
从零开始理解SIMT算子开发:一个真实案例的完整拆解
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161601003
背景概述
在推荐系统、大模型训练等场景中,嵌入(Embedding)类操作频繁出现,其核心特征是离散索引访问——即根据 (table_id, row_id) 这样的非连续索引,从缓存中读取或更新对应数据。SIMT(Single Instruction Multiple Thread)执行模型,允许每个线程独立寻址、独立执行,从而显著提升离散访问场景下的并行效率。
在此背景下,Ascend C作为面向AI Core的高性能编程语言,提供了对SIMT模型的原生支持。然而,对于初学者而言,面对复杂的工程结构、Host与Kernel的分工以及线程调度策略,往往感到无从下手。
本文将通过一个真实、典型的SIMT算子实现——linearize_cache_indices_from_row_idx,系统梳理从算子分析、设计、实现到调试优化的完整流程,帮助开发者建立清晰的认知框架,快速掌握昇腾算子开发的核心方法论。
AscendC的相关知识介绍
SIMT与SIMD差异
在AI芯片并行计算领域,SIMD与SIMT是两种最核心的执行模型。理解它们的本质差异,是掌握昇腾算子开发的关键。
SIMD:规整数据计算的极致效率
SIMD(Single Instruction Multiple Data)的核心思想是:一条指令驱动多个计算单元同时执行。
它特别适合以下场景:向量加法、乘法,矩阵运算,卷积计算
在这些场景中,数据布局规整、内存访问连续、分支逻辑一致,SIMD能发挥出极高的计算密度。
