
从 MiniMind 推理实战出发:使用 msprof 定位 Ascend NPU 性能瓶颈
从 MiniMind 推理实战出发:使用 msprof 定位 Ascend NPU 性能瓶颈
目录
- 前言
- 核心结论
- 测试环境与复现条件
- msprof 简介
- Profiling 结果目录结构
- 指标口径说明
- 测试数据附件
- 1.
msprof_*.json— Timeline 报告 - 2.
op_summary_*.csv— Device 算子耗时 - 3.
op_statistic_*.csv— Device 算子按类型聚合 - 4.
task_time_*.csv— Task 级时间线 - 5.
api_statistic_*.csv— Host ACL API 调用统计 - 6. 优化验证计划
- 7. 全文总结
前言
MiniMind 是一个 GitHub 开源项目,它主要以轻量级方式实现大语言模型的训练和推理。
项目地址:https://github.com/jingyaogong/minimind
在将 MiniMind 部署到 Ascend NPU 的过程中,我们希望了解:
- 当前模型推理性能是否达到预期
- NPU 算力是否被充分利用
- 是否存在非必要的数据搬运或 CPU 参与计算
- Transformer 推理的主要瓶颈在哪里
因此,我们使用 CANN 自带的 Profiling 工具 msprof 对推理过程进行了分析。
本文结合真实案例,介绍数据采集、Profiling 结果解析及性能优化方向。
核心结论
本次 MiniMind 在 Ascend 910B4 上的推理瓶颈主要集中在以下几个方面:
- Device 侧算子高度串行:主计算几乎集中在单一 stream 上,stream 利用率偏低,stream gap 占比较高。
- Decode shape 较小:batch=1、query length=1 的 decode 场景使 MatMul 和 FlashAttention 的并行度没有充分发挥。
- 部分算子走 AI_CPU 路径:
ScatterElements、MaskedFill、Cumsum等算子在部分场景下落到 AI_CPU,单次耗时明显高于 AI Core / AI Vector Core 路径。 - 高频小算子数量多:
Mul、Cast、Add、ReduceMean、Pows、Rsqrt等算子单次耗时不高,但调用频次很高,累积后形成明显开销。 - Host 侧调度与首次调用长尾明显:
node.launch、aclrtLaunchKernelWithHostArgs、tiling、workspace 查询和首次调用初始化共同增加了 host 侧开销。
因此,后续优化优先级建议为:
| 优先级 | 优化方向 | 目标 |
|---|---|---|
| P0 | 消除关键 AI_CPU 算子、减少单 stream 串行等待 | 降低最明显的 device 侧瓶颈 |
| P1 | 融合高频小算子、减少 launch 次数 | 降低 host 调度和小算子累计开销 |
| P2 | 引入 batching / continuous batching | 提高 MatMul 与 FlashAttention 的硬件利用率 |
| P3 | 增加 warm-up、缓存 tiling / workspace、优化采样路径 | 降低首次调用长尾和 runtime 辅助开销 |
测试环境与复现条件
为了便于复现和横向对比,建议在后续实验中固定并记录以下环境信息。本次报告中已明确的配置如下,未确认项可按实际环境继续补充。
| 项目 | 配置 |
|---|---|
| 硬件 | Ascend 910B4 单卡 |
| Profiling 工具 | msprof |
| CANN 版本 | CANN 9.1(文中基于该版本说明 msprof report 已移除) |
| Python 版本 | 3.10 |
| PyTorch 版本 | 2.7.1 |
| torch-npu 版本 | 2.7.1 |
| MiniMind 项目 | jingyaogong/minimind |
| MiniMind 模型 | minimind-3 |
| 推理脚本 | eval_llm.py |
| 推理精度 | 待补充;本次 MatMul 记录中输入 dtype 为 FLOAT16;FLOAT16 |
| batch size | 主要为 batch=1,存在少量 batch=22/28/31 等片段 |
| decode query length | 主要为 1 |
msprof 简介
msprof 是 Ascend CANN 提供的 Profiling 工具,可采集:
- AscendCL API
- Runtime
- AI Core / AI CPU
- 通信
- Timeline
采集命令:
msprof --output=./msprof_inference python eval_llm.py --load_from ./minimind-3
采集完成后,目录 ./msprof_inference 下会生成 PROF_xxx 目录。
Profiling 结果目录结构
PROF_xxx
├── device_0
├── host
├── msprof_xxx.db
├── mindstudio_profiler_output
mindstudio_profiler_output/ 由 msprof 在 analyze 阶段生成,所有文件均派生自同一份 msprof_*.db,但聚合维度不同。
| 文件 | 视角 | 用途 |
|---|---|---|
msprof_*.json |
完整时间线事件流 | Chrome chrome://tracing 或 Perfetto UI 可视化 |
op_summary_*.csv |
Device 算子逐条 + 输入 shape | 定位慢算子、找瓶颈 |
op_statistic_*.csv |
按 OP Type 聚合 | Device 算子总览(高层分布) |
task_time_*.csv |
Task 级时间戳序列 | 分析 stream 利用率、kernel 调度间隔 |
api_statistic_*.csv |
Host ACL API 调用统计 | 定位 host 端 launch / runtime 开销 |
指标口径说明
本文中的时间指标主要分为三类,阅读时需要区分它们的统计口径:
| 指标类别 | 主要来源 | 含义 | 注意点 |
|---|---|---|---|
| Device 算子执行时间 | op_summary / op_statistic / task_time |
算子真正落到 NPU device 上执行的时间 | 反映 NPU 执行开销,不等同于完整端到端耗时 |
| Stream 等待时间 | Task Wait Time / stream gap |
算子排队、同步、host 调度或上游依赖造成的等待 | wait 高不一定说明单个算子慢,可能是调度或依赖链问题 |
| Host API 调用时间 | api_statistic |
Python / ACL / CANN 侧接口调用、tiling、workspace 查询、launch 等开销 | 属于 host 侧时间,不应直接与 device 执行时间简单相加后当作单个算子耗时 |
另外,本文中不同文件的聚合范围也不同:
op_summary_slice_0:只统计 slice_0,且该切片达到 1,000,000 行上限。op_summary_slice_1:补充 slice_1,对照 slice_0 的分布是否稳定。op_statistic:按 OP Type / Core Type 聚合,通常是跨切片合计视角。task_time:从 task 时间戳角度观察 stream span、gap 和利用率。api_statistic:从 host API 调用角度观察 launch、tiling、workspace 和数据搬运开销。
因此,文中出现的 3.47 s、4.96 s、39.72 s、host API 总耗时等数字并不矛盾,它们分别对应不同的数据文件和统计口径。
测试数据附件
数据源:
msprof_inference/PROF_000001_20260604083524441_00003419EPQDRQDI/mindstudio_profiler_output/
采集时间:2026-06-04 08:35–08:46
采样规模:slice_0 共 1,000,000 个 device 算子实例(仅本切片)
设备:Ascend 910B4 单卡,host = acl API
关联文件:
op_summary_slice_0_20260604084522.csv(312 MB,100 万行,本报告主要数据源)op_summary_slice_1_20260604084522.csv(133 MB)task_time_slice_0_20260604084522.csv(133 MB,按 kernel_type 汇总)task_time_slice_1_20260604084522.csv(64 MB)api_statistic_20260604084522.csv(host 侧 ACL API 调用统计)op_statistic_20260604084522.csv(按 Op Type 汇总)
本次测试产生的性能剖析记录及统计汇总数据已打包归档,可通过以下百度网盘链接获取(长期有效):
-
性能剖析原始数据
文件:msprof_20260604084027.json
说明:包含测试期间采集的完整性能分析轨迹(JSON 格式),可用于深度定位耗时热点及资源调用链。
链接:https://pan.baidu.com/s/1rMEy860xFHnagHRVojjWmw
提取码:uf6a -
测试指标汇总表
文件:profiler_csvs.zip
说明:压缩包内包含所有测试用例的统计表格(CSV 格式),覆盖各轮次的吞吐量、延迟、NPU/内存占用等关键指标,便于二次分析或图表绘制。
链接:https://pan.baidu.com/s/1LEQ7FArFRhCx5JOk1yaG1Q
提取码:t9nu
若链接失效,请联系测试负责人获取本地备份。
1. msprof_*.json — Timeline 报告
msprof_*.json 包含四层:
- CPU Layer:应用层算子执行耗时(msproftx/PyTorch)
- CANN Layer:AscendCL、Runtime、节点(算子)耗时
- Ascend Hardware Layer:NPU task 执行数据、通信、迭代追踪
- Overlap Analysis Layer:多设备或集群场景下计算与通信重叠情况,可评估 pipeline 利用率
为什么不能 msprof report? CANN 9.1 已移除 msprof report 子命令(旧版本 8.x 有)。当前版本若执行会报 Failed to find profiling data,因为它把 report 当成应用名了。
查看方式(按推荐顺序):
| 方式 | 命令 / 操作 | 适用 |
|---|---|---|
| Perfetto 网页版 | 把 msprof_*.json 拖到 https://ui.perfetto.dev |
时间线细节 |
| Mind Studio GUI | 导入 PROF_xxx 目录 |
完整 IDE 体验 |
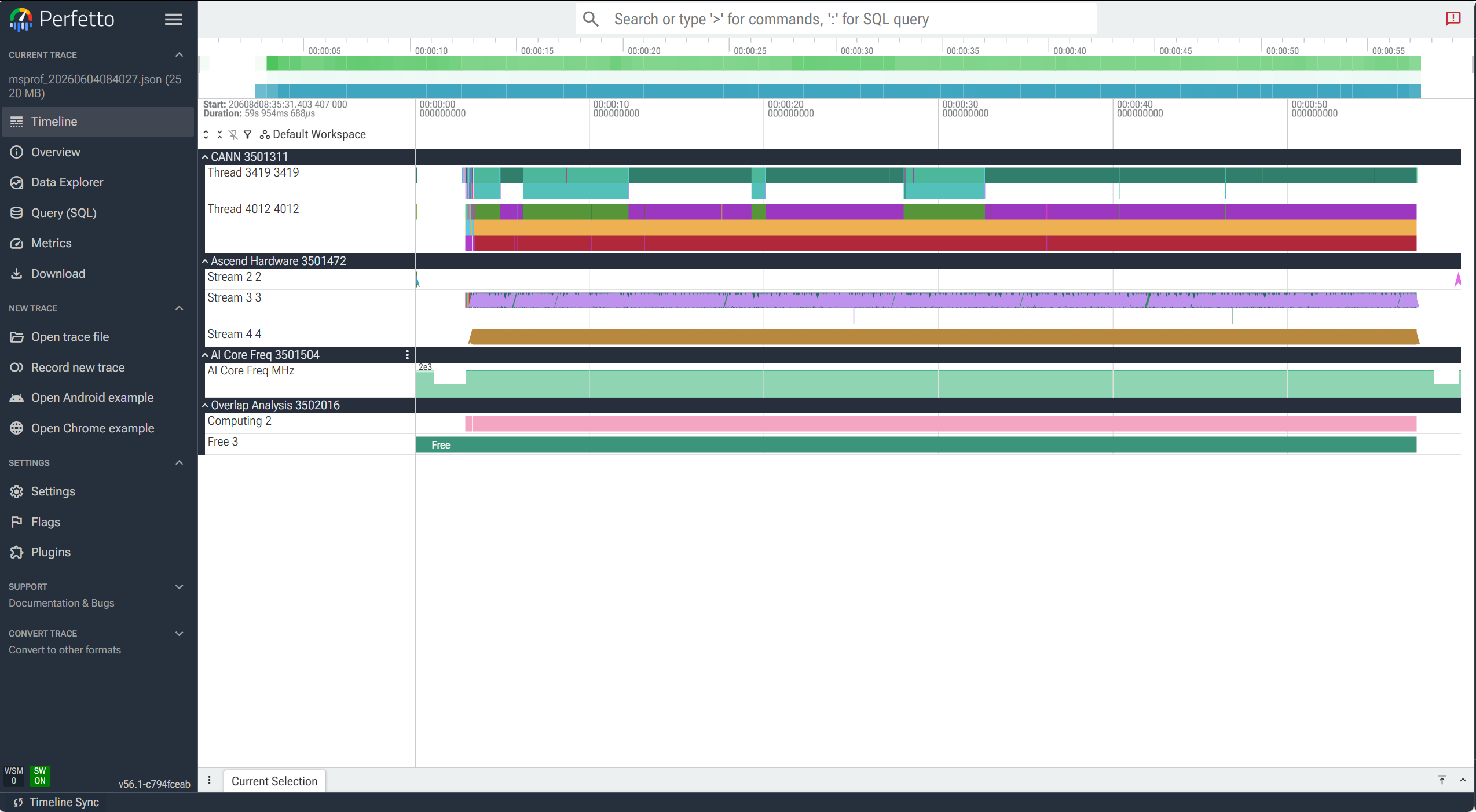
实际建议:报告里引用 CSV 的统计表格即可,时间线截图只在需要展示算子依赖关系时才需要。
2. op_summary_*.csv — Device 算子耗时
数据文件:
op_summary_slice_0_20260604084522.csv(1,000,000 行,已达 profiler 单切片上限)
对照切片:op_summary_slice_1_20260604084522.csv(数据未截断)
设备:Ascend 910B4
2.1 文件格式与字段说明
| 列 | 含义 | 用途 |
|---|---|---|
Op Name |
算子完整调用名(aclnn{接口}_{实现路径}_{算子类型}) |
唯一标识 |
OP Type |
算子大类(MatMulV2/Mul/…) |
横向归类 |
OP State |
图状态(dynamic/static) |
判断是否走静态图 |
Task Type |
物理执行单元(AI_CORE/AI_VECTOR_CORE/AI_CPU/MIX_AIC/MIX_AIV/DSA_SQE) |
决定优化方向 |
Task Start Time(us) |
算子在 stream 上的入队时刻 | 排序/分析时序 |
Task Duration(us) |
算子在 device 上的真实执行时长 | 核心指标 1 |
Task Wait Time(us) |
算子在 stream 队列中等待上游的时间 | 核心指标 2,越短越好 |
Block Num |
占用的 AI Core 块数 | 评估硬件占用 |
Mix Block Num |
混合算子占用的 AI Core 块数 | 仅 FA 类算子有意义 |
Input Shapes / Input Data Types / Input Formats |
输入张量规格 | 定位异常 shape |
Output Shapes / Output Data Types / Output Formats |
输出张量规格 | 定位异常 shape |
Context ID |
上下文编号 | 多卡/多 stream 区分 |
aicore_time(us) |
AI Core 整体耗时(覆盖 scalar/mte/mac/fixpipe 的合计) | 流水分析 |
aic_mac_time(us) / aic_mac_ratio |
矩阵乘阶段耗时及占 aicore 比例 | 看算力利用率 |
aic_scalar_time(us) / aic_scalar_ratio |
标量指令耗时及占比 | 看是否 scalar-bound |
aic_mte1_time(us) / aic_mte1_ratio |
L1 ↔ L0/A1 搬运耗时及占比 | 看是否带宽-bound |
aic_mte2_time(us) / aic_mte2_ratio |
