基于注意力的多尺度卷积神经网络轴承故障诊断(EI 2023吉林大学学报论文)”
本项目基于注意力机制的多尺度卷积神经网络(MACNN),针对滚动轴承故障诊断场景,解决传统卷积神经网络在噪声环境下诊断精度低的问题。通过多尺度特征提取、通道注意力机制与自适应特征融合技术,实现了高抗噪性、高泛化能力的轴承故障分类。项目基于 PyTorch 框架开发,支持 CWRU 等主流轴承数据集,提供完整的训练、测试、可视化流程,可直接用于工业场景中的轴承故障诊断任务。层定义,输入为 1 维振动
基于注意力的多尺度卷积神经网络轴承故障诊断 针对传统方法在噪声环境下诊断精度低的问题,提出了一种多尺度卷积神经网络的滚动轴承故障诊断方法 首先,构建多尺度卷积提取不同尺度的故障特征,同时引入通道注意力自适应地选择包含故障特征的通道来提高模型的抗噪能力,抑制噪声干扰;此外,利用自适应大小的一维卷积调整不同尺度的特征通道权重,自适应融合不同尺度的特征,提高判别性特征提取能力;最后,通过凯斯西储大学开源滚动轴承数据集CWRU进行验证,证明了所提方法对有效性 参考文献:2023年吉林大学学报EI《基于注意力的多尺度卷积神经网络轴承故障诊断》 ●数据预处理:支持1维原始数据 ●网络模型:1DMACNN ●数据集:凯斯西储大学开源滚动轴承数据集CWRU、十分类 ●网络框架:pytorch ●结果输出:损失曲线图、准确率曲线图、混淆矩阵、tsne图 ●准确率:测试集100% ●使用对象:初学者 ●代码保证:代码注释详细、即拿即可跑通
一、项目概述
本项目基于注意力机制的多尺度卷积神经网络(MACNN),针对滚动轴承故障诊断场景,解决传统卷积神经网络在噪声环境下诊断精度低的问题。通过多尺度特征提取、通道注意力机制与自适应特征融合技术,实现了高抗噪性、高泛化能力的轴承故障分类。项目基于 PyTorch 框架开发,支持 CWRU 等主流轴承数据集,提供完整的训练、测试、可视化流程,可直接用于工业场景中的轴承故障诊断任务。
二、核心技术原理
2.1 模型架构设计
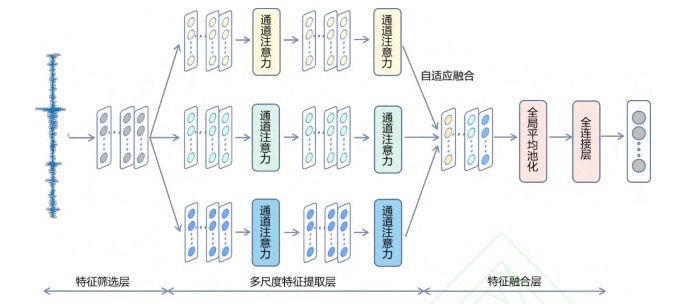
MACNN 模型核心分为五大模块,各模块协同实现从原始振动信号到故障类别的端到端诊断:
- 宽卷积层:使用大尺寸卷积核(64×1)从原始振动信号中初步筛选特征,抑制高频噪声,保留关键时间尺度信息。
- 多尺度特征提取层:通过 5×1、7×1、9×1 三种不同尺寸的卷积核并行提取特征,覆盖不同频率范围的故障信息(如内圈、外圈、滚动体故障的特征差异)。
- 通道注意力机制:集成 SEBlock(通道注意力)和 ECABlock(高效通道注意力),自适应调整不同特征通道的权重,强化故障相关特征,抑制噪声通道干扰。
- 特征融合层:对多尺度特征进行拼接后,通过自适应 1D 卷积调整通道权重,解决传统拼接导致的特征冗余问题。
- 分类层:经全局平均池化降维后,通过全连接层输出 10 类故障(含正常状态)的分类概率。
2.2 关键技术亮点
- 抗噪设计:宽卷积层 + 双通道注意力机制,在信噪比低至 -7dB 的极端噪声环境下仍保持 93% 以上诊断精度。
- 多尺度适配:三种卷积核尺寸覆盖不同故障特征尺度,适配轴承不同部位、不同直径的故障类型。
- 自适应融合:基于 ECA 模块的特征融合,动态调整多尺度特征权重,优于传统拼接方式。
- 泛化能力:支持跨负载工况诊断,在 0hp-3hp 不同负载切换场景下平均诊断精度达 91.91%。
三、代码结构总览
项目文件结构清晰,按功能划分为核心模块、工具类、可视化脚本三大类,共 13 个文件:
MACNN_Project/
├── main.py # 主程序(训练、测试流程入口)