但其局限性也十分明显:必须连续取址,以及由于算术逻辑单元(arithmetic and logic unit,ALU) 宽度的限制,因此计算时要求数据类型、格式、大小必须严格对齐。
SIMT:更灵活的并行模型
SIMT(Single Instruction Multiple Thread)则完全不同,每个线程拥有独立的程序计数器、寄存器和寻址能力,但共享同一指令流。
这意味着:
thread0 -> addr0
thread1 -> addr10000
thread2 -> addr123456
thread3 -> addr7
不同线程可以访问完全不同的内存地址,无需等待或同步。
比 SIMD 编程开发更灵活,适用于数据并行的大规模计算场景
新手视角下host与kernel的分工
简单来说,Host侧不执行实际的数值计算,而是负责“算子怎么跑、跑多少、跑哪里”的元决策,而Kernel侧是算子真正执行数值计算的地方,通过AscendC语言实现我们的计算逻辑,如下图示意

昇腾SIMT算子实操,以 linearize_cache_indices_from_row_idx 算子为例
下面以 linearize_cache_indices_from_row_idx 算子为例,完整拆解一个SIMT算子的开发流程。
算子背景
算子原理
该算子的核心功能是:将 (table_id, row_id) 转换为全局唯一的线性缓存索引。
已知:
cache_hash_size_cumsum:各表的起始偏移量数组
update_table_indices:待更新的表ID列表
update_row_indices:对应行ID列表