L2 ↔ L1 搬运耗时及占比 | 看是否带宽-bound |
aic_fixpipe_time(us) / aic_fixpipe_ratio |
累加/写回阶段耗时及占比 | 看是否输出-bound |
aiv_time(us) / aiv_total_cycles |
Vector Core 整体耗时与时钟周期 | vector 流水分析 |
aiv_vec_time(us) / aiv_vec_ratio |
Vector 计算耗时及占比 | |
aiv_scalar_time(us) / aiv_scalar_ratio |
Vector 标量耗时及占比 | |
aiv_mte2_time(us) / aiv_mte2_ratio |
Vector L2 ↔ L1 搬运耗时及占比 | |
aiv_mte3_time(us) / aiv_mte3_ratio |
Vector L1 ↔ UB 搬运耗时及占比 | |
cube_utilization(%) |
AI Core 矩阵单元利用率 | 核心指标 3 |
2.2 总体统计
| 指标 | 数值 |
|---|---|
| 算子实例总数 | 1,000,000 |
Task Duration(us) 累计 |
3,473,625 us ≈ 3.47 s |
Task Wait Time(us) 累计 |
34,878,692 us ≈ 34.88 s |
| Wait / Duration 比率 | 1004.10 % |
| 最大单算子时长 | 365.90 us(aclnnInplaceOne_OnesLikeAiCPU_OnesLike) |
| 涉及 Stream 数 | 1(stream_id=3,独占 100 % 算子) |
| 算子所属 OP State | 100 % dynamic |
解读:
- 设备侧总耗时 3.47 s,但仅完成了一次推理切片(100 万次算子下发)。其中真正在 chip 上执行的只有 3.47 s,等待 stream 队列的时间高达 34.88 s,是执行的 10 倍。
- 全部算子集中在
stream_id=3单 stream 上,无并行调度能力,是当前 device 侧最大瓶颈。 - 所有算子 state 为
dynamic,说明 shape 是在 host 端动态下发,没有走静态图优化路径。
2.3 执行单元分布
| Task Type | 调用次数 | 总耗时 (ms) | 占比 | 平均 (us) |
|---|---|---|---|---|
| AI_VECTOR_CORE | 812,325 | 1,740.12 | 50.10 % | 2.14 |
| AI_CORE | 99,958 | 692.68 | 19.94 % | 6.93 |
| AI_CPU ⚠️ | 5,279 | 443.81 | 12.78 % | 84.07 |
| MIX_AIC | 14,029 | 352.72 | 10.15 % | 25.14 |
| MIX_AIV | 66,656 | 241.12 | 6.94 % | 3.62 |
| DSA_SQE | 1,753 | 3.18 | 0.09 % | 1.81 |
解读:
- AI_VECTOR_CORE 占 50.10 %:element-wise 算子(Mul/Cast/Add/ReduceMean/…)占了一半工作量,是典型的"小算子密集"模型。
- AI_CPU 占 12.78 %,但平均 84 us/次,是 AI_CORE(6.93 us/次)的 12 倍。AI_CPU 任务数量虽少(仅 5,279 次),但单次开销高,是隐形的性能杀手。
- AI_CORE 仅 19.94 %:理论上 GEMM 类算子应占主导,但本 workload 因 batch=1、seq=1 的 decode 形状,矩阵太小,AI Core 没有被充分喂饱。
2.4 Top 高耗时算子
| 排名 | Op Name | 次数 | 总耗时 (ms) | 平均 dur (us) | 平均 wait (us) | wait/dur | max_dur (us) | max_wait (us) |
|---|---|---|---|---|---|---|---|---|
| 1 | aclnnMatmul_MatMulCommon_MatMulV2 |
99,958 | 692.68 | 6.93 | 70.85 | 10.2× | 21.60 | 60,870.80 |
| 2 | aclnnMul_MulAiCore_Mul |
189,393 | 402.04 | 2.12 | 16.57 | 7.8× | 16.70 | 2,479.49 |
| 3 | aclnnFlashAttentionScore_FlashAttentionScore_FlashAttentionScore |
14,029 | 352.72 | 25.14 | 86.52 | 3.4× | 39.40 | 96,602.88 |
| 4 | aclnnScatter_ScatterElements_ScatterElements |
1,753 | 318.75 | 181.83 | 182.12 | 1.0× | 336.84 | 1,178.81 |
| 5 | aclnnCat_ConcatD_ConcatD |
61,280 | 206.70 | 3.37 | 20.06 | 6.0× | 20.16 | 1,217.39 |
| 6 | aclnnMean_ReduceMeanAiCore_ReduceMean |
57,872 | 194.04 | 3.35 | 29.35 | 8.8× | 13.56 | 28,544.77 |
| 7 | aclnnInplaceCopy_BroadcastToAiCore_BroadcastTo |
28,058 | 160.08 | 5.71 | 89.42 | 15.7× | 10.64 | 2,610.88 |
| 8 | aclnnCast_CastAiCore_Cast |
122,759 | 155.95 | 1.27 | 40.30 | 31.7× ⚠️ | 5.86 | 3,359.75 |
| 9 | aclnnPowTensorScalar_PowsAiCore_Pows |
57,872 | 125.29 | 2.16 | 22.73 | 10.5× | 15.50 | 1,266.59 |
| 10 | aclnnAdds_AddAiCore_Add |
59,624 | 87.75 | 1.47 | 29.26 | 19.9× | 3.56 | 4,437.54 |
TOP 10 总耗时 2,696 ms,占 device 总耗时 77.6 %。
2.5 完整排名
| OP Type | 次数 | 总耗时 (ms) | 占比 |
|---|---|---|---|
| MatMulV2 | 99,958 | 692.68 | 19.94 % |
| Mul | 194,655 | 409.99 | 11.80 % |
| FlashAttentionScore | 14,029 | 352.72 | 10.15 % |
| ScatterElements | 1,753 | 318.75 | 9.18 % |
| ConcatD | 61,280 | 206.70 | 5.95 % |
| ReduceMean | 57,872 | 194.04 | 5.59 % |
| Cast | 133,278 | 175.26 | 5.05 % |
| Add | 119,246 | 170.85 | 4.92 % |
| BroadcastTo | 28,058 | 160.08 | 4.61 % |
| Pows | 57,872 | 125.29 | 3.61 % |
| Slice | 56,116 | 114.19 | 3.29 % |
| Cumsum | 3,513 | 82.46 | 2.37 % |
| MaskedFill | 5,260 | 75.66 | 2.18 % |
| Rsqrt | 57,871 | 72.88 | 2.10 % |
| Neg | 28,058 | 35.98 | 1.04 % |
| Transpose | 3,892 | 35.67 | 1.03 % |
| Sort | 1,753 | 22.02 | 0.63 % |
| Swish | 14,029 | 22.00 | 0.63 % |
| GatherV2 | 1,754 | 20.67 | 0.60 % |
| MemSet | 1,753 | 20.25 | 0.58 % |
Top 6 累计 53.61 %,Top 14 累计 75.0 %。
2.6 异常 Shape 钻取
2.6.1 MatMul Shape 分析
| Input → Output | 次数 | 总耗时 (ms) | 平均 dur (us) | 平均 wait (us) | wait/dur | Block Num |
|---|---|---|---|---|---|---|
[1,768] × [2432,768] → [1,2432] |
27,962 | 250.29 | 8.95 | 54.49 | 6.09× | 12 |
[1,2432] × [768,2432] → [1,768] |
13,981 | 164.36 | 11.76 | 39.87 | 3.39× | 16 |
[1,768] × [768,768] → [1,768] |
27,963 | 139.36 | 4.98 | 97.86 | 19.64× ⚠️ | 16 |
[1,768] × [384,768] → [1,384] |
27,963 | 104.56 | 3.74 | 68.62 | 18.35× ⚠️ | 19 |
[1,768] × [6400,768] → [1,6400] |
1,753 | 31.78 | 18.13 | 150.19 | 8.28× | 13 |
[28,768] × [2432,768] → [28,2432] |
16 | 0.16 | 9.84 | 47.87 | 4.86× | 12 |
[22,768] × [2432,768] → [22,2432] |
16 | 0.15 | 9.66 | 32.53 | 3.37× | 12 |
[31,768] × [2432,768] → [31,2432] |
16 | 0.15 | 9.58 | 46.91 | 4.90× | 12 |
解读:
- 所有高频 MatMul 都是 M=1, K=768 的单 token decode 形状,对应 minimind 的
hidden_size=768、ffn=2432、vocab=6400、num_heads=8, head_dim=96。 [1,768] × [768,768]这个 self-attention QKV projection 的 wait/dur 高达 19.64×,说明它排队严重,本身只需 5 us,但平均要等 98 us。- 偶发的 batch=28/22/31/30 的 MatMul 出现 16 次(出现在 DPO 的 chosen+rejected 拼接时),单算子耗时反而比 batch=1 还短(同样 ~10 us),说明 batch 增大时 NPU 的"算力密度"优势显现。
2.6.2 FlashAttentionScore Shape 分析
| Input → Output | 次数 | 总耗时 (ms) | 平均 dur (us) | 平均 wait (us) |
|---|---|---|---|---|
[1,8,1,96];[1,8,67,96];[1,8,67,96];... → [1,8,1,8];[1,8,1,8];;[1,8,1,96] |
48 | 1.31 | 27.30 | 74.74 |
[1,8,1,96];[1,8,66,96];[1,8,66,96];... → [1,8,1,8];[1,8,1,8];;[1,8,1,96] |
48 | 1.31 | 27.25 | 75.52 |
[1,8,1,96];[1,8,65,96];[1,8,65,96];... → [1,8,1,8];[1,8,1,8];;[1,8,1,96] |
48 | 1.31 | 27.24 | 75.45 |
[1,8,1,96];[1,8,68,96];[1,8,68,96];... → [1,8,1,8];[1,8,1,8];;[1,8,1,96] |
48 | 1.30 | 27.14 | 74.31 |
[1,8,1,96];[1,8,64,96];[1,8,64,96];... → [1,8,1,8];[1,8,1,8];;[1,8,1,96] |
48 | 1.29 | 26.78 | 75.04 |
解读:
- query 长度始终为 1(典型的 KV-cache decode 步),key 长度在 64~68 范围内小范围波动(KV cache 在增长)。
- 单次 FA 平均 27 us,但等待 75 us(wait/dur ≈ 2.8×),仍然有排队问题。
- 此场景 query 太短(仅 1 个 token),FlashAttention 算子的并行度被严重压缩。
2.6.3 ScatterElements 异常分析
| Input → Output | 次数 | 总耗时 (ms) | 平均 dur (us) | 平均 wait (us) |
|---|---|---|---|---|
[1,6400];[1,6400];[1,6400] → [1,6400] |
1,753 | 318.75 | 181.83 | 182.12 |
解读:
- 1,753 次 Scatter 全部走 AI_CPU(task_type=AI_CPU)。
- 单次 Scatter 182 us,与一次 MatMul(~7 us)相比慢 23 倍。
vocab_size=6400与 minimind 模型对齐 —— 这是 DPO/RLHF 把chosen_token_ids/rejected_token_idsscatter 到 logits 时的开销,每生成一个偏好对就触发一次。
2.7 MatMul 流水阶段与 Cube 利用率
来源:op_summary_slice_0_20260604084522.csv 中 99,958 次 MatMul 算子。
