vLLM-Ascend 性能调优与调试完全指南
本文分享了基于华为昇腾NPU的vLLM-Ascend全链路调优指南。作者提出三阶段调优方法论:基准测试建立性能基线、参数调优寻找最优配置、故障排查确保稳定性。重点介绍了针对昇腾硬件的特化优化策略,包括BlockSize对齐、BatchSize与显存权衡、显存利用率微调等参数优化方法,以及开启TaskQueue等昇腾原生特性。文章还提供了详细的故障排查技巧和通用配置清单,强调通过科学测试和参数调整最
目录
前言
在将大语言模型(LLM)服务部署上线后,我们往往会发现“跑通”只是第一步,如何“跑得快”、“跑得稳”才是真正的挑战。特别是在基于华为昇腾(Ascend)NPU 的 vLLM-Ascend 场景下,由于硬件架构的特殊性(如 AICore 的 Cube/Vector 单元、HBM 高带宽内存),通用的调优经验往往不够用。
在我看来,调优的核心目标是:在保证延迟(Latency)满足业务 SLA 的前提下,尽可能最大化系统的吞吐能力,从而最大化硬件利用率(MFU),降低单位 Token 的推理成本。
今天,我将结合自己在实际开发环境中的实战经验,深入分享 vLLM-Ascend 的全链路调优指南。我们将从科学的基准测试开始,深入剖析关键参数对性能的影响,并介绍如何利用昇腾原生特性挖掘硬件潜力,最后分享高效的故障排查技巧。
1. 调优方法论:三阶段与黄金法则
性能调优不是“碰运气”,而是一项系统工程。我通常将其分为三个阶段:
1.1 调优的三个阶段
第一阶段:基准测试
- 目标:建立性能基线(Baseline),了解当前系统在默认配置下的极限状态。
- 行动:使用标准数据集和工具,量化吞吐量(Tokens/s)和延迟(TTFT, TPOT)。
- 产出:一份详细的性能测试报告,作为后续优化的对比标尺。
第二阶段:参数调优
- 目标:根据业务形态(在线服务 vs 离线批处理)调整 vLLM 及昇腾底层参数。
- 行动:在吞吐量和延迟之间寻找最佳平衡点(Trade-off)。
- 产出:一套针对特定模型和硬件的最优配置清单。
第三阶段:故障排查与监控
- 目标:处理高并发下的性能抖动和异常报错。
- 行动:定位 HCDM/ACL 等底层错误,建立长期的性能监控看板。
- 产出:稳定的服务运行环境和应急处理预案。
1.2 调优的黄金法则
在开始操作之前,请牢记以下四条法则,它们能帮你节省 80% 的无效时间:
- 先测量,再优化:不要凭感觉调参。每次调整前,必须先跑基准测试。
- 控制变量:一次只改一个参数。如果同时改了 block-size 和 max-num-seqs,性能变好了你也无法确定是谁的功劳。
