
异步拷贝:如果支持,用异步拷贝,让拷贝和计算重叠。
批量拷贝:一次拷贝多点数据,减少拷贝次数。
8.7.3 执行优化
Stream并发:用多个Stream让多个算子并发执行。
执行器复用:如果输入输出形状不变,复用执行器。
流水线:让数据加载、计算、结果写回流水线化。
学习检查点
学完这一篇,你应该能做到这些:
理解aclnn API的两段式接口设计,知道为什么这样设计。掌握算子描述的创建,知道如何定义输入输出。理解OpRunner的实现,知道如何管理内存、拷贝数据、执行算子。掌握完整的调用流程,从初始化到执行到清理。能够参考AclNNInvocation示例,实现自己的算子调用程序。
实践练习
运行AclNNInvocation示例:在ModelArts Notebook中运行1_add_frameworklaunch/AclNNInvocation示例,理解完整的调用流程。
修改示例:尝试修改算子描述,改成不同的形状或数据类型,看看效果。
实现新的调用程序:参考AclNNInvocation,实现一个调用其他算子(比如Mul、Sub)的程序。
性能测试:测试不同大小的输入,看看性能如何变化。尝试优化内存分配和数据拷贝,提升性能。
下一步:掌握了算子调用方式后,你已经能够完整地开发和使用自定义算子了。可以继续学习其他调用方式,比如KernelLaunch、第三方框架集成等,或者在实际项目中应用这些知识。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
社区地址:https://www.hiascend.com/developer

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐



 13
13 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)