| 流水阶段 | 平均耗时 (us) | 占 aicore 比例 |
|---|---|---|
aic_scalar_time |
3.259 | 59.7 % ⚠️ |
aic_mte2_time(L2↔L1 搬运) |
3.110 | 52.1 % |
aic_mte1_time(L1↔A1/L0 搬运) |
0.920 | 15.8 % |
aic_mac_time(矩阵乘) |
0.396 | 6.4 % ⚠️ |
aic_fixpipe_time(累加/写回) |
0.153 | 3.7 % |
aicore_time(合计) |
5.401 | 100 % |
cube_utilization(%) 分布(99,958 次 MatMul):
| 利用率区间 | 次数 | 占比 |
|---|---|---|
| 20–30 % | 6 | 0.01 % |
| 30–40 % | 1,979 | 1.98 % |
| 40–50 % | 27,907 | 27.92 % |
| 50–60 % | 26,528 | 26.54 % |
| 60–70 % | 16,087 | 16.09 % |
| 70–80 % | 18,711 | 18.72 % |
| 80–90 % | 8,740 | 8.74 % |
平均 59.54 %,最大 85.95 %,最小 29.05 %。无任何一次 MatMul 达到 90 % 以上。
dtype 分布:99,958 次全部为 FLOAT16;FLOAT16。
解读:
- aic_mac_time 仅 0.396 us / 次(占 aicore 6.4 %):真正在算矩阵的微秒数极少,AI Core 矩阵单元大量空闲。
- aic_scalar_time 占 59.7 %:matmul tiling 的初始化、index 计算、地址生成等标量指令消耗了大部分时间。这是典型的小矩阵现象(M=1,标量控制流相对矩阵运算占比偏高)。
- cube_utilization 平均 59.54 %:即使把矩阵单元跑满算力也只有 ~60 %,说明硬件占用率低的主因是 shape 太小(M=1 喂不满 AI Core)。
- dtype 一致为 FLOAT16,说明 cast 主要是发生在非 matmul 路径上(Cast 算子单独占了 5.05 %)。
2.8 关键异常 Shape 总结
| 异常点 | 现象 | 数值 |
|---|---|---|
[1,768] × [768,768] MatMul |
wait/dur 异常 | 19.64× |
[1,768] × [384,768] MatMul |
wait/dur 异常 | 18.35× |
aclnnAdds_AddAiCore_Add |
wait/dur 异常 | 19.9× |
aclnnInplaceCopy_BroadcastToAiCore_BroadcastTo |
wait/dur 异常 | 15.7× |
aclnnCast_CastAiCore_Cast |
wait/dur 最高 | 31.7× |
aclnnScatter_ScatterElements_ScatterElements |
单算子 dur 最高 | 181.83 us / 次,AI_CPU 路径 |
aclnnFlashAttentionScore 单次最大 wait |
一次等待 96 ms | max_wait=96,602.88 us |
2.9 分析与优化建议
🔴 P0:解决单 Stream 串行
stream_id=3 独占 100 % 算子,wait/dur 高达 1004 %,是头号瓶颈。
- 把
Mul、Add、Cast这类 element-wise 算子切到独立 stream:s_aux = torch.npu.Stream() with torch.npu.stream(s_aux): bias = self.bias_proj(x) # 主 stream 不需要等 bias 就绪 - 从当前 Top 算子占比和 stream gap 估算,若能有效减少串行等待和高频小算子 launch,device 侧耗时存在明显下降空间;具体收益需要通过 A/B profiling 验证。
🔴 P0:ScatterElements 走 AI_CORE 路径
1,753 次 AI_CPU scatter,单次 182 us,浪费 318 ms。
- 业务侧排查 DPO / preference 数据构造代码,改写为:
# 替换 torch.npu.scatter_(...) 或 tensor.scatter_(...) # 改为 torch.npu.cat([chosen, rejected], dim=0) 走 AI_CORE - 或在 host 侧设
torch.npu.set_per_process_memory_fraction(0.95)+ACLNN_CACHE_MODE=1触发 AI_CORE scatter。
🟠 P1:RMSNorm 算子融合
每 token 的 RMSNorm 由 ReduceMean → Pows → Rsqrt → Mul 4 个算子串联,单次 ~9 us。
- 替换为
aclnnRmsNorm单算子,理论 2 us 内完成。 - 每层 transformer 节省 ~7 us × N 层 × M tokens。
🟠 P1:dtype 统一,去掉中间 Cast
133,278 次 Cast,wait/dur=31.7×,是 wait/dur 最高的算子。
- 把 embedding、loss、sampling 全部统一到 fp16 或 bf16,避免 fp32↔fp16↔int64 之间频繁转换。
- embedding 阶段一旦 cast 到 fp32 就无法回退,要从模型入口处保持 fp16。
🟡 P2:FlashAttention 在当前 decode shape 下收益有限
query 长度恒为 1,FA 的并行优势被压缩,平均 27 us + 等待 75 us。
- decode 阶段临时切回
Q @ K^T → Softmax → @V三件套,等 batch 提升到 8+ 再启用 FA。
🟡 P2:Batch=1 MatMul 硬件利用率低
所有高频 matmul 的 M=1,导致 cube_utilization 平均仅 59.54 %,最高 85.95 %。
- 推理侧开启 continuous batching,把多条请求合并到同一 batch(M=8/16)执行。
- 当前已经偶发的
M=28/22/31的 matmul 单耗时 ~10 us 反而比 M=1 的 ~5 us 更"划算"。
🟢 P3:算子融合(element-wise)
Cast → Mul → Add、Mul → Add、ReduceMean → Pows → Rsqrt → Mul 是高频 pipeline。
- 使用
torch.npu.graphs(等价 NPUGraph)做 capture-replay,或者调用aclnn的融合算子(如aclnnAddcmul、aclnnRmsNorm等)。
3. op_statistic_*.csv — Device 算子按类型聚合
数据文件:
op_statistic_20260604084522.csv(46 行,含 Header)
设备:Ascend 910B4
作用:本切片是op_summary的高层聚合视图,所有Ratio(%)字段均由 profiler 直接计算。
3.1 文件格式与字段说明
每行 = 一个 (OP Type, Core Type) 组合:
| 列 | 含义 |
|---|---|
Device_id |
设备编号(单卡:0) |
OP Type |
算子大类 |
Core Type |
物理执行单元:AI_CORE / AI_VECTOR_CORE / AI_CPU / MIX_AIC / MIX_AIV / DSA_SQE |
Count |
调用次数 |
Total Time(us) |
该 (OP, Core) 组合累计耗时 |
Min Time(us) / Avg Time(us) / Max Time(us) |
单次耗时统计 |
Ratio(%) |
占比(直接由 profiler 计算,等于本组合 Total Time / 全局 Total Time) |
3.2 总体统计
| 指标 | 数值 |
|---|---|
| (OP Type, Core Type) 组合数 | 46 |
| 全部 Ratio 之和 | 99.997 %(含浮点误差) |
| 全局总耗时 | 4,955,239 us ≈ 4.96 s(已合并 slice_0 + slice_1) |
op_statistic是 跨切片合计,所以总耗时(4.96 s)比op_summary_slice_0单独的 3.47 s 更高。
3.3 执行单元分布
| Core Type | 调用次数 | 总耗时 (ms) | Ratio |
|---|---|---|---|
| AI_VECTOR_CORE | 1,159,888 | 2,483.37 | 50.116 % |
| AI_CORE | 142,728 | 988.49 | 19.949 % |
| AI_CPU | 7,536 | 631.78 | 12.749 % ⚠️ |
| MIX_AIC | 20,032 | 502.66 | 10.144 % |
| MIX_AIV | 95,176 | 344.25 | 6.947 % |
| DSA_SQE | 2,504 | 4.54 | 0.092 % |
对比 op_summary_slice_0 中的 Task Type 分布(3.47 s 切片):
| Task Type | op_summary_slice_0 ratio | op_statistic ratio | 差异 |
|---|---|---|---|
| AI_VECTOR_CORE | 50.10 % | 50.12 % | +0.02 % |
| AI_CORE | 19.94 % | 19.95 % | +0.01 % |
| AI_CPU | 12.78 % | 12.75 % | −0.03 % |
| MIX_AIC | 10.15 % | 10.14 % | −0.01 % |
| MIX_AIV | 6.94 % | 6.95 % | +0.01 % |
两个数据源的 Core Type 分布几乎一致(slice_1 与 slice_0 同分布),证明采样具有代表性。
3.4 Top 高耗时算子
| Rank | OP Type | Core Type | Ratio | Avg (us) | 单次最大 (us) |
|---|---|---|---|---|---|
| 1 | MatMulV2 | AI_CORE | 19.949 % | 6.925 | 22.10 |
| 2 | Mul | AI_VECTOR_CORE | 11.800 % | 2.103 | 16.70 |
| 3 | FlashAttentionScore | MIX_AIC | 10.144 % | 25.092 | 39.40 |
| 4 | ScatterElements | AI_CPU | 9.168 % | 181.429 | 336.84 |
| 5 | ConcatD | AI_VECTOR_CORE | 5.929 % | 3.357 | 20.16 |
| 6 | ReduceMean | MIX_AIV | 5.590 % | 3.352 | 13.56 |
| 7 | Cast | AI_VECTOR_CORE | 5.049 % | 1.314 | 5.86 |
| 8 | Add | AI_VECTOR_CORE | 4.922 % | 1.432 | 4.16 |
| 9 | BroadcastTo | AI_VECTOR_CORE | 4.611 % | 5.702 | 10.64 |
| 10 | Pows | AI_VECTOR_CORE | 3.605 % | 2.161 | 15.50 |
Top 4 累计 = 51.06 %,Top 10 累计 = 80.77 %。
3.5 完整排名
按 Total Time(us) 降序(46 行全部):
| 排名 | OP Type | Core Type | Count | Total (us) | Min (us) | Avg (us) | Max (us) | Ratio |
|---|---|---|---|---|---|---|---|---|
| 1 | MatMulV2 | AI_CORE | 142,728 | 988,491.74 | 3.26 | 6.925 | 22.10 | 19.949 % |
| 2 | Mul | AI_VECTOR_CORE | 277,944 | 584,722.52 | 1.14 | 2.103 | 16.70 | 11.800 % |
| 3 | FlashAttentionScore | MIX_AIC | 20,032 | 502,662.72 | 20.52 | 25.092 | 39.40 | 10.144 % |
| 4 | ScatterElements | AI_CPU ⚠️ | 2,504 | 454,299.40 | 153.32 | 181.429 | 336.84 | 9.168 % |
| 5 | ConcatD | AI_VECTOR_CORE | 87,512 | 293,778.62 | 1.70 | 3.357 | 20.16 | 5.929 % |
| 6 | ReduceMean | MIX_AIV | 82,632 | 277,009.24 | 2.42 | 3.352 | 13.56 | 5.590 % |
| 7 | Cast | AI_VECTOR_CORE | 190,304 | 250,196.68 | 1.02 | 1.314 | 5.86 | 5.049 % |
| 8 | Add | AI_VECTOR_CORE | 170,272 | 243,880.10 | 1.12 | 1.432 | 4.16 | 4.922 % |
| 9 | BroadcastTo | AI_VECTOR_CORE | 40,064 | 228,473.70 | 3.36 | 5.702 | 10.64 | 4.611 % |