核心逻辑为:
(table_id, row_id)
↓
offset = cache_hash_size_cumsum[table_id]
↓
linear_index = offset + row_id
若 table_id < 0 或 row_id < 0,则返回哨兵值(表示非法索引)。
下面是两个例子演示计算过程
全局缓存地址空间分段布局(以4 张表、每张容量 12 为例)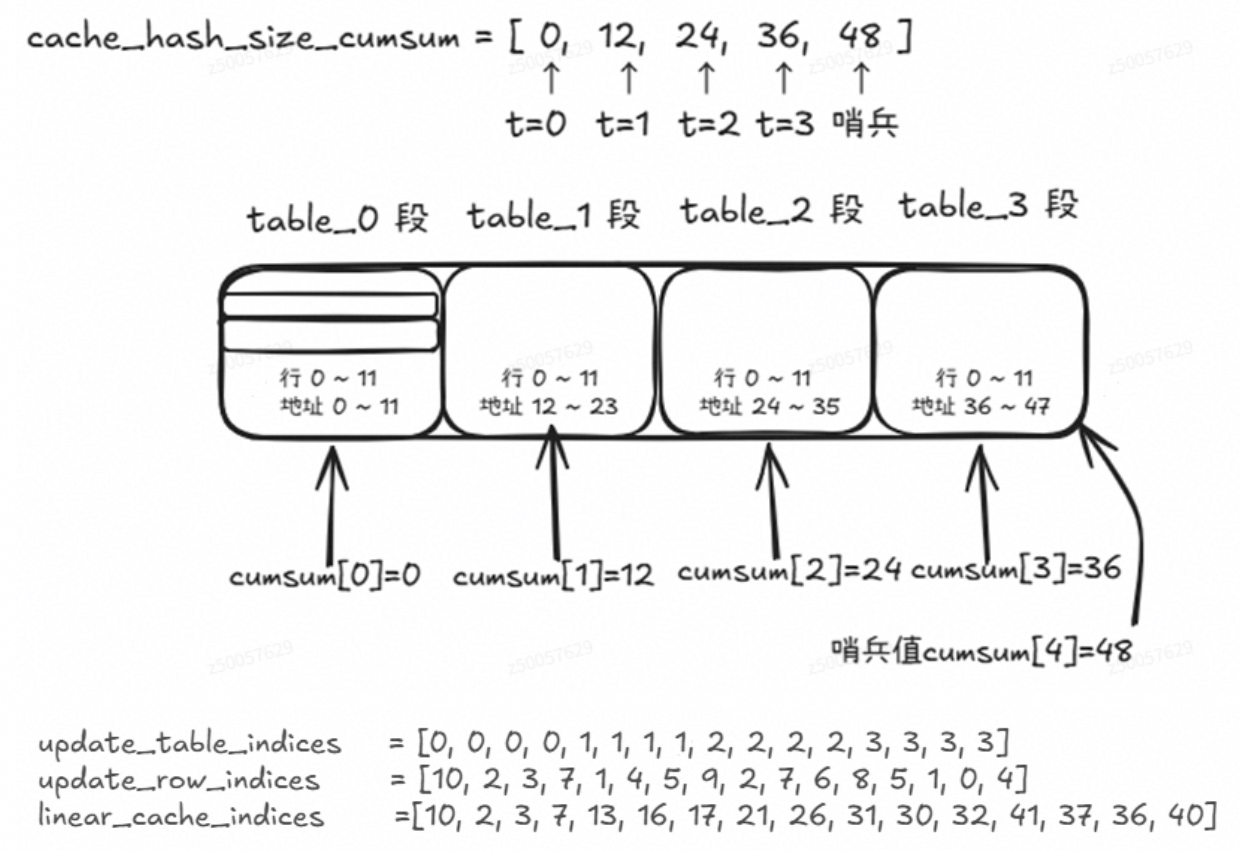
含未缓存表的情况(cumsum[2] = -1,table_2 不在缓存中)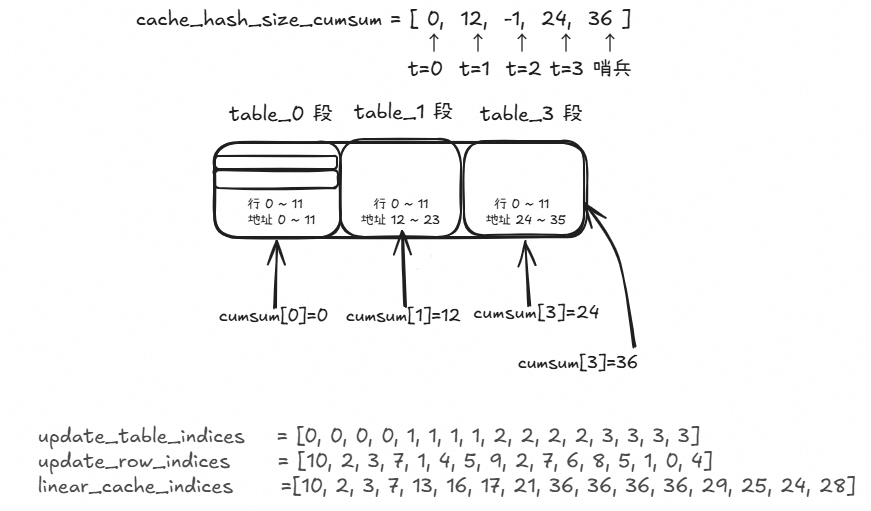
算子全流程调用栈
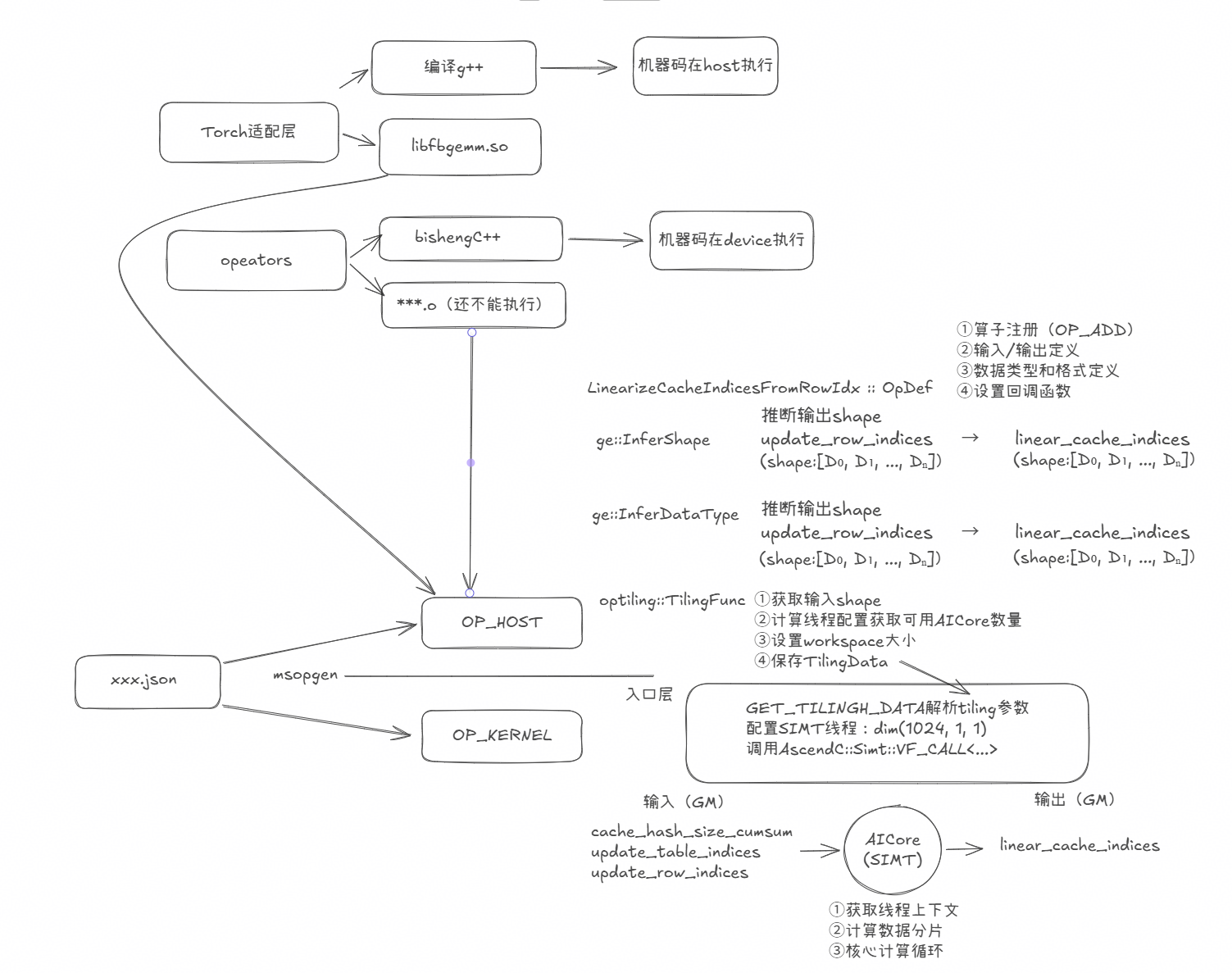
一个完整的算子工程包含适配层、编译脚本、host侧与kernel侧的实现等模块,下面详细介绍。
PyTorch适配层
适配层负责把PyTorch代码中需要调用的算子映射适配昇腾AI处理器的算子,以本算子为例,适配层调用如下图示意,左侧是一个PyTorch代码调用本算子的例子,右侧表明是适配层代码是如何映射适配昇腾AI处理器的算子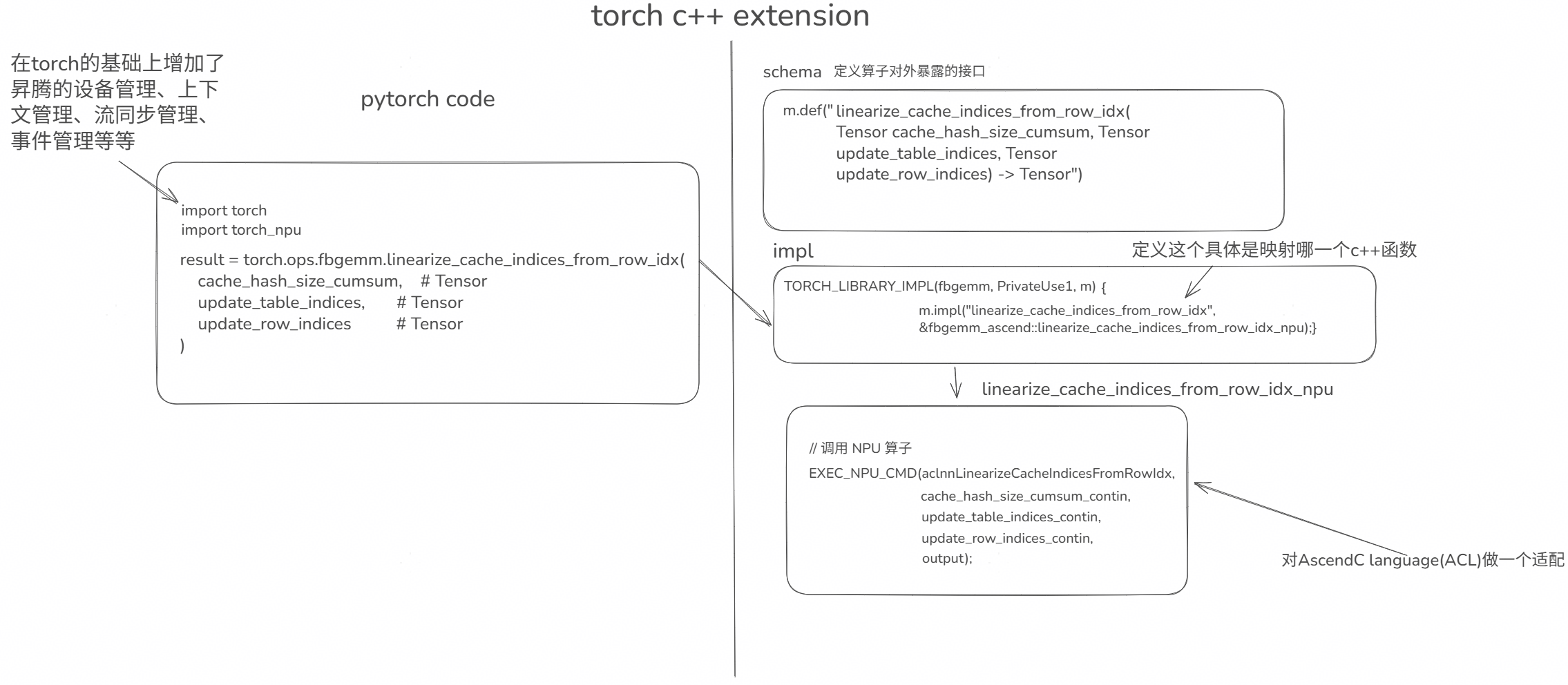
算子实现(host,kernel)
Host侧
Host 侧主要承担三项核心职责:输出 Tensor 的 Shape 推导(InferShape)、数据类型推导(InferDtype),以及算子分核分块的 Tiling 逻辑。其中,Tiling 逻辑是性能的关键——昇腾 NPU 采用多核并行架构,算子能否充分利用所有 AI Core 的算力,直接取决于 Tiling 策略的好坏。因此,本节将重点介绍 Tiling 的设计与实现。