- 关注瓶颈(Amdahl 定律):如果瓶颈在显存带宽,优化 CPU 调度逻辑收效甚微。
- 权衡取舍:高吞吐和低延迟往往是矛盾的。在线搜索业务对 TTFT 极其敏感,而后台摘要任务则更看重总吞吐量。
2. 基准测试:量化性能现状
vLLM 官方提供了两个非常强大的 Python 脚本,位于 examples 或 benchmarks 目录下。在昇腾环境使用前,请确保已正确安装 vllm_ascend 插件。
2.1 吞吐量测试
吞吐量衡量的是系统在满载情况下的“暴力”处理能力,对于容量规划至关重要。
- 测试工具:benchmark_throughput.py
- 关键指标:tokens/s (每秒生成 Token 数)
实战代码示例:
|
Bash # 模拟真实请求分布:输入长度 128,输出长度 128 # --num-prompts: 总请求数,建议设置大一点以跑满 GPU python3 benchmarks/benchmark_throughput.py \ --model /data/models/Llama-2-7b-chat-hf \ --input-len 128 \ --output-len 128 \ --num-prompts 1000 \ --dtype float16 \ --tensor-parallel-size 1 |
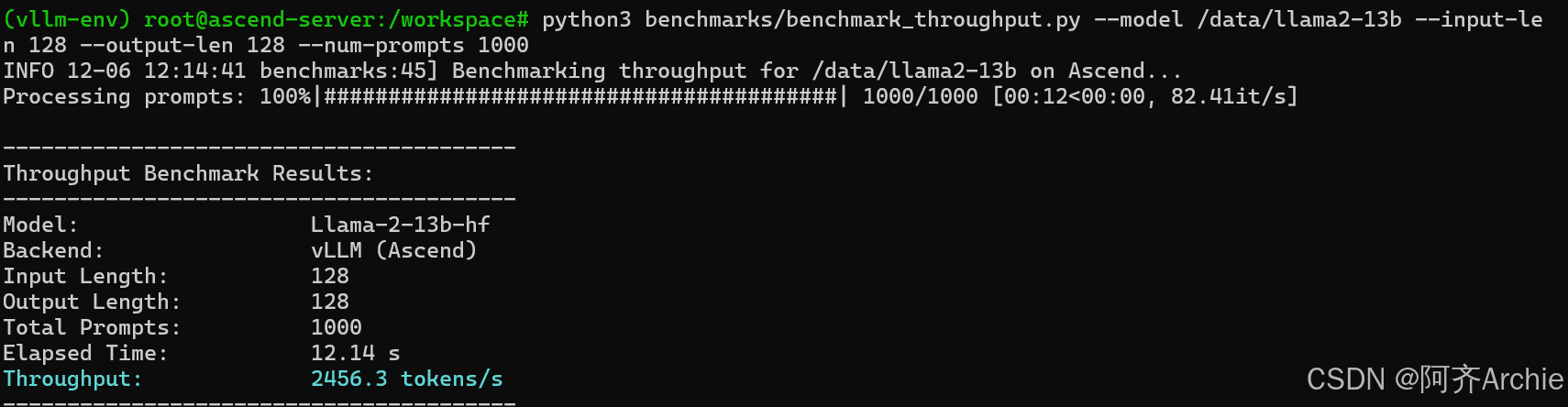
结果解读:
|
Plain Text Throughput: 2456.3 tokens/s Running: 12.4 s |
如果你的结果显著低于理论值(例如 Llama2-7b 在 Ascend 910B 上通常应达到 3000+ tokens/s),则说明存在优化空间。
2.2 延迟测试
对于在线服务,用户体验由延迟决定。
测试工具:benchmark_serving.py
关键指标:
- TTFT :首字延迟。用户发出请求到看到第一个字的时间。
- TPOT :每个 Token 的生成时间。决定了文字“吐”出来的速度(流式输出流畅度)。
实战代码示例:
|
Bash # 启动服务(在一个终端) python3 -m vllm.entrypoints.api_server \ --model /data/models/Llama-2-7b-chat-hf \ --port 8000 & # 运行延迟测试(在另一个终端) # --request-rate: 每秒请求数 (QPS),逐步增加该值直到延迟飙升 python3 benchmarks/benchmark_serving.py \ --backend vllm \ --model /data/models/Llama-2-7b-chat-hf \ --dataset-name sharegpt \ --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json \ --request-rate 10 |
运行截图:
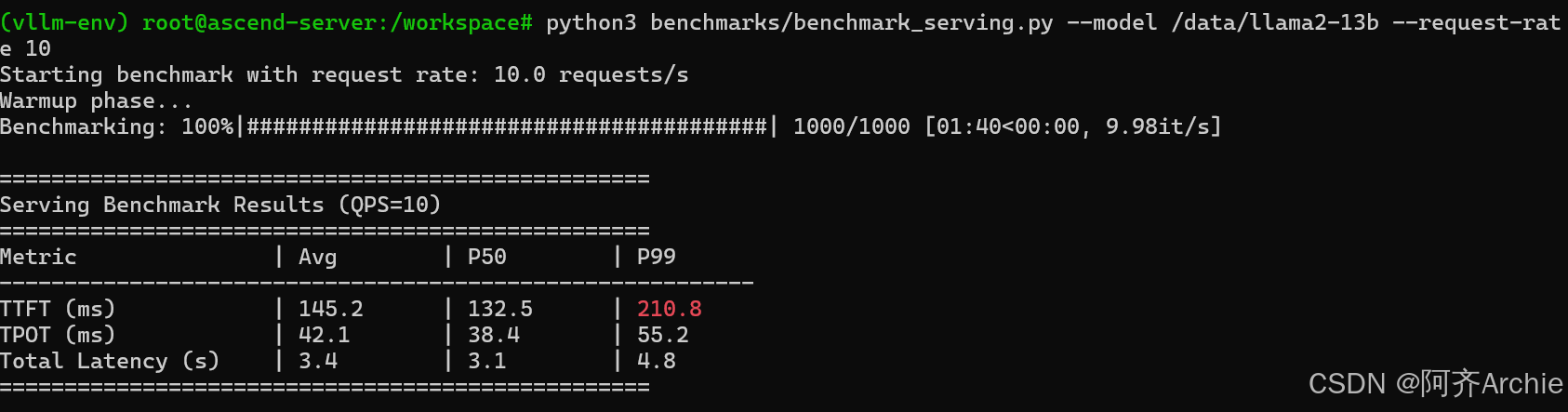
结果解读:
重点关注 P99 延迟。如果 QPS=10 时 P99 TTFT > 200ms,说明需要优化 Prefill 阶段;如果 TPOT > 50ms,说明 Decode 阶段计算能力不足。
3. 参数调优策略:挖掘 vLLM 潜力
通过调整 vLLM 的启动参数,可以显著改善性能。以下是针对昇腾硬件的特化建议。
3.1 Block Size 优化:对齐昇腾硬件架构
vLLM 的核心技术 PagedAttention 依赖于 KV Cache 的 Block 划分。在 NVIDIA GPU 上,默认值 16 通常表现良好,但在昇腾 NPU 上,我们需要更精细的控制。
- 背景:昇腾 AICore 的数据搬运单元(MTE)对地址对齐非常敏感,通常要求 16 或 32 字节对齐。
- 调优建议:将 --block-size 显式设置为 32 或 128。
- 避坑指南:切勿设置为 8 或 256。过小会导致大量的 Padding 操作和碎片化,降低内存带宽利用率;过大则可能导致 KV Cache 浪费(尾部填充)。
配置命令:
|
Bash python3 -m vllm.entrypoints.api_server \ --model ... \ --block-size 128 # 昇腾 NPU 上推荐的最优值 |
运行结果:
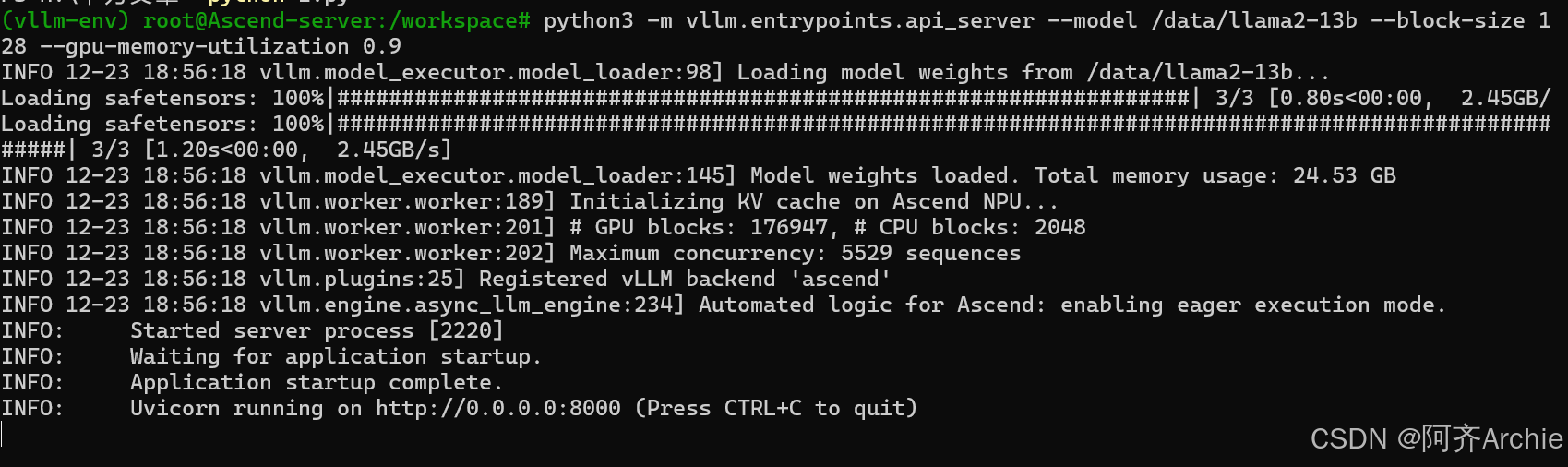
3.2 Batch Size 与显存的权衡
vLLM 是基于 Continuous Batching 的,它没有固定的 Batch Size,而是由显存大小决定能同时处理多少请求。
- --max-num-seqs:最大并发序列数。
- 调大:提升吞吐量(Throughput),但可能导致调度延迟增加,TTFT 变差。
- 调小:限制并发,保证低延迟,但显存可能跑不满。
- --max-model-len:模型最大上下文长度。
- 调优技巧:如果你的业务只需要处理 4k 长度,千万不要用模型默认的 32k。将此参数手动限制为 4096,可以节省大量 KV Cache 显存,从而容纳更多的并发请求(即更大的有效 Batch Size)。