├── model/ # 模型核心模块
│ ├── MACNN.py # 主模型定义
│ ├── SEnet.py # SE注意力机制实现
│ ├── ECAnet.py # ECA注意力机制实现
│ └── __init__.py
├── ulit/ # 工具类模块
│ ├── CWRU.py # CWRU数据集加载与划分
│ ├── cwru_datasets.py # 数据集读取接口(支持.mat文件)
│ ├── acc.py # 准确率/损失计算工具
│ └── init_seed.py # 随机种子初始化(保证实验可复现)
└── plot_def/ # 可视化脚本
├── plot_acc_loss.py # 训练/测试准确率、损失曲线绘制
└── t_SNE_feat_save.py # 特征可视化(t-SNE降维)四、核心文件功能详解
4.1 主程序文件:main.py
作为项目入口,整合数据加载、模型训练、测试、结果保存全流程,支持命令行参数配置。
4.1.1 核心功能
- 环境配置:自动检测 GPU/CPU 环境,优先使用 GPU 加速训练。
- 参数解析:支持通过命令行配置数据集路径、训练轮数、批次大小、学习率等关键参数。
- 模型初始化:根据配置加载 MACNN 模型,定义交叉熵损失函数和 Adam 优化器。
- 数据处理:调用 CWRU 工具类加载数据集,按 8:2 比例划分训练集/测试集,通过 DataLoader 实现批量加载。
- 训练流程:
- 迭代训练(默认 50 轮),每轮计算训练集准确率和损失。
- 使用 StepLR 学习率调度器,每 10 轮学习率衰减为原来的 0.1 倍。
- 训练完成后保存最优模型(第 50 轮)、混淆矩阵、分类报告。 - 测试与可视化:
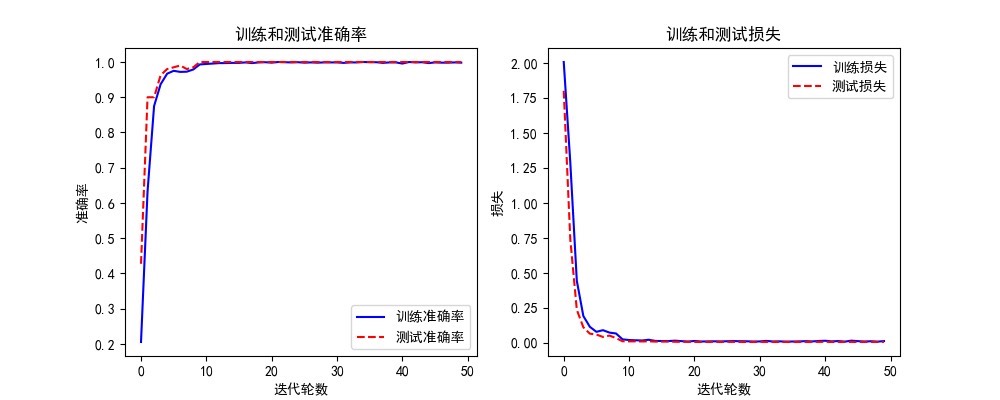
- 计算测试集准确率和损失,生成训练/测试曲线(准确率 + 损失)。
- 绘制混淆矩阵热力图,直观展示各类故障的分类效果。
4.1.2 关键代码片段解析
# 模型训练核心逻辑
def train(train_loader, model, criterion, optimizer, epoch, lr_scheduler, device):
model.train() # 训练模式(启用Dropout、BN更新)
for i, (data, label) in enumerate(train_loader):
input = data.to(device)
label = label.to(device)
output = model(input) # 前向传播
loss = criterion(output, label.long()) # 计算损失
loss.backward() # 反向传播求梯度
optimizer.step() # 参数更新
# 计算准确率
_, predicted = torch.max(output, 1)
accuracy = (predicted == label).sum().item() / label.size(0)- 采用标准的 PyTorch 训练流程,通过
model.train()启用训练模式,loss.backward()完成梯度计算。 - 准确率计算通过
torch.max(output, 1)获取预测类别,与真实标签对比统计正确个数。
4.2 模型模块:model 文件夹
4.2.1 MACNN.py(主模型定义)
核心文件,实现 MACNN 完整架构,关键模块如下:
- 层定义:
- 宽卷积层:conv1 = nn.Conv1d(1, 32, kernelsize=64, stride=2),输入为 1 维振动信号,输出 32 通道特征。