| 10 | Pows | AI_VECTOR_CORE | 82,632 | 178,641.00 | 1.52 | 2.161 | 15.50 | 3.605 % |
| 11 | Slice | AI_VECTOR_CORE | 80,128 | 163,146.74 | 1.42 | 2.036 | 3.94 | 3.292 % |
| 12 | Rsqrt | AI_VECTOR_CORE | 82,632 | 104,086.82 | 1.06 | 1.259 | 1.90 | 2.101 % |
| 13 | MaskedFill | AI_CPU ⚠️ | 2,504 | 88,123.48 | 27.18 | 35.193 | 99.02 | 1.778 % |
| 14 | Cumsum | AI_CPU ⚠️ | 2,512 | 87,861.30 | 24.56 | 34.976 | 83.98 | 1.773 % |
| 15 | Transpose | AI_VECTOR_CORE | 5,520 | 52,038.20 | 6.02 | 9.427 | 19.68 | 1.050 % |
| 16 | Neg | AI_VECTOR_CORE | 40,064 | 51,381.20 | 1.08 | 1.282 | 2.22 | 1.037 % |
| 17 | Sort | MIX_AIV | 2,504 | 31,443.10 | 11.78 | 12.557 | 14.48 | 0.635 % |
| 18 | Swish | AI_VECTOR_CORE | 20,032 | 31,261.68 | 1.32 | 1.560 | 8.28 | 0.631 % |
| 19 | GatherV2 | AI_VECTOR_CORE | 2,504 | 29,501.38 | 6.36 | 11.781 | 15.14 | 0.595 % |
| 20 | Cumsum | AI_VECTOR_CORE | 2,504 | 29,314.70 | 11.10 | 11.707 | 13.20 | 0.592 % |
| 21 | MemSet | AI_VECTOR_CORE | 2,504 | 29,060.70 | 10.98 | 11.605 | 16.78 | 0.586 % |
| 22 | SoftmaxV2 | AI_VECTOR_CORE | 5,008 | 27,298.18 | 4.02 | 5.450 | 7.66 | 0.551 % |
| 23 | Index | AI_VECTOR_CORE | 2,496 | 22,836.32 | 8.60 | 9.149 | 13.30 | 0.461 % |
| 24 | Sub | AI_VECTOR_CORE | 7,520 | 20,761.64 | 2.20 | 2.760 | 4.66 | 0.419 % |
| 25 | MaskedFill | AI_VECTOR_CORE | 5,008 | 19,732.68 | 3.14 | 3.940 | 4.94 | 0.398 % |
| 26 | TopKV2 | MIX_AIV | 2,504 | 19,031.34 | 7.00 | 7.600 | 8.60 | 0.384 % |
| 27 | Fill | AI_VECTOR_CORE | 12,528 | 18,240.34 | 1.20 | 1.455 | 4.36 | 0.368 % |
| 28 | Equal | AI_VECTOR_CORE | 7,520 | 18,133.12 | 1.86 | 2.411 | 4.60 | 0.366 % |
| 29 | RealDiv | AI_VECTOR_CORE | 5,008 | 12,778.38 | 2.24 | 2.551 | 3.16 | 0.258 % |
| 30 | GreaterEqual | AI_VECTOR_CORE | 2,504 | 7,941.58 | 2.80 | 3.171 | 4.98 | 0.160 % |
| 31 | ReduceAll | MIX_AIV | 2,504 | 7,939.50 | 2.50 | 3.170 | 4.56 | 0.160 % |
| 32 | LessEqual | AI_VECTOR_CORE | 2,504 | 7,849.58 | 2.88 | 3.134 | 3.64 | 0.158 % |
| 33 | LogicalOr | AI_VECTOR_CORE | 5,008 | 7,730.56 | 1.36 | 1.543 | 2.52 | 0.156 % |
| 34 | ArgMaxV2 | AI_VECTOR_CORE | 2,504 | 7,459.32 | 2.76 | 2.978 | 3.54 | 0.151 % |
| 35 | Less | AI_VECTOR_CORE | 2,512 | 7,429.60 | 2.76 | 2.957 | 3.90 | 0.150 % |
| 36 | Log | AI_VECTOR_CORE | 2,504 | 6,241.14 | 2.30 | 2.492 | 2.86 | 0.126 % |
| 37 | Abs | AI_VECTOR_CORE | 2,504 | 6,218.52 | 2.34 | 2.483 | 2.82 | 0.125 % |
| 38 | Cos | AI_VECTOR_CORE | 2,504 | 5,791.12 | 2.12 | 2.312 | 3.16 | 0.117 % |
| 39 | Sin | AI_VECTOR_CORE | 2,504 | 5,566.26 | 2.08 | 2.222 | 3.04 | 0.112 % |
| 40 | ReduceMax | MIX_AIV | 2,504 | 4,708.50 | 1.64 | 1.880 | 2.56 | 0.095 % |
| 41 | BitwiseAnd | AI_VECTOR_CORE | 2,504 | 4,660.04 | 1.60 | 1.861 | 2.98 | 0.094 % |
| 42 | DSARandomUniform | DSA_SQE | 2,504 | 4,540.76 | 1.58 | 1.813 | 3.44 | 0.092 % |
| 43 | ReduceAny | MIX_AIV | 2,528 | 4,123.04 | 1.18 | 1.630 | 3.48 | 0.083 % |
| 44 | LogicalNot | AI_VECTOR_CORE | 2,504 | 3,855.28 | 1.38 | 1.539 | 1.94 | 0.078 % |
| 45 | Triu | AI_VECTOR_CORE | 64 | 2,284.40 | 34.02 | 35.693 | 42.26 | 0.046 % |
| 46 | OnesLike | AI_CPU | 16 | 1,500.64 | 28.98 | 93.790 | 365.90 | 0.030 % |
| 47 | OnesLike | AI_VECTOR_CORE | 64 | 1,081.16 | 13.62 | 16.893 | 18.66 | 0.022 % |
注:实际数据为 47 行(不含 Header),上表 Row 编号 1–47。
3.6 Core Type 路由差异
op_statistic 相对于 op_summary 独有的能力——揭示一个 OP Type 会被路由到不同的物理 Core:
| OP Type | 两种实现对比 | Avg (us) | Ratio |
|---|---|---|---|
| MaskedFill | AI_CPU vs AI_VECTOR_CORE | 35.193 vs 3.940 | 1.778 % vs 0.398 % |
| Cumsum | AI_CPU vs AI_VECTOR_CORE | 34.976 vs 11.707 | 1.773 % vs 0.592 % |
| OnesLike | AI_CPU vs AI_VECTOR_CORE | 93.790 vs 16.893 | 0.030 % vs 0.022 % |
3.6.1 MaskedFill 路由对比
| Core Type | Count | Avg (us) | Total (ms) | Ratio |
|---|---|---|---|---|
| AI_CPU ⚠️ | 2,504 | 35.193 | 88.12 | 1.778 % |
| AI_VECTOR_CORE | 5,008 | 3.940 | 19.73 | 0.398 % |
解读:
- AI_CPU 路径的 MaskedFill 单次 35.193 us,是 AI_VECTOR_CORE 路径(3.940 us)的 8.93 倍。
- 但目前 2,504 次 仍走 AI_CPU —— 这是 63 % 的 MaskedFill 调用。
- 强制走 AI_VECTOR_CORE 路径可省约 78.26 ms。
3.6.2 Cumsum 路由对比
| Core Type | Count | Avg (us) | Total (ms) | Ratio |
|---|---|---|---|---|
| AI_CPU ⚠️ | 2,512 | 34.976 | 87.86 | 1.773 % |
| AI_VECTOR_CORE | 2,504 | 11.707 | 29.31 | 0.592 % |
解读:
- AI_CPU 路径的 Cumsum 是 AI_VECTOR_CORE 路径的 2.99 倍。
- 调用次数近乎 1:1,当前 NPU 调度器把约 50 % 的 Cumsum 路由到了慢路径。
3.6.3 OnesLike 路由对比
| Core Type | Count | Avg (us) | Total (ms) | Ratio |
|---|---|---|---|---|
| AI_CPU ⚠️ | 16 | 93.790 | 1.50 | 0.030 % |
| AI_VECTOR_CORE | 64 | 16.893 | 1.08 | 0.022 % |
- 调用次数少(80 次),影响有限,但单次耗时仍明显偏高。
3.7 AI_CPU 算子清单
AI_CPU 路径合计 Ratio = 12.749 %(631.78 ms / 4,955 ms),全部来自以下算子:
| OP Type | Count | Avg (us) | Total (ms) | Ratio |
|---|---|---|---|---|
| ScatterElements | 2,504 | 181.429 | 454.30 | 9.168 % |
| MaskedFill | 2,504 | 35.193 | 88.12 | 1.778 % |
| Cumsum | 2,512 | 34.976 | 87.86 | 1.773 % |
| OnesLike | 16 | 93.790 | 1.50 | 0.030 % |
| 小计 | 7,536 | — | 631.78 | 12.749 % |
这是
op_statistic视角下最值得优化的板块。若能将适合的 AI_CPU 调用改写或路由到 AI_VECTOR_CORE / AI_CORE,理论上有机会释放约 520 ms(占总耗时约 10.5 %),但具体收益需要结合算子语义和 A/B profiling 验证。
3.8 高频低耗时算子
调用次数 > 50,000 但 Avg Time < 5 us 的算子:
| OP Type | Count | Avg (us) | Ratio | 备注 |
|---|---|---|---|---|
| Mul | 277,944 | 2.103 | 11.80 % | element-wise |
| Cast | 190,304 | 1.314 | 5.05 % | dtype 转换 |
| Add | 170,272 | 1.432 | 4.92 % | element-wise |
| ConcatD | 87,512 | 3.357 | 5.93 % | tensor 拼接 |
| ReduceMean | 82,632 | 3.352 | 5.59 % | RMSNorm 第 1 步 |
| Pows | 82,632 | 2.161 | 3.61 % | RMSNorm 第 2 步 |
| Rsqrt | 82,632 | 1.259 | 2.10 % | RMSNorm 第 3 步 |
| Slice | 80,128 | 2.036 | 3.29 % | tensor 切分 |
特征:单算子便宜(1–3 us),但调用量极大,是典型的小算子密集 workload。
3.9 数据一致性验证
| OP Type | op_statistic Count | op_summary slice_0 Count | 比例(statistic / slice_0) |
|---|---|---|---|
| MatMulV2 | 142,728 | 99,958 | 1.428× |
| Mul | 277,944 | 194,655 | 1.428× |
| FlashAttentionScore | 20,032 | 14,029 | 1.428× |
| ScatterElements | 2,504 | 1,753 | 1.428× |
| ConcatD | 87,512 | 61,280 | 1.428× |
| ReduceMean | 82,632 | 57,872 | 1.428× |
| Cast | 190,304 | 133,278 | 1.428× |
| Add | 170,272 | 119,246 | 1.428× |
| BroadcastTo | 40,064 | 28,058 | 1.428× |
| Pows | 82,632 | 57,872 | 1.428× |
op_statistic / op_summary_slice_0 ≈ 1.428×(精确)——说明 slice_0 与 slice_1 是均匀分割的同一 workload,op_statistic 是两个切片合并后的聚合结果。