由于本算子算法特性是无依赖的逐元素操作,即每条更新记录完全独立,没有数据依赖,没有状态共享,并且内存访问模式相同都是读两个输入数组 → 查 cumsum → 写输出,所以tiling 算子分核分块逻辑我们采用均匀切分,确保每个核同时满负荷运行、同时完成,最大化硬件利用率。具体的实现思路为先查询 NPU 有多少个核,获得实际可以调用的核数,把总数据量均匀分给每个核,计算每核处理多少条(blockDim)和需要启动多少轮(gridDim),同时加两个上限保护防止硬件超限。这里对blockDim和gridDim都用了向上取整数,确保最后几条数据不被遗漏。
核心实现代码如下
Kernel侧:SIMT的核心实现
Kernel是算子的灵魂,负责具体计算逻辑。
如下图示意,本算子的核心计算逻辑本质是一次坐标系变换:将 (表号 t, 局部行号 r) 的二元组映射为全局一维地址。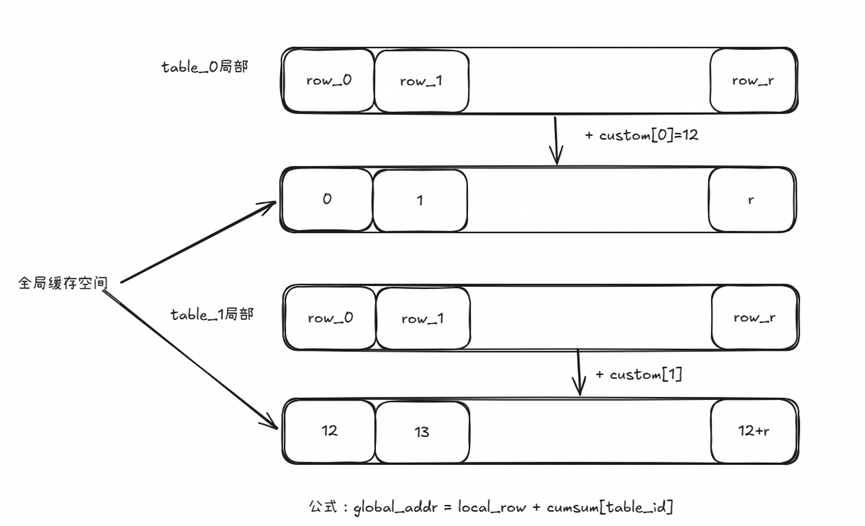
在kernel侧实现了核心计算逻辑:根据表索引查前缀和得到基地址,加上行索引得到线性缓存索引,若输入非法则写入哨兵值,代码如下: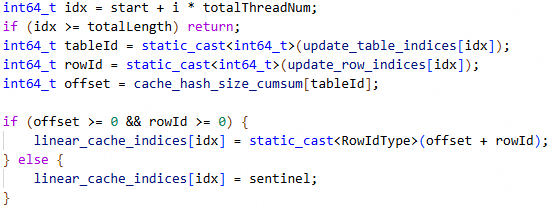
同时为了最大化硬件利用率,Kernel 侧线程分配逻辑我们采用for循环按固定间隔依次取数,确保每个线程同时满负荷运行、同时完成,具体实现逻辑为:先查询 SIMT 网格有多少个线程块和每块线程数,获得实际可以调用的总线程数,把总数据量按交错步长分给每个线程,计算每线程处理多少条(kDataPerThread)和线程起始位置(start),同时用向上取整确保最后几条数据不被遗漏,用提前边界判断让无效线程立即退出不空转。代码如下:
int32_t threadIdx = AscendC::Simt::GetThreadIdx<<0>(); // 块内线程号
int32_t blockIdx = AscendC::Simt::GetBlockIdx(); // 块号
int32_t threadNum = AscendC::Simt::GetThreadNum<<0>(); // 每块线程数
int32_t totalThreadNum = AscendC::Simt::GetBlockNum() * threadNum; // 总线程数
// 计算本线程的全局起始索引
int64_t start = (static_cast<int64_t>(blockIdx) * threadNum + threadIdx);
// 向上取整:每线程处理的数据量
int64_t kDataPerThread = (totalLength + totalThreadNum - 1) / totalThreadNum;
// for循环:按固定间隔依次取数,分散内存访问压力
for (int i = 0; i < kDataPerThread; ++i) {
int64_t idx = start + i * totalThreadNum; // 间隔 totalThreadNum 取一条
if (idx >= totalLength) return; // 边界保护:无效线程立即退出
// ... 查表计算 ...