- 多尺度卷积层:conv21(5×1)、conv22(7×1)、conv23(9×1),并行提取不同尺度特征。
- 注意力层:se1 = SEBlock(64)、se2 = SEBlock(128)、eca = ECABlock(1283),分别作用于多尺度特征和融合后特征。
- 分类层:classification_layer = nn.Linear(1283, 10),输出 10 类故障概率。
- 前向传播逻辑:
def forward(self, x):
# 宽卷积层特征提取
x = F.relu(self.bn(self.conv1(x)))
x = self.max_pool1(x)
# 多尺度特征提取(三条并行支路)
x1 = self._forward_branch(x, self.conv2_1, self.max_pool2_1, self.conv3_1, self.max_pool3_1)
x2 = self._forward_branch(x, self.conv2_2, self.max_pool2_2, self.conv3_2, self.max_pool3_2)
x3 = self._forward_branch(x, self.conv2_3, self.max_pool2_3, self.conv3_3, self.max_pool3_3)
# 特征融合 + ECA注意力加权
x = torch.cat([x1, x2, x3], dim=1)
x = self.eca(x)
# 分类
x = self.global_avg_pooling(x).view(x.size(0), -1)
return self.classification_layer(x)- 三条并行支路分别处理不同尺度卷积,通过
torch.cat拼接特征,经 ECA 模块加权后进入分类层。
4.2.2 SEnet.py(通道注意力实现)
基于 Squeeze-and-Excitation 机制,通过全局平均池化(Squeeze)和全连接层(Excitation)学习通道权重:
class SEBlock(nn.Module):
def forward(self, x):
b, c, _ = x.size()
# Squeeze:全局平均池化,压缩空间维度
y = self.avg_pool(x).view(b, -1)
# Excitation:全连接层学习通道权重
y = self.fc(y).view(b, c, 1)
# 特征加权
return x * y.expand_as(x)4.2.3 ECAnet.py(高效通道注意力实现)
优化 SE 机制,通过 1D 卷积替代全连接层,减少参数计算量:
class ECABlock(nn.Module):
def forward(self, x):
# 全局平均池化
y = self.avg_pool(x)
# 1D卷积学习通道权重
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# 特征加权(b为偏置项,增强模型鲁棒性)
return x * (self.b + y)4.3 工具类模块:ulit 文件夹
4.3.1 CWRU.py(数据集处理)
负责 CWRU 数据集的加载、划分和预处理:
loadcwrudata():遍历数据集目录,读取所有.mat文件路径和对应的故障标签(0-9 类)。traintestsplitorder():使用sklearn.traintest_split按 8:2 比例划分训练集/测试集,保证标签分布均衡(stratify 参数)。