3.10 分析与优化建议
3.10.1 快速锁定 Top 占比
- 排名前 4 的算子(MatMul + Mul + FlashAttention + Scatter)已经占据 51.06 % 的 device 时间。
- 排名前 10 占据 80.77 %。优化时应优先处理这些 Top 算子。
3.10.2 Core Type 路由差异
op_statistic 暴露了 MaskedFill / Cumsum / OnesLike 三种算子在 AI_CPU 与 AI_VECTOR_CORE 路径之间的差异:
| OP Type | AI_CPU Avg | AI_VECTOR_CORE Avg | 慢倍率 | 当前走慢路径的次数 |
|---|---|---|---|---|
| MaskedFill | 35.193 us | 3.940 us | 8.93× | 2,504 |
| Cumsum | 34.976 us | 11.707 us | 2.99× | 2,512 |
| OnesLike | 93.790 us | 16.893 us | 5.55× | 16 |
优化路径:
# 业务侧:用 shape 提示算子调度器走 AI_VECTOR_CORE
# 或者:调用 aclnn 接口时显式指定 backend
# 例如 Cumsum:传入 dim=-1 的 contiguous tensor 时,调度器倾向走 AI_VECTOR_CORE
# OnesLike 改用 torch.ones_like 显式调用,走 AI_VECTOR_CORE 路径
y = torch.ones_like(x, dtype=x.dtype) # 强制走 AI_VECTOR_CORE 路径
3.10.3 ScatterElements 单点优化
op_statistic 显示 ScatterElements 单次 181.429 us,最大 336.84 us,是平均耗时最高的算子。
- 来源
model/model_minimind.py的 DPO/RLHF preference 对齐逻辑。 - 改写建议同 2.9 节:改用
torch.npu.cat([chosen_logits, rejected_logits], dim=0)走 AI_CORE MatMul,避免 scatter。
3.10.4 小算子融合
Avg < 5 us 的 element-wise 算子占比合计 40 %+,建议:
- 启用
torch.npu.graphs做 capture-replay - 或对连续
Cast → Mul → Add → Rsqrt等 pipeline 显式调用aclnnRmsNorm/aclnnAddcmul融合算子
3.11 与其他文件的使用建议
| 场景 | 推荐文件 |
|---|---|
| 高层 overview / 占比分析 | op_statistic_*.csv |
| TOP 瓶颈算子定位 | op_statistic_*.csv |
| 异常 shape 钻取(cube utilization、block num) | op_summary_*.csv |
| 流水阶段分析(aic_mac_time / aiv_vec_time) | op_summary_*.csv |
| 单算子耗时分布(min/avg/max + wait time) | op_summary_*.csv |
| 跨切片合计数据 | op_statistic_*.csv |
| 同一 OP 不同 Core 路径对比 | op_statistic_*.csv |
4. task_time_*.csv — Task 级时间线
数据文件:
task_time_slice_0_20260604084522.csv(1,000,000 行)、task_time_slice_1_20260604084522.csv(485,553 行)
设备:Ascend 910B4
用途:算 stream 利用率、stream 间并行度、stream 气泡(host-device 同步等待)
4.1 文件格式与字段说明
每行 = 一个 device task(即一个 kernel 实例):
| 列 | 含义 |
|---|---|
Device_id |
设备编号(单卡:0) |
kernel_name |
算子名称(特殊任务如 EVENT_WAIT、MEMCPY_ASYNC 用 N/A) |
kernel_type |
物理执行类型:AI_CORE / AI_VECTOR_CORE / AI_CPU / MIX_AIC / MIX_AIV / DSA_SQE / MEMCPY_ASYNC / EVENT_WAIT / EVENT_RECORD 等 |
stream_id |
所属 stream |
task_id |
任务编号 |
task_time(us) |
该 task 实际执行耗时 |
task_start(us) |
task 在 stream 上启动的绝对时间戳(来自 device clock) |
task_stop(us) |
task 完成的绝对时间戳 |
task_stop − task_start = task_time,三者一致;时间戳精度为 0.01 us。
4.2 总体统计
| 指标 | 数值 |
|---|---|
| Task 总数 | 1,000,000 |
Task 执行总耗时(sum of task_time) |
3,354,818 us ≈ 3.35 s |
| Stream 总跨度(first start → last stop) | 39,723 us ≈ 39.72 s |
| 平均 stream 利用率 | 3,355 / 39,723 ≈ 8.44 % |
| Task 时长中位数 | 1.92 us |
| Task 时长 p99 | 25.86 us |
| Task 时长 max | 365.90 us |
| < 10 us 的 task 占比 | 95.51 %(955,138 个) |
| 10–100 us 的 task 占比 | 4.32 % |
| ≥ 100 us 的 task 占比 | 0.17 %(仅 1,688 个) |
关键结论:
- 95.51 % 的 task 都在 10 us 以内 —— 典型的小算子密集 workload。
- 真正在 NPU 上"干活"的时间只有 3.35 s,但整个推理切片从第一个 task 到最后一个 task 横跨 39.72 s,其中 91.56 % 的时间是 stream 气泡或空闲等待。
4.3 Stream 分布与利用率
| stream_id | Task 数 | 总执行时间 (ms) | Span (ms) | 利用率 | 说明 |
|---|---|---|---|---|---|
| 3 | 986,513 | 3,348.02 | 36,886.58 | 9.08 % | 主计算 stream,承担 98.65 % 的 task |
| 4 | 13,485 | 6.94 | 36,472.49 | 0.02 % ⚠️ | FlashAttention 旁路 stream,几乎闲置 |
| 2 | 2 | 0.10 | 10.00 | 1.01 % | 启动/收尾 stream |
Stream 利用率公式:
util(stream) = Σ task_time(stream) / (last_stop(stream) − first_start(stream))
4.3.1 stream=3 主计算 Stream
- 986,513 个 task,跨度 36.89 s,实际执行仅 3.35 s
- span 与执行时间的差异全部来自 task 之间的 gap(host 同步 + 调度 + 上游依赖)。
4.3.2 stream=4 FlashAttention 旁路 Stream
- 仅 13,485 个 task(几乎全是 FlashAttention),跨度 36.47 s
- 实际执行 6.94 ms,99.98 % 的时间都在等待 stream=3 的输入就绪。
4.3.3 stream=2 Profiling 控制 Stream
- 仅 2 个 task:
PROFILING_ENABLE+TASK_TIMEOUT_SET,跨度 10 ms - 这是 profiling 控制流专用 stream。
4.4 Stream Gap 分析
Gap = 当前 task 的
task_start− 同一 stream 上一个 task 的task_stop。
4.4.1 stream=3 Gap 分布
| 统计指标 | 数值 |
|---|---|
| 总 Gap 时间 | 33,538.01 ms |
| Gap 占 stream span 比例 | 90.92 % |
| 平均 Gap | 34.00 us |
| p50 Gap | 24.75 us |
| p90 Gap | 69.00 us |
| p99 Gap | 171.00 us |
| Max Gap | 96,603.00 us ≈ 96.6 ms ⚠️ |
解读:
- 90.92 % 的 stream span 都是 gap —— 设备绝大多数时间都在等。
- p50 gap = 24.75 us ≈ 一个普通 task 的耗时,说明算子之间几乎是背靠背执行,仅在 host 调度或同步点出现短暂停顿。
- p99 gap = 171 us —— 偶发的 host 阻塞(Python 解释器、torch dispatch)。
- max gap = 96.6 ms —— 出现过一次长达 96 ms 的 host-device 同步等待。
4.4.2 stream=4 Gap 分布
| 统计指标 | 数值 |
|---|---|
| 总 Gap 时间 | 36,465.55 ms |
| Gap 占 stream span 比例 | 99.98 % |
| 平均 Gap | 2,704.36 us |
| p50 Gap | 2,098.00 us |
| p90 Gap | 6,507.25 us |
| p99 Gap | 8,085.25 us |
| Max Gap | 80,408.00 us ≈ 80.4 ms ⚠️ |
解读:
- FA 旁路 stream 的 gap 中位数 2.1 ms,说明 FA 任务间隔很大 —— 因为每生成一个新 token 才需要触发一次 FA。
- 平均每 2.7 ms 才有一个 task,stream=4 完全可以合并到 stream=3 而不影响功能。
4.5 Task 时长分布
n = 1,000,000
min = 0.00 us
p1 = 0.02 us
p10 = 1.22 us
p50 = 1.92 us
p90 = 5.64 us
p99 = 25.86 us
max = 365.90 us
sum = 3.355 s
| 区间 | 次数 | 占比 |
|---|---|---|
| < 10 us | 955,138 | 95.51 % |
| 10–100 us | 43,174 | 4.32 % |
| 100–1000 us | 1,688 | 0.17 % |
| ≥ 1000 us | 0 | 0.00 % |
关键结论:
- 绝大多数 task 是 1–5 us 的极小 kernel —— 这是 element-wise 算子(Mul/Cast/Add/…)的特征。
- 单 task 慢于 100 us 的仅有 1,688 个(0.17 %),但它们贡献了绝大部分的执行时间(AI_CPU 上的 Scatter 单个 180 us,Cumsum/MaskedFill 单个 35 us)。
4.6 Stream 并行度
4.6.1 时间窗口对比
| stream | first_start (us) | last_stop (us) | span (ms) |
|---|---|---|---|
| 2 | 1780562131451008.25 | 1780562131461010.50 | 10.00 |
| 3 | 1780562134297677.25 | 1780562171184258.75 | 36,886.58 |
| 4 | 1780562134710415.00 | 1780562171182906.25 | 36,472.49 |
- stream=3 与 stream=4 的 span 几乎完全重叠(差值仅 414 ms,仅占 1.1 %)
- stream=4 在等 stream=3 的输入就绪(依赖关系通过 stream wait event 建立)。
4.6.2 Head Gap 与 Tail Gap
| stream | head_gap (ms) | tail_gap (ms) |
|---|---|---|
| 2 | 0.00 | 39,723.25 |
| 3 | 2,846.67 | 0.00 |
| 4 | 3,259.41 | 1.35 |
解读:
- stream=3 的 head_gap = 2,846.67 ms(≈ 2.85 s):从程序启动到 stream=3 上第一个 task 下发,host 端耗时 ~2.85 s 用于初始化、模型加载、shape 推导、第一次 tiling 编译等。
- stream=4 的 head_gap = 3,259.41 ms:额外多出 ~413 ms —— 等 stream=3 上前面的 task 完成。
- stream=2 的 tail_gap = 39,723.25 ms:stream=2 只用于初始化,两个 task 在 10 ms 内完成,但 profile 一直挂起到推理结束。
4.7 Kernel Type 时间分布
| Kernel Type | 次数 | 总耗时 (ms) | Span (ms) | 利用率 | 备注 |
|---|---|---|---|---|---|
| AI_VECTOR_CORE | 780,778 | 1,671.51 | 36,886.58 | 4.53 % | 占 task 数 78 %,总耗时 49.8 % |
| AI_CORE | 96,082 | 666.18 | 36,640.62 | 1.82 % | MatMul |
| AI_CPU | 5,072 | 426.63 | 36,830.37 | 1.16 % | Scatter/Cumsum/MaskedFill |