}
踩坑与自救
Q1:芯片类型的问题
单独运行脚本编译算子时,报错发生在编译流程的后端打包阶段。具体而言,系统尝试移动 buildout/opkernel/binary/ascend910b/*.json 文件时失败,提示 No such file or directory。这表明算子二进制编译的前置步骤未能成功生成 .json 文件,导致打包阶段因缺少依赖而中断,最终造成 binary 目标编译失败。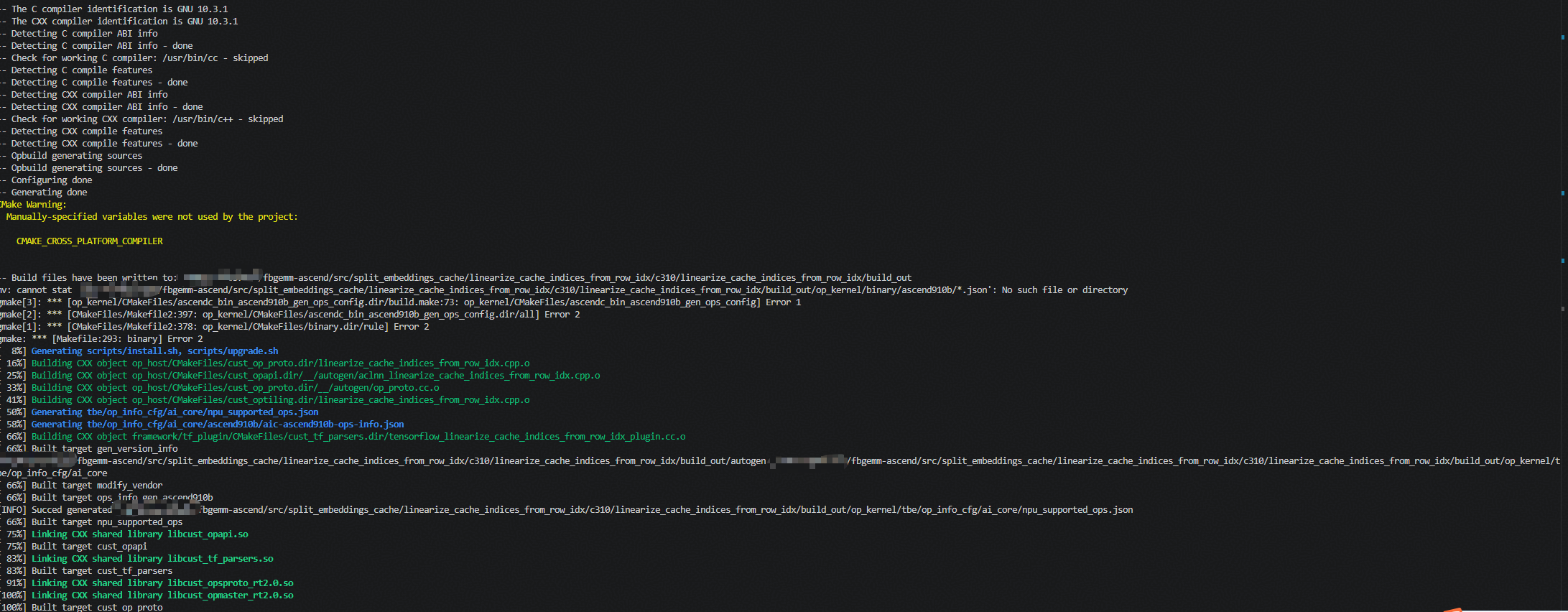
A1:首先排查环境问题是否为根因:运行 npu-smi info 查看实际芯片型号。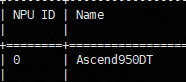
发现环境中部署的是 Ascend 950 DT,而脚本配置的目标平台为 Atlas 800I A2。两者不一致导致编译后端无法匹配正确的芯片指令集,进而无法生成 ascend910b/*.json 目标文件。定位问题后,修改脚本中的芯片配置与实际环境对齐,重新编译即可解决
Q2:数据类型不匹配
首先分析测试失败原因:提取失败用例的报错信息,发现均为数据类型不匹配导致的异常。 为进一步定位问题,选取一个典型失败样例,打印其输入数据类型与数值,观察到算子实际仅支持 updateTableIndices、updateRowIndices、out 为 DT_INT32 的场景。
为进一步定位问题,选取一个典型失败样例,打印其输入数据类型与数值,观察到算子实际仅支持 updateTableIndices、updateRowIndices、out 为 DT_INT32 的场景。
对照 Host 侧算子定义,cacheHashSizeCumsum 类型为 INT64,updateTableIndices 与 updateRowIndices 支持 INT32 或 INT64(且两者必须一致),输出 linearCacheIndices 类型与 updateRowIndices 相同。因此,Host 侧类型约束已正确声明,问题应向下追溯至 Kernel 侧的类型处理逻辑。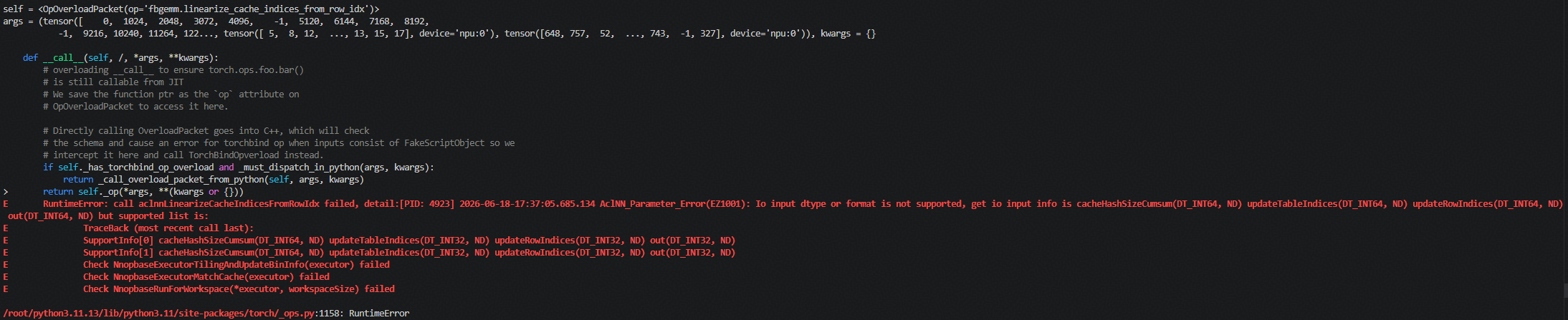
检查 Kernel 侧实现发现,VFCALL 内部的模板参数被硬编码为固定类型 int32t,未根据实际输入数据类型动态派发。这导致只有当输入数据类型恰好匹配硬编码类型时才能正常执行,其他合法类型组合(如 INT64)的测试用例均因类型不匹配而失败。
A2:针对该问题,解决方案采用宏定义实现编译期多类型自动实例化。具体而言,将 VF_CALL 内的参数处理逻辑抽象为宏定义,利用宏展开机制在编译期自动生成多种数据类型组合的 Kernel 实例。运行时则根据实际输入 Tensor 的 dtype 动态匹配并调用对应分支,从而覆盖 Host 侧声明的全部合法类型组合(INT32/INT64 的多种配对场景),最终使所有测试用例通过。
Q3:张量索引错位带来的数据越界访问