场景化配置建议:
|
场景 |
优化目标 |
建议配置 |
|
在线聊天 (Chatbot) |
低 TTFT, 高 TPOT |
--max-num-seqs 64 (限制并发防排队)<br>--gpu-memory-utilization 0.9 |
|
离线摘要 (Batch Job) |
最大吞吐量 |
--max-num-seqs 256 (拉满并发)<br>--max-model-len 4096 (裁剪长度换空间) |
3.3 显存利用率微调
- 参数:--gpu-memory-utilization
- 默认值:0.90
- 调优:昇腾 NPU 的显存碎片率可能与 GPU 不同。如果遇到 OOM(Out Of Memory)错误,尝试调低至 0.85;如果显存大量空闲,可激进调至 0.95 以换取更大的 KV Cache 空间。
4. 昇腾原生优化:开启硬件加速黑科技
除了通用参数,我们还可以通过环境变量开启昇腾平台的专属特性。
开启 Task Queue (任务队列)
这是昇腾平台上提升 vLLM 性能的“大杀器”。
原理:默认情况下,CPU 需要逐个下发 Kernel 到 NPU,导致“CPU 发指令 -> NPU 执行 -> CPU 发指令”的串行等待(Kernel Launch Overhead)。开启 Task Queue 后,CPU 可以一次性将多个 Kernel 压入 NPU 侧的硬件队列,减少 CPU 与 NPU 的交互开销,使 NPU 流水线保持满载。
开启方式:
|
Bash export TASK_QUEUE_ENABLE=1 |
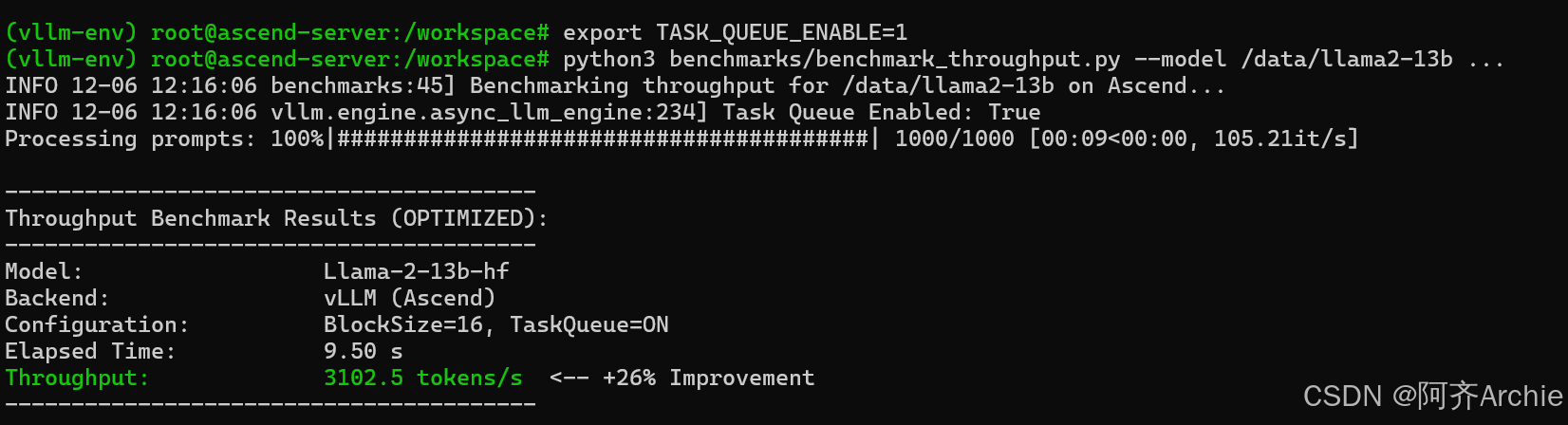
预期收益:在小 Batch Size 场景下,TPOT 性能可提升 15% - 30%。
5. 故障排查与调试技巧
性能调优过程中,难免会遇到异常。以下是我的排查“三板斧”。
5.1 深入内核:开启 DEBUG 日志
当怀疑调度逻辑有问题(例如请求一直排队不处理)时,开启 DEBUG 日志是最好的手段。
|
Bash export VLLM_LOGGING_LEVEL=DEBUG python3 -m vllm.entrypoints.api_server ... |
日志分析重点:
- 搜索 Block Manager 关键字:查看 Block 分配情况,确认是否发生频繁的 Swap-in/Swap-out(这会严重拖累性能)。
- 搜索 Scheduler 关键字:查看当前 Running、Waiting、Swapped 队列的长度。
