CANN数据类型与内存管理入门
写完第一个算子后,我发现自己对数据类型和内存管理还是一知半解。什么时候用FP16,什么时候用FP32?Global Memory和Unified Buffer到底有什么区别?内存对齐是怎么回事?这些问题直到我踩了几次坑,才慢慢理解。让我们先看看CANN的整体架构:从官方架构图可以看到,CANN的异构计算架构包含多层内存层次和不同的数据类型支持。今天就来系统梳理CANN的数据类型和内存管理,这是写高
CANN数据类型与内存管理入门
昇腾训练营报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机、平板、开发板等大奖。
前言
写完第一个算子后,我发现自己对数据类型和内存管理还是一知半解。什么时候用FP16,什么时候用FP32?Global Memory和Unified Buffer到底有什么区别?内存对齐是怎么回事?
这些问题直到我踩了几次坑,才慢慢理解。让我们先看看CANN的整体架构:
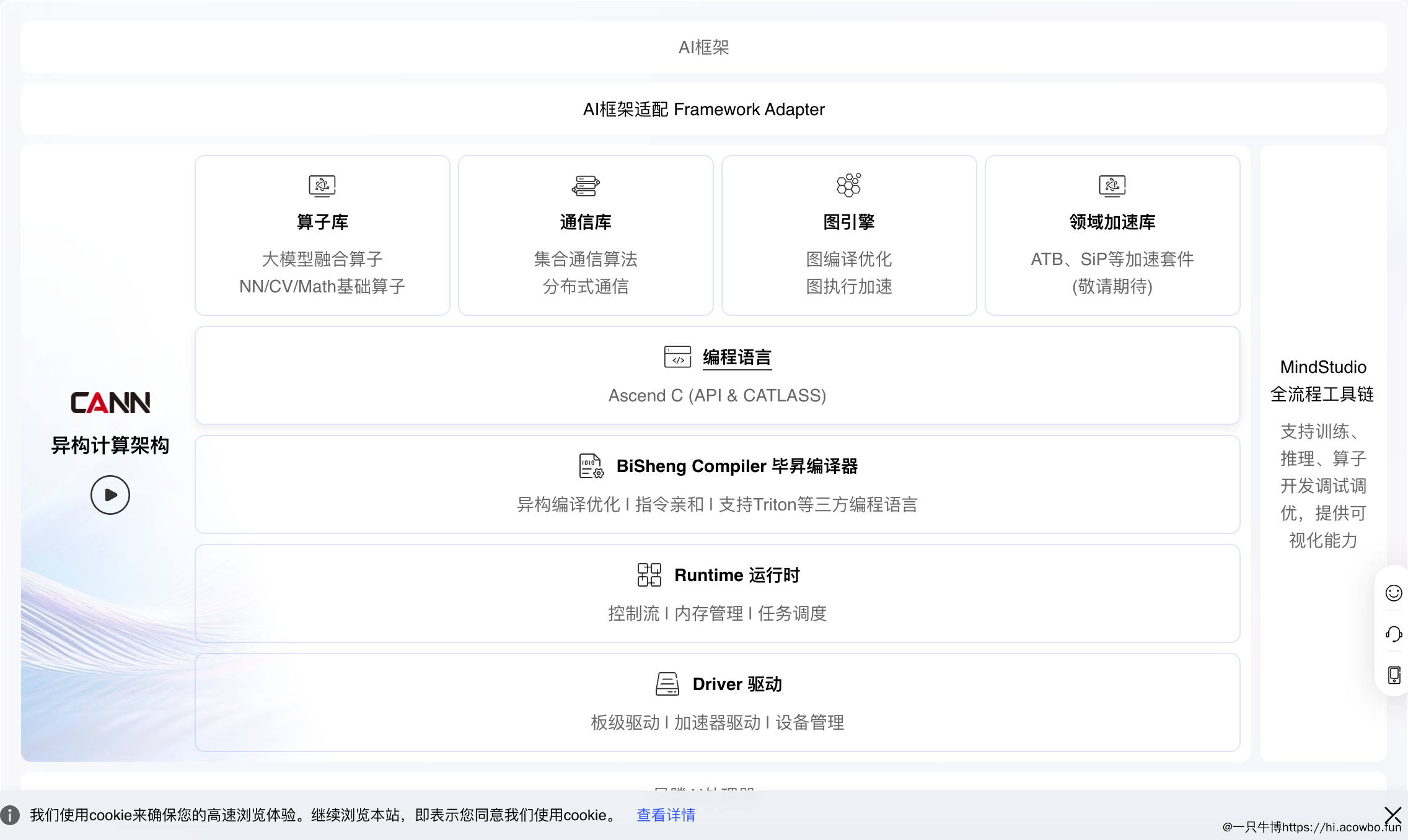
从官方架构图可以看到,CANN的异构计算架构包含多层内存层次和不同的数据类型支持。今天就来系统梳理CANN的数据类型和内存管理,这是写高性能算子的基础!