测试用例执行过程中偶发 RuntimeError: ACL stream synchronize failed, error code: 507035。该错误并非每次复现,且在不同规模组合下表现不一,部分规模通过,部分失败,无明显规律。报错信息语义模糊,仅提示流同步失败。初步错误堆栈显示,异常发生在数据从 Host 拷贝至 NPU 设备之后,初步怀疑为 Kernel 侧线程索引计算越界或设备侧执行异常。
cumsum_np = array(I 0, 256, 512, 768,1024, 1280,1536, 1792,2048, 2304,2560,
2816, 3072, 3328, 3584, 3840, 4096]), table _indices_np = array([14, 7, 15, , 15, 10, 14],
shape=(1024,), dtype=int32)
row_indices_np = array([ 8, 200, 159,., 85, 213, 125], shape=(1024,), dtype=int32), index dtype =
torch.int64
def run_test(cumsum_np, table indices_np, row indices_np,. index dtype):
"核心测试逻辑:对比CPU参考实现与NPU算子输出。
#CPU 参考结果
ref output=linearize_cache indicesfrom_rowidxref(
cumsum_np, table indices_np, row indices_np
#转换为Tensor并移至NPU
>
cumsum_t=torch.from_numpy(cumsum_np).to(torch.int64).to(DEVICE)
E
RuntimeError:ACL stream synchronize failed,error code:507035
t
///test/linearize_cache_indices_from_row_idx_test/test_linearize_cache_indices_from_row_idx.py:133:
RuntimeError
A3:为了定位该偶发问题,我们进行了单个样例测试并设置分层的打点实验,逐级排查:
(1)输入数据校验
在框架层和接口层打印输入张量的形状与数据类型,确认三个输入张量的 shape 和 dtype 均与预期一致。其中:
cumsum 长度为 17;
table / row indices 长度为 1024。
(2)Tiling 层分析
在 Host 侧 Tiling 函数中打印 GetInputShape (0) 得到 17,而 GetInputShape (2) 得到 1024。根据业务逻辑,totalLength 应代表实际待处理的记录条数(即 1024),但代码错误地使用了索引 0 作为 totalLength,导致 Tiling 计算严重偏差:实际ai core 合计仅调度处理 17 条数据,剩余 1007 条数据未被纳入调度。