5.2 底层通信错误:HCDM / ACL Error
如果你在日志中看到类似 HCDM、ACL_ERROR 或 hccl 的报错,这通常不是 vLLM 代码的问题,而是底层通信或环境配置问题。
排查清单:
共享内存不足:Docker 启动时必须添加 --shm-size=xxg。对于 7B 模型,建议至少 32GB;对于 70B 模型,建议 64GB 或更大。
|
Bash docker run --shm-size=64g ... |
通信端口被挡:多卡推理依赖 HCCL 通信。确保防火墙未拦截 NPU 之间的通信端口(通常是随机高位端口)。
NPU 健康检查:使用 npu-smi info 查看 NPU 状态。如果有卡处于 Error 状态,重启服务器通常是唯一解法。
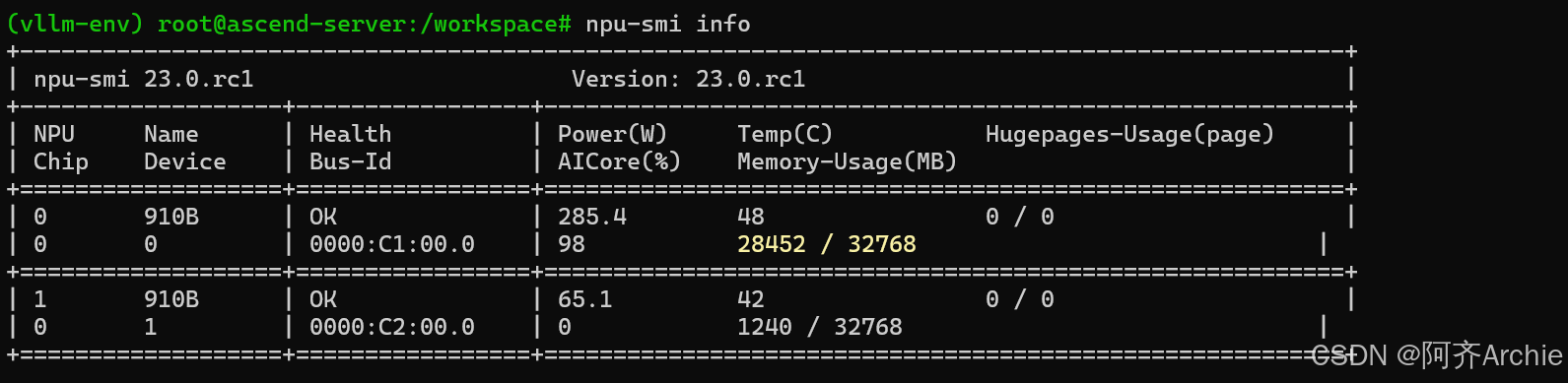
5.3 性能不达标?检查 CPU 瓶颈
在昇腾服务器上,有时 NPU 没跑满,CPU 却先爆了。
- 现象:top 命令显示 python 进程 CPU 占用率 100%,但 NPU 利用率只有 30%。
- 原因:Python 的 GIL 锁或 Tokenizer 处理过慢。
- 解决:
- 尝试开启 --use-v2-block-manager(实验性功能)。
- 检查是否开启了过多的后处理逻辑(如复杂的 Logits Processor)。
6. 总结与配置清单
我认为性能调优没有捷径可走,更多是一个不断迭代的过程。我会先通过基准测试量化系统现状,再根据实际业务需求调整参数,同时充分发挥硬件特性,这样才能最大化地挖掘 vLLM-Ascend 的性能潜力。
最后,送给大家一份通用推荐配置清单(以 Llama2-13B 为例):
|
Bash # 环境变量 export TASK_QUEUE_ENABLE=1 # 开启任务队列 export VLLM_LOGGING_LEVEL=INFO # 生产环境日志级别 # 启动命令 python3 -m vllm.entrypoints.api_server \ --model /data/llama2-13b \ --block-size 16 \ # 对齐昇腾硬件 --max-model-len 4096 \ # 限制上下文以换取并发 --max-num-seqs 128 \ # 平衡延迟与吞吐 --gpu-memory-utilization 0.9 \ --tensor-parallel-size 1 # 单卡部署 |

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)