
香橙派(Orange Pi AI Pro,昇腾NPU)本地跑DeepSeek等LLM
从零于香橙派快速部署DeepSeek1.5B、QWen0.5B、TinyLLama三个轻量LLM。8T和20T算力的都行,内存最好16GB或以上。
0、SD卡导入镜像
用balenaEtcher将官网的镜像拷进SD卡 (最好Ubuntu 22.04)
1、连接板子
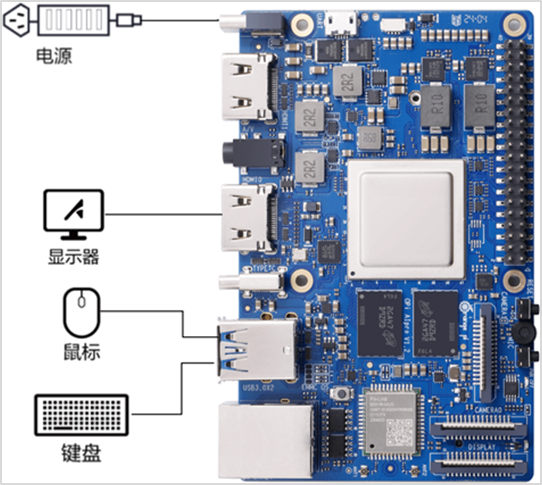
开发板开机成功后登录帐号HwHiAiUser,密码Mind@123
单击下方菜单栏的终端图标,或使用Ctrl+Alt+T快捷键,打开终端窗口,执行Linux命令
2、环境配置
检查CANN版本
cat /usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/ascend_toolkit_install.info
输出如下信息OK,
否则参考CANN升级指南 进行CANN升级或者降级
安装MindSpore
pip uninstall mindspore -y
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.5.0/MindSpore/unified/aarch64/mindspore-2.5.0-cp39-cp39-linux_aarch64.whl--trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