一、CANN支持的数据类型
1.1 标量类型
CANN支持多种数据类型,每种都有各自的用途:
// 浮点类型
half // FP16,16位浮点(最常用)
float // FP32,32位浮点
bfloat16 // BF16,Google提出的16位浮点(部分硬件支持)
// 整数类型
int8_t // 8位有符号整数
uint8_t // 8位无符号整数
int16_t // 16位有符号整数
uint16_t // 16位无符号整数
int32_t // 32位有符号整数
uint32_t // 32位无符号整数
int64_t // 64位有符号整数(部分操作支持)
// 布尔类型
bool // 1字节
1.2 数据类型详解
FP16 (half):
half x = 1.5f; // FP16
// 内存占用:2字节
// 精度:约3位小数
// 范围:±6.5e4
// 用途:深度学习最常用,速度快,精度够用
FP16的内存布局:
15 10 9 0
[符号][指数][尾数部分]
1位 5位 10位
FP32 (float):
float y = 1.5f; // FP32
// 内存占用:4字节
// 精度:约7位小数
// 范围:±3.4e38
// 用途:高精度要求的场景
BF16 (bfloat16):
bfloat16 z = 1.5f; // BF16
// 内存占用:2字节
// 精度:约2-3位小数(比FP16略差)
// 范围:±3.4e38(和FP32相同!)
// 用途:训练大模型,保持FP32的数值范围
三者对比:
| 类型 | 大小 | 精度 | 范围 | 速度 | 应用 |
|---|---|---|---|---|---|
| FP16 | 2B | 高 | 小 | 最快 | 推理 |
| BF16 | 2B | 中 | 大 | 快 | 训练 |
| FP32 | 4B | 最高 | 大 | 慢 | 高精度计算 |
我的使用经验:
- 推理:优先FP16,速度快,精度够
- 训练:用BF16或FP32,避免梯度下溢
- 中间计算:可以用FP32累加,输入输出用FP16
1.3 向量类型
NPU支持向量运算,一条指令处理多个数据:
// FP16向量(最常用)
half8 vec8; // 8个half,16字节
half16 vec16; // 16个half,32字节
half32 vec32; // 32个half,64字节
// FP32向量
float8 vec8; // 8个float,32字节
float16 vec16; // 16个float,64字节
// INT8向量
int8x32 vec32; // 32个int8,32字节
int8x64 vec64; // 64个int8,64字节
为什么向量化重要?
// 标量方式:256条指令
for (int i = 0; i < 256; i++) {
z[i] = x[i] + y[i]; // 每次处理1个元素
}
// 向量方式:16条指令(FP16向量宽度=16)
Add(z, x, y, 256); // 每次处理16个元素,快16倍!