| MIX_AIC | 13,485 | 338.62 | 36,473.83 | 0.93 % | FlashAttention 算子 |
| MIX_AIV | 64,069 | 231.69 | 36,863.26 | 0.63 % | ReduceMean 等 |
| MEMCPY_ASYNC | 11,842 | 10.08 | 36,850.94 | 0.03 % | host↔device 搬运 |
| EVENT_WAIT | 13,485 | 6.94 | 36,472.49 | 0.02 % | stream 同步事件 |
| EVENT_RECORD | 13,485 | 0.25 | 36,473.03 | 0.00 % | stream 同步事件 |
| DSA_SQE | 1,685 | 3.05 | 36,426.15 | 0.01 % | DSA 任务 |
| PLACE_HOLDER_SQE | 15 | 0.00 | 33,844.24 | 0.00 % | 占位任务 |
解读:
- 各种 kernel_type 的 span 都接近 36.5 s,说明它们全时段都被使用,但每个 type 的实际执行时间都远小于 span —— NPU 各功能单元都是低负载运行。
- EVENT_WAIT 与 EVENT_RECORD 各 13,485 次,与 FA 调用次数一致 —— 每一次 FlashAttention 都伴随一对同步事件。
4.8 关键 Timeline 片段
| # | kernel_type | start (us) | dur (us) | stop (us) | 与上一个的 gap |
|---|---|---|---|---|---|
| 1 | AI_VECTOR_CORE | 1780562134297677.25 | 4.36 | 1780562134297681.75 | — |
| 2 | AI_VECTOR_CORE | 1780562134303922.00 | 4.50 | 1780562134303926.50 | 6,240.25 us ⚠️ |
| 3 | MIX_AIV | 1780562134320914.75 | 2.64 | 1780562134320917.50 | 16,988.25 us |
| 4 | MEMCPY_ASYNC | 1780562134321127.25 | 0.92 | 1780562134321128.25 | 209.75 us |
| 5 | MIX_AIV | 1780562134321275.75 | 3.44 | 1780562134321279.00 | 147.50 us |
| 6 | AI_VECTOR_CORE | 1780562134327212.75 | 3.14 | 1780562134327216.00 | 4,933.75 us |
| 7 | MIX_AIV | 1780562134327341.00 | 3.48 | 1780562134327344.50 | 125.00 us |
| 8 | AI_CPU | 1780562134341637.00 | 365.90 | 1780562134342002.75 | 14,292.50 us |
| 9 | AI_CPU | 1780562134342002.75 | 299.94 | 1780562134342302.75 | 0.00 us (back-to-back) |
| 10 | AI_CPU | 1780562134342302.75 | 79.28 | 1780562134342382.00 | 0.00 us (back-to-back) |
观察:第 1→2 个 task 之间间隔 6.24 ms,第 2→3 个 task 间隔 16.99 ms —— 这是程序启动期 host 端初始化开销。
4.9 Stream 气泡根因分析
4.9.1 Gap 分布形态
p50 = 24.75 us ← 正常调度 gap(与 task 中位数 1.92us + overhead 相当)
p90 = 69.00 us ← host dispatch 抖动
p99 = 171.00 us ← 偶发 Python/锁/同步阻塞
max = 96,603 us ← 单次 host-device sync(异常长尾)
4.9.2 长尾 Gap 来源
从采样看到 stream=3 上偶现的 96.6 ms gap 几乎一定是:
aclrtSynchronizeStreamWithTimeout等待结果回传- Python 层的
torch.cuda.synchronize()(在 torch-npu 中映射到aclrtSynchronizeStream) - 算子第一次被调用时的 tiling 编译(首次
aclnnMatmul调用可达数十 ms)
4.9.3 Stream 4 空闲分析
stream=4 99.98 % 的时间都在等 stream=3 的 KV 准备好 —— 当前 FA 旁路 stream 没有被并行利用,等效于同步执行,没有获得 multi-stream 加速收益。
4.10 分析与优化建议
4.10.1 Stream 利用率优化
- 真正计算时间 3.35 s,但 wall time 39.72 s
- 36.4 s 是气泡 / host 同步 / 调度等待
优化方向:
- 减少 host↔device 同步:删除不必要的
synchronize调用 - 算子预编译:在第一次 inference 之前 warm-up 所有算子,消除首次 tiling 编译开销
- 批量下发:把连续的小算子合并到
torch.npu.graphs(NPUGraph)一次性下发
4.10.2 Stream 合并建议
- stream=4 利用率 0.02 %,99.98 % 在等 stream=3
- 当前 FA 旁路 stream 没有任何并行收益,仅增加了 kernel 调度开销
- 建议:把 FA 任务合并到 stream=3,删除 stream=4 配置
# 当前(多 stream,未利用并行)
fa_stream = torch.npu.Stream()
with torch.npu.stream(fa_stream):
attn = self.flash_attn(q, k, v)
main_stream.wait_event(fa_stream.record_event())
# 改后(单 stream,去掉冗余)
attn = self.flash_attn(q, k, v) # 走默认 stream
4.10.3 Gap 优化
- p50 gap = 24.75 us 主要来自 kernel launch overhead(~10–15 us/launch × 1.5–2 个并发算子)
- p99 gap = 171 us 来自 host Python 抖动
优化:
- 启用
torch.npu.graphs.CUDAGraph()capture-replay,把整段推理捕获为静态图 - 把 Python 端的
torch.cat / torch.mul全部改为torch.npu._foreach_*等融合接口。
4.10.4 首次启动开销优化
stream=3 的 head_gap = 2.85 s,主要来自:
- 模型加载到 device:几百 MB 权重 × host→device 带宽
- 首次 tiling 编译:每个算子首次调用都会触发 tiling
- workspace 分配:
GetWorkspaceSize首次调用耗时方差极大(参考api_statistic中MatMulV2_Tilingmax=28 ms)
优化:
- 模型加载改为 mmap + 直接 device memory 映射,避免 H2D copy
- 提供一个 dummy warm-up pass,把所有算子都跑一遍,缓存 tiling 模板
- 启动阶段预分配 workspace 大小(用
ACLNN_CACHE_MODE缓存)。
4.10.5 极小 Task 合并
- 95.51 % 的 task 都 < 10 us,p50 仅 1.92 us
- 单个 kernel launch overhead 已经接近 task 本体耗时
- 必须靠算子融合消除:连续
Cast → Mul → Add → Rsqrt应该被融合为单 kernel。
4.11 与其他文件的使用建议
| 场景 | 推荐文件 |
|---|---|
| Stream 利用率、气泡分析、并行度 | task_time_*.csv |
| 算子占比(OP Type) | op_statistic_*.csv |
| 单算子耗时分布(min/avg/max + wait/dur) | op_summary_*.csv |
| 异常 shape 钻取 | op_summary_*.csv |
| 流水阶段(aic_mac_time / aiv_vec_time) | op_summary_*.csv |
| host 侧 API 调用耗时 | api_statistic_*.csv |
5. api_statistic_*.csv — Host ACL API 调用统计
数据文件:
api_statistic_20260604084522.csv(156 行,含 Header)
设备:Ascend 910B4
范围:Host CPU 上 Python → ACL runtime → CANN 的 API 调用开销。这是 host 侧耗时,不是 NPU 计算时间。
5.1 文件格式与字段说明
每行 = 一个 Host ACL API 调用的聚合统计:
| 列 | 含义 |
|---|---|
Device_id |
设备编号 |
Level |
API 层级:acl(算子级)/ runtime(runtime 间接调用)/ node(GE 图节点) |
API Name |
API 完整名(aclnn* / aclrt* / *_Tiling / *GetWorkspaceSize / node.launch) |
Time(us) |
累计耗时 |
Count |
调用次数 |
Avg(us) |
平均单次耗时 |
Min(us) / Max(us) |
单次最小/最大耗时 |
Variance |
单次耗时方差 |
5.1.1 Level 字段说明
| Level | 含义 | 典型 API |
|---|---|---|
acl |
算子级 API,用户直接调用 | aclnnMatmul、aclrtLaunchKernelWithHostArgs、aclrtMemcpy |
runtime |
runtime 间接调用(一般不直接出现在 api_statistic 中) | — |
node |
GE 图节点级,仅在 GE graph 模式出现 | node.launch |
5.2 总体统计
| 指标 | 数值 |
|---|---|
| API 种类(条目数) | 156 |
| API 调用总次数 | 5,887,135 |
| API 调用总耗时 | 38,409.82 ms ≈ 38.41 s |
唯一 _Tiling API |
41 |
唯一 GetWorkspaceSize API |
43 |
唯一 aclnn* API |
86 |
唯一 aclrt* API |
27 |
5.3 API Level 分布
| Level | 调用次数 | 总耗时 (ms) | 占比 |
|---|---|---|---|
acl |
4,459,271 | 28,463.03 | 74.10 % |
node |
1,427,864 | 9,946.79 | 25.90 % |
node仅一个条目node.launch,但占总调用次数的 24.25 %、总耗时的 25.90 % —— 说明当前 workload 全部走 GE 图执行模式。
5.4 API 调用全景
| 类别 | 数量 | 调用次数 | 总耗时 (ms) | 占比 |
|---|---|---|---|---|
aclrt* runtime API |
27 | 4,212,182 | 10,224.10 | 26.62 % |
aclnn* 算子 API |
86 | 247,089 | 18,238.93 | 47.49 % |
node.launch GE 图调度 |
1 | 1,427,864 | 9,946.79 | 25.90 % |
关键:算子 API 占总调用次数仅 4.2 %,但耗时占总 host 时间 47.49 % —— 单次算子调用开销大,需要 NPUGraph 批量下发。
5.5 Host Launch Path 分析
| API Name | Count | Time (ms) | Avg (us) | Max (us) | Ratio |
|---|---|---|---|---|---|
node.launch |
1,427,864 | 9,946.79 | 6.97 | 14,894.17 | 25.90 % |
aclrtLaunchKernelWithHostArgs |
1,425,360 | 7,761.16 | 5.45 | 1,730.60 | 20.21 % |
aclrtGetStreamAttribute |
1,332,400 | 623.45 | 0.47 | 13.83 | 1.62 % |
关键解读:
node.launch+aclrtLaunchKernelWithHostArgs累计 17,707.95 ms = 46.11 %。- 每条算子要依次经过
node.launch→aclrtLaunchKernelWithHostArgs→aclrtGetStreamAttribute三层 host 调度。 - 三者合计调用次数 ≈ 1.4M,每次 12.4 us —— 这是纯 host 调度开销,不包含任何 NPU 计算。
node.launchmax = 14.9 ms、aclrtLaunchKernelWithHostArgsmax = 1.73 ms —— 长尾来自 tiling 编译、workspace 分配等首次调用场景。
5.6 Top 高耗时 API
| Rank | Level | API Name | Count | Total (ms) | Pct | Avg (us) | Max (us) |
|---|---|---|---|---|---|---|---|
