登录社区云,与社区用户共同成长
邀请您加入社区
模型并行训练调度(支持 PP、TP、DP 并行组合);训练作业统一启动与监控;性能 profile 采集与分析;cluster 模式下的多节点同步日志聚合。在性能分析环节中,它通过profiling模块自动记录各算子的运行耗时、通信时长、内存占用与下发延迟。CANN 8 的性能表现变化,并非简单的“好”或“坏”, 而是一种系统在重构后,寻找新平衡点的过程。升级带来的不确定性,正是我们理解系统、掌握
随着昇腾AI计算平台的持续演进,CANN作为昇腾芯片的核心软件栈,它的版本迭代对模型训练性能提升非常大。本次测评主要是分析从CANN 7.0.1.3升级到CANN 8.0 RC2过程中常见的问题及性能差异,为大家提供实用的升级指导和性能优化建议。
CANN 开源仓核心模块深度解析:仓库结构与实战参与指南
前端采用Ascend MindIE推理引擎,其具备高性能(降低时延1倍+、提升吞吐10倍+)、高易用(天级上线模型服务)、高可靠(容灾备份与故障恢复)及开放兼容(支持客户引擎定制)特性,适配Wan2.1多模态模型的生成推理需求。该案例以昇腾910B NPU×8卡为硬件底座,构建“前端推理引擎-中间层加速-硬件算力”的全栈架构,通过MindIE推理引擎、CANN 8.2.RC1中间层及AOL算子库的
从异构编程到 GEMM 算子调优,核心逻辑始终围绕 “让软件行为贴合硬件特性” 展开。具体来看,异构编程的核心在于明确 Host 与 Device 的分工边界,而 GEMM 作为核心算子,从按 Cube 单元尺寸分块以适配硬件计算粒度,到通过块布局优化提升内存访问效率,再到用双缓冲实现计算与数据搬运的并行、用 Swizzling 平衡内存带宽压力,每一步优化都是对硬件特性的深度适配。但实践也表明,
摘要:本文详细介绍了华为昇腾AI处理器原生算子开发语言AscendC的环境搭建全流程。首先分析了硬件兼容性要求,包括Atlas训练/推理系列芯片和操作系统版本;其次讲解了系统依赖安装、Python环境配置和CANNToolkit部署方法;然后重点阐述了环境变量配置技巧;最后通过一个简单的Add算子示例,展示了工程目录结构、核心代码实现和CMake构建方法,并提供了编译运行及调试技巧。文档覆盖910
由于 NPU 的计算通常是按 Block 进行的(比如 128、256),当数据总量 n_elements 不是 Block Size 的整数倍时,如果不加 mask,就会导致内存越界访问,程序直接 Crash。Ascend C 确实强大,它赋予了我们对硬件的极致控制权,但不可否认,它的上手门槛相对较高,需要开发者对 Tiling(切分)、流水线同步、内存管理有非常深刻的理解。但我相信,随着社区的
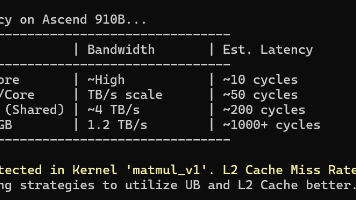
摘要:本文针对昇腾NPU算子开发中的性能瓶颈问题,重点分析了内存访问优化的关键策略。文章指出80%-90%的性能问题源于内存访问效率,并提出以下优化方法:1)确保连续访存避免带宽浪费;2)采用Block Swizzle技术提升L2缓存命中率;3)遵循128-bit内存对齐原则;4)合理管理UB空间和流水线调度。同时强调使用npu-smi和msprof等工具进行性能分析,通过Autotuner自动寻
摘要:《Triton-Ascend算子开发基础与实战指南》介绍了基于昇腾NPU的高效算子开发方法。传统昇腾算子开发需手写ASCENDC/汇编,而Triton-Ascend结合Python编程便捷性与昇腾硬件特性(如AICore、UB缓存、Cube单元),提供更优的开发体验。文章详细解析了昇腾特化的SPMD模型、核心概念差异,并通过向量加法等实战案例,重点阐述了UB分配、Cube单元适配、内存调度等
本文详细解析了Triton-Ascend开源项目,该项目实现了OpenAI Triton编译器在华为昇腾NPU的后端支持。文章从项目架构、核心功能模块(包括昇腾适配、补丁管理、第三方依赖等)展开说明,并提供了完整的开发环境搭建指南,涵盖硬件要求、CANN SDK安装和基础配置验证。通过向量加法示例演示算子开发流程,并深入探讨了针对昇腾910B的矩阵乘法性能优化策略,包括Autotune配置和性能分
问题定位:通过 Profiling 工具(如昇腾 Profiler)或用户反馈,明确性能瓶颈(如内存冲突、调度低效)或功能缺口(如方言不支持)。方案设计:结合 MLIR 的模块化特性,选择优化方式(如自定义 pass、方言扩展、算子增强),确保方案适配昇腾硬件特性。实现验证:基于 C++ 实现优化逻辑,通过 MLIR 的测试框架编写用例,验证正确性与性能提升。落地集成:将优化代码提交到 Ascen
基于 AscendNPU IR 的 HIVM 指令级调度自定义优化实战