二、内存层次结构
2.1 NPU的内存架构
NPU有多级内存,理解它们很关键
2.2 各级内存详解
DDR/HBM (外部内存)
// 通常不直接操作,通过AscendCL API管理
void* devPtr;
aclrtMalloc(&devPtr, size, ACL_MEM_MALLOC_HUGE_FIRST);
特点:
- ✅ 容量大(GB级)
- ❌ 速度慢
- 用途:存储模型参数、输入输出数据
Global Memory (GM)
__gm__ half* gmPtr; // GM指针
GlobalTensor<half> gmTensor;
gmTensor.SetGlobalBuffer(gmPtr);
特点:
- ✅ 容量较大(几GB)
- ⚠️ 速度一般
- 用途:Kernel的输入输出,临时存储
Unified Buffer (UB)
__ubuf__ half ubArray[1024]; // UB数组
LocalTensor<half> ubTensor;
特点:
- ✅ 速度快(~1TB/s)
- ❌ 容量小(几MB)
- 用途:计算时的工作区,Tiling的缓冲区
这是我们算子开发中最常用的内存!
L0 Buffer
// 通常由编译器自动管理,很少手动操作
特点:
- ✅ 速度最快(寄存器级)
- ❌ 容量极小(几KB)
- 用途:向量计算的临时寄存器
2.3 内存访问模式
不同内存之间的数据搬运:
// 1. GM -> UB (最常见)
LocalTensor<half> ubTensor = queue.AllocTensor<half>();
DataCopy(ubTensor, gmTensor[offset], count);
// 2. UB -> GM
DataCopy(gmTensor[offset], ubTensor, count);
// 3. UB -> UB (很少用)
DataCopy(ubTensor2, ubTensor1, count);
// 4. GM -> GM (不推荐,效率低)
// 应该通过UB中转
我踩过的坑:直接GM到GM拷贝
// ❌ 错误:直接GM到GM(不支持或效率低)
DataCopy(gmTensor2, gmTensor1, count);
// ✅ 正确:通过UB中转
LocalTensor<half> temp = queue.AllocTensor<half>();
DataCopy(temp, gmTensor1, count);
DataCopy(gmTensor2, temp, count);
queue.FreeTensor(temp);
三、内存对齐
3.1 为什么要内存对齐?
NPU硬件要求数据按特定边界对齐,才能高效访问。就像快递打包,按固定规格打包效率更高。
3.2 对齐规则
CANN的对齐要求:
// FP16: 32字节对齐(16个half)
constexpr uint32_t TILE_SIZE_FP16 = 256; // ✅ 256 * 2 = 512B,是32的倍数
// FP32: 32字节对齐(8个float)
constexpr uint32_t TILE_SIZE_FP32 = 256; // ✅ 256 * 4 = 1024B,是32的倍数
// 不对齐的例子
constexpr uint32_t TILE_SIZE_BAD = 100; // ❌ 100 * 2 = 200B,不是32的倍数
3.3 对齐检查
// 检查地址是否对齐
bool IsAligned(void* ptr, size_t alignment) {
return (reinterpret_cast<uintptr_t>(ptr) % alignment) == 0;
}
// 使用
if (!IsAligned(devPtr, 32)) {
printf("Warning: pointer not aligned!\n");
}
3.4 我的对齐踩坑经历
有一次我写了个算子,Tile大小设成100:
constexpr uint32_t TILE_SIZE = 100; // ❌
pipe.InitBuffer(queue, 2, TILE_SIZE * sizeof(half)); // 200字节
运行报错:
[ERROR] Memory alignment error
改成128后就好了:
constexpr uint32_t TILE_SIZE = 128; // ✅
pipe.InitBuffer(queue, 2, TILE_SIZE * sizeof(half)); // 256字节
四、内存分配与释放
4.1 Host端内存管理
// 方法1:使用aclrtMalloc (推荐)
void* devPtr = nullptr;
aclError ret = aclrtMalloc(&devPtr, size, ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_SUCCESS) {
printf("Malloc failed\n");
return -1;
}
// 使用...
// 释放
aclrtFree(devPtr);
// 方法2:使用aclrtMallocHost (Host内存,可以零拷贝访问)
void* hostPtr = nullptr;
aclrtMallocHost(&hostPtr, size);
// ...
aclrtFreeHost(hostPtr);
4.2 Device端内存管理
在Kernel内部,使用Queue管理:
// 初始化Buffer
pipe.InitBuffer(queue, BUFFER_NUM, TILE_SIZE * sizeof(half));
// 分配Tensor
LocalTensor<half> tensor = queue.AllocTensor<half>();
// 使用...