| 1 | node | node.launch |
1,427,864 | 9,946.79 | 25.90 % | 6.97 | 14,894.17 |
| 2 | acl | aclrtLaunchKernelWithHostArgs |
1,425,360 | 7,761.16 | 20.21 % | 5.45 | 1,730.60 |
| 3 | acl | aclnnMul |
270,432 | 2,676.66 | 6.97 % | 9.90 | 2,380.40 |
| 4 | acl | aclnnCast |
175,280 | 1,811.12 | 4.72 % | 10.33 | 1,674.99 |
| 5 | acl | aclnnMatmul |
145,232 | 1,579.55 | 4.11 % | 10.88 | 12,131.31 ⚠️ |
| 6 | acl | aclnnCat |
87,640 | 1,232.68 | 3.21 % | 14.06 | 1,935.63 |
| 7 | acl | aclnnMean |
82,632 | 1,121.33 | 2.92 % | 13.57 | 11,389.61 ⚠️ |
| 8 | acl | aclnnAdds |
85,136 | 899.81 | 2.34 % | 10.57 | 3,450.76 |
| 9 | acl | aclnnPowTensorScalar |
82,632 | 866.16 | 2.26 % | 10.48 | 1,121.81 |
| 10 | acl | aclnnAdd |
82,632 | 863.40 | 2.25 % | 10.45 | 1,873.86 |
| 11 | acl | aclnnRsqrt |
82,632 | 794.33 | 2.07 % | 9.61 | 678.91 |
| 12 | acl | aclnnInplaceCopy |
60,168 | 767.49 | 2.00 % | 12.76 | 1,731.75 |
| 13 | acl | aclnnMultinomial |
2,504 | 720.28 | 1.88 % | 287.65 ⚠️ | 3,529.91 |
| 14 | acl | aclnnFlashAttentionScore |
20,032 | 698.15 | 1.82 % | 34.85 | 97,033.31 ⚠️ |
| 15 | acl | aclnnNeg |
40,064 | 680.07 | 1.77 % | 16.98 | 38,670.34 |
| 16 | acl | aclrtGetStreamAttribute |
1,332,400 | 623.45 | 1.62 % | 0.47 | 13.83 |
| 17 | acl | aclrtMemcpy |
10,179 | 357.67 | 0.93 % | 35.14 | 1,845.30 |
| 18 | acl | aclnnInplaceCopyGetWorkspaceSize |
16,225 | 331.33 | 0.86 % | 20.42 | 5,303.69 |
| 19 | acl | aclrtRecordEvent |
20,032 | 277.42 | 0.72 % | 13.85 | 114.71 |
| 20 | acl | aclnnSilu |
20,032 | 210.77 | 0.55 % | 10.52 | 688.35 |
Top 20 累计 33,857.79 ms = 88.15 %。
5.7 关键 API 观察
5.7.1 aclnnMultinomial 耗时异常
| 指标 | 数值 |
|---|---|
| 调用次数 | 2,504 |
| 总耗时 | 720.28 ms |
| 平均单次 | 287.65 us ⚠️ |
| Max | 3,529.91 us |
- 调用次数少(仅 2,504),但平均 287.65 us / 次,是普通算子的 20–30 倍。
- 来源:生成阶段的 token 采样(每生成一个 token 调用一次)。
- 这是 host 侧的开销(采样逻辑在 CPU 跑),不是 NPU 计算。
5.7.2 aclnnFlashAttentionScore 首次调用长尾
| 指标 | 数值 |
|---|---|
| 调用次数 | 20,032 |
| 平均单次 | 34.85 us |
| Max | 97,033.31 us ≈ 97 ms ⚠️ |
| Max / Avg | 2,784× ⚠️ |
- 平均 35 us 算正常,但有 1 次调用花了 97 ms —— 首次 tiling 编译开销。
- 之后所有调用都稳定在 ~35 us,说明编译结果已被缓存。
5.8 Tiling API 分析
*_Tiling是 CANN 为每个算子做的 shape 切分/调度计算。首次调用*_Tiling会触发实际编译,耗时极高。
| 排名 | API Name | Count | Total (ms) | Avg (us) | Max (us) | Max/Avg |
|---|---|---|---|---|---|---|
| 1 | FlashAttentionScore_Tiling |
1,196 | 76.45 | 63.92 | 1,293.77 | 20.2× ⚠️ |
| 2 | Sub_Tiling |
3,097 | 61.82 | 19.96 | 89.19 | 4.5× |
| 3 | ConcatD_Tiling |
1,781 | 37.71 | 21.17 | 99.85 | 4.7× |
| 4 | MatMulV2_Tiling |
128 | 32.58 | 254.53 | 28,704.21 | 112.8× ⚠️ |
| 5 | Log_Tiling |
2,504 | 31.18 | 12.45 | 35.63 | 2.9× |
| 6 | Cast_Tiling |
3,166 | 25.06 | 7.91 | 239.59 | 30.3× |
| 7 | Transpose_Tiling |
2,510 | 18.92 | 7.54 | 1,069.00 | 141.8× |
| 8 | Add_Tiling |
2,580 | 18.77 | 7.28 | 120.30 | 16.5× |
| 9 | RealDiv_Tiling |
2,505 | 14.71 | 5.87 | 41.62 | 7.1× |
| 10 | Equal_Tiling |
1,172 | 14.46 | 12.34 | 46.30 | 3.8× |
| 11 | Abs_Tiling |
2,504 | 13.81 | 5.52 | 14.63 | 2.7× |
| 12 | ReduceAll_Tiling |
1,170 | 12.17 | 10.40 | 162.88 | 15.7× |
| 13 | BroadcastTo_Tiling |
593 | 8.76 | 14.77 | 48.26 | 3.3× |
| 14 | ArgMaxV2_Tiling |
2,504 | 8.57 | 3.42 | 10.59 | 3.1× |
| 15 | GreaterEqual_Tiling |
591 | 7.99 | 13.53 | 43.42 | 3.2× |
| 16 | Index_Tiling |
584 | 2.87 | 4.92 | 10.52 | 2.1× |
| 17 | Slice_Tiling |
38 | 1.45 | 38.15 | 870.43 | 22.8× |
| 18 | Mul_Tiling |
123 | 1.42 | 11.51 | 34.48 | 3.0× |
| 19 | ReduceMean_Tiling |
48 | 0.78 | 16.16 | 244.24 | 15.1× |
| 20 | Swish_Tiling |
15 | 0.37 | 24.86 | 67.01 | 2.7× |
| … | 其余 21 项 | < 0.4 ms each | — | — | — | — |
5.8.1 Tiling 长尾
| API | Count | Avg (us) | Max (us) | Max/Avg |
|---|---|---|---|---|
MatMulV2_Tiling |
128 | 254.53 | 28,704.21 | 112.8× ⚠️ |
Transpose_Tiling |
2,510 | 7.54 | 1,069.00 | 141.8× |
Slice_Tiling |
38 | 38.15 | 870.43 | 22.8× |
FlashAttentionScore_Tiling |
1,196 | 63.92 | 1,293.77 | 20.2× |
Cast_Tiling |
3,166 | 7.91 | 239.59 | 30.3× |
128 次
MatMulV2_Tiling平均 254 us,但 max 28.7 ms —— 单次编译耗时占整个 workload 的 5–10 %。
5.9 Workspace API 分析
*GetWorkspaceSize用于查询算子执行所需的临时 workspace 内存。重复调用相同 shape 表明 workspace 没有被复用。
| 排名 | API Name | Count | Total (ms) | Avg (us) | Max (us) |
|---|---|---|---|---|---|
| 1 | aclnnInplaceCopyGetWorkspaceSize |
16,225 | 331.33 | 20.42 | 5,303.69 |
| 2 | aclnnMultinomialGetWorkspaceSize |
2,504 | 183.02 | 73.09 | 6,470.44 |
| 3 | aclnnInplaceFillScalarGetWorkspaceSize |
3 | 147.19 | 49,064.69 | 145,619.09 ⚠️ |
| 4 | aclnnFlashAttentionScoreGetWorkspaceSize |
598 | 130.15 | 217.64 | 8,422.67 |
| 5 | aclnnCatGetWorkspaceSize |
1,854 | 103.09 | 55.60 | 35,720.40 |
| 6 | aclnnScatterGetWorkspaceSize |
2,504 | 88.92 | 35.51 | 245.71 |
| 7 | aclnnIndexGetWorkspaceSize |
584 | 76.11 | 130.33 | 19,281.44 |
| 8 | aclnnCumsumGetWorkspaceSize |
2,513 | 73.38 | 29.20 | 4,793.78 |
| 9 | aclnnMatmulGetWorkspaceSize |
72 | 71.53 | 993.46 | 58,449.45 ⚠️ |
| 10 | aclnnInplaceMaskedFillScalarGetWorkspaceSize |
2,506 | 61.31 | 24.46 | 2,080.98 |
| 11 | aclnnAllGetWorkspaceSize |
585 | 47.10 | 80.51 | 10,355.65 |
| 12 | aclnnNegGetWorkspaceSize |
19 | 34.06 | 1,792.37 | 32,458.14 |
| 13 | aclnnEqTensorGetWorkspaceSize |
586 | 22.40 | 38.23 | 2,992.29 |
| 14 | aclnnGeScalarGetWorkspaceSize |
591 | 20.86 | 35.30 | 2,372.29 |
| 15 | aclnnMeanGetWorkspaceSize |
24 | 18.67 | 777.92 | 17,328.99 |
| 16 | aclnnSubsGetWorkspaceSize |
592 | 18.47 | 31.20 | 2,835.65 |
| … | 其余 27 项 | < 15 ms each | — | — | — |
5.9.1 Workspace 调用异常
| API | Count | Avg | Max | 解读 |
|---|---|---|---|---|
aclnnInplaceFillScalarGetWorkspaceSize |
3 | 49,064.69 us | 145,619.09 us ≈ 145 ms | 3 次就消耗 147 ms,单次 workspace 查询 145 ms |
aclnnMatmulGetWorkspaceSize |
72 | 993.46 us | 58,449.45 us ≈ 58 ms | 平均 1 ms/次 |
aclnnMultinomialGetWorkspaceSize |
2,504 | 73.09 us | 6,470.44 us | 采样阶段每次生成都重新查 workspace |
5.9.2 Workspace 未复用问题
| API | Count | Total (ms) | 复用建议 |
|---|---|---|---|
aclnnInplaceCopyGetWorkspaceSize |
16,225 | 331.33 | 同 shape 重复查询,应缓存 |
aclnnInplaceMaskedFillScalarGetWorkspaceSize |
2,506 | 61.31 | 同上 |
aclnnCumsumGetWorkspaceSize |
2,513 | 73.38 | 同上 |
aclnnMultinomialGetWorkspaceSize |
2,504 | 183.02 | 同上 |
aclnnScatterGetWorkspaceSize |
2,504 | 88.92 | 同上 |
5 个 API 总计 26,252 次 workspace 查询 = 737.96 ms 浪费。
5.10 首次调用编译开销