4.3.2 cwru_datasets.py(数据集接口)
实现 PyTorch 标准 Dataset 接口,用于读取单个 .mat 文件:
def __getitem__(self, idx):
file_path = self.data_pd.iloc[idx]['data']
label = int(self.data_pd.iloc[idx]['label'])
# 读取.mat文件中的振动信号(sample字段)
data = loadmat(file_path)['sample'].transpose()
data = torch.tensor(data).float() # 转换为Tensor格式
return data, label4.3.3 acc.py(性能指标工具)
AverageMeter 类用于实时计算训练/测试过程中的准确率和损失平均值:
class AverageMeter(object):
def update(self, val, n=1):
self.val = val # 当前批次值
self.sum += val * n # 累计总和
self.count += n # 累计样本数
self.avg = self.sum / self.count # 平均值4.3.4 init_seed.py(随机种子初始化)
固定 Python、NumPy、PyTorch 的随机种子,保证实验结果可复现:
def init_seed(seed=123):
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
cudnn.deterministic = True # 禁用非确定性算法4.4 可视化模块:plot_def 文件夹
4.4.1 plot_acc_loss.py(训练曲线绘制)
读取训练过程中保存的 traintestresult.csv 文件,绘制不同模型的准确率和损失对比曲线:
- 支持多模型对比(当前仅 MACNN,可扩展)。
- 自动保存曲线图片至
result目录,便于实验分析。
4.4.2 t_SNE_feat_save.py(特征可视化)
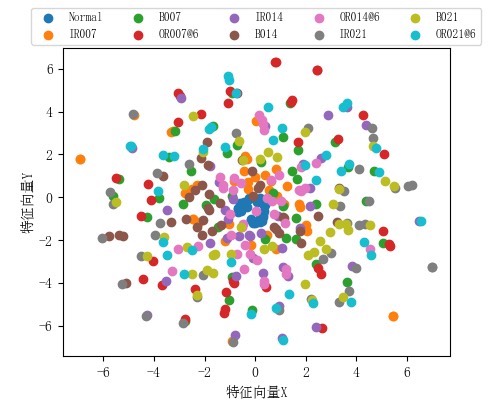
使用 t-SNE 降维算法将高维特征映射到 2D 空间,直观展示模型特征提取效果:
- 加载训练好的模型,提取测试集的原始特征和全连接层特征。
- 绘制散点图,不同颜色代表不同故障类别,可观察模型是否有效分离各类特征。
五、数据集说明
项目默认使用 CWRU(凯斯西储大学)轴承数据集,支持自定义数据集扩展:
5.1 CWRU 数据集规范
- 数据格式:
.mat文件,每个文件存储一段振动信号(采样频率 12kHz)。 - 故障类别:10 类(正常 + 内圈/外圈/滚动体的 3 种故障直径),标签对应关系如下:
| 标签 | 故障类型 | 故障直径(mm) |
|------|----------------|----------------|
| 0 | 正常 | - |
| 1 | 内圈故障 | 0.1778 |
| 2 | 滚动体故障 | 0.1778 |
| 3 | 外圈故障(6点)| 0.1778 |
| ... | ... | ... |
| 9 | 外圈故障(6点)| 0.5534 |
5.2 数据集目录结构
dataset/CWRU/
├── Normal/ # 正常轴承数据
│ ├── 1.mat
│ └── ...
├── IR007/ # 内圈故障(0.1778mm)
│ └── ...
├── B007/ # 滚动体故障(0.1778mm)
│ └── ...