// 释放
queue.FreeTensor(tensor);
关键点:
AllocTensor和FreeTensor必须配对- 忘记Free会导致内存泄漏
- 多次Free同一个Tensor会crash
4.3 内存泄漏检测
我写了个简单的检测工具:
class MemTracker {
private:
static int allocCount;
static int freeCount;
public:
static void OnAlloc() { allocCount++; }
static void OnFree() { freeCount++; }
static void Report() {
printf("Alloc: %d, Free: %d\n", allocCount, freeCount);
if (allocCount != freeCount) {
printf("⚠️ Memory leak detected!\n");
}
}
};
// 使用
LocalTensor<half> tensor = queue.AllocTensor<half>();
MemTracker::OnAlloc();
// ...
queue.FreeTensor(tensor);
MemTracker::OnFree();
// 程序结束时
MemTracker::Report();
五、数据类型转换
5.1 显式转换
// FP32 -> FP16
float f32 = 1.5f;
half h16 = static_cast<half>(f32);
// FP16 -> FP32
half h16 = 1.5;
float f32 = static_cast<float>(h16);
// 整数 -> 浮点
int32_t i32 = 100;
half h16 = static_cast<half>(i32);
5.2 向量转换
CANN提供了向量转换API:
// FP32 -> FP16 (向量)
LocalTensor<float> fp32Tensor;
LocalTensor<half> fp16Tensor;
Cast(fp16Tensor, fp32Tensor, count, CastMode::FP32_TO_FP16);
// FP16 -> FP32 (向量)
Cast(fp32Tensor, fp16Tensor, count, CastMode::FP16_TO_FP32);
// INT32 -> FP16
Cast(fp16Tensor, int32Tensor, count, CastMode::INT32_TO_FP16);
5.3 精度损失问题
FP32转FP16会损失精度:
float f32 = 1.234567f; // FP32精度
half h16 = static_cast<half>(f32);
float f32_back = static_cast<float>(h16);
printf("Original: %.7f\n", f32); // 1.2345670
printf("After cast: %.7f\n", f32_back); // 1.2343750 (精度损失!)
我的经验:
- 如果精度要求高,中间计算用FP32,最后再转FP16
- 梯度累加一定要用FP32,否则会下溢
六、Tensor操作
6.1 Tensor的创建
// 方法1:通过Queue分配
LocalTensor<half> tensor1 = queue.AllocTensor<half>();
// 方法2:设置Global Buffer
GlobalTensor<half> tensor2;
tensor2.SetGlobalBuffer((__gm__ half*)ptr);
// 方法3:栈上分配(小数据量)
__ubuf__ half buffer[128];
LocalTensor<half> tensor3 = *(LocalTensor<half>*)buffer;
6.2 Tensor的基本操作
// 获取大小
uint32_t size = tensor.GetSize();
// 访问元素(不推荐,用向量操作)
half value = tensor.GetValue(index);
// 设置元素(不推荐)
tensor.SetValue(index, value);
// 获取指针(谨慎使用)
half* ptr = tensor.GetData();
6.3 Tensor的拷贝
// 完整拷贝
DataCopy(dstTensor, srcTensor, count);
// 带偏移的拷贝
uint32_t srcOffset = 100;
uint32_t dstOffset = 0;
DataCopy(dstTensor[dstOffset], srcTensor[srcOffset], count);
// 带步长的拷贝(某些场景)
DataCopyPad(dstTensor, srcTensor, count, stride);
七、内存优化技巧
7.1 减少数据搬运
// ❌ 不好:频繁搬运
for (int i = 0; i < 100; i++) {
DataCopy(ub, gm[i], 1); // 搬运1个元素,100次
Compute(ub, 1);
DataCopy(gm[i], ub, 1);
}
// ✅ 好:批量搬运
DataCopy(ub, gm, 100); // 搬运100个元素,1次
Compute(ub, 100);
DataCopy(gm, ub, 100);
7.2 数据复用
// ❌ 不好:重复搬运
DataCopy(ub, gm[0], size); // 搬运一次
Compute1(ub);
FreeTensor(ub);
ub = AllocTensor();
DataCopy(ub, gm[0], size); // 又搬运一次(数据没变!)