(3)Kernel 层验证
Kernel 内部读取的 totalLength 同样为 17,因此核函数只计算到第 17 条数据便提前终止,剩余 1007 个线程(或后续数据)未执行有效计算,处于空转状态。
根因结论:Host 侧 TilingFunc 中误将索引 0(cumsum 长度)当作总处理长度,而正确应为索引 2(实际更新记录数)。尽管 cumsum 也是合法张量,编译阶段不会报错,但运行时当 totalLength 过小时,大量线程因 idx >= totalLength 条件提前返回,Kernel 中存在线程块内同步操作,同一个线程块内,提前返回的线程不会执行同步点,而仍在运行的线程会到达同步点并永久等待,造成线程块级死锁,设备侧任务执行超时。Host 侧调用 aclrtSynchronizeStream 等待设备完成时检测到超时或设备异常,最终返回错误码 507035。
根据以上我们进行如下修改
// 错误代码
int64_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
// 索引 0 对应 cache_hash_size_cumsum,其长度为 num_tables + 1(如 17)
应修改为
// 正确代码
int64_t totalLength = context->GetInputShape(2)->GetOriginShape().GetShapeSize();
// 索引 2 对应 update_row_indices,其长度为实际更新记录数 N(如 1024)
代码错误排查的通用思路
经过多个算子的开发与排查,我总结出一套如下问题定位与性能优化流程,以供参考。
分层排查策略(自上而下)如下图所示
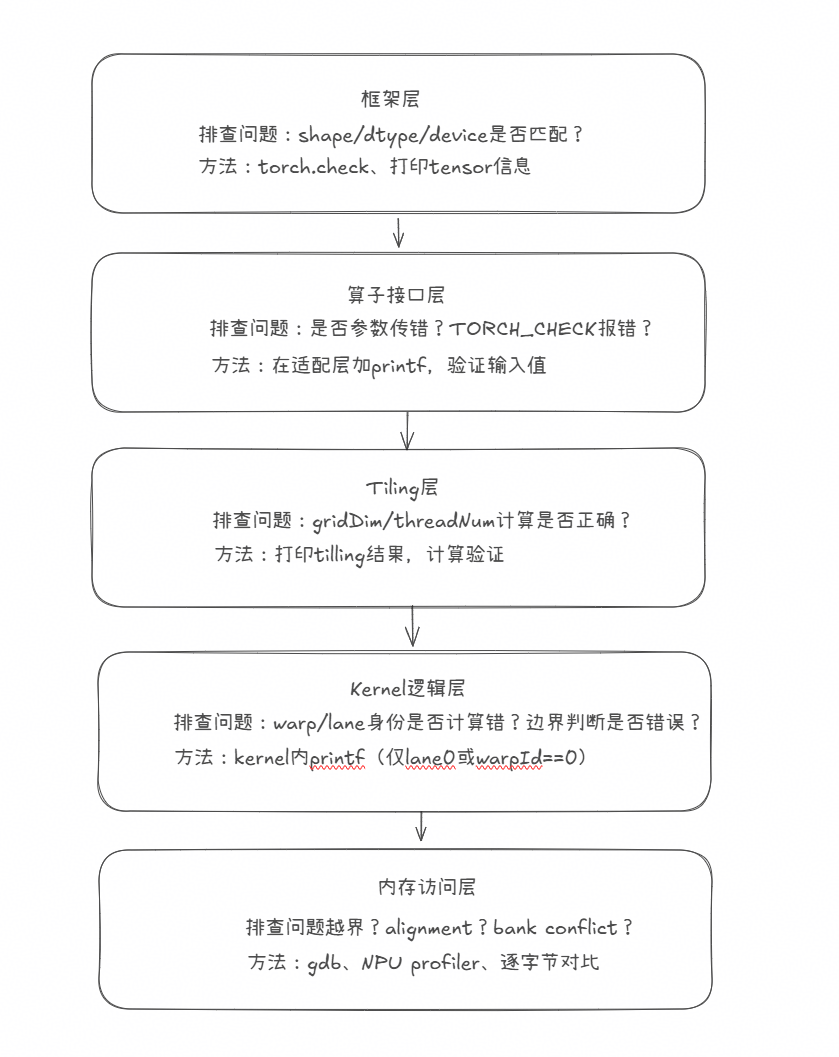
大部分的Bug集中在前3层并且容易检查出来,建议优先排查。
写在最后
作为SIMT算子开发的新手,我在学习过程中走了不少弯路,最初面对一堆文件也同样不知道从何下手。在尝试第一个算子开发后,我发现SIMT算子开发关键要理解“如何把数据分给线程”以及“每个线程需要做什么”这两个问题。这篇文章是我对前面算子开发工作的经验总结,难免有理解不到位的地方,希望可以帮助到同样在入门的朋友,也欢迎前辈们指正。
参考资料
fbgemm-ascend源码仓库:fbgemm-ascend:基于昇腾平台的推荐系统高性能PyTorch NPU算子库项目 - AtomGit
AscendC算子开发文档:基础知识-CANN社区版9.0.0-昇腾社区
fbgemm1.5.0:表分批嵌入运算符 — FBGEMM 1.5.0 文档 - PyTorch 文档

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)