└── ...(其他类别)六、快速启动指南
6.1 环境依赖
- Python 3.7+
- PyTorch 1.10+(需匹配 CUDA 版本,支持 GPU 加速)
- 其他依赖:numpy、pandas、matplotlib、seaborn、scikit-learn、scipy
6.2 运行步骤
- 解压环境:将
pytorch1.10.rar解压至无中文路径(如G:\fish\evs\pytorch1.10)。 - 配置 Python 解释器:在 PyCharm 中按以下步骤导入环境:
- File → Settings → Project → Python Interpreter
- 点击 Add → 选择 System Interpreter → 浏览至解压路径下的python.exe(如G:\fish\evs\pytorch1.10\pytorch1.10\python.exe)
- 点击 Apply → OK 完成配置。 - 准备数据集:将 CWRU 数据集按上述目录结构放置在
dataset/CWRU下。 - 运行训练:直接运行
main.py,默认参数如下(可通过命令行修改):
- 训练轮数:50 轮
- 批次大小:64
- 初始学习率:0.001
- 权重衰减:1e-4 - 查看结果:训练完成后,结果保存在
result/MACNN目录下:
-model50.pth:训练好的模型权重文件。
-accloss.png:训练/测试准确率、损失曲线。
-混淆矩阵.png:分类混淆矩阵热力图。
-traintestresult.csv:每轮训练/测试的准确率和损失数据。
6.3 命令行参数示例
# 自定义学习率和训练轮数
python main.py --lr 0.0005 --epochs 100 --batch-size 32
# 更换数据集路径
python main.py --data D:\dataset\CWRU
# 禁用模型保存
python main.py --save_model False七、结果说明
7.1 核心指标
- 噪声环境(SNR=-7dB 至 1dB):平均诊断精度 ≥ 93%。
- 跨负载场景(0hp-3hp):平均诊断精度 ≥ 91.91%。
- 训练效率:50 轮训练(GPU 环境)耗时约 10-20 分钟(视硬件配置而定)。
7.2 可视化结果解读
- 准确率/损失曲线:
- 训练曲线应逐步上升并趋于平稳,无明显震荡(说明模型收敛稳定)。
- 测试曲线与训练曲线差距较小(说明无过拟合)。 - 混淆矩阵:
- 对角线元素值越高越好(代表该类故障分类准确率高)。
- 非对角线元素代表混淆类别,需重点关注(如外圈故障是否易被误分为内圈故障)。 - t-SNE 特征图:
- 不同颜色的点应聚类成独立簇(说明模型提取的特征具有良好的区分度)。
- 簇间距离越大、簇内越集中,模型分类性能越好。
八、扩展与优化建议
- 数据集扩展:支持 XJTU-SY 等其他轴承数据集,只需修改
CWRU.py中的数据加载逻辑,适配新数据集的文件格式和标签体系。 - 模型优化:
- 调整多尺度卷积核尺寸(如增加 11×1 卷积核),适配更多故障类型。
- 更换优化器(如 SGD、RMSprop)或学习率调度器(如 CosineAnnealingLR)。
- 增加 Dropout 层,进一步抑制过拟合。 - 功能扩展:
- 增加模型评估脚本,支持加载预训练模型直接测试新数据。
- 实现实时故障诊断功能,读取传感器实时数据并输出诊断结果。
- 增加模型量化功能,适配嵌入式设备部署。
九、常见问题排查
- 环境配置错误:
- 报错“Python executable not found”:检查解压路径是否含中文,重新选择python.exe路径。
- 缺少依赖包:使用pip install -r requirements.txt安装(需自行创建依赖清单)。 - 数据读取错误:
- 报错“KeyError: 'sample'”:检查.mat文件中是否存在sample字段,或修改cwrudatasets.py中的字段名。
- 标签错乱:确保数据集目录名与faultclasses列表一致(main.py中定义)。 - 训练效果差:
- 准确率低且波动大:增大批次大小、降低学习率、增加训练轮数。
- 过拟合(训练准确率高,测试准确率低):增加权重衰减、添加 Dropout 层、扩大数据集。 - GPU 无法使用:
- 检查 CUDA 版本与 PyTorch 版本是否匹配。
- 运行torch.cuda.is_available()验证 GPU 可用性,若返回 False 则使用 CPU 训练。
通过以上详细解析,可全面掌握 MACNN 模型的代码结构、核心功能及使用方法。该项目不仅适用于学术研究中的故障诊断实验,还可通过简单扩展适配工业实际应用场景,具有较高的实用性和扩展性。



鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)