这些 API 平均看起来很快(< 50 us),但单次 max 比 avg 大 100 倍以上,说明有首次编译/初始化的"长尾"。
| Rank | API Name | Count | Avg (us) | Max (us) | Max/Avg |
|---|---|---|---|---|---|
| 1 | aclnnFlashAttentionScore |
20,032 | 34.85 | 97,033.31 | 2,784× |
| 2 | aclnnNeg |
40,064 | 16.98 | 38,670.34 | 2,278× |
| 3 | node.launch |
1,427,864 | 6.97 | 14,894.17 | 2,138× |
| 4 | aclnnMatmul |
145,232 | 10.88 | 12,131.31 | 1,115× |
| 5 | aclnnMean |
82,632 | 13.57 | 11,389.61 | 839× |
| 6 | aclnnCatGetWorkspaceSize |
1,854 | 55.60 | 35,720.40 | 642× |
| 7 | aclnnAdds |
85,136 | 10.57 | 3,450.76 | 326× |
| 8 | aclrtLaunchKernelWithHostArgs |
1,425,360 | 5.45 | 1,730.60 | 318× |
| 9 | aclnnInplaceFillScalar |
12,528 | 11.48 | 3,454.77 | 301× |
| 10 | aclnnAny |
2,528 | 17.83 | 4,829.93 | 271× |
| 11 | aclnnInplaceCopyGetWorkspaceSize |
16,225 | 20.42 | 5,303.69 | 260× |
| 12 | aclnnMax |
2,504 | 15.21 | 3,850.25 | 253× |
| 13 | aclnnEmbedding |
2,504 | 14.69 | 3,594.21 | 245× |
| 14 | aclnnMul |
270,432 | 9.90 | 2,380.40 | 240× |
| 15 | aclnnBitwiseOrTensor |
5,008 | 11.60 | 2,348.84 | 202× |
这些都是首次编译/workspace 分配/动态 shape 探测的代价,主要发生在推理启动阶段(前 ~10 个调用)。
5.11 Host-Device 数据搬运开销
| API | Count | Total (ms) | Avg (us) | Max (us) | 含义 |
|---|---|---|---|---|---|
aclrtMemcpy |
10,179 | 357.67 | 35.14 | 1,845.30 | 同步 H2D/D2H 拷贝 |
aclrtMemcpyAsync |
17,600 | 169.26 | 9.62 | 46.62 | 异步 H2D/D2H 拷贝 |
aclrtRandomNumAsync |
2,504 | 147.43 | 58.88 | 102.95 | RNG 异步采样 |
aclrtFree |
20 | 2.26 | 112.75 | 1,116.93 | 显存释放 |
关键:
aclrtMemcpy(同步)总耗时是aclrtMemcpyAsync的 2.11 倍,说明应该把可异步的拷贝都改成 async 形式。- 17,600 次
aclrtMemcpyAsync通常是模型权重加载阶段的预取。
5.12 分析与优化建议
5.12.1 Host Launch 开销优化
node.launch + aclrtLaunchKernelWithHostArgs = 17.71 s,占总 API 时间的 46.11 %。
优化:
# 1. 使用 NPUGraph 把整段推理捕获为静态图
graph = torch.npu.CUDAGraph()
with torch.npu.graph(graph):
out = model(input)
# 之后只需一次 launch 即可执行整段推理
graph.replay()
# 2. 算子融合(Fusion)减少 launch 次数
# 1 次 fused RMSNorm 替代 4 次独立算子 = 节省 4×launch overhead
预期收益:理论上可以减少明显的 host 调度时间,具体幅度需要通过优化前后 api_statistic 对比确认。
5.12.2 Tiling 编译长尾优化
| API | Count | Avg (us) | Max (us) |
|---|---|---|---|
MatMulV2_Tiling |
128 | 254.53 | 28,704.21 |
FlashAttentionScore_Tiling |
1,196 | 63.92 | 1,293.77 |
Transpose_Tiling |
2,510 | 7.54 | 1,069.00 |
优化:
# Warm-up pass:首次推理前把所有算子都跑一遍,缓存 tiling
for shape in all_shapes:
_ = model(dummy_input[shape])
# 启用 ACLNN caching
os.environ['ACLNN_CACHE_MODE'] = '1' # 启用 tiling cache
预期收益:理论上可以降低首次编译长尾,具体幅度需要通过 warm-up 前后对比确认。
5.12.3 Workspace 复用
| 高频 API | Count | 总耗时 (ms) |
|---|---|---|
aclnnInplaceCopyGetWorkspaceSize |
16,225 | 331.33 |
aclnnCumsumGetWorkspaceSize |
2,513 | 73.38 |
aclnnMultinomialGetWorkspaceSize |
2,504 | 183.02 |
aclnnScatterGetWorkspaceSize |
2,504 | 88.92 |
优化:
# 业务侧:用 npu 的 memory pool 复用 workspace
torch.npu.set_per_process_memory_fraction(0.9)
# 或在 CANN 层开启 workspace cache
os.environ['CANN_WORKSPACE_CACHE'] = '1'
预期收益:理论上可以减少 workspace 查询时间,具体幅度需要通过 *GetWorkspaceSize 调用次数和总耗时对比确认。
5.12.4 同步改异步
aclrtMemcpy(sync) 总耗时 357.67 ms,调用 10,179 次aclrtMemcpyAsync(async) 总耗时 169.26 ms,调用 17,600 次
优化:把所有 D2H 结果回传改为 MemcpyAsync,或合并到 aclrtSynchronizeStream 一次等待。
5.12.5 采样算子优化
aclnnMultinomial 平均 287.65 us / 次,是其他算子的 20–30 倍。
- 这是 host 侧的 token 采样逻辑
- 优化:批量化采样,或在 device 端做 top-k + sampling
5.12.6 Node Level Launch 模式
node.launch 仅出现在 GE graph 模式下。当前 25.90 % 的 host 耗时来自 GE 图调度:
- 如果改用 acl 算子级直接调用,可绕开 GE 调度(但失去 graph 优化)
- 或者使用
msprof --mode=acl重新 profile,对比两种模式的差距
5.13 与其他文件的使用建议
| 场景 | 推荐文件 |
|---|---|
| Host 侧 API 开销分析 | api_statistic_*.csv |
| 算子 tiling/workspace 首次编译开销 | api_statistic_*.csv |
| host launch overhead 评估 | api_statistic_*.csv |
| NPU 实际计算时间(device 侧) | op_summary_*.csv / op_statistic_*.csv |
| Device task 时间线 / stream 利用率 | task_time_*.csv |
关键认识:
api_statistic统计的是 host CPU 时间,不计入 NPU chip 时间。
一个 inference 的总耗时 = host API 时间(api_statistic) + device 计算时间(op_summary / op_statistic / task_time)。
6. 优化验证计划
后续优化不建议一次性全部修改,而是按优先级逐项验证。每次只改一个关键点,并用同一套 profiling 指标做前后对比,避免无法判断收益来源。
| 实验编号 | 优化项 | 主要观察指标 | 预期变化 |
|---|---|---|---|
| Exp-1 | 消除 ScatterElements AI_CPU 路径 |
AI_CPU Ratio、ScatterElements 总耗时、Top 算子排名 |
AI_CPU 占比下降,Scatter 总耗时下降 |
| Exp-2 | 优化 MaskedFill / Cumsum 路由 |
AI_CPU 算子清单、Core Type 路由差异 | 慢路径调用次数减少 |
| Exp-3 | 融合 RMSNorm 相关小算子 | ReduceMean / Pows / Rsqrt / Mul 调用次数与总耗时 |
高频小算子数量下降 |
| Exp-4 | 启用 warm-up | Tiling API max time、首次调用长尾、首轮 latency | 首次调用长尾下降 |
| Exp-5 | 缓存 workspace | *GetWorkspaceSize 调用次数与总耗时 |
workspace 查询开销下降 |
| Exp-6 | 尝试 NPUGraph / capture-replay | node.launch、aclrtLaunchKernelWithHostArgs、stream gap |
host launch 次数和 gap 减少 |
| Exp-7 | 提高 batch / continuous batching | cube_utilization(%)、MatMul 平均耗时、tokens/s |
MatMul 利用率提升 |
| Exp-8 | 对比 FlashAttention 与普通 attention 路径 | FA 总耗时、attention 相关算子总耗时、TPOT | 判断当前 decode shape 下哪条路径更优 |
| Exp-9 | 优化采样路径 | aclnnMultinomial 总耗时、采样阶段 latency |
采样开销下降 |
建议每轮实验都固定记录以下结果:
- tokens/s
- TTFT(Time To First Token)
- TPOT(Time Per Output Token)
- P50 / P90 / P99 latency
- AI_CPU 占比
- Stream 利用率
- Stream gap 总量与 p99 gap
- Top 10 算子总耗时
- Host API 总耗时
node.launch/aclrtLaunchKernelWithHostArgs总耗时*Tiling与*GetWorkspaceSize长尾耗时
最终建议形成一张优化前后对比表:
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| tokens/s | 待补充 | 待补充 | 待补充 |
| TPOT | 待补充 | 待补充 | 待补充 |
| AI_CPU Ratio | 待补充 | 待补充 | 待补充 |
| Stream 利用率 | 待补充 | 待补充 | 待补充 |
| Top 10 算子总耗时 | 待补充 | 待补充 | 待补充 |
| Host API 总耗时 | 待补充 | 待补充 | 待补充 |
7. 全文总结
本文从 MiniMind 推理实战出发,使用 msprof 对 Ascend NPU 上的推理过程进行了 profiling 分析。通过 msprof_*.json、op_summary_*.csv、op_statistic_*.csv、task_time_*.csv 和 api_statistic_*.csv,可以分别从 Timeline、算子逐条耗时、算子类型聚合、task 时间线和 host API 调用五个角度定位性能瓶颈。
本次 profiling 显示,当前性能瓶颈并不单纯来自某一个大算子,而是由 单 stream 串行、小矩阵 decode、AI_CPU 路径、高频小算子、host launch 开销、tiling / workspace 长尾 共同造成。也就是说,优化时不能只盯着 MatMul 或 FlashAttention,而应该同时关注 device 执行、stream 调度、host API 和模型代码路径。
后续优化建议优先围绕以下方向展开:
- 减少
ScatterElements、MaskedFill、Cumsum等 AI_CPU 路径。 - 使用算子融合或 NPUGraph 降低高频小算子和 host launch 开销。
- 通过 batching / continuous batching 提高 MatMul 与 attention 的硬件利用率。
- 通过 warm-up、tiling cache、workspace cache 降低首次调用和动态 shape 长尾。
- 针对采样、数据搬运和同步点继续做端到端 profiling 验证。
这篇报告的重点不是给出一次性的最终结论,而是建立一套从 msprof 数据出发定位 Ascend NPU 推理瓶颈的方法:先看总体分布,再看 Top 算子,再钻取 shape 和 Core Type,最后用 task timeline 与 host API 统计补齐调度和运行时开销。

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)