Swap检查
free -m

若swap没有配置,需要执行下面命令,配置swap 16G
sudo fallocate -l 16G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
安装gradio
pip uninstall gradio -y
pip install gradio==4.44.0
安装mindnlp (0.4版本)
pip install git+https://github.com/mindspore-lab/mindnlp.git@0.4
环境变量配置
echo 'export TE_PARALLEL_COMPILER=1' >>~/.bashrc
echo 'export MAX_COMPILE_CORE_NUMBER=1' >>~/.bashrc
source ~/.bashrc
安装cgroup
sudo apt-get update
sudo apt-get install cgroup-tools
# 检查是否安装成功
cgcreate --help
3.1、部署Deepseek1.5B
新建Deepseek-Qwen文件夹
mkdir Deepseek-Qwen
下载代码文件
到代码仓库下载源码,放到Deepseek-Qwen文件夹下
传输文件可以用微信传输助手网页版,比较方便
打开终端,进入Deepseek-Qwen文件夹,运行以下命令测试推理代码
cd Deepseek-Qwen
python deepseek-r1-distill-qwen-1.5b.py
运行过程中,会从modelers等国内镜像平台下载模型文件,一定要确保开发板联网以及mindnlp是0.4版本。
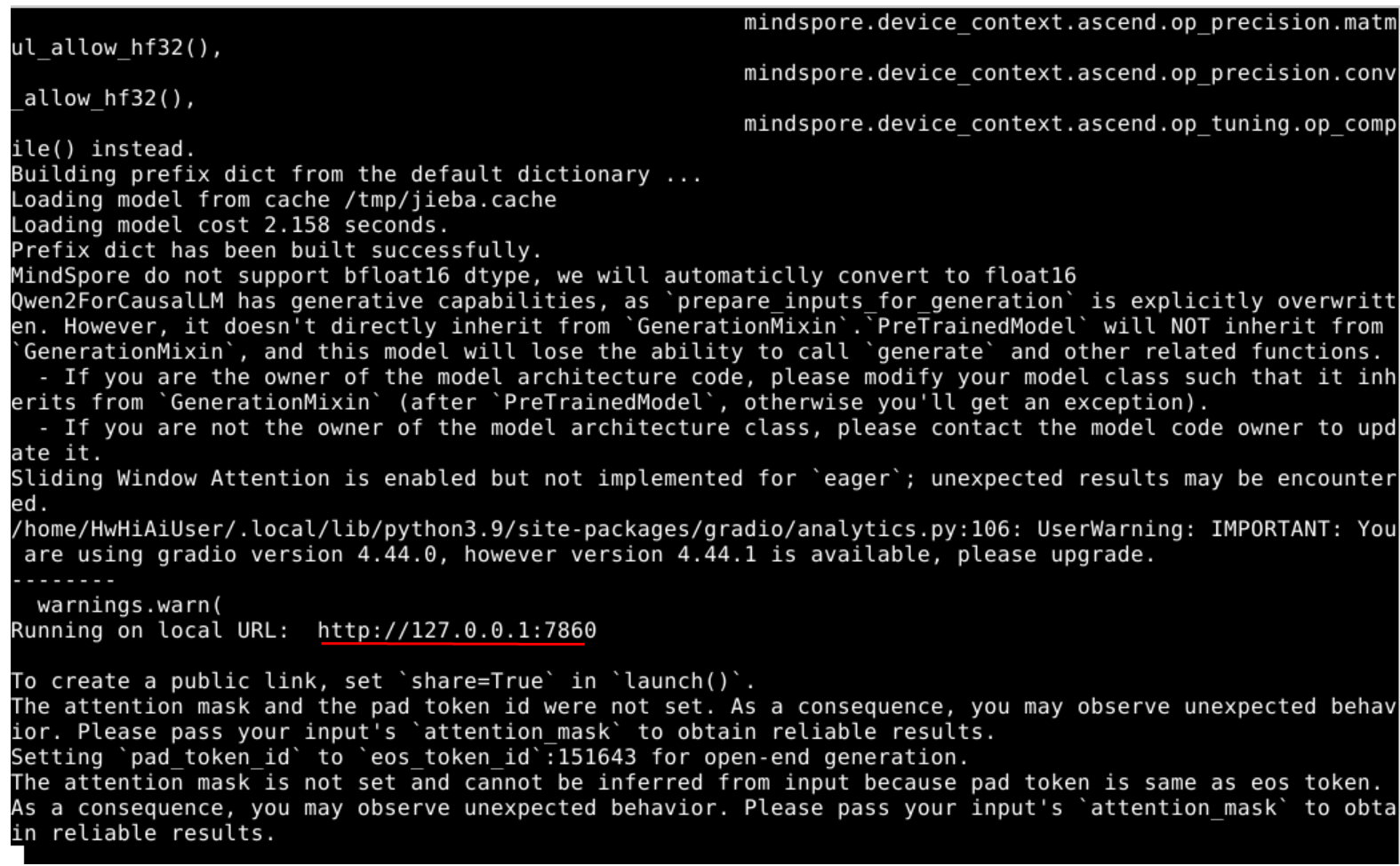
复制http链接:http://127.0.0.1:7860/到浏览器并打开
在输入框,输入问题,等待反馈结果。
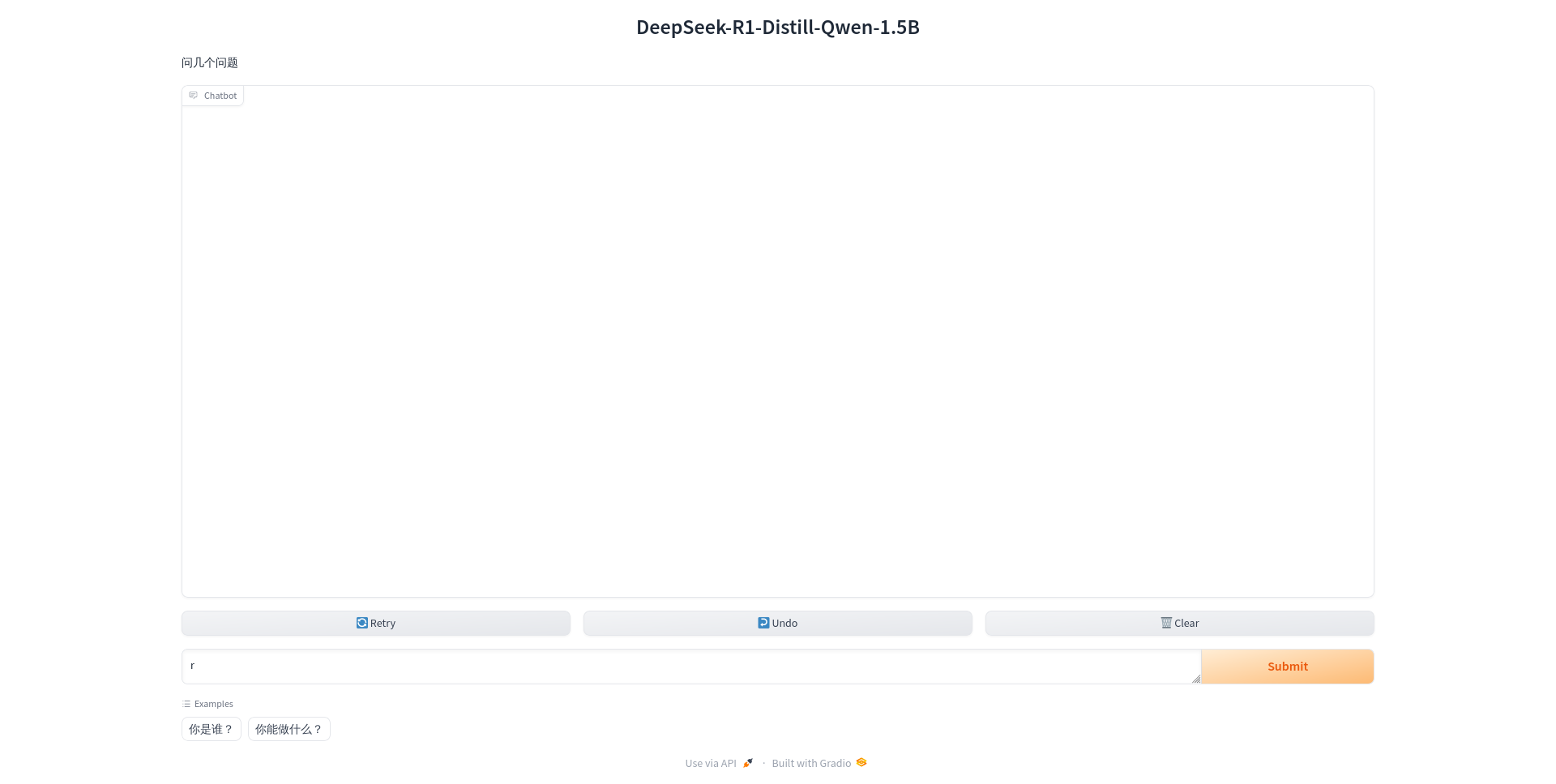
你会发现,推理得很慢很慢。昇腾对于LLM的推理引擎目前做得不好,应该很多计算没有offload到NPU,硬件加速没有充分利用,对比RK3588的rkllm模型推理速度差很多。
3.2、部署Qwen0.5B
如法炮制
下载并终端运行上面的代码
还是推理得挺慢
3.3、部署TinyLLama
下载并终端运行上面的代码

鲲鹏昇腾开发者社区是面向全社会开放的“联接全球计算开发者,聚合华为+生态”的社区,内容涵盖鲲鹏、昇腾资源,帮助开发者快速获取所需的知识、经验、软件、工具、算力,支撑开发者易学、好用、成功,成为核心开发者。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)