Compute2(ub);
// ✅ 好:复用数据
DataCopy(ub, gm[0], size); // 只搬运一次
Compute1(ub);
Compute2(ub); // 复用数据
FreeTensor(ub);
7.3 内存池
对于频繁分配释放,可以用内存池:
class TensorPool {
private:
std::vector<LocalTensor<half>> pool;
public:
LocalTensor<half> Acquire() {
if (pool.empty()) {
return queue.AllocTensor<half>(); // 新分配
} else {
LocalTensor<half> tensor = pool.back();
pool.pop_back();
return tensor; // 复用
}
}
void Release(LocalTensor<half> tensor) {
pool.push_back(tensor); // 回收
}
};
八、常见错误及解决
错误1:内存越界
[ERROR] Memory access out of bounds
原因:
constexpr uint32_t TILE_SIZE = 256;
pipe.InitBuffer(queue, 2, TILE_SIZE * sizeof(half)); // 分配256个元素
LocalTensor<half> tensor = queue.AllocTensor<half>();
DataCopy(tensor, gm, 512); // ❌ 拷贝512个元素,越界!
解决:确保拷贝大小不超过Buffer大小
错误2:内存未对齐
[ERROR] Memory alignment error, addr=0x...
原因:Tile大小不是32字节的倍数
解决:调整TILE_SIZE为32字节的倍数
错误3:内存泄漏
现象:运行一段时间后,可用内存越来越少
# 用npu-smi监控
watch -n 1 npu-smi info
原因:忘记FreeTensor或aclrtFree
解决:确保每个Alloc都有对应的Free
九、实战案例:手动内存管理
完整示例:
class MyKernel {
public:
__aicore__ inline void Process() {
// 1. 分配内存
LocalTensor<half> input1 = queueIn.AllocTensor<half>();
LocalTensor<half> input2 = queueIn.AllocTensor<half>();
LocalTensor<half> temp = queueTemp.AllocTensor<half>();
LocalTensor<half> output = queueOut.AllocTensor<half>();
// 2. 拷贝数据
DataCopy(input1, gmInput1, TILE_SIZE);
DataCopy(input2, gmInput2, TILE_SIZE);
// 3. 计算
Mul(temp, input1, input2, TILE_SIZE); // temp = input1 * input2
Add(output, temp, input1, TILE_SIZE); // output = temp + input1
// 4. 拷贝结果
DataCopy(gmOutput, output, TILE_SIZE);
// 5. 释放内存(重要!)
queueIn.FreeTensor(input1);
queueIn.FreeTensor(input2);
queueTemp.FreeTensor(temp);
queueOut.FreeTensor(output);
}
private:
TPipe pipe;
GlobalTensor<half> gmInput1, gmInput2, gmOutput;
TQue<QuePosition::VECIN, 2> queueIn;
TQue<QuePosition::VECCALC, 2> queueTemp;
TQue<QuePosition::VECOUT, 2> queueOut;
};
十、总结
CANN数据类型和内存管理要点:
数据类型:
- FP16:推理首选,速度快
- BF16:训练友好,范围大
- FP32:高精度计算
- 向量类型:性能关键
内存层次:
- DDR/HBM:容量大,速度慢
- Global Memory:中转存储
- Unified Buffer:计算工作区(最常用)
- L0 Buffer:寄存器级(编译器管理)
关键原则:
- ✅ 内存对齐(32字节)
- ✅ 分配释放配对
- ✅ 减少数据搬运
- ✅ 数据复用
- ✅ 向量化访问
理解了这些,就能写出高效的CANN算子。下一篇我会讲Tensor的高级操作,包括shape变换、数据排布等。
相关文章推荐:
- 上一篇:第一个Hello World算子开发实战
- 下一篇:Tensor操作基础:理解张量在NPU中的运作
练习建议:
试着修改Hello World算子,换成FP32数据类型,观察性能差异。
有问题欢迎留言!点赞收藏支持一下~

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)